






复现Reducing Complexity of HEVC: A Deep Learning Approach", in IEEE Transactions on Image Processing (TIP) 只对帧内模式进行复现,补充代码修改部分
论文链接
tianyili2017/HEVC-Complexity-Reduction: Source programs to test the deep-learning-based complexity reduction approach for HEVC, at both intra- and inter-modes. (github.com)

作者在GitHub开源,给出了代码,高手只要一看就知道该怎么操作,但是对于刚入门深度学习的小白们,还是有一定困难的。因此我将详细讲解我是如何在师兄的帮助下一步步复现的。
1、下载数据库。
HEVC-Projects/CPH: A large-scale database for CU partition of HEVC (CPH), at both intra- and inter-modes. (github.com)
作者在论文的第一页就告诉了读者他们建立了一个数据库CPH,既包含了帧内模式也包含了帧间模式的CU分割数据,其中帧内模式数据有2000张原始图片由四个QP压缩得到,帧间模式序列由111条原始序列压缩而成)。

通过百度网盘https://pan.baidu.com/s/1hszUzeW下载

在解压缩的时候,注意YUV_All.part01-07解压缩到一个文件夹中,Info暂时可以先不管,而YUV_All文件夹里面包含了12个序列:

上面我们提到,帧内数据集一共有2000张分辨率为4928x3264的图片,2000张图片随机分成训练集(1700张图片),测试集(200张图片)、验证集(100张图片),每个集再平均分成四个数量相等,分辨率不同的图片集:4928x3264,2880x1920,1536x1024,768x512。
数据集图片包含多种分辨率可以给CU分割的预测学习提供足够丰富的数据。
2、帧内训练模式
在作者的GitHub-READM-Training at Intra-mode下,给出了相关文件夹和说明。
2.1制作数据集
用Visual Studio2010 打开HM-16.5_Extract_Data/,按下Ctrl+F(搜索快捷键),在查找内容中输入added,查找范围选择整个解决方案,可以发现作者很奈斯的在改动的地方都会有类似20170319 added 的标注,这样可以方便大家去学习,对照原始HM-16.5。
// 20170319 added
//static char cmd[500];
static char phDateTime[100];
static char phInputFile[200];
static char phFileNameCUDepth[100], phFileNamePUPartSize[100], phFileNameTUDepth[100], phFileNameIndex[100];
static char phFileNameCUDepthText[100], phFileNamePUPartSizeText[100], phFileNameTUDepthText[100];
FILE * fpYuvNameTemp = fopen("YuvNameTemp.dat", "r+");
assert(fscanf(fpYuvNameTemp, "%s\n%s", phInputFile, phDateTime)>=0);
fclose(fpYuvNameTemp);
sprintf(phFileNameCUDepth, "Info_%s_CUDepth.dat", phDateTime);
sprintf(phFileNamePUPartSize, "Info_%s_PUPartSize.dat", phDateTime);
sprintf(phFileNameTUDepth, "Info_%s_TUDepth.dat", phDateTime);
sprintf(phFileNameIndex, "Info_%s_Index.dat", phDateTime);
sprintf(phFileNameCUDepthText, "Info_%s_CUDepthText.dat", phDateTime);
sprintf(phFileNamePUPartSizeText, "Info_%s_PUPartSizeText.dat", phDateTime);
sprintf(phFileNameTUDepthText, "Info_%s_TUDepthText.dat", phDateTime);
copyFile((char*)"Info_CUDepth.dat", phFileNameCUDepth);
copyFile((char*)"Info_PUPartSize.dat", phFileNamePUPartSize);
copyFile((char*)"Info_TUDepth.dat", phFileNameTUDepth);
copyFile((char*)"Info_Index.dat", phFileNameIndex);
copyFile((char*)"Info_CUDepthText.dat", phFileNameCUDepthText);
copyFile((char*)"Info_PUPartSizeText.dat", phFileNamePUPartSizeText);
copyFile((char*)"Info_TUDepthText.dat", phFileNameTUDepthText);
*/
/*
sprintf(cmd, "CopyFile.exe %s Info_CUDepth.dat", phFileNameCUDepth); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_PUPartSize.dat", phFileNamePUPartSize); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_TUDepth.dat", phFileNameTUDepth); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_Index.dat", phFileNameIndex); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_CUDepthText.dat", phFileNameCUDepthText); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_PUPartSizeText.dat", phFileNamePUPartSizeText); system(cmd);
sprintf(cmd, "CopyFile.exe %s Info_TUDepthText.dat", phFileNameTUDepthText); system(cmd);
*/
// 20170319 end

