









通过阅读本文将了解以下知识:
- 预训练任务 MLM 和 NSP 是什么?
- BERT 模型的输入和输出,以及一些与 Transformer 不同的地方。
- 以 BERT BASE \text{BERT}_\text{BASE} BERTBASE 为例,计算模型的总参数量。
…
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin et al. | arXiv 1810.04805 | Code - 官方 Tensorflow | NAACL 2019 | Google AI Language
学习 & 参考资料
前置文章
机器学习
—— 李宏毅老师的 B 站搬运视频
论文逐段精读
—— 沐神的论文精读合集
3Blue1Brown
—— 顶级的动画解释
可视化工具
观察 Self-Attention 的中间过程。
需要注意的是网页端演示的不是传统的 Transformer 架构,而是 GPT-2(Decoder-Only),不过 BERT 的架构中也包含 Self-Attention,通过 GPT-2 理解相同的部分是完全足够的。
写在前面,在对 BERT 有了基础认知之后,可以尝试这份作业:BERT 微调抽取式问答。
前言
在计算机视觉(Computer Vision, CV)领域,很早就开始利用卷积神经网络(Convolutional Neural Network, CNN)在大型数据集上进行预训练(Pre-training),然后迁移到其他任务中提升性能。但在自然语言处理(Natural Language Processing, NLP)领域,长期以来并没有类似的通用深度神经网络模型,许多研究都是“各自为战”,为特定任务训练专属的模型,导致计算资源重复利用,研究成果难以共享,常常重复“造轮子”。
Transformer 架构的提出为 NLP 带来了新的可能,BERT 的出现更是彻底改变了 NLP 的研究格局。BERT 将 Transformer 架构从翻译任务推广到了其他的 NLP 任务,并刷新了 11 项任务的 SOTA(State of the Art),证明了其架构的通用性和有效性,同时开启了预训练语言模型(Pre-trained Language Models, PLMs)研究的浪潮,对整个领域产生了深远影响。
[!tip]
BERT 的名字来源于美国经典儿童节目《芝麻街》(Sesame Street)的角色。论文中对应的全称为 Bidirectional Encoder Representations from Transformer,即“基于 Transformer 架构的双向编码器表示”。是的,“硬凑名字”,类似地,BERT 的“前辈” ELMo(Embeddings from Language Models)1也是如此。“学术严肃与幽默并存” 😃
贡献
BERT 的主要贡献如下:
-
双向上下文建模(Bidirectional Contextual Representation)
过去的语言模型(如 GPT2)大多采用单向建模,即只利用从左到右的上下文信息来预测下一个词(token),无法充分利用句子的全局信息。BERT 引入掩码语言模型(Masked Language Model,MLM),随机遮掩输入序列中的部分词,迫使模型基于上下文来预测它(类似于完形填空),实现了深度的双向表征学习。
在此之前也有研究(如 ELMo1)将从左到右和从右到左两个单向模型的表示拼接在一起,以达到双向的目的,不过 BERT 对双向信息的利用更好。
-
预训练与微调框架(Pre-training & Fine-tuning)
BERT 是第一个使用预训练与微调范式在一系列 NLP 任务(句子层面和词元层面)都达到 SOTA 的模型,全面验证了该方法的有效性。
尽管这种思想并非由 BERT 首次提出,但却是因为 BERT 才广为人知。毕竟,谁不喜欢架构简单、模型开源、结果还 SOTA 的研究呢?截至 2024 年 11 月,BERT 的引用量已经超过 118K3,大量的研究以 BERT 为基础进行发展(摸着 BERT 过河)。
Q1: 什么是预训练(Pre-training)?什么是微调(Fine-tuning)?
- 预训练:利用大量无标注的数据,通过自监督学习(Self-supervised Learning)训练模型,使其学习通用的表示。
- 微调:在特定的下游任务(如文本分类、问答、命名实体识别)中,使用少量标注数据,对预训练好的模型进行进一步训练,使其适应特定任务的需求。
Q2: 什么是自监督学习?
自监督学习更像是介于无监督学习和有监督学习之间的概念,从数据上看,自监督学习的数据没有经过标注,从训练上来看,自监督学习又有着监督信号(伪标签)作为指导。它的核心思想是设计一个“代理任务”(Pretext Task),或者说人为的定义一些规则,从数据中自动生成“伪标签”来训练模型。
举一些实际的例子:
- 自然语言处理(NLP)
- GPT 的自回归模型:通过给定前面的词序列,预测下一个词(单向)。
- BERT 的 Masked Language Model(MLM):在输入文本中随机遮掩某个词,模型根据上下文进行预测(双向)。
- 计算机视觉(CV)
- 图像遮掩预测:遮掩图像的一部分,模型根据周围的像素信息预测被遮挡的区域内容。
- 早期的对比学习(Contrastive Learning):将同一图像的不同增强版本视为“正样本对”,不同图像视为“负样本对”。模型通过拉近正样本对的表示、拉远负样本对的表示进行学习。
Q3: 论文提到将预训练表示应用到下游任务有两种策略:基于特征(feature-based)和微调(fine-tuning),二者有什么区别?
摘自论文 Introduction 部分:
There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning.
The feature-based approach, such as ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features.
The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pre-trained parameters.
The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations.
基于特征(feature-based)方法:
- 预训练模型参数保持不变,将其视为固定的特征提取器。
- 预训练模型的输出作为下游任务的额外输入,可以直接与原始输入进行拼接。
- 下游任务可能设计了特定的模型。
微调(fine-tuning)方法:
- 预训练模型的参数在下游任务中继续更新,对预训练模型进行端到端的训练,论文中提到的是全量微调。
- 下游任务中,只需在预训练模型顶部添加少量的任务特定参数(如分类层)。
模型架构
前文提到,BERT 的创新之一在于其引入了双向建模,从单向过渡到双向这一说法似乎很自然,但更应该结合模型架构的演变时间线进行理解:
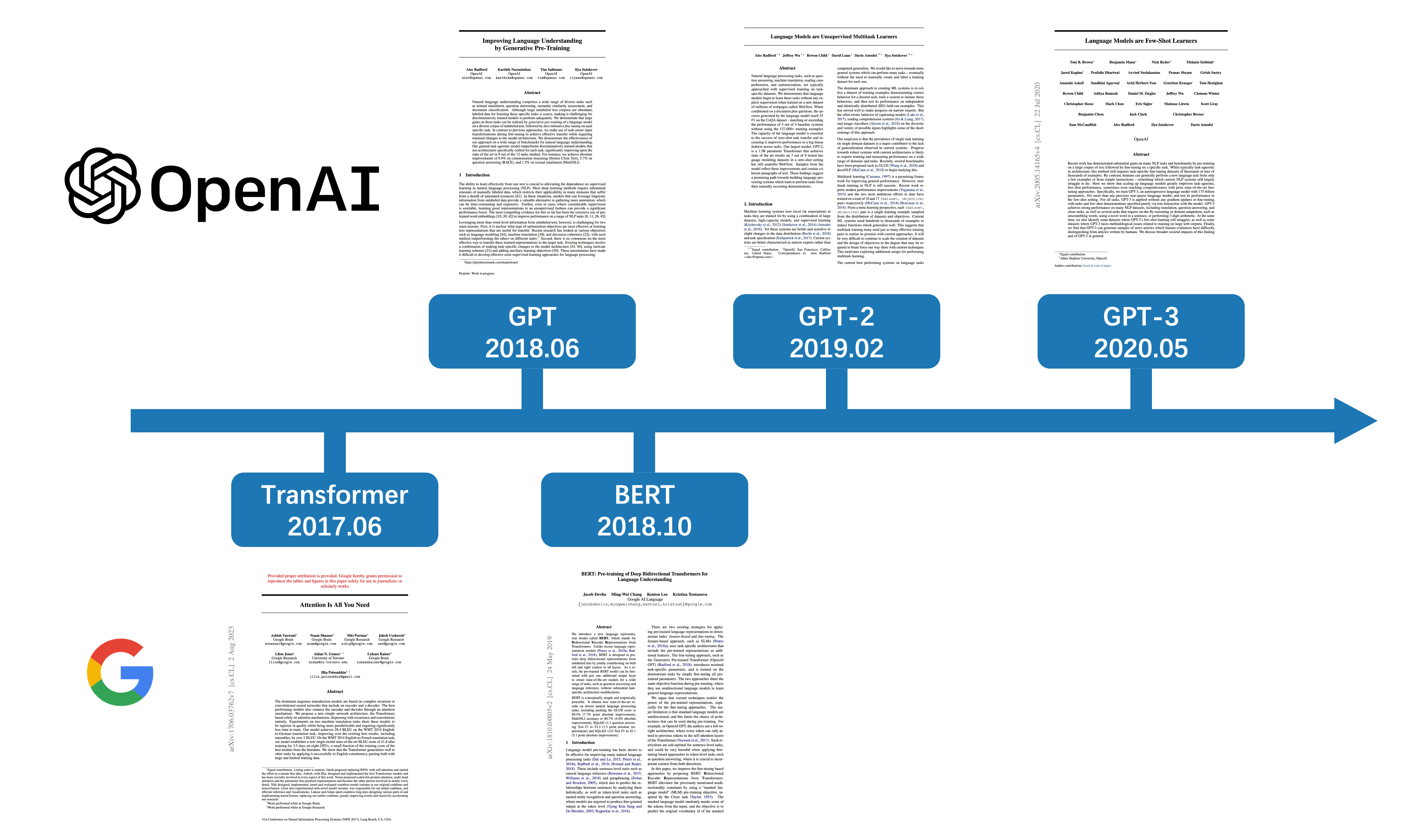
Transformer 原始架构由编码器(Encoder)和解码器(Decoder)组成。GPT 在 BERT 之前发表,仅用了 Transformer 架构的解码器(因此 GPT 也被称之为 “Decoder-Only” 模型),或许 BERT 正是受启发于 GPT,所以才用了 Transformer 架构的另一半:编码器(因此 BERT 也被称之为 “Encoder-Only” 模型)。
读到这里可能会有疑问:这能说明什么?
