







一、数据
深度学习的数据用于训练模型、验证模型与测试模型,其中涉及到了训练数据 、验证数据与测试数据。
1.验证数据与测试数据的讨论
从模型训练完整流程的角度来讲,其包括了训练-验证-测试三个阶段。但对于大多数模型训练者来讲,仅进行训练与验证是很常见的操作。验证集作为评判模型训练效果的工具,可以帮助训练者调整模型各种超参数。那么测试时期使用的测试集的作用又是什么呢?它与验证集有什么不一样呢?
与验证集类似,测试集也是用于衡量模型目前训练效果的工具。但是其更加凸显模型的泛化能力,不可以用于调参。可是这是为什么呢?
可以这样理解,当模型用训练集学习时,其实是在不断地调整,目的是学着去拟合训练集的特征,当模型在训练集上表现很好时(大部分模型的表现好是指误差很低,准确率很高,但是也有模型具有其他的衡量标准,具体任务具体分析),表示模型的参数对这些特征拟合很不错。
随后,使用训练好的模型在验证集上校验,去探究这些已经调整好的参数是否对于除了训练集以外的数据也有较好的效果,而不是仅仅针对训练集有较好的效果呢?此时若发现模型在验证集上的效果不是很好,则有理由怀疑模型在训练集上学习到了太多没必要的特征(比如图片中的噪声点)。此时训练者可以通过调整超参数或采用其他措施来重新训练模型,例如改变学习率等,然后使用新的模型重新在该验证集上验证。通过不断验证不断调参,最终使得模型不仅仅在训练集上表现好,在验证集上表现也很棒。此处其实也可以理解为,当模型通过调整超参数,不断逼近验证集上的准确率时,其实也是在不断地去拟合验证集数据上的特征。那么,若模型在训练集上与验证集上都得到了较好的结果时,就表明该模型具有较好的泛化能力了吗?换句话说,此时的模型对于训练集与验证集以外的数据就有较好的表现效果吗?
为了探究上述问题的答案,训练者还需要准备一个测试集,来验证模型的真实效果,也就是泛化能力,即对于未验证过的数据是否具有较好的表现效果。若模型在测试集上表现不佳,则说明模型对于验证集其实也是过拟合的,即哪怕经过训练集与验证集的考验,模型仍旧学到了一些多余的东西,此时训练者就需要再次调整模型。
经过此次调整后,模型需要在一个新的测试集上测试性能。为什么不能像验证集一样重复利用数据呢?因为若利用了重复的测试集,就像是又重新构建了另一份验证集,模型不断逼近该测试集,哪怕在该测试集上得到了较好的结果,但仍有可能也仅仅针对训练集、验证集以及该组测试集达到了拟合,对除此之外的数据仍旧是达到了过拟合的效果。因此当测试集仅仅作为测试泛化能力的数据时,其为了避免再次出现过拟合,需要不断使用新数据。
