






0、环境检查
主机信息
| 主机地址 | 主机名 | 部署应用 |
|---|---|---|
| 192.168.75.140 | node01 | zookeeper-3.7.1+hdfs-3.3.5+hbase-2.5.2 |
| 192.168.75.141 | node02 | zookeeper-3.7.1+hdfs-3.3.5+hbase-2.5.2 |
| 192.168.75.142 | node03 | zookeeper-3.7.1+hdfs-3.3.5+hbase-2.5.2 |
基础环境配置:
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
#关闭seLinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
setenforce 0
getenforce
#主机上分别设置主机名
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
#配置主机hosts
cat <<EOF >>/etc/hosts
192.168.75.140 node01
192.168.75.141 node02
192.168.75.142 node03
EOF
#配置主机之间免密登录,每台主机上执行,回车
ssh-keygen -t rsa
#每台主机都要执行
ssh-copy-id -i /root/.ssh/id_rsa node01
ssh-copy-id -i /root/.ssh/id_rsa node02
ssh-copy-id -i /root/.ssh/id_rsa node03
安装包下载
https://archive.apache.org/dist/
安装包上传到主机 /opt/file,批量解压:
for i in `ls /opt/file`;do tar -xzvf $i -C /opt;done
1、zookeeper部署
1、安装jdk-1.8.0
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
2、配置zk:cat conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/apache-zookeeper-3.7.1-bin/zkdata/
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
#在每个节点上创建myid文件
touch /opt/apache-zookeeper-3.7.1-bin/zkdata/myid
#根据zoo.cfg配置,分别写入对应的myid
#比如,node01
echo 1 > /opt/apache-zookeeper-3.7.1-bin/zkdata/myid
#node02
echo 2 > /opt/apache-zookeeper-3.7.1-bin/zkdata/myid
启动zookeeper
#启动
./zkServer.sh start
#停止
./zkServer.sh stop
#查看zk状态
./zkServer.sh status
理论性说明
1、zookeeper原理
主要功能
协调服务,实现集群的高可用。实际生产环境的集群搭建,需要我们使用Zookeeper的协调服务(如心跳机制)来保证集群节点的高可用,并实现故障节点自动切换、数据自动迁移。
工作原理
zookeeper是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。通过选举机制来确保服务的状态的稳定性和可靠性。zookeeper集群的选举机制要求集群的节点数量为奇数个,在集群启动的时候,集群中大多数的机器得到像应开始选举,并最终选出一个节点为leader,其他节点都是follwer,然后进行数据同步。
zookeeper为什么总是奇数个?
zookeeper有这样一个特性:集群中只要有超过过半的机器是正常工作的,那么整个集群对外就是可用的。
也就是说如果有2个zookeeper,那么只要有1个死了,zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;
同理,要是有3个zookeeper,一个死了,还剩2个正常的,过半了,所以3个zookeeper的容忍度为1;
同理你多列举几个:2->0 ; 3->1 ; 4->1 ; 5->2 ; 6->2。。。会发现一个规律,2n个2n-1的容忍度都是一样的,既然一样,为了更加高效何必增加那一个不必要的zookeeper呢。
2、hadoop部署
架构图