实际上,编码器和解码器在处理输入时的不同直接影响了模型是单向还是双向建模:
- 编码器(Encoder):
- 自注意力机制是双向的:输入序列不做额外处理,每个位置都可以关注到序列中所有其他位置的词(包括前面的和后面的)。
- 解码器(Decoder):
- 自注意力机制是单向的:通过对未来位置进行掩码,输入序列中的每个位置只能关注到它之前的词(从左到右)。
- 未来掩码:训练时,防止模型在生成当前位置的词时看到未来的信息(答案)。
- 自注意力机制是单向的:通过对未来位置进行掩码,输入序列中的每个位置只能关注到它之前的词(从左到右)。
因此,GPT 是单向模型,因为采用了解码器架构,从左到右生成文本;而 BERT 是双向模型,因为采用了编码器架构,能同时利用左侧和右侧的信息(上下文)进行建模。值得注意的是,所谓单向和双向建模,本质上取决于是否对输入序列添加未来掩码,编码器和解码器的实现机制实际上非常相似,详见 Transformer 的代码实现。
所以,与其说是从单向过渡到双向,不如说 BERT 选择了 Transformer 架构的编码器部分,来实现双向的表征学习。
| 模型类型 | 模型架构 | 代表模型 | 应用场景举例 |
|---|---|---|---|
| Encoder | 双向 | BERT | 文本理解 |
| Decoder | 单向(左到右) | GPT | 文本生成 |
| Encoder+Decoder | 双向(编码器)+单向(解码器) | Transformer | 文本翻译 |
如果并不了解 Transformer/Encoder/Decoder 是什么,推荐先阅读《Transformer 论文精读》。
输入处理
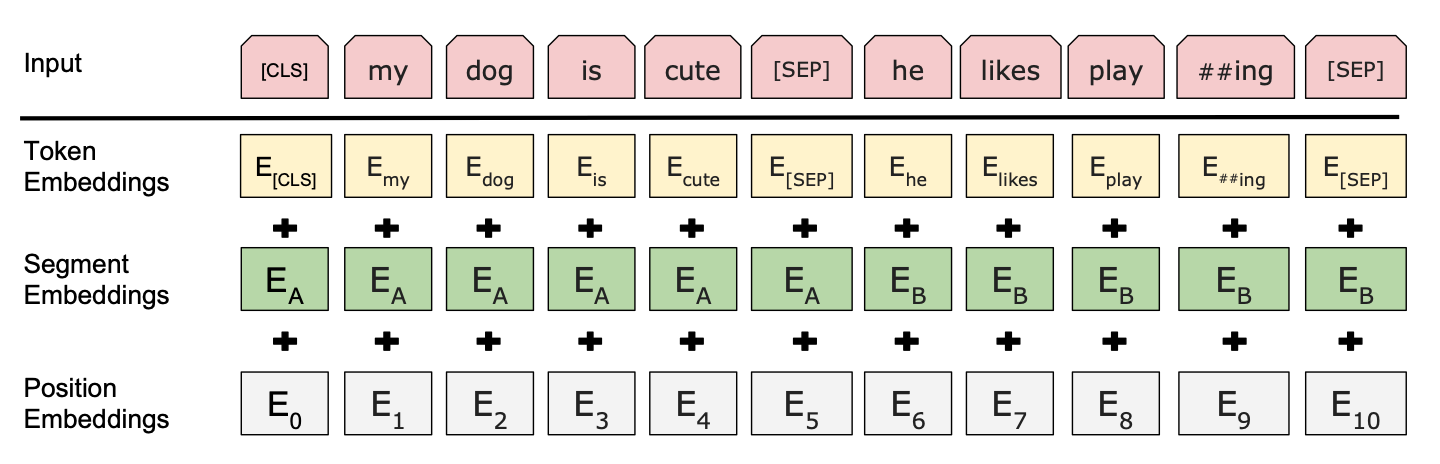
BERT 的输入由三个嵌入层组成:Token Embeddings、Segment Embeddings 和 Position Embeddings,和 Transformer 的不同之处在于,BERT 的位置嵌入是可学习的,并且多了分段嵌入。
-
Token Embeddings(词嵌入):
BERT 使用 WordPiece4 构造词汇表,将输入文本拆分为子词单元(subword units),每个子词最终对应一个嵌入向量。
对 WordPiece 感兴趣的同学可以进一步阅读《21. BPE vs WordPiece:理解 Tokenizer 的工作原理与子词分割方法》。
尝试 The Tokenizer Playground,选择
bert-base-cased: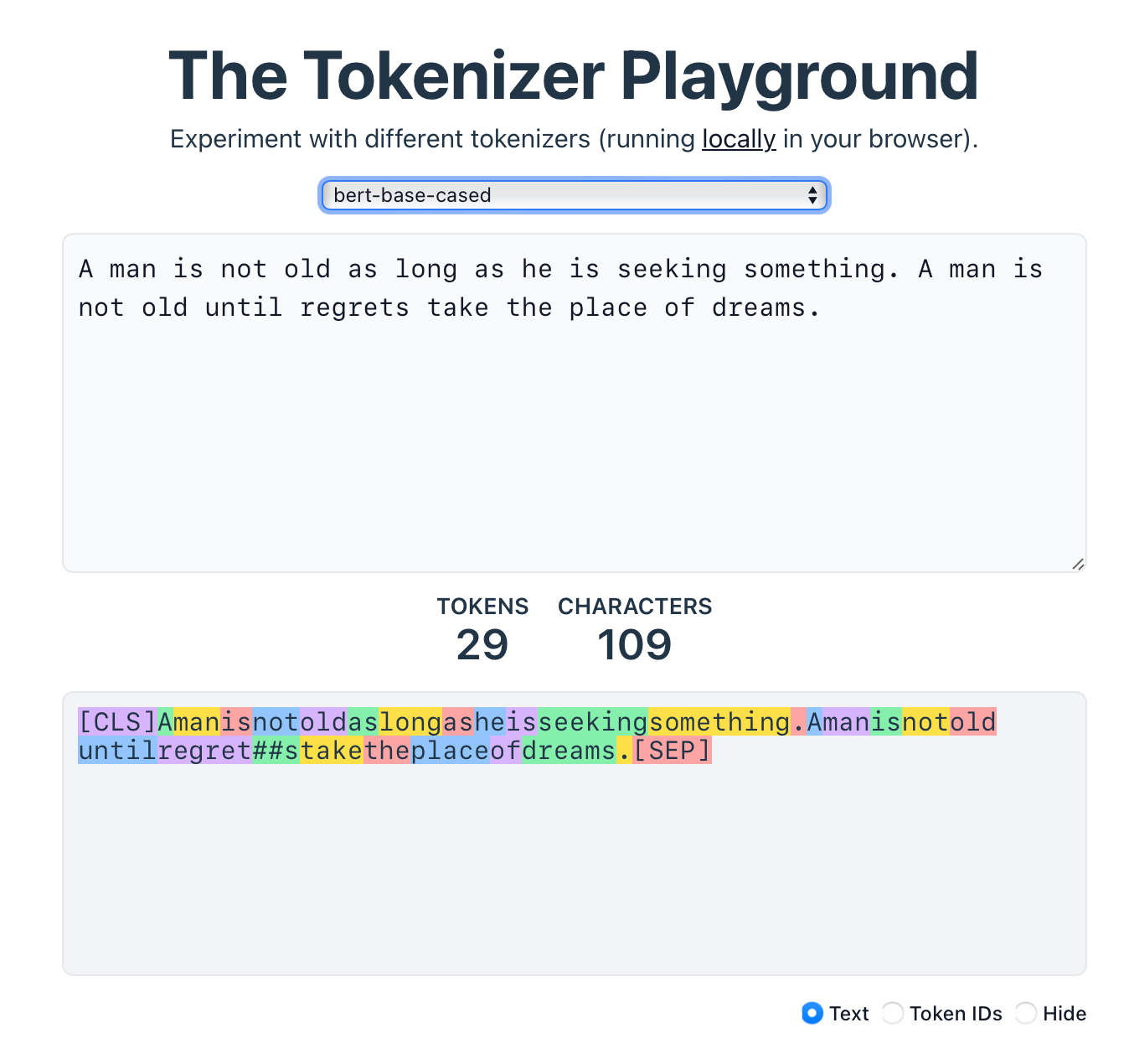
-
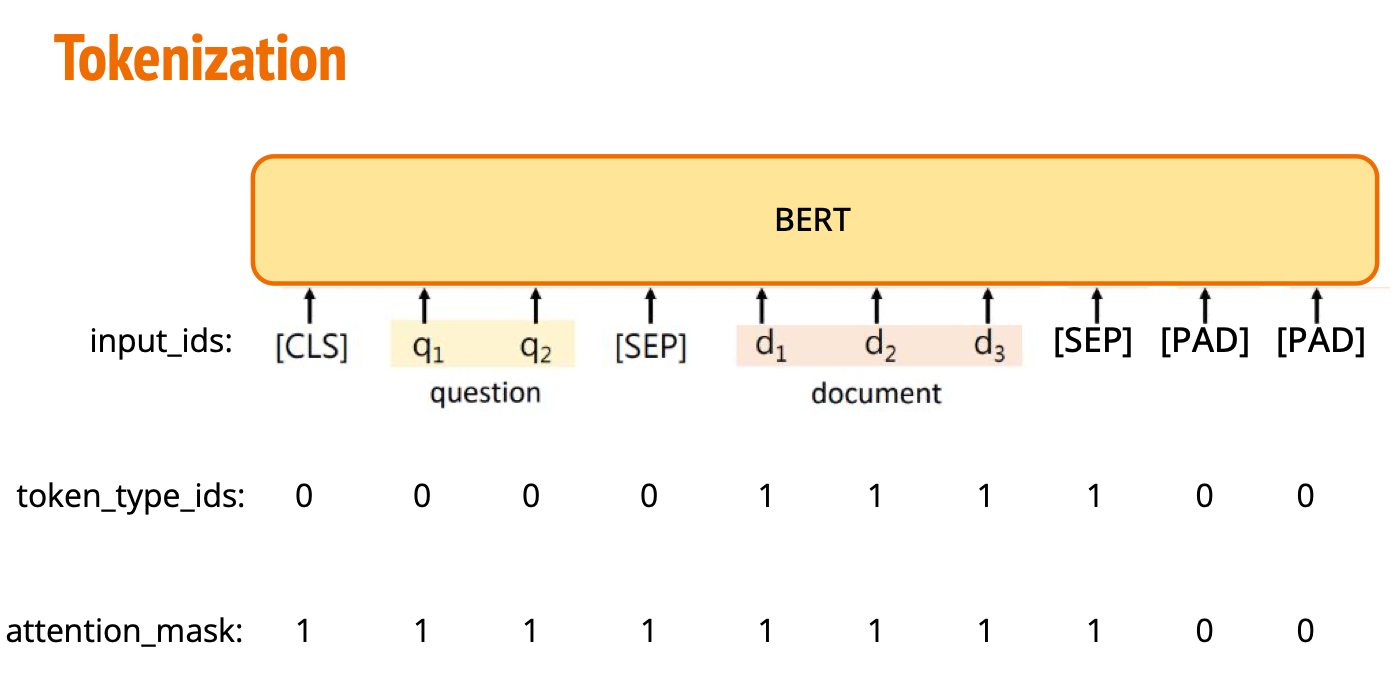
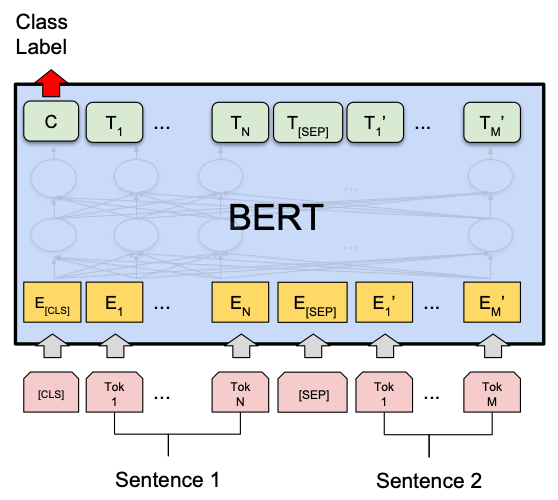
Segment Embeddings(段嵌入):
为了区分输入中的不同句子,每个词都会加上一个分段标识(Segment ID),标识它属于句子 A 还是句子 B。比如,句子 A 的 Segment ID 设为 0,句子 B 的 Segment ID 设为 1。