| 验证集 | 测试集 | |
| 作用 | 通过评估训练后的模型效果帮助模型调整参数 | 验证模型的泛化能力 |
| 使用次数 | 模型每次训练时可以重复使用 | 一次 |
2.batchsize
根据此篇知乎文章可以知道随机梯度下降算法(SGD)的公式为:
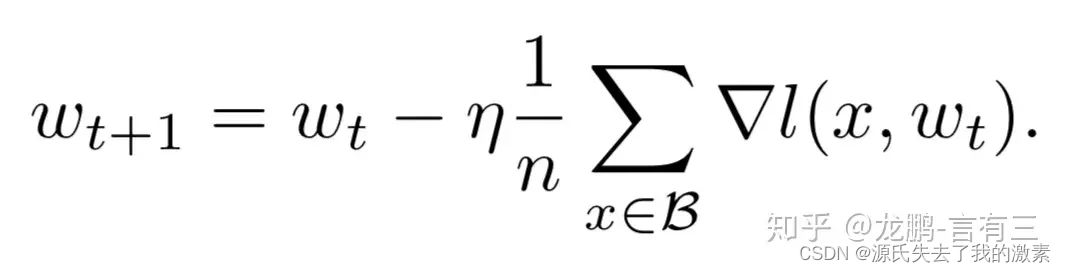
n是批量大小(batchsize),η是学习率(learning rate)。可知道除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看它们是影响模型性能收敛最重要的参数。
总结来看,上文讲到,大的batchsize会降低batch的值,因此可以加快训练速度。同时,大的batchsize梯度计算会更加稳定,有利于曲线的平滑。但是当batchsize过大时,模型收敛到sharp minimum,而小的batchsize收敛到flat minimum,后者具有更好的泛化能力。
造成这个现象的主要原因是大的batchsize性能下降是因为训练时间不够长,而小的batchsize带来的噪声有助于逃离sharp minimum。因此,batchsize的变大也具有一个临界值。
二、优化器
优化器是用来计算梯度并且更新模型结构参数的工具,使得参数逼近或者达到最优值,最优值指loss达到最小的值,可以参考梯度小节中的极小值位置。不同的优化器对应不同的处理原理。
1.梯度
官方对于梯度的解释为:表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。总之,是损失函数在这个参数上的偏导就对了。 优化器的目的就是找到loss极小值,即对于参数的偏导是0或者接近0的位置。
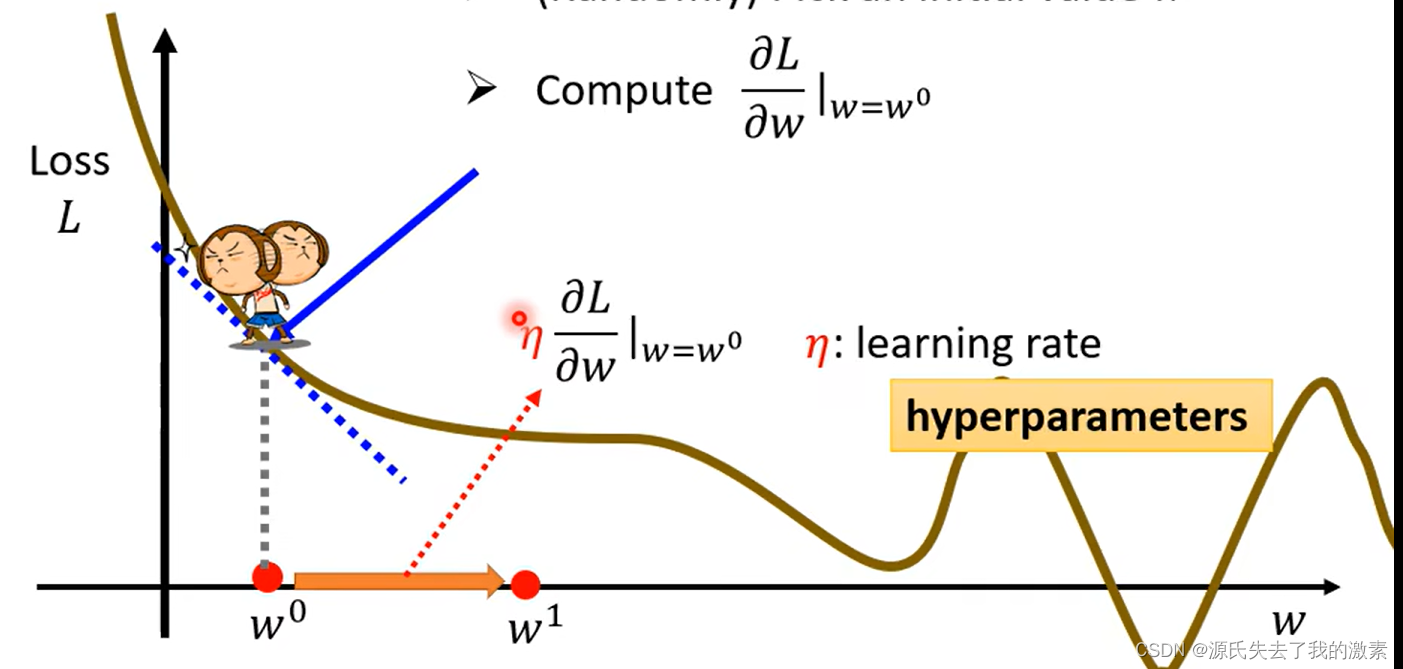
简单来说明,下图中L为损失函数loss,w为参数,w0为具体的某个参数。蓝色虚线表示的是损失函数对w0的偏导线,优化器需要沿着导线方向更新参数,因为这样参数可以以最大的变化率更新参数值。

优化器的变化方向是loss值变小的方向,也就是常说的梯度下降因此优化器需要向右沿着导线方向更新参数w0.
