






1、修改密码指令
alter user root@localhost identified by '123456';
2、删除数据库
drop database <数据库名>;
3、切换数据库
use <数据库名>
4、数据类型
- 数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
- 日期和时间类型
| 类型 | 大小 | 范围 | 格式 | 用途 |
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
- 字符串类型
| 类型 | 大小 | 用途 |
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
5、创建表
CREATE TABLE IF NOT EXISTS `runoob_tbl`( `runoob_id` INT UNSIGNED AUTO_INCREMENT, `runoob_title` VARCHAR(100) NOT NULL, `runoob_author` VARCHAR(40) NOT NULL, `submission_date` DATE, PRIMARY KEY ( `runoob_id` ) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 如果不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
6、删除表
DROP TABLE table_name ;
7、插入数据
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );
8、查询数据
SELECT column_name,column_name FROM table_name [WHERE Clause] [LIMIT N][ OFFSET M]
- 可以使用 LIMIT 属性来设定返回的记录数。
- 可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
9、更新数据
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause]
10、删除数据
DELETE FROM table_name [WHERE Clause]
11、like语句
select * from table_name where value like '%%'
12、union操作符
- UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions] UNION [ALL | DISTINCT] SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];
- expression1, expression2, ... expression_n: 要检索的列。
- tables: 要检索的数据表。
- WHERE conditions: 可选, 检索条件。
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
13、分组
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
- WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
SELECT name, SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
- coalesce 来设置一个可以取代 NUll 的名称。参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
SELECT coalesce(name, '总数'), SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------------------------+--------------+ | coalesce(name, '总数') | signin_count | +--------------------------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | 总数 | 16 | +--------------------------+--------------+ 4 rows in set (0.01 sec)
14、连接的使用
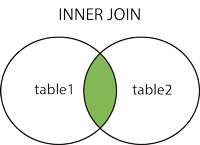
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
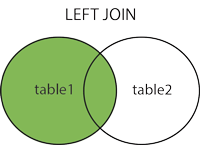
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
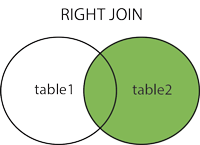
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