BERT 的官方代码中将这一概念称为词元类型 IDs(Token Type IDs),结合下图5来理解:
-
Position Embeddings(位置嵌入):
编码器本身无法直接感知输入序列的顺序,因此需要对输入数据进行额外的位置信息补充。BERT 通过添加可学习的位置嵌入帮助模型捕获序列的顺序关系。
另外,这里的嵌入层都是可学习的,接受的输入分别是 :
- Token ID(词元标识,用于映射词嵌入)
- Segment ID / Token Type ID(段标识,用于区分句子)
- Position ID(位置信息,用于捕获序列顺序)
可以通过拓展文章《g. 嵌入层 nn.Embedding() 详解和要点提醒(PyTorch)》进一步了解什么是嵌入层。
注意,这三个嵌入层相加后还需要过一次 Layer Norm 和 Dropout,见官方代码:
output = input_tensor
...
output += token_type_embeddings
...
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
训练细节
BERT 的训练包含两个步骤:预训练和微调。
预训练(Pre-training)
BERT 使用了两个预训练任务:
掩码语言模型(Masked Language Model,MLM)
随机遮掩输入序列中的部分词元(Token,标记),让模型根据上下文预测被遮掩的词元。
单向模型的任务很简单,就是预测下一个词。那么,有什么任务可以同时利用上下文的信息呢?
答:完形填空。
实现细节:
-
在每个训练样本中,随机选择 15% 的词元进行遮掩处理。
-
如果直接将选中的词元全部替换为
[MASK],会导致预训练和微调看到的数据会不一样,因为后续微调的时候的输入是没有遮掩的。为了缓解这个问题,BERT 对于被选中的词元采用了三种处理方式。假设句子为
my dog is hairy,在随机遮掩过程中选择了第 4 个词元(对应于hairy),具体的遮掩处理如下:-
80% 的情况下:将选中的词元替换为
[MASK],例如:
my dog is hairy → my dog is [MASK] -
10% 的情况下:将选中的词元替换为一个随机词,例如:
my dog is hairy → my dog is apple -
10% 的情况下:保持选中的词元不变,但模型依旧需要预测它,例如:
my dog is hairy → my dog is hairy此时输入和微调时看到的一样。
The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been re- placed by random words, so it is forced to keep a distributional contextual representation of every input token.
