






Learning Self-Consistency for Deepfake Detection
介绍
思想:伪造图像中源特征不一致,检测基于缝合的方法生成的深度伪影
基于假设:生成的伪图像可以保存和提取图像的不同源特征
方法:成对自一致性学习(PCL),用于训练ConvNets提取这些源特征并检测深度伪图像。
图像合成方法,不一致图像生成器(I2G),为PCL提供丰富注释的训练数据。
源特征能够唯一标识其源的空间局部信息,可以来自成像管道(PRNU噪声:光响应不均匀性)、编码方法(JPEG压缩模式、压缩率)或图像合成模型,伪造的图像的源特征仍然保留,所以会在不同的位置包含不同的源特征,对于原始图像的源特征必须在所有位置一致,从而测量局部源特征的自一致性,就可以检测伪造图像。
方法:1、使用卷积神经网络(ConvNet)以降采样特征图的形式提取源特征。每个特征向量表示输入图像中对应位置的源特征。
1.1使用成对自一致性学习(PCL)训练ConvNet,其中使用一致性损失进行监督,也就是计算源特征图中每对特征向量之间的余弦相似性,并根据对应图像位置是否来自同一源图像来计算所有对上的一致性损失。惩罚引用来自相同源图像的位置的对,因为他们具有低的相似度分数,引用来自不同源图像位置的对,具有高的相似度分数。
1.2PCL中的一致性丢失需要关于位置是否已修改的像素级注释。它通常在deepfake检测数据集中不可用,在这些数据集上重新注释可能会很费力且容易出错。所以使用不一致图像生成器(I2G)生成的合成数据来解决这个问题。它根据deepfake生成方法中的最新技术生成伪造图像。为了节省计算成本并实现在线生成,I2G只将原始源图像和目标图像拼接在一起,而不是来自深度网络的合成图像。在生成过程中随机抽取伪造掩码进行拼接,这将成为PCL所需的像素级注释,结果表明虽然使用简化的生成过程,但利用I2G合成数据学习的模型有效地提取了原始图像和深度伪图像中的辨别源特征。
2、学习源特征图上附加一个非线性二元分类器来执行深度伪检测,用额外的损失训练,以生成图像级别的真实标签和伪标签。
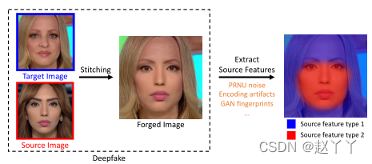
通过拼接目标图像和源图像生成伪造图像,对于每一个图像都有不同的源特征,可以唯一识别它们的源,所以伪造图像在不同的位置包含不同的源特征,而原始图像的源特征在所有位置一致,所以可以提取局部源特征并测量其自一致性,从而检测伪造图像。
方法
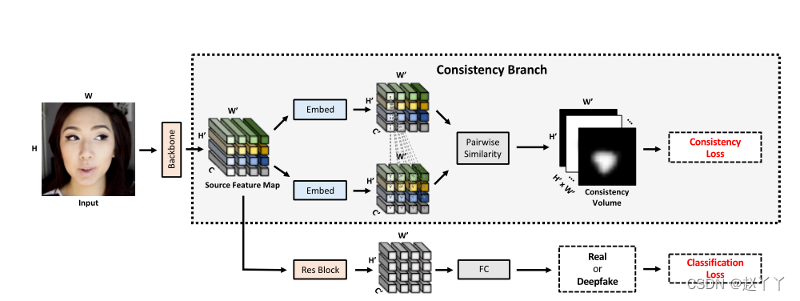
多任务学习架构,一致性分支被优化以预测每个图像块的一致性图,指示其源特征与所有其他特征的一致性。分类分支应用于源特征,并输出二进制标签用于评估。使用I2G提供的注释,对模型进行了一致性和分类丢失训练。
一致性分支侧重于根据图像块的源特征测量图像块的一致性。在源特征图之后应用分类分支,并预测深度伪检测的二进制分数。
成对自一致学习(PCL)
