







写在前边
科研小白,写下来有助于理解以及以后学习使用。介绍了一些pytorch的resnet50 掉包,以及VGGFACE上预训练过的resnet50模型的迁移学习过程。
目录
1.网络详细结构图
在没有用代码实现之前,我对网络的结构的认知一直停留在论文中的结构图,如下图所示:
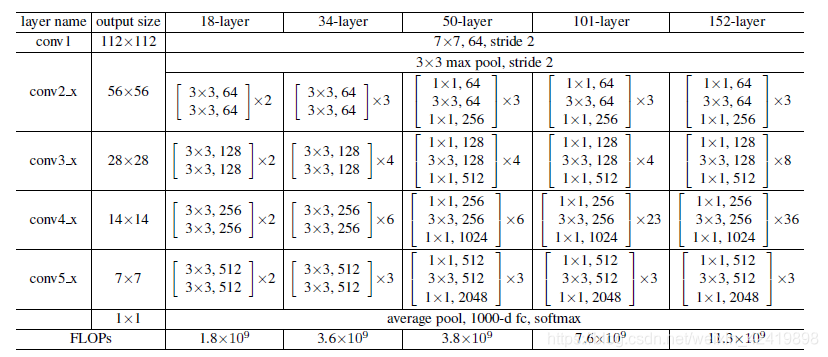
由于最近想要借助Resnet_50网络进行迁移学习的训练,所以在编码层又对网络进行了相关认识和学习,其实整个网络详细并且清晰的结构图如下图,根据这个结构图就可以完成代码的编写,在文章的最后一部分也是会展示一些代码。希望这个结构图能让和我一样的小白,能够在编码层有所认知(哈哈哈哈,不迁移学习的时候我也是想要掉包的,但是由于迁移学习过程中要进行一定的网络改写和调用-_-wuuuuu)。
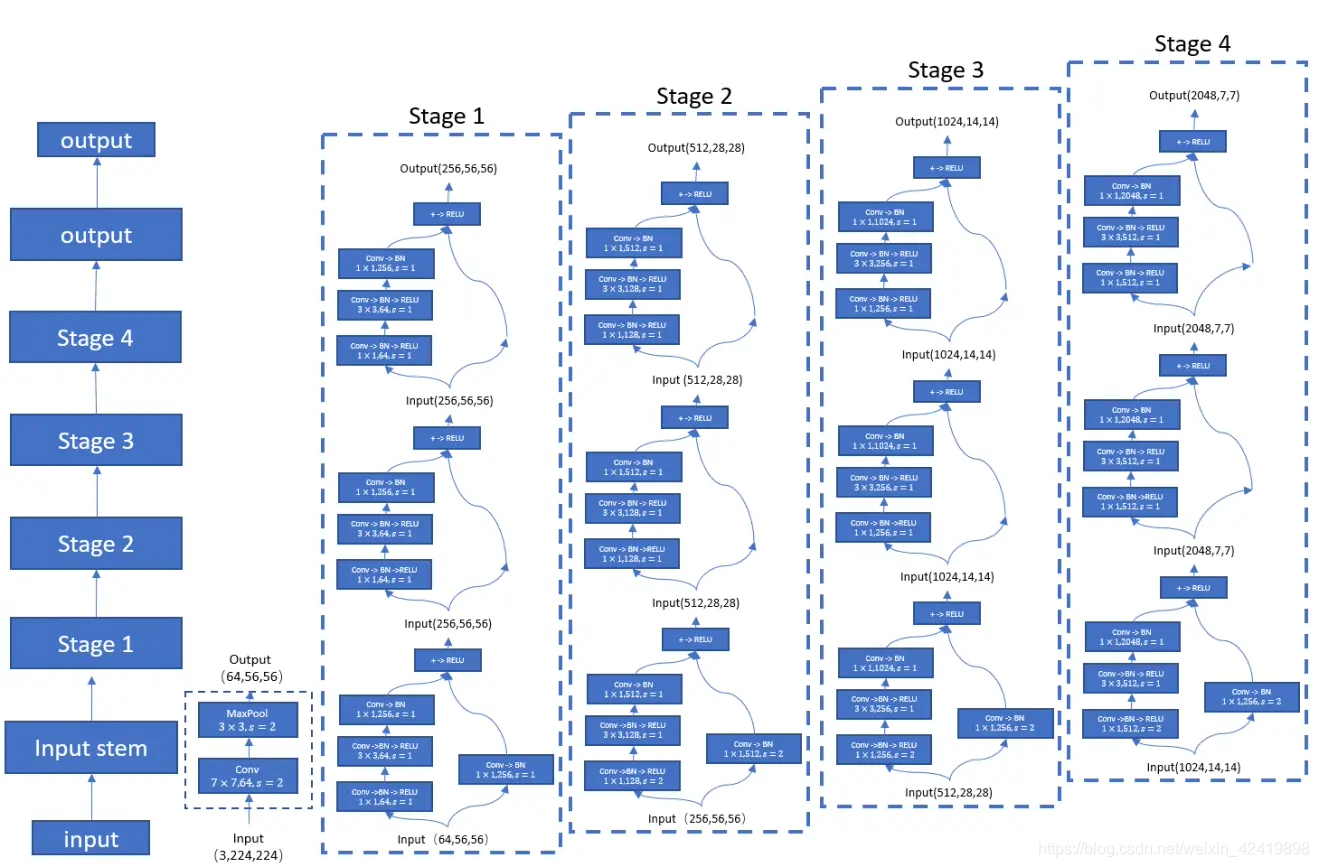
图片来源:https://www.bilibili.com/read/cv2051292,其实仔细看的话,可以发现这个图是有问题的。1-4层并不都是三层的,层数应该是[3,4,6,3]。
2.网络原理
因为在不断增加卷积层的过程中,会出现各种的问题,残差网络主要解决了两个问题:
1.解决梯度的问题,添加正则化层(Batch Normalization),借助初始的正则化和中间的正则化层。基本的说:BN层即将每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
2.网络退化的问题,如果堆砌的网络间为恒等映射(即 f (x)=x),那么网络就退化成一个浅层网络。其实要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
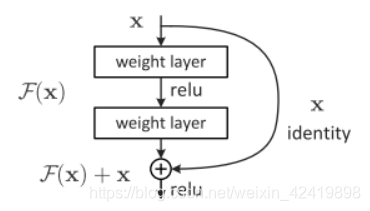
其实整个残差网络就是在没增加复杂度的情况下,提升各个层的效果,防止梯度爆炸的同时,实现端到端的反向传播训练。
3.pytorch实现网络
本部分,我想通过两种情况介绍网络的实现部分。一部分就是快乐的掉包,这一部分就借鉴pyrotch API的内容进行编写,一部分就从我现在经历的迁移学习(借助已经预训练过的模型进行fine-training)来进行简单的介绍:
1.快乐的调包
torchvision.models.resnet50(pretrained=False, progress=True, **kwargs)这是pytorch API中的定义好的model,其中的pretrained是在imageNet数据集上进行的。如果progress为True,则显示下载到stderr的进度条。要说明的是,这个语句第一次运行的时候需要一些时间,因为需要下载模型。其实从我个人的角度来说,这种直接使用的情况不是很多,下面我们主要的来看一下迁移学习。
2.迁移学习
这里以我现在正在使用的VGG FACE2上的预训练模型为例,进行相关的说明。首先,找到相应的模型和对应的预训练的权重(奉上下载链接:https://www.robots.ox.ac.uk/~albanie/pytorch-models.html),下载之后就可以看到和上边的结构图一样详细的resnet 50 网络的代码:
class Resnet50_ferplus_dag(nn.Module):
def __init__(self):
super(Resnet50_ferplus_dag, self).__init__()
self.meta = {'mean': [131.0912, 103.8827, 91.4953],
'std': [1, 1, 1],
'imageSize': [224, 224, 3]}
from collections import OrderedDict
self.debug_feats = OrderedDict() # only used for feature verification
self.conv1_7x7_s2 = nn.Conv2d(3, 64, kernel_size=[7, 7], stride=(2, 2), padding=(3, 3), bias=False)