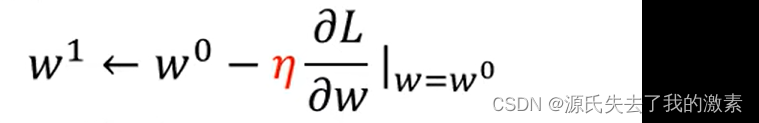
下图中的蓝色虚线是下降趋势,也就是说偏导数是负值,那么此时优化器就将向右增大w0,若蓝色虚线是上升趋势,那么就说明偏导数是正值,则优化器会向左减小w0.那么变化的幅度是多大呢,此时就需要学习率来决定前进的步伐大小了。
2.动量
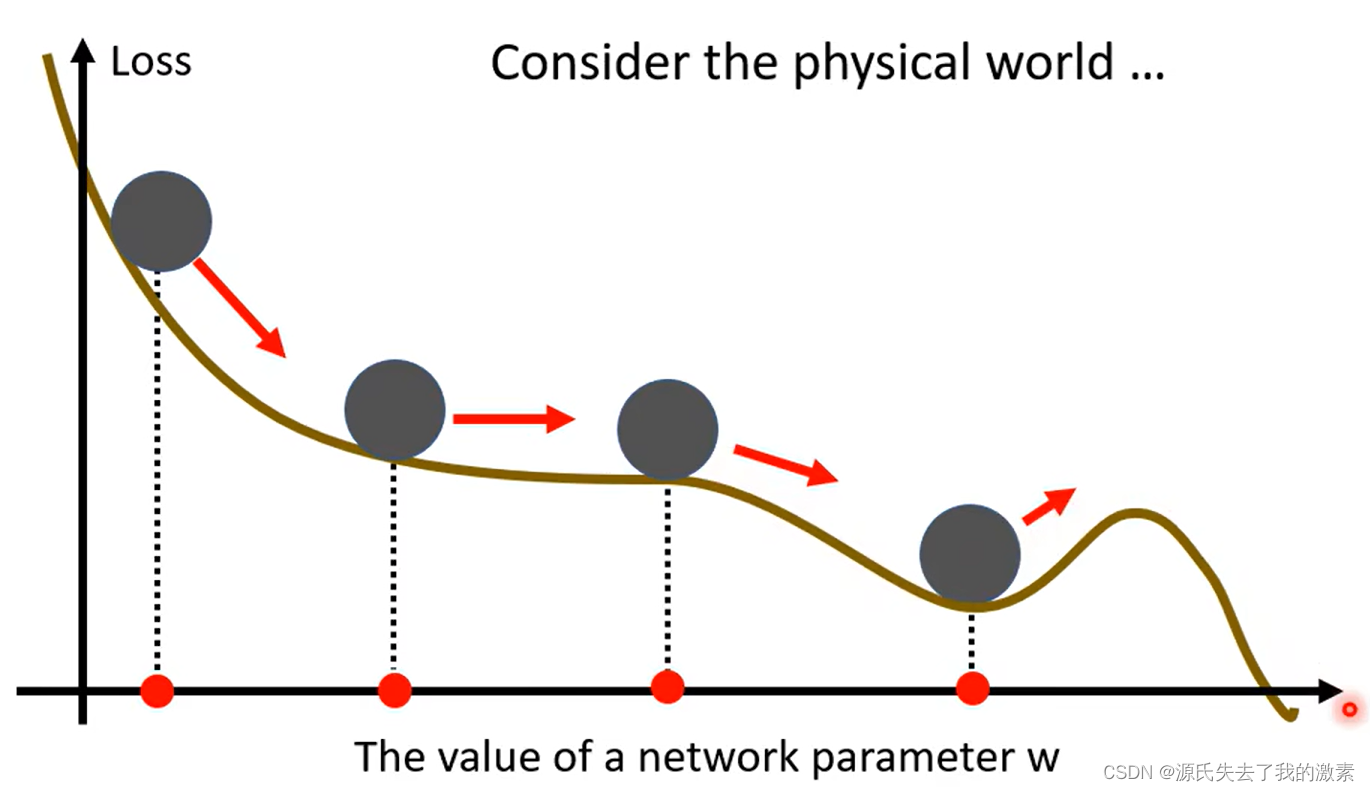
动量可以先理解为“惯性”,上图的损失曲线可以看作是山坡,在现实世界中,小球滚下来带有惯性,因此,哪怕小球到了上图的低洼处(极小值点),其依旧可以依靠惯性向又移动,如果惯性够大,其有可能翻越右边的山峰(极大值点)。
那么在学习率中同样可以考虑此概念,在学习率变化中,惯性变成了动量。下图表示此时损失函数在θ0处的梯度也就是导数是g0(红色箭头)。由于还没有移动,因此动量(惯性)m0为0.