而我在这边的改动主要是针对输出文件Info,在TEncSlice.cpp,858-862行,做了修改,在输出的时候获取文件的名字、QP值、编码的帧数等信息。得到跟作者相似的输出Info格式。然后就是编译,生成TAppEncoder的程序,复制到bin文件夹,复制修改编码器配置文件、视频源配置文件,用批处理文件快速运行程序。(记得在Visual Studio里,设置编码器的工作目录、命令参数)
sprintf(phFileNameCUDepth, "Info_%s_%s_%d_%d_CUDepth.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
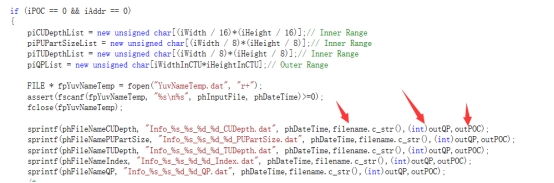
这是作者的
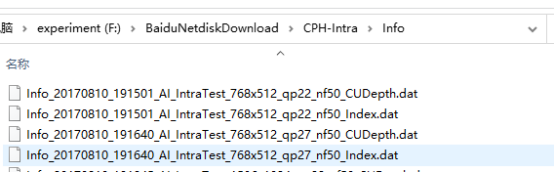
这是我的(_Li)
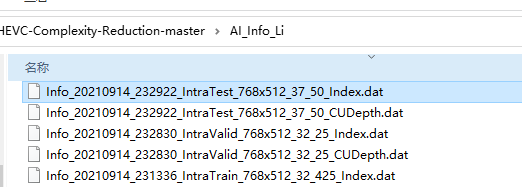
多少还是有点不一样,但是没关系。
编码器截图:


视频源输入配置截图:


批处理命令截图:

生成的Info如图


到此,数据库就做好了。提取Info_XX.dat其他两个str_XX.bin, log_XX.txt files我没提取到,不知道啥原因。
2.2提取数据
To configure: variables YUV_PATH_ORI and INFO_PATH in Extract_Data/extract_data_AI.py.
这句话的意思是要让你在extract_data_AI.py.里修改你自己的YUV文件输入地址和INFO_PATH输入地址
# To configure: two variables
YUV_PATH_ORI = 'F:/HEVC-Complexity-Reduction-master/HEVC-Complexity-Reduction-master/YUV_All/' # path storing 12 raw YUV files
INFO_PATH = 'F:/HEVC-Complexity-Reduction-master/HEVC-Complexity-Reduction-master/AI_Info_Li/' # path storing Info_XX.dat files for All-Intra configuration
只要2.1的文件提取没问题,就可以得到3个打乱的训练集、验证集、测试集。
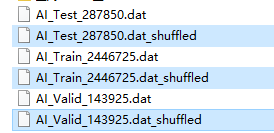
然后再将选中的这三个随机打乱的shuffled文件,拷贝到ETH-CNN_Training_AI\Data下
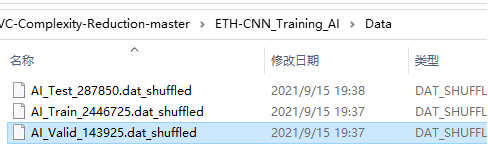
到此,数据提取完成。
2.3训练
following the instruction ETH-CNN_Training_AI/readme.txt.
这里有几个地方要注意修改
input_data.py下,
第10行,数据地址要改:
data_dir = 'F:/HEVC-Complexity-Reduction-master/HEVC-Complexity-Reduction-master/ETH-CNN_Training_AI/Data/' # path of training/validation/test data
第39行,QP类型
第58行,数据选择,因为我们自己做了数据集,所以不用demo sets
# select training for which range of QP
MODEL_TYPE = 4
if MODEL_TYPE == 1:
MODEL_NAME = 'qp22'
SELECT_QP_LIST = [22]
EVALUATE_QP_THR_LIST = [20, 25]
if MODEL_TYPE == 2:
MODEL_NAME = 'qp27'
SELECT_QP_LIST = [27]
EVALUATE_QP_THR_LIST = [25, 30]
if MODEL_TYPE == 3:
MODEL_NAME = 'qp32'
SELECT_QP_LIST = [32]
EVALUATE_QP_THR_LIST = [30, 35]
if MODEL_TYPE == 4:
MODEL_NAME = 'qp37'
SELECT_QP_LIST = [37]
EVALUATE_QP_THR_LIST = [35, 40]
DATA_SWITCH = 0
def get_train_valid_test_sets(DATA_SWITCH):
global TRAINSET, VALIDSET, TESTSET
if DATA_SWITCH == 0: # full sets (the full program for generating these files will be open on GitHub soon)
TRAINSET = 'AI_Train_2446725.dat_shuffled'
VALIDSET = 'AI_Valid_143925.dat_shuffled'
TESTSET = 'AI_Test_287850.dat_shuffled'
elif DATA_SWITCH == 1: # demo sets
TRAINSET = 'AI_Train_5000.dat_shuffled'
VALIDSET = 'AI_Valid_5000.dat_shuffled'
TESTSET = 'AI_Test_5000.dat_shuffled'
elif DATA_SWITCH == 2: # choose other files if necessary
pass