self.conv1_7x7_s2_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv1_relu_7x7_s2 = nn.ReLU()
self.pool1_3x3_s2 = nn.MaxPool2d(kernel_size=[3, 3], stride=[2, 2], padding=(0, 0), dilation=1, ceil_mode=True)
self.conv2_1_1x1_reduce = nn.Conv2d(64, 64, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_1_1x1_reduce_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_1_1x1_reduce_relu = nn.ReLU()
self.conv2_1_3x3 = nn.Conv2d(64, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1), bias=False)
self.conv2_1_3x3_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_1_3x3_relu = nn.ReLU()
self.conv2_1_1x1_increase = nn.Conv2d(64, 256, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_1_1x1_proj = nn.Conv2d(64, 256, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_1_1x1_increase_bn = nn.BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_1_1x1_proj_bn = nn.BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_1_relu = nn.ReLU()
self.conv2_2_1x1_reduce = nn.Conv2d(256, 64, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_2_1x1_reduce_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_2_1x1_reduce_relu = nn.ReLU()
self.conv2_2_3x3 = nn.Conv2d(64, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1), bias=False)
self.conv2_2_3x3_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_2_3x3_relu = nn.ReLU()
self.conv2_2_1x1_increase = nn.Conv2d(64, 256, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_2_1x1_increase_bn = nn.BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_2_relu = nn.ReLU()
self.conv2_3_1x1_reduce = nn.Conv2d(256, 64, kernel_size=[1, 1], stride=(1, 1), bias=False)
self.conv2_3_1x1_reduce_bn = nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv2_3_1x1_reduce_relu = nn.ReLU()
self.conv2_3_3x3 = nn.Conv2d(64, 64, kernel_size= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3117
3117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