配置文件
[root@node01 bin]# ll /opt/hadoop-3.3.5/etc/hadoop/
total 176
-rw-r--r--. 1 2002 2002 9213 Mar 16 00:36 capacity-scheduler.xml
-rw-r--r--. 1 2002 2002 1335 Mar 16 00:38 configuration.xsl
-rw-r--r--. 1 2002 2002 2567 Mar 16 00:36 container-executor.cfg
-rw-r--r-- 1 2002 2002 1368 Jul 7 15:58 core-site.xml
-rw-r--r--. 1 2002 2002 3999 Mar 15 23:57 hadoop-env.cmd
-rw-r--r-- 1 2002 2002 16699 Jul 10 10:37 hadoop-env.sh
-rw-r--r--. 1 2002 2002 3321 Mar 15 23:57 hadoop-metrics2.properties
-rw-r--r--. 1 2002 2002 11765 Mar 15 23:57 hadoop-policy.xml
-rw-r--r--. 1 2002 2002 3414 Mar 15 23:57 hadoop-user-functions.sh.example
-rw-r--r--. 1 2002 2002 683 Mar 16 00:07 hdfs-rbf-site.xml
-rw-r--r-- 1 2002 2002 4080 Jul 10 10:02 hdfs-site.xml
-rw-r--r--. 1 2002 2002 1484 Mar 16 00:06 httpfs-env.sh
-rw-r--r--. 1 2002 2002 1657 Mar 16 00:06 httpfs-log4j.properties
-rw-r--r--. 1 2002 2002 620 Mar 16 00:06 httpfs-site.xml
-rw-r--r--. 1 2002 2002 3518 Mar 15 23:58 kms-acls.xml
-rw-r--r--. 1 2002 2002 1351 Mar 15 23:58 kms-env.sh
-rw-r--r--. 1 2002 2002 1860 Mar 15 23:58 kms-log4j.properties
-rw-r--r--. 1 2002 2002 682 Mar 15 23:58 kms-site.xml
-rw-r--r--. 1 2002 2002 13700 Mar 15 23:57 log4j.properties
-rw-r--r--. 1 2002 2002 951 Mar 16 00:38 mapred-env.cmd
-rw-r--r--. 1 2002 2002 1764 Mar 16 00:38 mapred-env.sh
-rw-r--r--. 1 2002 2002 4113 Mar 16 00:38 mapred-queues.xml.template
-rw-r--r--. 1 2002 2002 758 Mar 16 00:38 mapred-site.xml
drwxr-xr-x. 2 2002 2002 24 Mar 15 23:57 shellprofile.d
-rw-r--r--. 1 2002 2002 2316 Mar 15 23:57 ssl-client.xml.example
-rw-r--r--. 1 2002 2002 2697 Mar 15 23:57 ssl-server.xml.example
-rw-r--r--. 1 2002 2002 2681 Mar 16 00:02 user_ec_policies.xml.template
-rw-r--r--. 1 2002 2002 10 Mar 15 23:57 workers
-rw-r--r--. 1 2002 2002 2250 Mar 16 00:36 yarn-env.cmd
-rw-r--r--. 1 2002 2002 6329 Mar 16 00:36 yarn-env.sh
-rw-r--r--. 1 2002 2002 2591 Mar 16 00:36 yarnservice-log4j.properties
-rw-r--r--. 1 2002 2002 690 Mar 16 00:36 yarn-site.xml
1、配置环境变量
#vi /root/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#载入环境变量
source /root/.bashrc
2、配置core-site.yaml
<configuration>
<!-- 指定hdfs的nameservice为myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.5/hdfsdata/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
3、配置hdfs-site.yaml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.3.5/hdfsdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-3.3.5/hdfsdata/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>node01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn1</name>
<value>node01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn2</name>
<value>node02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn2</name>
<value>node02:50070</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/myha01</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.3.5/hdfsdata/dfs/data/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myha01</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
4、配置hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.372.b07-1.el7_9.x86_64/jre
5、集群第一次初始化的时候,在node01格式化namenode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format
scp -r /opt/hadoop-3.3.5/hdfsdata/ node02:/opt/hadoop-3.3.5/
启动hdfs服务
/opt/hadoop-3.3.5/sbin/start-dfs.sh
3、hbase部署
HBase简介
什么是HBase
HBase是 Google 的 Bigtable 开发的java版本。是一个建立在 HDFS 之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式(实时读写nosql)数据库。
HBase是列式NoSql数据库。Hbase中仅支持的数据类型为byte[];它主要用来存储结构化和半结构化的松散数据。
HBase可以理解为一个非常大的分布式HashMap,在hadoop集群的各个节点中以行主键+列族(包含列)+时间戳为键,以储存的值为值。
与hadoop一样,Hbase主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase 特点
HBase中的表一般有这样的特点:
大: 一个表可以有上十亿行,上百万列
面向列: 面向列(族)的存储和权限控制,列(族)独立检索。
稀疏: 对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase的特点:
海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据;同时能够达到随机读取20~100k ops/s(每秒操作次数)的速度。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。需要注意的是,列族理论上可以很多,但实际上建议不要超过6个。
极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,扩展的机器可以达到20000+,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。通过横向添加Datanode的机器,进行HDFS存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几IO延迟下降并不多。能获得高并发、低延迟的服务。
稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
ZooKeeper集群协调一致性服务
ZooKeeper集群协调一致性服务可以分为如下三种功能:
协调监督保障 HMaster 高可用
只有一个HMaster,如果HMaster异常或死亡,则通过Failover 竞争机制产生新的HMaster。如何选举HMaster,有点类似 ZooKeeper的选举机制
监控HRegionServer的状态
当HRegionServer异常时,HMaster会通过Zookeeper收到HRegionServer上下线状态
元数据入口地址
ROOT表在哪台服务器上,ROOT这张表的位置信息;存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family