迭代次数是1000000,经过4个QP的训练之后,可以得到如下模型和准确度,log等文件



到此,训练结束。
3、帧内测试
测试序列:BasketballPass_416x240_50.yuv
把训练好的QP22,27,32,37四个序列的相关文件复制到
HM-16.5_Test_AI\bin
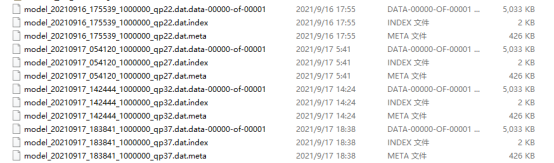

video_to_cu_depth.py里面这里的模型要改成自己训练好的
3.1编码
编码前,需要先运行编码器,编译成功了以后复制TAppEncoder.exe到bin文件下,运行批处理文件RUN_AI.bat
用之前说过的搜索方法,找出代码修改的部分
Invoke “video_to_cu_depth.py” with Tensorflow to predict the CU partition for the whole YUV sequence.

重新编译,通过(不需要修改什么)

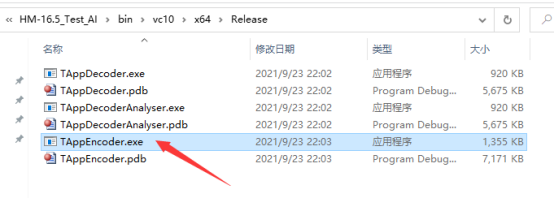
复制到这

批处理代码:

3.2结果比较
总的时间
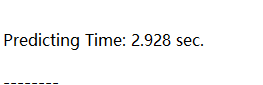
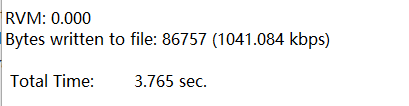
需要2.928(预测)+3.765(HM)=6.693。而HM16.5平台却需要75.724秒。

徐迈:

HM-16.5

主观感觉差别不大。
Ps:细心的朋友们可能会发现,每次运行的预测时间和编码时间不一样,这是由于编码的帧数过少,当增加编码帧数以后,时间差别不大。
至此,徐迈老师的文献也就复现得差不多了。由于是初学的小白,难免会有很多错误,还望大佬们多多指教。也希望本文能对目前正在阅读的你有所帮助,希望我们能共同进步,在视频编码方向有所建树~
有读者反馈按照上面提供的代码不能运行,是因为有部分改动我没贴出来,接下来把完整改动贴出来仅供大家参考学习
补充修改代码以下是所有涉及代码改动的地方
//20211020add
sprintf(phFileNameCUDepth, "Info_%s_%s_%d_%d_CUDepth.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
sprintf(phFileNamePUPartSize, "Info_%s_%s_%d_%d_PUPartSize.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
sprintf(phFileNameTUDepth, "Info_%s_%s_%d_%d_TUDepth.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
sprintf(phFileNameIndex, "Info_%s_%s_%d_%d_Index.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
sprintf(phFileNameQP, "Info_%s_%s_%d_%d_QP.dat", phDateTime,filename.c_str(),(int)outQP,outPOC);
//20211020end

//20211020add
filename = m_pchInputFile;
int nPos = filename.find_last_of("\\");
filename = filename.substr(nPos+1);
//20211020end


//2211020add
extern Double outQP;
extern int outPOC;
//2211020add

//20211020add
Double outQP;
int outPOC;
//20211020end
















 2022
2022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