这个过程的优点是,Transformer 编码器不知道它将被要求预测哪些单词,或者哪些单词已经被随机单词替换了,因此它被迫保持每个输入标记的分布上下文表示。
注意:这里指的是已经决定要被遮掩的词元,即这三种情况是在被选择遮掩的 15% 中随机分布。其他的特殊词元不进行处理(
[CLS]和SEP)。 -
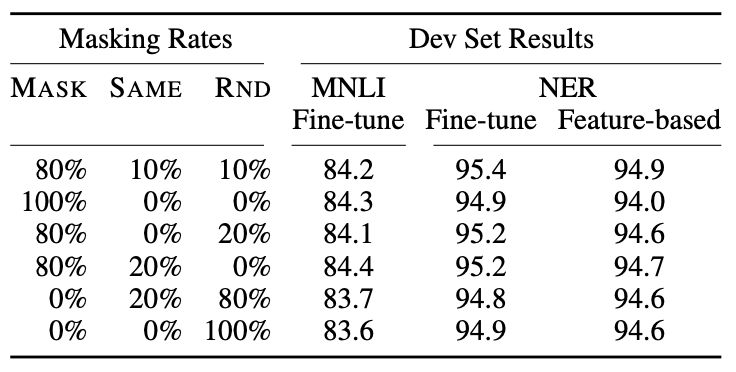
当前比例的选择依据表 8 的消融实验:
下一句预测(Next Sentence Prediction,NSP)
判断两个句子在原文中是否相邻。
实现细节:
-
50% 的训练样本为相邻句子对(标签为 “IsNext”)。
例如:
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] -
50% 的训练样本为非相邻句子对(标签为 “NotNext”)。
例如:
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
数据集
BERT 的预训练数据集包含大量未标注文本,主要来自:
- 书籍语料库(BooksCorpus6):包含超过 11,000 本英文小说的全文,约 8 亿词元。
- 英文维基百科(English Wikipedia):包含海量的高质量文本,约 25 亿词元。
论文指出应该用文档级别(Document-Level)的数据集而非随机打乱的句子(shuffled sentence-level corpus)。
超参数设置

BERT 的模型架构基于 Transformer 的编码器结构。需要注意的是,BERT 的 BASE 和 LARGE 模型的超参数设置并不对应于 Transformer 论文中的 base 和 big 模型。
-
BERT
BASE
\text{BERT}_\text{BASE}
BERTBASE
-
层数 L = 12 L=12 L=12:Transformer 编码器的层数。
-
隐藏层维度 H = 768 H=768 H=768:每个隐藏层的维度。
-
注意力头数 A = 12 A=12 A=12:每层的多头注意力机制包含 12 个注意力头,每个头的维度为 64, 12 ∗ 64 = 768 12 * 64 = 768 12∗64=768。
-
总参数量:约 110M(与 GPT 参数量差不多,方便对比)。
-
-
BERT
LARGE
\text{BERT}_\text{LARGE}
BERTLARGE
-
层数 L = 24 L=24 L=24。
-
隐藏层维度 H = 1024 H=1024 H=1024。
-
注意力头数 A = 16 A=16 A=16。
-
总参数量:约 340M。
-
Q: BERT 模型的参数量怎么计算?
模型参数来自以下几个部分:
-
嵌入层参数:
-
词嵌入(Token Embeddings):词汇表大小 V V V 乘以隐藏层维度 H H H, 即 V × H V \times H V×H。
self.embed = nn.Embedding(V, H) -
位置嵌入(Position Embeddings):最大序列长度 L seq L_{\text{seq}} Lseq 乘以隐藏层维度 H H H, 即 L seq × H L_{\text{seq}} \times H Lseq×H, 注意,在 BERT 的官方实现中该部分是可以训练的。
-
分段嵌入(Segment Embeddings):两个分段(句子 A 和句子 B)对应参数量为 2 × H 2 \times H 2×H。
-
层归一化(LayerNorm)参数:嵌入层的输出经过 LayerNorm 操作,其中包含两个参数: γ \gamma γ(缩放)和 β \beta β(偏移),每个大小为 H H H, 共 2 × H 2 \times H 2×H。
self.gamma = nn.Parameter(torch.ones(H)) # 可学习缩放参数,初始值为 1 self.beta = nn.Parameter(torch.zeros(H)) # 可学习偏移参数,初始值为 0
总嵌入层参数量: ( V + L seq + 2 + 2 ) × H = ( V + L seq + 4 ) × H (V + L_{\text{seq}} + 2 + 2) \times H = (V + L_{\text{seq}} + 4) \times H (V+Lseq+2+2)×H=(V+Lseq+4)×H。
-
-
Transformer 编码器层参数:
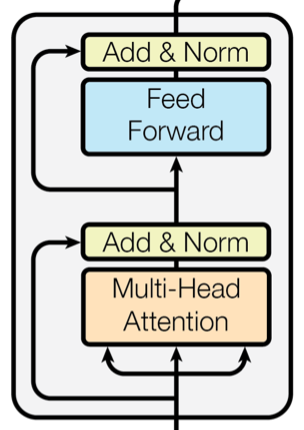
代码修改自《Transformer 论文精读》。
每个编码器层包含以下参数:
-
多头自注意力层:
-
查询(Query)、键(Key)、值(Value)权重矩阵:每个矩阵参数量为 H × H H \times H H×H, 共 3 3 3 个矩阵。
-
查询、键、值的偏置向量:每个偏置向量大小为 H H H, 共 3 3 3 个偏置。
# 定义线性层,用于生成查询、键和值矩阵 self.w_q = nn.Linear(H, H) self.w_k = nn.Linear(H, H) self.w_v = nn.Linear(H, H) -
输出映射矩阵:参数量为 H × H H \times H H×H。
# 输出线性层,将多头拼接后的输出映射回 H self.fc_out = nn.Linear(H, H) -
总计:
Attention Params = ( 3 × H × H ) + ( 3 × H ) + ( H × H ) + H = 4 H 2 + 4 H \text{Attention Params} = (3 \times H \times H) + (3 \times H) + (H \times H) + H = 4H^2 + 4H Attention Params=(3×H×H)+(3×H)+(H×H)+H=4H2+4H
-
-
前馈神经网络(FFN)层:
-
第一层权重矩阵: H × 4 H H \times 4H H×4H, 偏置为 4 H 4H 4H。
-
第二层权重矩阵: 4 H × H 4H \times H 4H×H, 偏置为 H H H。
self.w_1 = nn.Linear(H, 4 * H) # 第一个线性层 self.w_2 = nn.Linear(4 * H, H) # 第二个线性层 -
总计:
FFN Params = ( H × 4 H ) + ( 4 H ) + ( 4 H × H ) + H = 8 H 2 + 5 H \text{FFN Params} = (H \times 4H) + (4H) + (4H \times H) + H = 8H^2 + 5H FFN Params=(H×4H)+(4H)+(4H×H)+H=8H2+5H
-
-
层归一化(Layer Norm)参数:
-
每个 Layer Norm 层有两个参数: γ \gamma γ(缩放)和 β \beta β(偏移),每个大小为 H H H。
-
每层编码器有两个 Layer Norm 层,参数量为 2 × 2 H = 4 H 2 \times 2H = 4H 2×2H=4H。
-
每层总参数量:
Per-Layer Params = Attention Params + FFN Params + Layer Norm Params = ( 4 H 2 + 4 H ) + ( 8 H 2 + 5 H ) + 4 H = 12 H 2 + 13 H \begin{align*} \text{Per-Layer Params} &= \text{Attention Params} + \text{FFN Params} + \text{Layer Norm Params} \\ &= (4H^2 + 4H) + (8H^2 + 5H) + 4H \\ &= 12H^2 + 13H \end{align*} Per-Layer Params=Attention Params+FFN Params+Layer Norm Params=(4H2+4H)+(8H2+5H)+4H=12H2+13H
所有编码器层的总参数量: Per-Layer Params × L \text{Per-Layer Params} \times L Per-Layer Params×L, 其中 L L L 是层数。
-
-
池化层参数
BERT 的池化层是一个简单的线性变换层,参数量:
Pooling Params = H × H + H = H 2 + H \text{Pooling Params} = H \times H + H = H^2 + H Pooling Params=H×H+H=H2+H
注意,Transformer 中没有池化层。
以 BERT BASE \text{BERT}_\text{BASE} BERTBASE 为例:
- 词汇表大小 V = 30 , 522 V = 30,522 V=30,522。(论文中写的是 30,000,这里遵循代码实现中的 30,522)
- 最大序列长度 L seq = 512 L_{\text{seq}} = 512 Lseq=512。
- 隐藏层维度 H = 768 H = 768 H=768。
- 编码器层数 L = 12 L = 12 L=12。
可以先手动计算一下再往下看。
嵌入层参数量:
( V + L seq + 4 ) × H = ( 30 , 522 + 512 + 4 ) × 768 = 31 , 038 × 768 = 23 , 837 , 184 (V + L_{\text{seq}} + 4) \times H = (30,522 + 512 + 4) \times 768 = 31,038 \times 768 = 23,837,184 (V+Lseq+4)×H=(30,522+512+4)×768=31,038×768=23,837,184
编码器层参数量:
-
每层参数量:
12 H 2 + 13 H = 12 × 76 8 2 + 13 × 768 = 7 , 077 , 888 + 9 , 984 = 7 , 087 , 872 12H^2 + 13H = 12 \times 768^2 + 13 \times 768 = 7,077,888 + 9,984 = 7,087,872 12H2+13H=12×7682+13×768=7,077,888+9,984=7,087,872
-
所有层的参数量:
12 × 7 , 087 , 872 = 85 , 054 , 464 12 \times 7,087,872 = 85,054,464 12×7,087,872=85,054,464
池化层参数:
H 2 + H = 76 8 2 + 768 = 590 , 592 H^2 + H = 768^2 + 768 = 590,592 H2+H=7682+768=590,592
总参数量估计:
23 , 837 , 184 (嵌入层) + 85 , 054 , 464 (编码器层) + 590 , 592 (池化层) = 109 , 482 , 240 23,837,184 \text{(嵌入层)} + 85,054,464 \text{(编码器层)} + 590,592 \text{(池化层)} = 109,482,240 23,837,184(嵌入层)+85,054,464(编码器层)+590,592(池化层)=109,482,240
与论文中提到的 110M 相符。
附录的表格证明了当前计算的正确性。
微调(Fine-tuning)
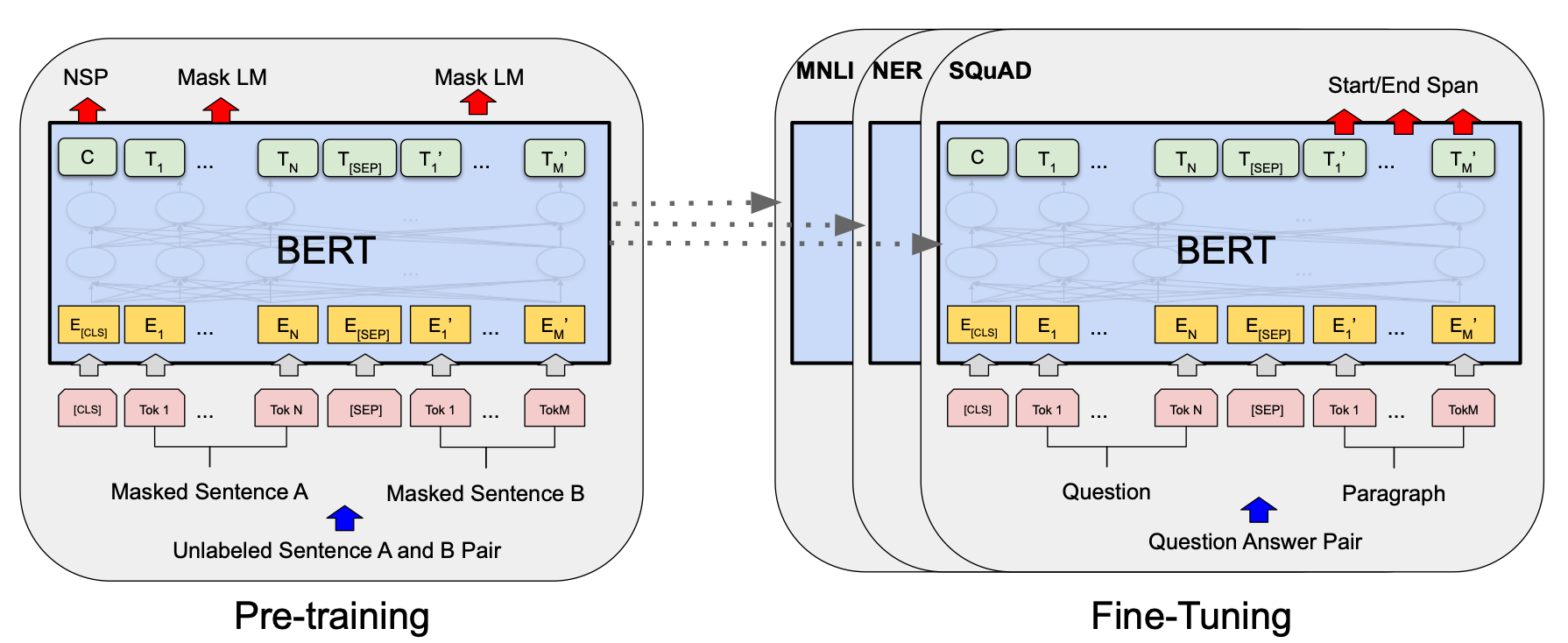
在微调阶段,模型首先使用预训练得到的参数进行初始化,然后在下游任务的标注数据上,对所有参数进行微调。不同的下游任务使用相同的预训练模型进行初始化,但每个任务都有各自的微调过程和特定的输出层。
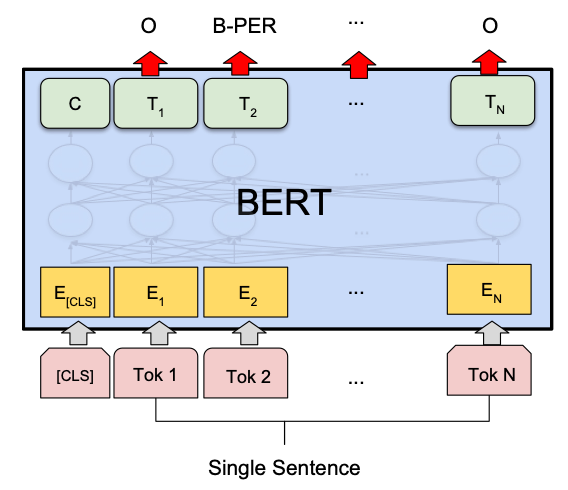
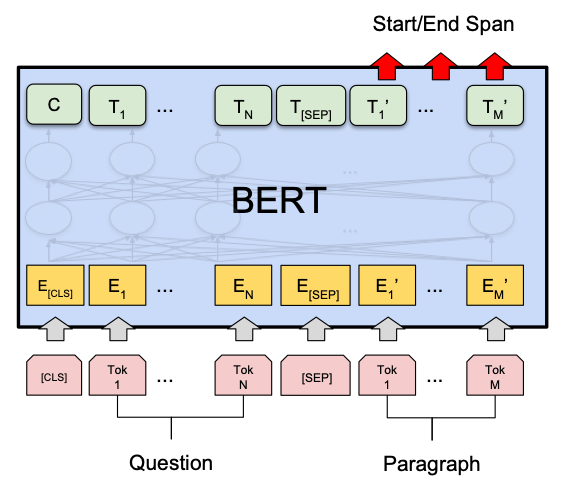
通过论文中的图 1 进一步理解,图示为问答任务:
解释:
模型架构统一:预训练和微调过程中使用相同的模型架构,除了任务特定的输出层。虚线表示预训练模型参数被用于初始化下游任务模型。
特殊词元/标记:
[CLS](Classification Token):在每个输入序列的开头添加。编码器的自注意力机制会计算[CLS]与序列中所有其他词的关系,因此,[CLS]的输出向量可以有效地表示整个序列的上下文信息。[CLS]向量常作为句子级别(Sentence-Level)的 embedding,被应用于句子分类、情感分析、文本分类等任务。[SEP](Separator Token):用于分隔不同的句子或表示序列的结束。举个例子,如果我们有两个句子:
- 句子 A:“BERT is great.”
- 句子 B:“It works well.”