秉承着梯度下降的思想,此时,目标函数的变化应该为梯度相反的方向即蓝色实线方向,到达θ1,则该行为产生了动量m1(先忽略公式)。(此处的蓝色实线既表示目标函数变化方向,也表示动量方向,不必过分纠结)

同样地,在θ1出计算出目标函数在此处的梯度为g1,则仅考虑梯度下降时,参数应当向右变化,目标函数的变化应当遵循红色虚线方向。

可是此时由于存在动量m1,因此还应该考虑动量带来的影响,即蓝色虚线方向。
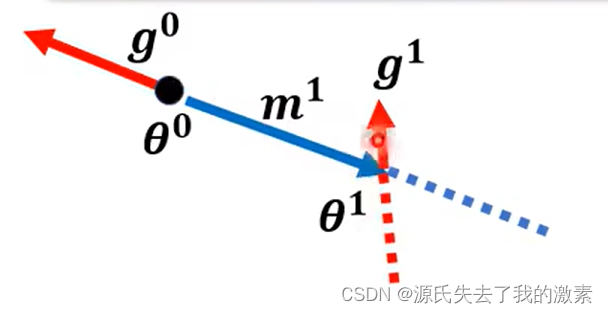
因此,处于梯度下降与动量的双重影响,此时,目标函数的变化方向应为新出现的蓝色实线,并产生动量m2,到达θ2.
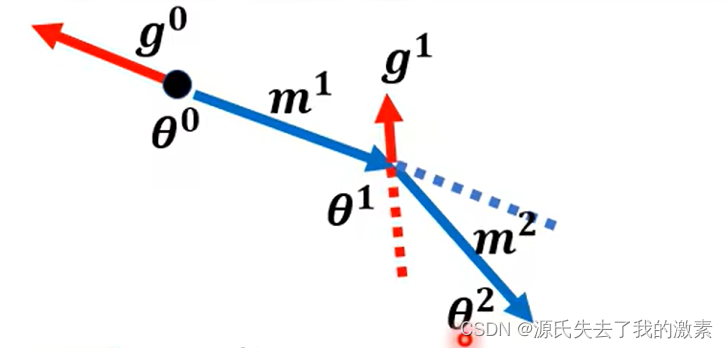
经过上述流程可以发现,当前的目标函数与参数行为不仅仅受到了当前梯度的影响,同时也受到了之前梯度的影响。

此时再看公式,其中拉姆达为动量系数,η为学习率,将m2的公式展开,可以观察到下图公式,进一步解释了当前的目标函数与参数行为不仅仅受到了当前梯度的影响,同时也受到了之前梯度的影响。