一致性分支
计算图像中所有可能的局部补丁对的成对相似性分数,并预测4D一致性卷V
输入:给定大小为H×W×3的预处理视频帧X,将其馈送到主干,并从中间卷积层提取大小为H‘×W’×C的源特征F,其中H’高度,W’宽度,C是通道大小。对源特征图中的每个补丁将其与所有其他补丁进行比较,测量它们的特征相似性,并获得大小为H’×W’的2D一致性图,一致性得分在[0,1]范围内。对于任何一对补丁pi和pj,使用其提取的特征向量fi和fj计算其点积相似度,估计其一致性得分。
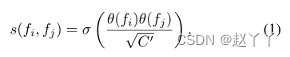
其中θ是嵌入函数,由1×1卷积实现,C′是嵌入维数,σ是Sigmoid函数。在源特征图中的所有补丁上迭代该过程,最终得到尺寸H′×W′×H′×W′的4D一致性卷V。
为了获得关于修改区域的可视化线索,在所有补丁上融合4D一致性卷V,并生成尺寸为H′×W′的2D全局热图,将H′×W′大小的样本增加到H×W,以匹配可视化的输入大小。
优化一致性分支
需要4D真实的一致性卷V
给定大小为H×W的groundtruth掩码指示输入X的操纵区域,首先通过双线性下采样创建其与H′×W′的大小匹配的粗略版本。
通过计算其自身值与其他值之间的元素差异,获取第(h,w)块的groundtruth2D一致性图
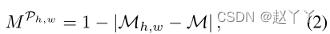
其中,Mh,w是位置(h,w)中的标量值,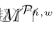 的大小为H′×W′,对于2D一致性图的每个条目,接近1表示两个补丁一致。
的大小为H′×W′,对于2D一致性图的每个条目,接近1表示两个补丁一致。
为了获得groundtruth的4D全球地图V,计算所有补丁的2D一致性图,原始图像的V应该是1,即所有值都等于1或接近1的4D卷。
使用二进制交叉熵(BCE)损失监督4D一致性卷V的一致性预测
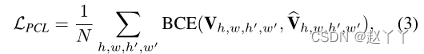
真实和预测的交叉熵,其中其中h和h′∈{1,2,…,H′},w和w′∈{1,2、…,W′},N等于H′×W′×H′×W′
分类分支
在源特征映射之后预测输入是真还是假
提取的源特征被馈送到另一卷积运算中,然后构建一个全局平均池和全连接层作为分类器,分类器输出 输入为真或假的概率分数,使用两类交叉熵(CE)损失CLS来监督分类分支中的训练。
总损失函数:
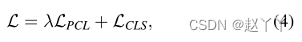
具有超参数λ(经过消融研究,大的话相对好,取10)
不一致图像生成器(I2G)
训练PCL需要操作区域的补丁级别注释,I2G从原始图像生成“自不一致”图像以及ground truth掩膜(修改的部分)
为了以最少的努力保证训练数据的足够数量和多样性,I2G通过用真实图像代替使用GAN或VAE的面部图像合成来降低计算成本。因此,I2G可以在训练期间支持CPU上的动态数据生成,并用作深度伪检测数据增强的一部分。