HMaster节点
HMaster节点的功能总结如下:
故障转移: 监控HRegionServer,当某HRegionServer异常或死亡,将HRegion转移到其他HRegionServer上执行(通过与zookeeper的Heartbeat和监听ZooKeeper中的状态,并不直接和slave相连)
新HRegion分配: HRegion分裂后的重新分配
元数据变更(Admin职能): 增删改 Table 操作
数据负载均衡: 空闲时在HRegionServer之间迁移HRegion
发送自己位置给Client: 借Zookeeper实现
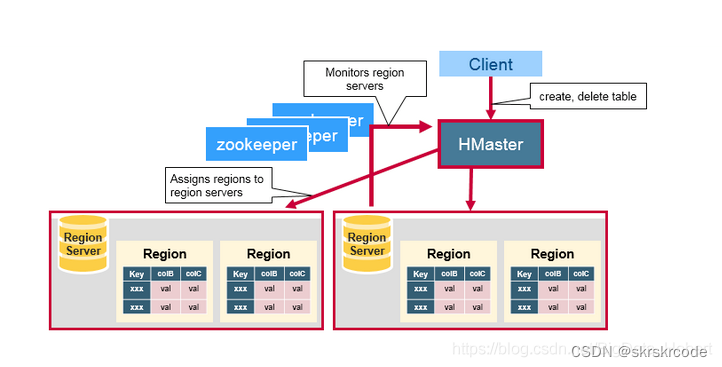
HRegionServer节点
HRegionServer节点的功能总结如下:
处理分配的HRegion
刷新Cache(读写缓存)到HDFS
维护WAL(Write Ahead Log, HLog)(高容错)
处理来之用户Clinet的读写请求
处理HRegion变大后的拆分
负责StoreFile的合并工作

可以看到,client 访问 hbase 上数据的过程并不需要master参与(寻址访问 zookeeper 和 region server,数据读写访问regione server),master 仅仅维护者table和region的元数据信息,负载很低。
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空,类似链表),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。
1、Table 中的所有行都按照 RowKey 的字典顺序进行排列;HBase就是一个庞大的HashMap, RowKey 的字典顺序就类似HashMap中key的哈希算法排序的。
2、Table 在行的方向上分割为多个 HRegion,类似于hadoop下mapreduce中的文件切割。
3、HRegion 是按大小分割的(默认为 10G),每个表一开始只有一个 HRegion,随着表中的数据不断增加,HRegion 不断增大,当增大到一个阈值的时候,HRegion 就会等分为两个新的 HRegion,当表中的行不断增多,就会有越来越多的 HRegion。
4、HRegion 是 HBase 中分布式存储和负载均衡的最小单元。 最小单元就表示不同的 HRegion 可以分布在不同的 HRegionServer 上。但是一个 HRegion 是不会拆分到多个 Server 上的。
5、HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion 是由一个或多个 Store 组成,每个 Store 保存一个 Column Family。每个 Store 又由一个 MemStore 和 0 到多个 StoreFile 组成。
HDFS
提供元数据和表数据的底层分布式存储服务
WAL(Write Ahead Log, HLog)落盘
数据多副本,保证的高可靠和高可用性
1、修改hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://myha01//hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<!-- 指定缓存文件存储的路径 -->
<property>
<name>hbase.tmp.dir</name>
<value>/tmp/hbase-${user.name}</value>
</property>
<!-- 指定Zookeeper数据存储的路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase-2.5.2/zookeeperData</value>
</property>
<!-- 完全分布式式必须为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
创建指定Zookeeper数据存储的路径
mkdir -p /opt/hbase-2.5.2/zookeeperData
注意:hbase-site.xml 的 hbase.rootdir 的 value 值(包括主机和端口号)与 core-site.xml 的 fs.default.name 的 value 值(包括主机和端口号)一致
2、配置 hbase-env.sh
#jdk替换成实际的
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.372.b07-1.el7_9.x86_64/jr
#Hbase 底层存储依靠 HDFS,因此需要 hadoop 配置参数,hadoop 路径换成实际路径
export HBASE_CLASSPATH=/opt/hadoop-3.3.5/etc/hadoop
#Hbase 如果使用自带的 zookeeper 则设置为 true,如果依赖外部 zookeeper,则设置为 false
export HBASE_MANAGES_ZK=false
#启动时告诉HBase是否应该包含Hadoop的lib
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
3、配置 regionservers
vi regionservers
#配置部署的地址
node01
node02
node03
4、配置环境变量
vi /root/.bashrc
export HBASE_HOME=/opt/hbase-2.5.2/
export PATH=$PATH:$HBASE_HOME/bin
5、启动
start-hbase.sh
jps查看

6、访问portal页面
http://192.168.75.141:16010/master-status
架构
集群整体架构图

常用命令
1、zookeeper
在这里插入代码片
2、hadoop
状态检查
#状态检查
hdfs haadmin -getAllServiceState
#查看namenode是否是安全状态
hadoop dfsadmin -safemode get
#离开安全模式
hadoop dfsadmin -safemode leave
#进入安全模式(hadoop启动时30秒内是安全状态)
hadoop dfsadmin -safemode enter
3、hbase
#打开hbase shell
hbase shell
#查看服务器状态
status
#查看所有的表
list
#用户权限管理
grant '用户名' ,'RWXCA'
#查看命名空间
list_namespace
#查看命名空间下的表
list_namespace_tables 'events_db'
















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