它们会被处理成:
[CLS] BERT is great. [SEP] It works well. [SEP]下游任务示例(上图右侧):
MNLI(Multi-Genre Natural Language Inference):
任务描述:句子对分类任务,判断两个句子之间的逻辑关系(蕴含、中立、矛盾)。
输入形式:
[CLS]+ 前提句子 +[SEP]+ 假设句子 +[SEP]。输出层:在
[CLS]标记的嵌入表示上添加一个分类层,用于预测句子对的逻辑关系。
- 代码实现(伪代码):
# 假设 sequence_output 是模型的输出,维度为 (batch_size, seq_length, hidden_size) cls_embedding = sequence_output[:, 0, :] # 获取 [CLS] 的嵌入表示,维度为 (batch_size, hidden_size) classifier = nn.Linear(hidden_size, num_labels) # 分类层 logits = classifier(cls_embedding) # 预测结果,维度为 (batch_size, num_labels)NER(Named Entity Recognition):
任务描述:序列标注任务,在给定的文本中识别并分类命名实体(如人名、地名、组织等)。
输入形式:
[CLS]+ 句子 +[SEP],对每个词的表示进行标注。输出层:在每个词的嵌入表示上添加标注层,预测其对应的实体类别。
- 代码实现(伪代码):
# 假设 sequence_output 是模型的输出,维度为 (batch_size, seq_length, hidden_size) token_embeddings = sequence_output[:, 1:-1, :] # 排除 [CLS] 和 [SEP],维度为 (batch_size, seq_length - 2, hidden_size) tagger = nn.Linear(hidden_size, num_entity_labels) # 标注层 logits = tagger(token_embeddings) # 预测结果,维度为 (batch_size, seq_length - 2, num_entity_labels)SQuAD(Stanford Question Answering Dataset):
任务描述:问答任务,给定一个问题和相关段落,模型需要从段落中提取出能够回答该问题的文本片段。
输入形式:
[CLS]+ 问题 +[SEP]+ 段落 +[SEP]。输出层:预测答案起始(start)和结束(end)位置。
- 代码实现(伪代码):
# 假设 sequence_output 是模型的输出,形状为 (batch_size, seq_length, hidden_size) # 定义一个线性层,将 hidden_size 映射到 2(分别用于预测 start 和 end 位置),当然,可以定义两个线性层分别进行预测,因为线性层每个位置的处理是相互独立的 qa_outputs = nn.Linear(hidden_size, 2) logits = qa_outputs(sequence_output) # 形状为 (batch_size, seq_length, 2) start_logits, end_logits = logits.split(1, dim=-1) # 每个的形状为 (batch_size, seq_length, 1) start_logits = start_logits.squeeze(-1) # 形状为 (batch_size, seq_length) end_logits = end_logits.squeeze(-1) # 形状为 (batch_size, seq_length)
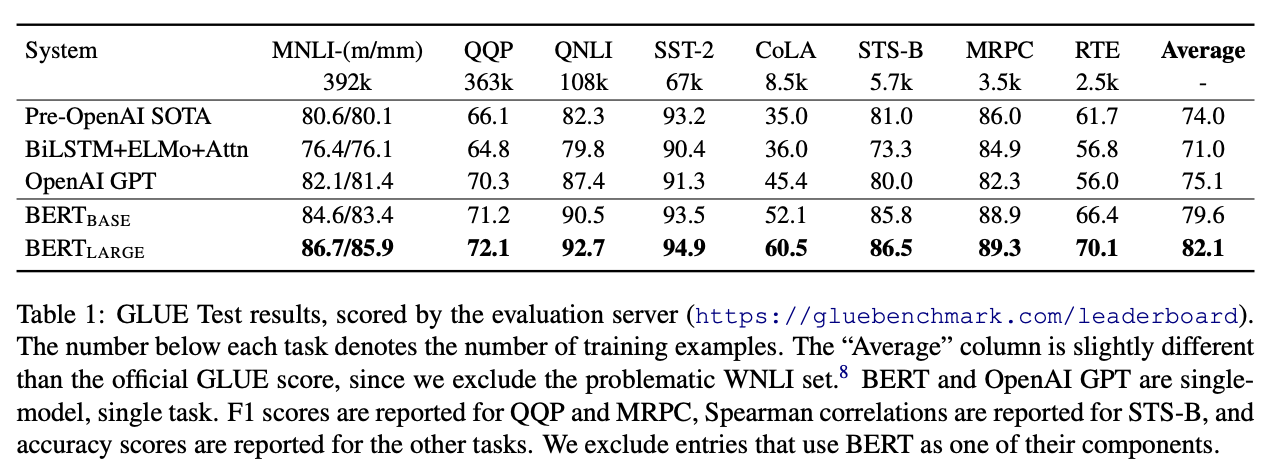
呈现
表 1
BERT 论文逐段精读【论文精读】 37:11 - 38:10 部分
BERT BASE \text{BERT}_\text{BASE} BERTBASE 和 GPT 的可学习的参数量接近,对比结果 BERT 的提升还是比较大的。
表头中每个任务名称下的数字表示该任务对应的训练样本数量。
“Average”(平均分)列展示了模型在各任务上的综合表现,这里计算的平均分与 GLUE 官方的 GLUE Score 略有不同,因为它排除了 WNLI(Winograd NLI)任务,这个任务被认为存在问题。
表中的结果排除了任何使用 BERT 作为组成部分的模型。
注意,这句话并非 18 年初版 arXiv 1810.04805v1 中的叙述,而是新版 arXiv 1810.04805v2 增加的。如果你读到这句话产生了疑惑:“怎么 BERT 还没发表就被用来当组件了?”,不妨访问一下它们。
作为拓展了解一下 GLUE(General Language Understanding Evaluation),这是一个用于评估模型性能的基准数据集,由多个子任务78组成(仅列举表格中存在的):
| 任务 | 全称 | 任务类型 | 评价指标 | 训练样本数量 | 备注 |
|---|---|---|---|---|---|
| MNLI-(m/mm) | MultiNLI Matched/MultiNLI Mismatched | 自然语言推理(Natural Language Inference, NLI),三分类(蕴涵、矛盾、中立) | 准确率(匹配/不匹配) | 392k | 包含匹配(in-domain)和不匹配(cross-domain)两个部分 |
| QQP | Quora Question Pairs | 语义等价判断(二分类) | F1分数 & 准确率 | 363k | 判断问题对是否等价,数据来自 Quora |
| QNLI | Question NLI | 自然语言推理(二分类) | 准确率 | 108k | 由 SQuAD 改造而来,判断句子是否包含问题的答案 |
| SST-2 | The Stanford Sentiment Treebank | 句子情感分类(二分类) | 准确率 | 67k | 基于电影评论的句子情感分析 |
| CoLA | The Corpus of Linguistic Acceptability | 语法正确性判断(二分类) | Matthew相关系数 | 8.5k | 判断句子是否为合法的英语句子(0 不合法,1 合法) |
| STS-B | Semantic Textual Similarity Benchmark | 语义文本相似度(回归) | Spearman相关系数 | 5.7k | 预测句子对的语义相似度得分(1-5分) |
| MRPC | Microsoft Research Paraphrase Corpus | 语义等价判断(二分类) | F1分数 & 准确率 | 3.5k | 判断句子对是否为同义改写 |
| RTE | Recognizing Textual Entailment | 自然语言推理(二分类) | 准确率 | 2.5k | 由多个 RTE 数据集合并,简化为二分类任务 |
认识问答任务:抽取式和生成式
在 BERT 的实验中,使用了 SQuAD(Stanford Question Answering Dataset),这是斯坦福大学发布的一个问答数据集。这里的“问答”特指抽取式问答(Extractive Question Answering),即模型需要根据「给定的问题」和「包含答案的文本」,从中抽取出对应的答案片段,不需要生成新的词语。
举例说明:
- 文本:
BERT 是由 Google 提出的预训练语言模型,它在多个 NLP 任务上取得了 SOTA 的成绩。 - 问题:
谁提出了 BERT? - 答案:
Google
如果去掉“抽取式”的限定,广义上的“问答”更接近于生成式问答(Generative Question Answering),即答案并非固定的文本片段,模型基于理解进行生成,最终的答案不拘泥于特定的文本。
举例说明:
- 文本:同上。
- 问题:同上。
- 答案:
BERT 是由 Google 提出的预训练语言模型。具体来说,它是由 Jacob Devlin 等研究人员在 2018 年的论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中首次介绍的。BERT 在多个 NLP 任务上取得了 SOTA(State-of-the-Art)的成绩,推动了自然语言处理领域的快速发展。(该答案由 GPT-4o 生成)生成式问答涉及到另一篇基础论文:GPT,后续会上传解读文章,这里就不“喧宾夺主”了,我们来思考下面的问题。
Q: 模型怎么完成抽取式问答任务?输出是什么?
停下来思考一下,是直接生成答案对应的词或句子吗?