首先,由于面部图像具有一些强烈的结构偏差,与面部外壳区域的拼接可能会在源特征不一致性和面部边界之间产生不期望的相关性。I2G使用弹性变形来改善掩模M的多样性,从而消除这些伪相关性。
第二,由于攻击者会故意删除源特征以使deepfake图像更逼真,PCL需要使用不易受这些方法攻击的源功能。
I2G在数据生成中从一组穷尽的混合方法中随机选择一种,所以对于删除源特征具有鲁棒性
第三,我们期望学习到的表征能够推广到广泛的来源,甚至是在训练过程中看不见的来源。I2G将图像增强添加到生成过程中以实现此目标。增强方法包括JPEG压缩、高斯噪声/模糊、亮度对比度、随机擦除和颜色抖动。
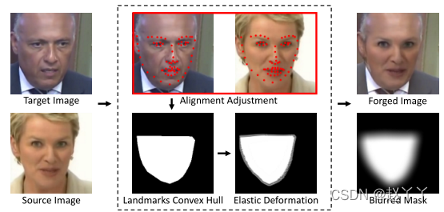
对于每个源图像和目标图像对,通过获取界标的凸包,然后进行弹性变形和高斯模糊,生成变形掩模。使用混合技术将目标图像的掩蔽区域替换为源图像的掩蔽区。
输入:大小为(H,W,3)的目标视频帧Xt。
输出:生成的视频帧Xg和掩码M
地标探测器K:RH×W×3→ R68×2
1、获取视频帧Xt及其地标K(Xt)
2、找到一个不同ID的随机源帧Xs,其满足‖K(Xt)−K(Xs)‖2<,阈值为>0。
3、使用界标将Xs与Xt对齐
4、计算K(Xt)的凸包H。
5、通过弹性变形和模糊H获得掩模M。
6、通过混合Xt、Xs和M获得Xg
Ground truth就是人工标注的结果,模型预测要和ground truth作比较。
下采样:缩小图像
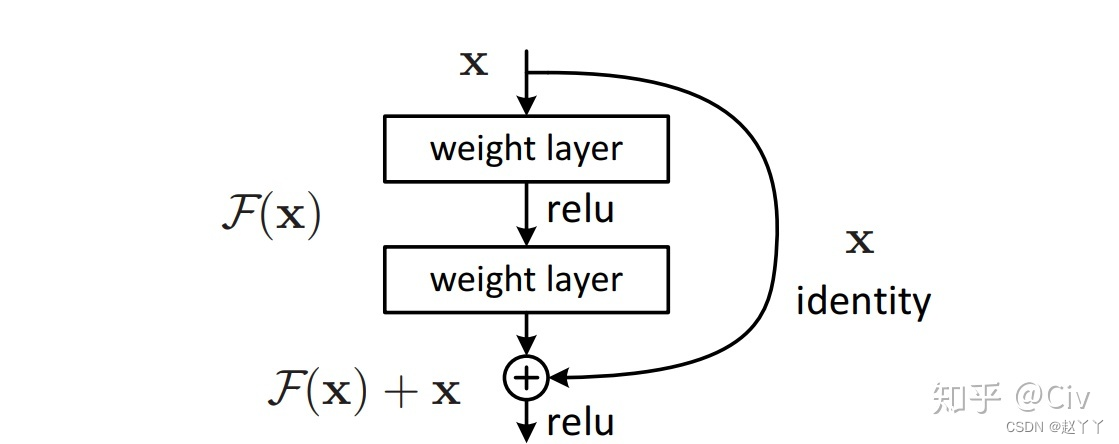
ResBlock是构成ResNet的基础模块,
生成式模型:由模型通过学习一组数据的分布,然后生成类似的数据
生成式对抗网络(Generative adversarial net,GAN)
变分自编码器(variational autoencoder, VAE)
流模型(Flow-based model)
实验
实验细节
1、预处理:
对于每个初始视频帧,使用公共工具箱检测地标,使用ImageNet平均值[0.485,0.456,0.406]和标准差[0.229,0.224,0.225]对所有面部作物进行归一化,并将其调整为256×256
使用标准数据增强,包括JPEG压缩、高斯噪声/模糊、亮度对比度、随机擦除和颜色抖动
2、网络架构:
采用ResNet-34作为主干,并在ImageNet上使用预训练的权重进行初始化。给定大小为H×W×3的预处理视频帧X,我们首先将其馈送到主干中,并在大小为H′×W′×256的conv3层之后提取特征F,其中H′=H/16,W′=W/16。这里,每个补丁对应于原始图像中的16×16区域。
3、训练:
对于每次迭代,从每个视频中随机采样32帧,K个视频的训练样本总数为32×K,使用Adam优化器对该模型进行了150次迭代的训练,批量大小batchsize为128,β系数为0.9和0.999,ε为10−8。在训练迭代的第一季度,学习率从0线性增加到5*10-5,在最后一个季度衰减到0,超参数λ默认设置为10。
实验设置
1、训练数据:
每个训练样本的形式为(X,V,y),其中X是输入视频帧,V是地面真相4D一致性卷,y是二进制标签。对于真实帧,V是1的4D张量,表示图像是自一致的,y为0。
两种类型的伪造样本:
(1)现有deepfake数据集的deepfake视频帧,为其找到相应的真实视频帧,计算它们之间的结构相异性(DSSIM),然后通过采用DSSIM的高斯模糊,然后进行阈值处理来生成掩模M。地面真相4D一致性卷V由掩膜M通过公式2计算得出,y为1。
(2)在真实图像上由I2G增强的假图像,其中地面真相4D一致性卷V是用I2G的掩码(修改的部分)计算的,y是1。通过使用I2G增强数据集进行训练,每当在训练期间对真实数据(Xt,1,0)(真实帧V是1,y是0)进行采样时,I2G将其动态转换为伪数据(Xg,V,1)(伪造帧V是V,y是1)的可能性为50%,其中Xg合成的帧和M掩膜是I2G的输出,V通过公式2与M一起计算。
(3)在数据集内的实验中,训练集包括来自数据集训练分割的原始视频和深度伪造视频,还使用I2G增强的伪样本作为数据增强,在交叉数据集实验中,仅使用FaceForensics++(FF++)原始版本的真实视频进行训练,并通过I2G进行增强。
2、测试数据:
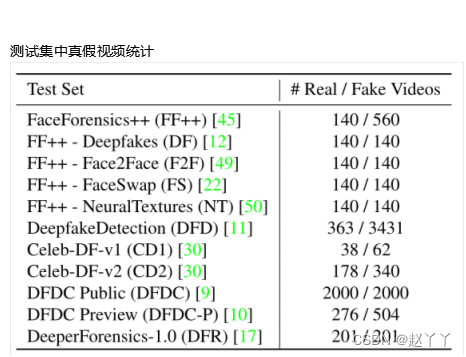
FaceForensics++(FF++)原始版本包含700个测试视频,包括来自4种不同算法的140个原始视频和560个伪视频,分别是Deepfakes(DF),Face2Face(F2F),FaceSwap(FS)NeuralTextures(NT)。DeepfakeDetection(DFD)数据集与FF++结合发布,支持deepfake检测研究。Celeb-DF-v1(CD1)和-v2(CD2)数据集由使用高级合成工艺的高质量伪造名人视频组成。
Deepfake检测挑战(DFDC)公开测试集是为Deepfake检测挑战发布的,DFDC预览(DFDC-P)是其初步版本。DFDC和DFDC-P包含许多极低质量的视频,使其极具挑战性。DeeperForensics1.0(DFR)使用新的面部ID和更先进的技术修改了FF++中的原始视频。
3、评价指标:
ROC曲线下面积(AUC)和平均精度(AP)。AUC或AP值越高,表示性能越好。
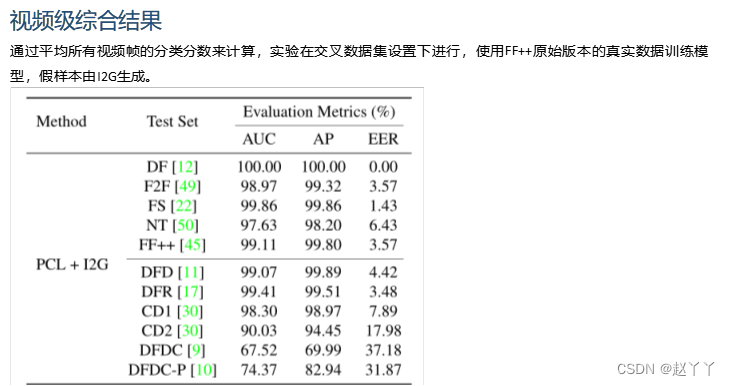
数据集内评估
FF++、CD2和DFDC-P

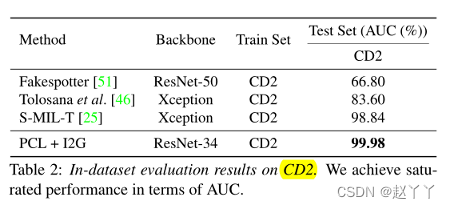
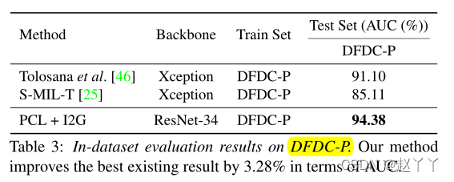