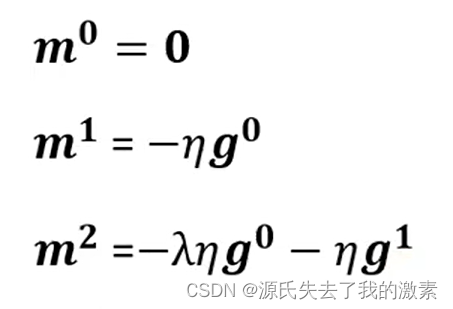
那么可以将动量公式概括为
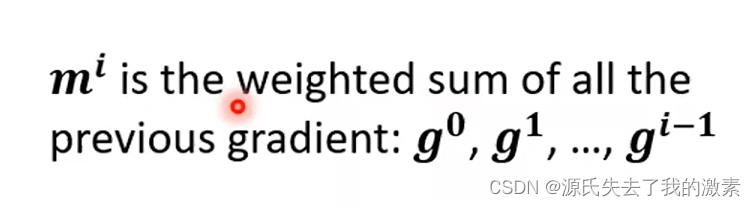
回到曲线图,假设现在经过动量与梯度下降的助力,目标函数与参数达到了局部最优解的状态,此时梯度为0:
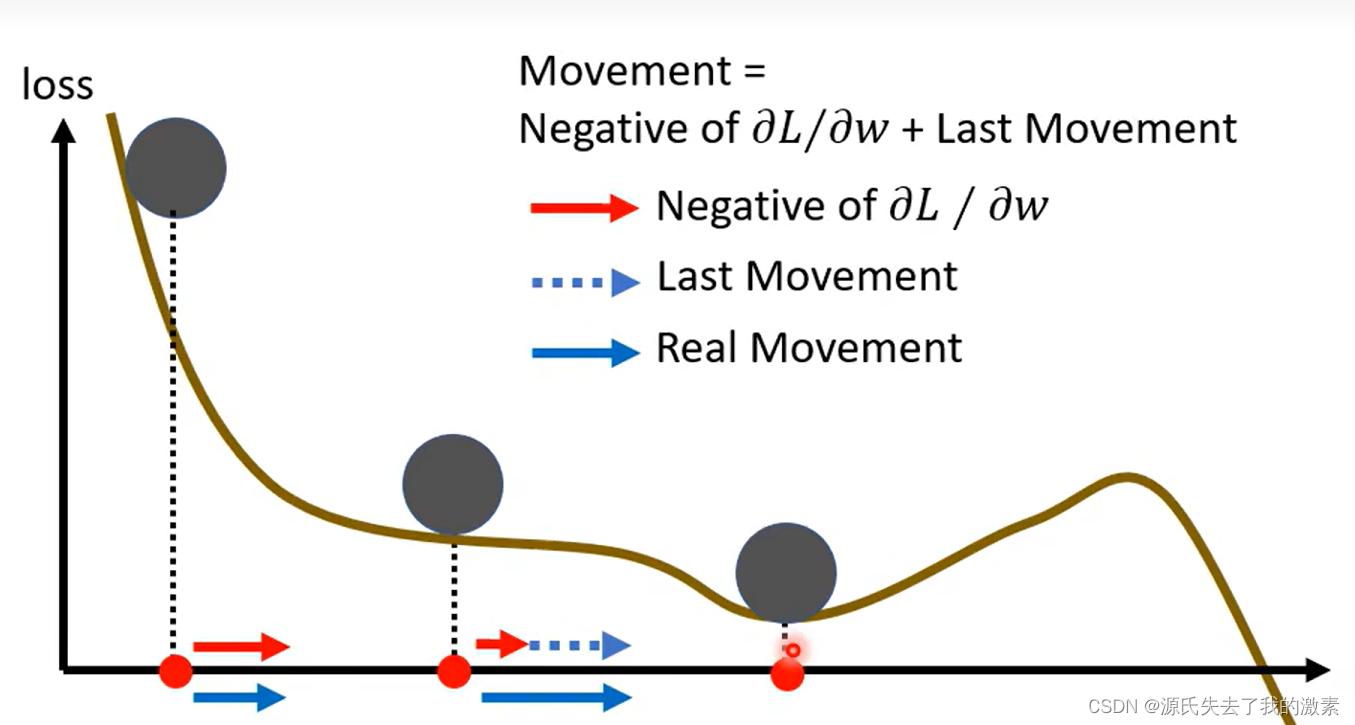
但是由于动量的存在,参数与目标函数可以继续超着右侧变化:
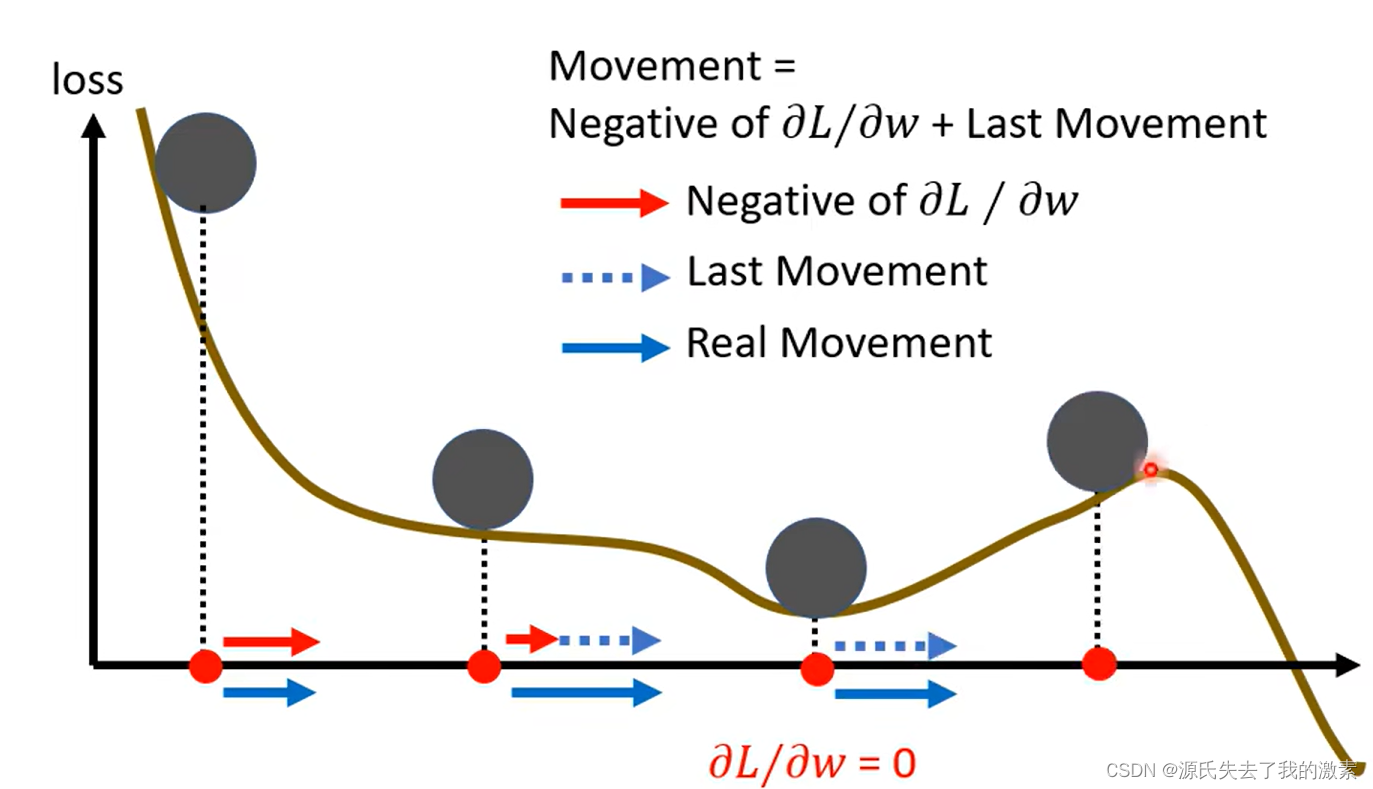
甚至在右侧时,梯度下降的方向变为向左,但是若此时动量较大,仍会使得目标函数与参数向右变化,不会仅仅跟随梯度下降的方向改变:
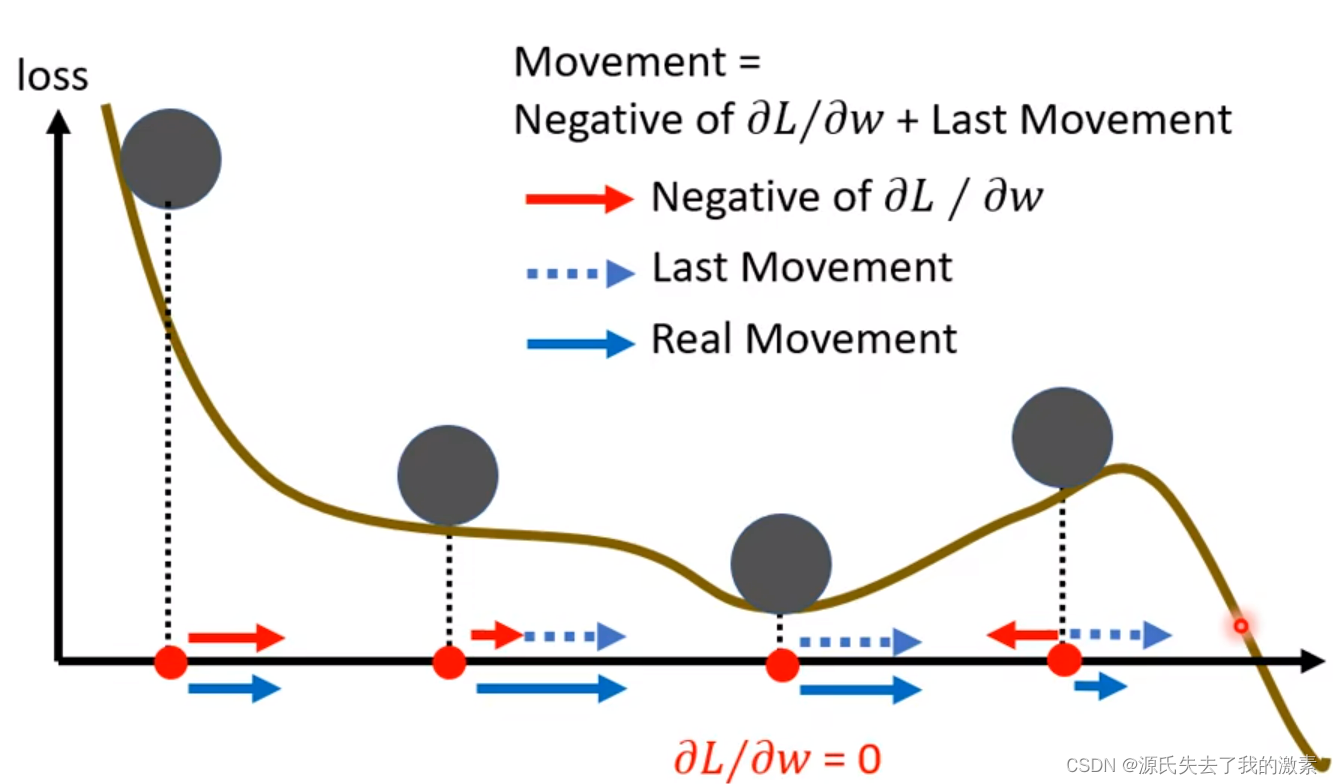
作用:经过上面的描述,那么动量有什么用呢,那就是可以辅助模型走出局部最优点或者鞍点,尽量去寻找更好的最优点。
3.SGD(Stochastic Gradient Descent)随机梯度下降算法
参考: 梯度下降法(SGD)原理解析及其改进优化算法 - 知乎