不是,输出的是答案在文本中的起始和结束位置。通过下图9进行理解:
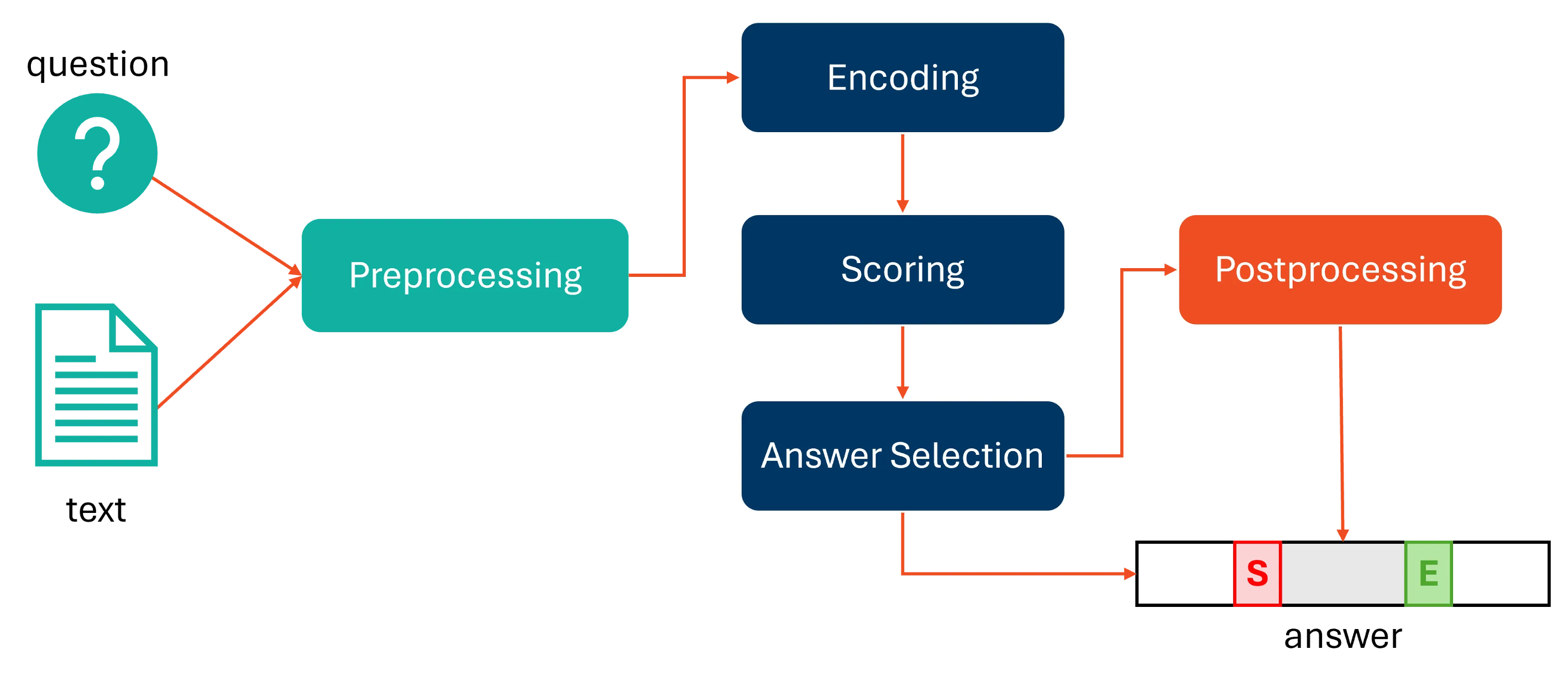
模型的最终输出为两个向量:起始位置得分向量 s ∈ R N \mathbf{s} \in \mathbb{R}^N s∈RN 和结束位置得分向量 e ∈ R N \mathbf{e} \in \mathbb{R}^N e∈RN,其中 N N N 是输入序列的长度。
对于每个位置 i i i,模型计算其作为答案起始位置和结束位置的得分:
s i = w start h i + b start e i = w end h i + b end \begin{aligned} s_i &= \mathbf{w}_{\text{start}} \mathbf{h}_i + b_{\text{start}} \\ e_i &= \mathbf{w}_{\text{end}} \mathbf{h}_i + b_{\text{end}} \end{aligned} siei=wstarthi+bstart=wendhi+bend
其中,
h
i
∈
R
H
\mathbf{h}_i \in \mathbb{R}^H
hi∈RH 是编码器在位置
i
i
i 的隐藏状态输出 (
h
\mathbf{h}
h 就是 BERT 模型的最终输出),
H
H
H 是隐藏层的维度。
w
start
∈
R
H
\mathbf{w}_{\text{start}} \in \mathbb{R}^H
wstart∈RH 和
w
end
∈
R
H
\mathbf{w}_{\text{end}} \in \mathbb{R}^H
wend∈RH 是权重向量(对应于 nn.Linear(H, 1),这里写成了常见的数学形式,了解线性层代码的同学可以当做
h
w
⊤
\mathbf{h}\mathbf{w}^\top
hw⊤),
b
start
b_{\text{start}}
bstart 和
b
end
b_{\text{end}}
bend 是偏置项。
然后,对得分向量进行 softmax 操作,得到每个位置作为起始和结束位置的概率分布:
P start ( i ) = e s i ∑ j = 1 N e s j P end ( i ) = e e i ∑ j = 1 N e e j \begin{aligned} P_{\text{start}}(i) &= \frac{e^{s_i}}{\sum_{j=1}^{N} e^{s_j}} \\ P_{\text{end}}(i) &= \frac{e^{e_i}}{\sum_{j=1}^{N} e^{e_j}} \end{aligned} Pstart(i)Pend(i)=∑j=1Nesjesi=∑j=1Neejeei
在推理时,选择具有最高概率的起始位置 s ^ \hat{s} s^ 和结束位置 e ^ \hat{e} e^。为了保证答案的合理性,通常要求 s ^ ≤ e ^ \hat{s} \leq \hat{e} s^≤e^,并且答案的长度不超过预设的最大长度 L max L_{\text{max}} Lmax。此时的行为称为后处理(Postprocessing),根据实际需求进行。
最终,答案就是输入序列中从位置 s ^ \hat{s} s^ 到 e ^ \hat{e} e^ 的片段,即:
Answer = Input [ s ^ : e ^ ] \text{Answer} = \text{Input}[\hat{s}:\hat{e}] Answer=Input[s^:e^]
那么,对应到代码是什么样的呢?
代码示例
写在前面,前文数学符号与代码变量名的对应关系:
- H H H:
hidden_size- N N N:
batch_size- h \mathbf{h} h:
outputs.last_hidden_state- s , e s, e s,e:
start_logits,end_logits(可以当做得分)- P start , P end P_{\text{start}}, P_{\text{end}} Pstart,Pend:
start_probs,end_probs- Answer , Input \text{Answer}, \text{Input} Answer,Input:
answer,input_ids
import torch
import torch.nn as nn
import torch.nn.functional as F
class BertForQuestionAnswering(nn.Module):
def __init__(self, bert_model):
super(BertForQuestionAnswering, self).__init__()
self.bert = bert_model # 预训练的 BERT 模型
self.qa_outputs = nn.Linear(self.bert.config.hidden_size, 2) # 输出层
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
# 获取 BERT 的输出
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
sequence_output = outputs.last_hidden_state # (batch_size, seq_length, hidden_size)
# 通过线性层得到起始和结束位置的 logits
logits = self.qa_outputs(sequence_output) # (batch_size, seq_length, 2)
start_logits, end_logits = logits.split(1, dim=-1) # 每个的形状为 (batch_size, seq_length, 1)
start_logits = start_logits.squeeze(-1) # (batch_size, seq_length)
end_logits = end_logits.squeeze(-1) # (batch_size, seq_length)
# 返回起始和结束位置的 logits
return start_logits, end_logits
# 示例推理过程
# 假设我们有 input_ids、attention_mask、token_type_ids,以及预训练的 bert_model 和 tokenizer
model = BertForQuestionAnswering(bert_model)
start_logits, end_logits = model(input_ids, attention_mask, token_type_ids)
# 对 logits 应用 softmax,得到概率分布(可选)
start_probs = F.softmax(start_logits, dim=-1) # (batch_size, seq_length)
end_probs = F.softmax(end_logits, dim=-1)
# 获取起始和结束位置的索引(其实直接对 logits 用 argmax 就可以了,除非需要根据概率进行更复杂的后处理)
start_indices = torch.argmax(start_probs, dim=-1) # (batch_size,)
end_indices = torch.argmax(end_probs, dim=-1)
# 为了确保起始位置不超过结束位置,可以进行如下处理
for i in range(start_indices.size(0)):
if start_indices[i] > end_indices[i]:
start_indices[i], end_indices[i] = end_indices[i], start_indices[i]
# 从输入序列中提取答案(以 batch_size=1 为例),在 Python 中,列表切片是左闭右开区间,因此需要加 1
answer = input_ids[0, start_indices[0]:end_indices[0]+1] # 提取答案的 token_ids
# 将 token IDs 转换为文本
answer = tokenizer.decode(answer_ids, skip_special_tokens=True)
print("答案:", answer)
拓展
BERT 中的池化层
这个池化层并不存在于 Transformer 的原始架构中,以下为参考官方代码的 PyTorch 实现:
class BertPooler(nn.Module):
def __init__(self, hidden_size):
super(BertPooler, self).__init__()
# 全连接层
self.dense = nn.Linear(hidden_size, hidden_size)
# 激活函数,使用 tanh
self.activation = nn.Tanh()
def forward(self, sequence_output):
"""
参数:
sequence_output: BERT 的最后一层输出, shape [batch_size, seq_length, hidden_size]
返回:
pooled_output: 池化后的输出, shape [batch_size, hidden_size]
"""
# 取出序列中第一个 token ([CLS]) 的隐藏状态,或者说向量
first_token_tensor = sequence_output[:, 0] # shape [batch_size, hidden_size]
# 应用全连接层和激活函数
pooled_output = self.activation(self.dense(first_token_tensor))
return pooled_output
争议:关于 NSP 任务
在后续的研究中,NSP 任务去除后(即仅使用 MLM 任务进行预训练)也可以取得不错的表现,下图来自 RoBERTa10 的表 2:
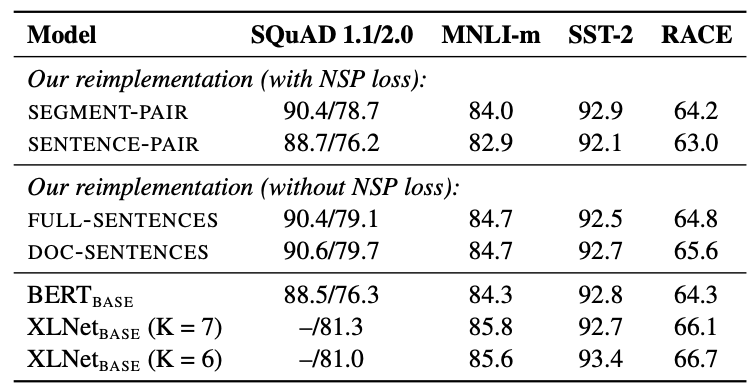
但 ALBERT11 引入的类似任务 SOP 似乎又说明了对句子顺序进行预测是一个有用的任务。那么,NSP 不那么有效可能在于负样本的句子对经常并非同一主题,所以 NSP 可能做的并非逻辑上的顺序预测,而是预测两句话的主题是否一致12。
Q: 什么是 SOP?
