







因为本人暑假想搞一个股票筛选软件自己玩玩,所有开始学习python语言,算是边学边应用吧,有错的地方请大佬不吝啬指导
1.首页去东方财富股票列表展示按F12查看Network请求的数据
可以找到这串请求
http://64.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124001651461580406255_1561992580766&pn=1&pz=3754&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2&fields=f2,f12,f14,f13&_=1561992580767
其中pz列表所要展示多少条股票信息,这里3754是展示了所有的股票信息,fields信息是指所有获取的个股详细信息,这里
f2:标明此股是否已退市
f12:标明股票的代码
f14:标明股票的名称
f13:是股票的secid码(在获取个股详细信息url中有重大作用)
这四个是我自己所需要的field,这里可以根据你们自己的需要来获取。
所获取的信息类似这种格式(这里只展示前5条):
jQuery1124001651461580406255_1561992580766({"rc":0,"rt":6,"svr":182482182,"lt":1,"full":1,"data":{"total":3756,"diff":[{"f2":4.15,"f12":"000892","f13":0,"f14":"欢瑞世纪"},{"f2":4.7,"f12":"002641","f13":0,"f14":"永高股份"},{"f2":6.68,"f12":"002330","f13":0,"f14":"得利斯"},{"f2":5.48,"f12":"601236","f13":1,"f14":"红塔证券"},{"f2":8.67,"f12":"002037","f13":0,"f14":"久联发展"}]}});
2.接下来就是代码时间,先import urllib,json,ssl
def getHtml(url):
mm=data_config.Http_Request()
request = urllib.request.Request(url, headers=mm.get_header())
html = urllib.request.urlopen(request).read().decode('utf-8')
pos_start = html.find("[")#截取以'['开头的
pos_end = html.find("]")
data = html[pos_start:pos_end+1]#将内容以所示条件剪切
return data这里是url就是我们最上面那串url,mm是我自己编辑的模块进行实例化,headers是自己虚拟一个访问地址,在network的header中也可以复制下来直接用,此时返回的data就是一串列表,其中有多个字典,每个字典就是一个个股。
这里我为了通俗易懂把f开头的全部换成了对应的中文,比如:
stocks,temp = [],{}
code =json.loads(getHtml(detail_url))
for name in code:
if(name["f2"]!="-"):#所有未退市的股票
temp["stock_code"]=name["f12"]#写入字典
temp["stock_name"]=name["f14"]#写入字典
temp["secid"]=name["f13"]#写入字典
stocks.append(temp.copy())#将字典存入列表以组成json,必须用copy()
temp.clear()#再清空,因为一次存一个
#存入json文件
with open("stocks.json",'w') as f:
json.dump(stocks, f, ensure_ascii=False, indent=4)#第二个参数是防止中文乱码,第三个参数是排列最后存入文件的效果就是:
[
{
"stock_code": "000892",
"stock_name": "欢瑞世纪",
"secid": 0
},
{
"stock_code": "002641",
"stock_name": "永高股份",
"secid": 0
},
{
"stock_code": "601236",
"stock_name": "红塔证券",
"secid": 1
},
{
"stock_code": "002860",
"stock_name": "星帅尔",
"secid": 0
}
]做到这里我们已经获取到了所有未退市的股票。但我们的目的是获取所有股票的详细信息,所有此时我们才开始。
3.访问东方财富任意一个股票详细页面:例如TCL集团的详细页面
可以看到我们访问也这个页面需要我们刚刚所获取的stock_code,然后同样的进入NetWork去找到请求,如下图:
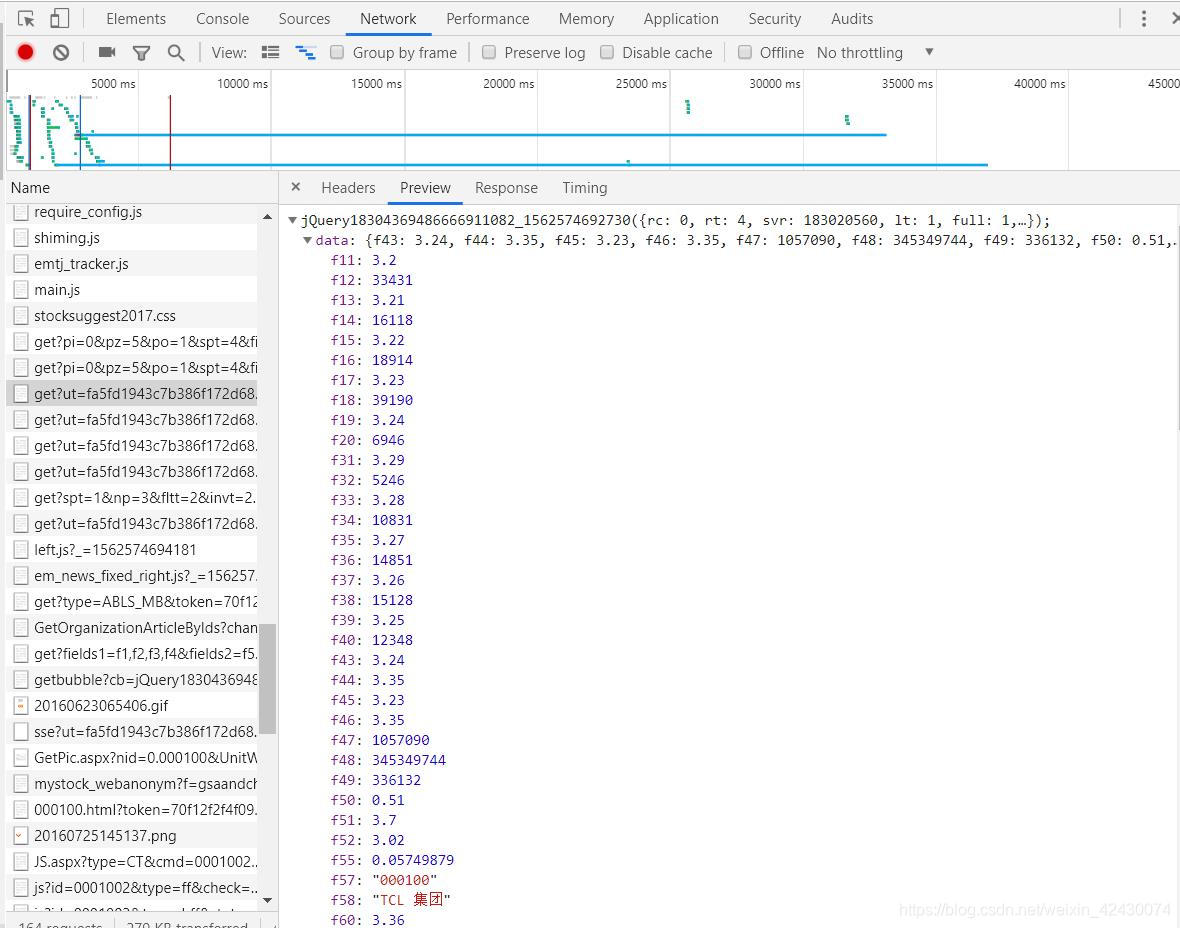
这是发送请求url
可以观察到fields有很多数据,选一些你需要的数据即可,还有secid=0.000100,这不就是我们上面抓的secid和stock_code吗,原来要组合拼接才行,每个股票的secid都不同,所以我们刚刚才需要抓取。
既然目标找到了,就开始动手敲代码了。
这里我又引入了 import re,datetime,threading,time,queue
def get_detail(secid,code_number,qq):