注:上面知乎的参考方法在batchsize处描述有误,但是对于SGD的解释比较便于理解。要了解SGD的原理,看其中的一、二、就够了。
在pytorch中,使用SGD直接调用封装好的方法即可。其中,parameters模型参数,lr为初始学习率,momentum为动量值,一般情况动量值下比较接近1,例如0.8、0.9等,但还是应当视任务情况而定。动量值越接近1,表示之前梯度的影响就越大。
import torch.optim as optim
# SGD优化器
optimzier = optim.SGD(parameters, lr, momentum)
4.SGDR(SGD+余弦退火)
参考:Cosine Annealing Warm Restart - 知乎
注:该知乎文章简单介绍了SGDR是如何被提出的,最好看之前对余弦退火学习率策略以及SGD的原理有所了解
一些大规模训练集使用的优化器其实并非adam等,而是仍旧延续了经典的SGD,相应的学习率是采用梯度下降的策略,即每个固定的间隔便成一定比例下降。但是在论文《STOCHASTIC GRADIENT DESCENT WITH WARM RESTARTS》中,作者提出了一种带有热重启的SGD,该策略可以减少训练次数,加快训练速度,并有助于提升精度。
带有热重启的SGD,简称SGDR,其实是使用了余弦退火学习率变化策略(Cosine Annealing Warm Restart)与SGD优化器的方法。
在pytorch中使用SGDR,直接使用SGD以及Cosine Annealing Warm Restart方法即可:
from torch import optim
from torch.optim import lr_scheduler
model, parameters = Creat_model(opt)
#优化器
optimizer = optim.SGD(parameters , lr, momentum)
#学习率策略
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult, eta_min, last_epoch)















 2943
2943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