通过两张非常棒的图12来直观理解:
NSP:
SOP:

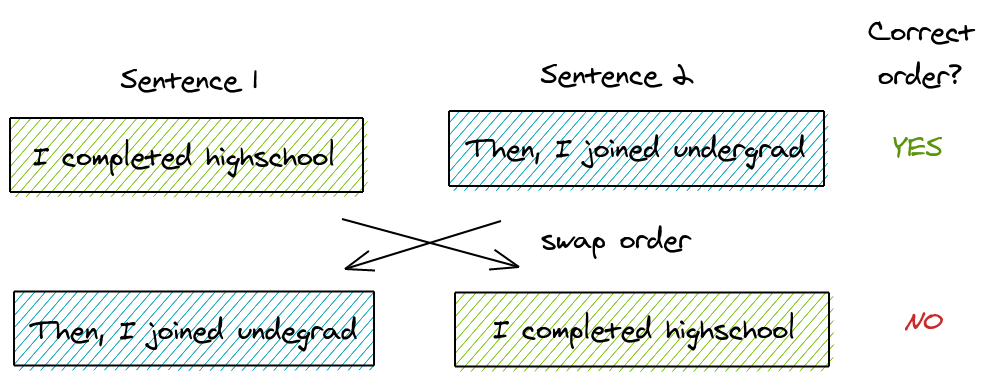
句子顺序预测(Sentence Order Prediction),负样本从随机的两个不相邻的句子(NSP)变成了原来顺序相邻的句子交换位置。修改自 BERT NSP:
-
正样本(相邻句子对):
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] -
负样本(相邻句子对交换位置):
[CLS] he bought a gallon [MASK] milk [SEP] the man [MASK] to the store [SEP]
附录
参数量
1. bert-base-uncased, 110M parameters
| Bert-base-uncased | Key | Shape | Count | |
|---|---|---|---|---|
| Embedding | embeddings.word_embeddings.weight | [30522, 768] | 23,440,896 | 23,837,184 |
| embeddings.position_embeddings.weight | [512, 768] | 393,216 | ||
| embeddings.token_type_embeddings.weight | [2, 768] | 1,536 | ||
| embeddings.LayerNorm.weight | [768] | 768 | ||
| embeddings.LayerNorm.bias | [768] | 768 | ||
| Transformer * 12 | encoder.layer.0.attention.self.query.weight | [768, 768] | 589,824 | 7,087,872 * 12 = 85,054,464 |
| encoder.layer.0.attention.self.query.bias | [768] | 768 | ||
| encoder.layer.0.attention.self.key.weight | [768, 768] | 589,824 | ||
| encoder.layer.0.attention.self.key.bias | [768] | 768 | ||
| encoder.layer.0.attention.self.value.weight | [768, 768] | 589,824 | ||
| encoder.layer.0.attention.self.value.bias | [768] | 768 | ||
| encoder.layer.0.attention.output.dense.weight | [768, 768] | 589,824 | ||
| encoder.layer.0.attention.output.dense.bias | [768] | 768 | ||
| encoder.layer.0.attention.output.LayerNorm.weight | [768] | 768 | ||
| encoder.layer.0.attention.output.LayerNorm.bias | [768] | 768 | ||
| encoder.layer.0.intermediate.dense.weight | [3072, 768] | 2,359,296 | ||
| encoder.layer.0.intermediate.dense.bias | [3072] | 3072 | ||
| encoder.layer.0.output.dense.weight | [768, 3072] | 2,359,296 | ||
| encoder.layer.0.output.dense.bias | [768] | 768 | ||
| encoder.layer.0.output.LayerNorm.weight | [768] | 768 | ||
| encoder.layer.0.output.LayerNorm.bias | [768] | 768 | ||
| Pooler | pooler.dense.weight | [768, 768] | 589,824 | 590,592 |
| pooler.dense.bias | [768] | 768 | ||
| 109,482,240 |
2. bert-large-uncased, 340M parameters
| Bert-large-uncased | Key | Shape | Count | Count All |
|---|---|---|---|---|
| Embedding | embeddings.word_embeddings.weight | [30522, 1024] | 31,254,528 | 31,782,912 |
| embeddings.position_embeddings.weight | [512, 1024] | 524,288 | ||
| embeddings.token_type_embeddings.weight | [2, 1024] | 2,048 | ||
| embeddings.LayerNorm.weight | [1024] | 1,024 | ||
| embeddings.LayerNorm.bias | [1024] | 1,024 | ||
| Transformer * 24 | encoder.layer.0.attention.self.query.weight | [1024, 1024] | 1,048,576 | 12,592,128 * 24 = 302,211,072 |
| encoder.layer.0.attention.self.query.bias | [1024] | 1,024 | ||
| encoder.layer.0.attention.self.key.weight | [1024, 1024] | 1,048,576 | ||
| encoder.layer.0.attention.self.key.bias | [1024] | 1,024 | ||
| encoder.layer.0.attention.self.value.weight | [1024, 1024] | 1,048,576 | ||
| encoder.layer.0.attention.self.value.bias | [1024] | 1,024 | ||
| encoder.layer.0.attention.output.dense.weight | [1024, 1024] | 1,048,576 | ||
| encoder.layer.0.attention.output.dense.bias | [1024] | 1,024 | ||
| encoder.layer.0.attention.output.LayerNorm.weight | [1024] | 1,024 | ||
| encoder.layer.0.attention.output.LayerNorm.bias | [1024] | 1,024 | ||
| encoder.layer.0.intermediate.dense.weight | [4096, 1024] | 4,194,304 | ||
| encoder.layer.0.intermediate.dense.bias | [4096] | 4,096 | ||
| encoder.layer.0.output.dense.weight | [1024, 4096] | 4,194,304 | ||
| encoder.layer.0.output.dense.bias | [1024] | 1,024 | ||
| encoder.layer.0.output.LayerNorm.weight | [1024] | 1,024 | ||
| encoder.layer.0.output.LayerNorm.bias | [1024] | 1,024 | ||
| Pooler | pooler.dense.weight | [1024, 1024] | 1,048,576 | 1,049,600 |
| pooler.dense.bias | [1024] | 1,024 | ||
| 335,043,584 |
Improving Language Understanding by Generative Pre-Training. ↩︎
引用次数数据来源于 Google Scholar。 ↩︎
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. ↩︎
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books ↩︎
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS. ↩︎


















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