DFDC-P报告的结果相对较低,因为数据集的不可忽略部分质量极低,例如,某些视频中的人脸很难识别。
跨数据集评估
接近不知道潜在攻击类型的真实场景
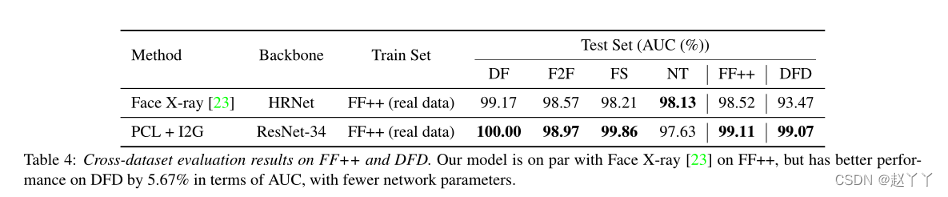
在DFD上,我们方法的性能比Face X-ray好很多
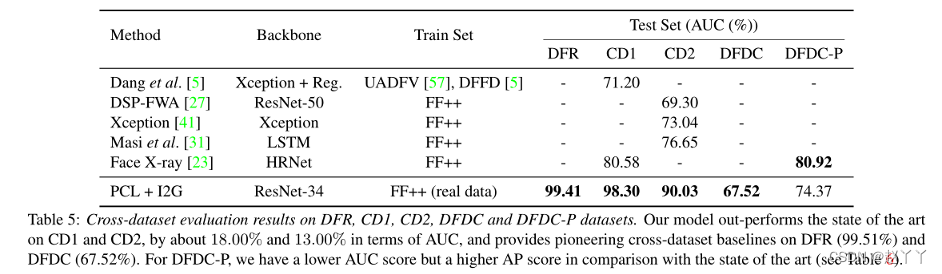
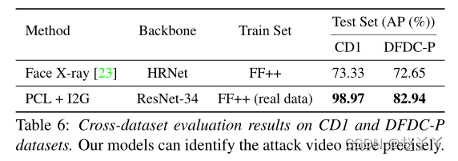
CD1和CD2上表现出最先进的AUC,分别为18.00%和13.00%,并在DFR(99.51%)和DFDC(67.52%)上提供了开创性的跨数据集基线。与最先进的相比,DFDC-P的AUC得分更低,但AP得分更高(见表6)
消融研究
1、PCL的影响
λ来平衡一致性和分类损失,通过设置λ=0,我们禁用了PCL,并获得了一个等效于vanilla ResNet-34的网络架构,具有二进制分类损失。
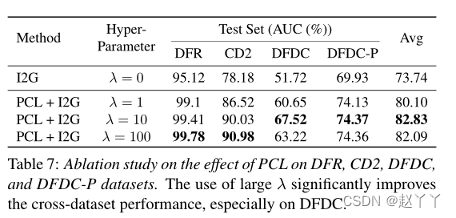
结果表明,在训练过程中使用大的λ是有益的,这也表明PCL在成功中起主导作用。
2、I2G联合训练的效果
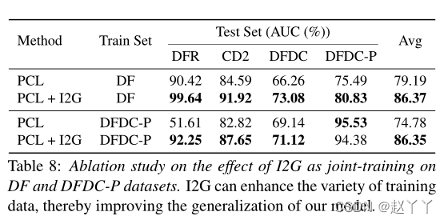
I2G可以增强训练数据的多样性,从而提高我们模型的通用性。
3、I2G预训练的效果
当计算deepfakes的DSSIM掩码都不可行时,可以使用一致性损失用I2G增强的任何真实数据来预处理模型。之后,可以对整个数据集进行深度伪检测或相关任务的任何标准训练。
进行了一项实验:首先对由I2G增强的DF的真实数据进行了ResNet-34预处理,以进行一致性预测,并对DF的真实和伪数据进行了微调以进行分类。DFR、CD2、DFDC、DFDC-P的评估结果,AUC分别为99.57%、91.88%、68.95%、79.17%(平均84.89%)。这些结果毫不奇怪地低于联合训练的结果,但仍显著优于基线(平均79.19%)。此外,我们的预训练模型可能不一定是从已建立的deepfake数据集训练的。I2G可以潜在地应用于任何人脸图像或视频数据集,如IMDb人脸和Y ouTube人脸[,为深度假相关研究提供了更强的预训练模型。
4、补丁大小的选择
较大的补丁会得到更粗糙的一致性图,降低其伪造检测的效率。较小的补丁可能不会包含足够的源特征信息,并导致额外的计算成本。评估了表4中的交叉数据集模型,FF++上的补丁大小为4×4、8×8、16×16和32×32,AUC分别为98.32%、98.35%、99.11%和98.74%。
定性结果
PCL不仅改进了深度伪检测的表示学习,而且可以生成修改区域的可解释可视化线索

使用在交叉数据集中通过I2G增强的FF++真实视频训练的模型,并根据预测的一致性卷计算预测,ground truth修正区域由DSSIM生成。