#fltt是控制小数点的,secid是控制股票代号
url = data_config.Get_Detail_Info_Url+'secid='+str(secid)+'.'+str(code_number)
code =json.loads(getHtml(url))
#qq.put(data_config.Choose_detail.judge_one(code))
qq.put(code['f58'])
start= datetime.datetime.now()#开始时间
num=0
with open('stocks.json') as j:
q=Queue()#只能用queue来取出thread中的值
threads=[]
for sc in json.load(j):
num=num+1;
t1 = threading.Thread(target=get_detail, args=(sc['secid'],sc['stock_code'],q))
t1.start()
threads.append(t1)
results=[]
for s in range(num):
print(q.get()+str(s))
print("--------总计算量:%d--------" % num)
end=datetime.datetime.now()#结束时间
print('--运行时间: %s秒--'%(end-start))这里我用了多线程,因为不用线程的化抓取所有代码要花12分钟左右,而用了线程后只要1分钟不到,此时我qq.put(code['f58'])只是一个股票的名称(为了先更好的展示效果)。
然后我们返回的json是这种格式
jQuery18304369486666911082_1562574692730({"rc":0,"rt":4,"svr":183023622,"lt":1,"full":1,"data":{"f43":3.24,"f55":0.05749879,"f62":1,"f71":3.27,"f78":0,"f80":"[{\"b\":201907080930,\"e\":201907081130},{\"b\":201907081300,\"e\":201907081500}]","f84":13549648507.0,"f85":12694467190.0,"f86":1562571063,"f92":2.1955947,"f104":0.0,"f105":779088389.0,"f107":0,"f110":0,"f111":6,"f117":41130073695.600009,"f127":"电子元件","f128":"广东板块","f140":-49920567.0,"f143":-34825721.0,"f146":11156488.0,"f147":151476020.0,"f148":77886220.0,"f149":73589800.0,"f162":14.09,"f173":2.54,"f177":1089,"f183":29600956875.0,"f184":15.494096692427183,"f185":6.6022,"f186":17.451900000000003,"f187":2.63,"f188":68.05525926224941,"f189":20040130,"f190":0.6877349019412463,"f191":32.48,"f192":56195,"f193":-24.54,"f194":-14.46,"f195":-10.08,"f196":3.23,"f197":21.31,"f199":90,"f250":"-","f251":"-","f252":"-","f253":"-","f254":"-","f255":0,"f256":"-","f257":37312,"f258":"-","f262":"-","f263":0,"f264":"-","f266":"-","f267":"-","f268":"-","f269":"-","f270":0,"f271":"-","f273":"-","f274":"-","f275":"-","f280":"-","f281":"-","f282":"-","f284":0,"f285":"-","f286":0,"f287":"-"}});
但这并不是我们想要的,所有我们要用正则表达式获取从第2个"{"开始的到导数第2个"}"。
def getHtml(url):#获取个股详细字典
global res
mm=data_config.Http_Request()
request = urllib.request.Request(url, headers=mm.get_header())
while True: #循环抓取直到没异常发生
try:
html = urllib.request.urlopen(request)
res = re.search(r"(:{1})+(\{.+\})", html.read().decode('utf-8')).group()[1:-1]
break
except:
time.sleep(3)
pass
return res这里必须要用循环异常处理,因为多次访问一个网站,他会断开你的连接,所有必须要循环执行,这是血的教训。
4.下面展示效果。
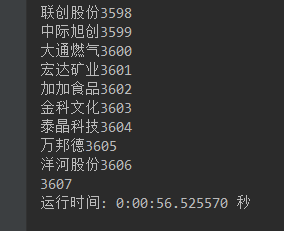

















 3906
3906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