当输入真实图像时,在大多数情况下,可视化是纯空白图像,表明输入的源特征是一致的。在测试deepfakes时,预测的一致性图可以充分匹配地面真相。我们还从真实图像中计算一致性体积的平均值,并分别使用内部和交叉数据集模型获得0.9854和0.9866。
PCL预测正确预测样本的一致性卷中的所有条目与高平均置信度一致,而不是简单地分割整个面部区域。
对于错误案例,可能是由照明和异常纹理造成的,由于高压缩或高/低曝光,低质量的样本会导致错误的负面预测。
局限性
1、对于全脸合成训练了一个直接输出整个图像的生成模型,该模型是自一致的,PCL是否能够处理这种类型的面部伪造是未知的。
2、在低质量数据上可以进一步改进
附录
Celeb-DF-v2上的帧级结果
将本文的模型与其他最先进的方法在CD2上的帧级AUC方面进行了比较,所有模型都在跨数据集设置下进行训练,即在FF++上接受训练,在CD2上进行评估
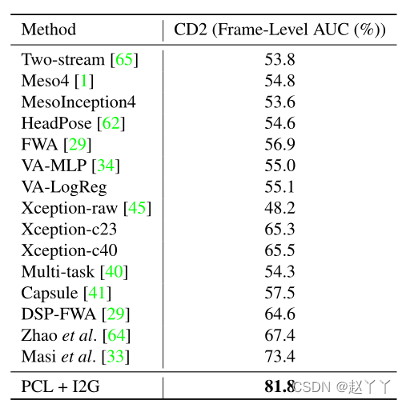
计算复杂性
大小为H/P×W/P×C的源特征图中大小为C的每个向量对应于输入图像中的P×P块,P是下采样因子。
PCL额外的计算包括:(1)用O(CC’HW/P2)触发器将特征图嵌入尺寸为H/P×W/P×C’
(2)用O(C’H2W2/P4)触发器计算成对一致性。在实际中,使用H=W=256、C=256、C0=128、P=16和ResNet-34作为主干,PCL在一个具有16GB内存的NVIDIA Tesla V100 GPU上运行,为单个图像的前向传递贡献了48.12M FLOP、65.5K参数和0.0009秒,总计9.62G FLOP、21.3M参数和0.0234秒。
一致性映射生成
对于可视化,假定有每一个图像上有两种源特征组,左上图像的补丁属于组0,不相似的补丁属于组1。
对于具有h*w一致性得分矩阵 的(h,w)处的补片,我们得到一个软组分配,作为其与左上补片
的(h,w)处的补片,我们得到一个软组分配,作为其与左上补片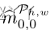 的余弦相似性。通过平均
的余弦相似性。通过平均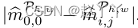 来计算一致性图中该补丁的相应灰度值,通过这种方式,可视化中的相似灰度值表明相应的补丁可能属于同一源特征组。
来计算一致性图中该补丁的相应灰度值,通过这种方式,可视化中的相似灰度值表明相应的补丁可能属于同一源特征组。
不同的主干
采用ResNets作为主干,从ResNet-18到ResNet-50,性能显著提高,继续深入,性能会降低
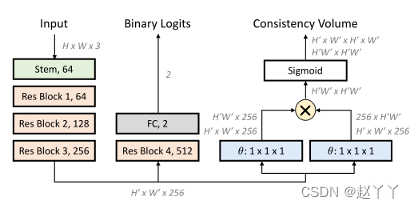
PCL架构,其实采用ResNet-34作为主干
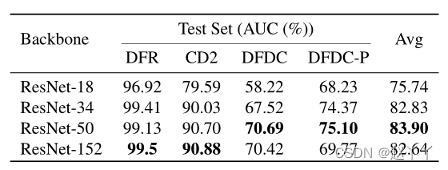
其中,λ = 10














 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









