







一、概述
1. 介绍
动态模型可以类比高斯混合模型这种静态模型,高斯混合模型的特点是“混合”,动态模型的特点是在“混合”的基础上加入了“时间”。动态模型包括多种模型:
D y n a m i c M o d e l { H M M K a l m a n F i l t e r P a r t i c l e F i l t e r Dynamic\; Model\left\{\begin{matrix} HMM\\ Kalman\; Filter\\ Particle\; Filter \end{matrix}\right. DynamicModel⎩⎨⎧HMMKalmanFilterParticleFilter
隐马尔可夫模型是动态模型的一种,它的状态空间是离散的,而另外两种动态模型的状态空间是连续的。
2. 模型
隐马尔可夫模型的概率图模型如下:
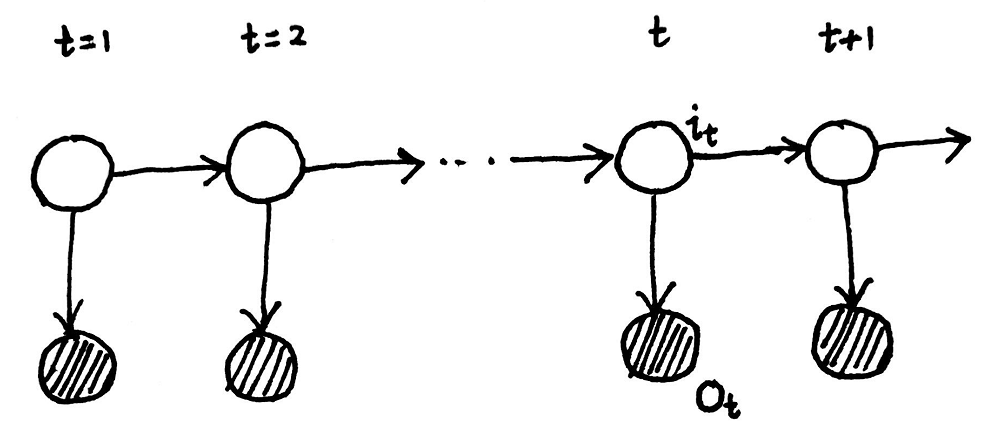
上图中 t t t代表时刻,阴影部分为观测变量序列 O O O,非阴影部分为状态变量序列 I I I,另外我们定义观测变量取值的集合为 V V V,状态变量取值的集合为 Q Q Q:
O = o 1 , o 2 , ⋯ , o t → V = { v 1 , v 2 , ⋯ , v m } I = i 1 , i 2 , ⋯ , i t → Q = { q 1 , q 2 , ⋯ , q n } O=o_{1},o_{2},\cdots ,o_{t}\rightarrow V=\left \{v_{1},v_{2},\cdots ,v_{m}\right \}\\ I=i_{1},i_{2},\cdots ,i_{t}\rightarrow Q=\left \{q_{1},q_{2},\cdots ,q_{n}\right \} O=o1,o2,⋯,ot→V={v1,v2,⋯,vm}I=i1,i2,⋯,it→Q={q1,q2,⋯,qn}
隐马尔可夫模型的参数用 λ \lambda λ表达:
λ = ( π , A , B ) \lambda =(\pi ,A,B) λ=(π,A,B)
其中 π \pi π为初始概率分布,是一个多维向量; A A A为状态转移矩阵; B B B为发射矩阵:
π = ( π 1 , π 2 , ⋯ , π N ) , ∑ i = 1 N π i = 1 A = [ a i j ] , a i j = P ( i t + 1 = q j ∣ i t = q i ) B = [ b j ( k ) ] , b j ( k ) = P ( o t = v k ∣ i t = q i ) \pi =(\pi _{1},\pi _{2},\cdots ,\pi _{N}),\sum_{i=1}^{N}\pi _{i}=1\\ A=[a_{ij}],a_{ij}=P(i_{t+1}=q_{j}|i_{t}=q_{i})\\ B=[b_{j}(k)],b_{j}(k)=P(o_{t}=v_{k}|i_{t}=q_{i}) π=(π1,π2,⋯,πN),i=1∑Nπi=1A=[aij],aij=P(it+1=qj∣it=qi)B=[bj(k)],bj(k)=P(ot=vk∣it=qi)
3. 两个假设
- 齐次马尔可夫假设
任意时刻的状态只依赖于前一时刻的状态,即:
P ( i t + 1 ∣ i t , i t − 1 , ⋯ , i 1 , o t , o t − 1 , ⋯ , o 1 ) = P ( i t + 1 ∣ i t ) P(i_{t+1}|i_{t},i_{t-1},\cdots ,i_{1},o_{t},o_{t-1},\cdots ,o_{1})=P(i_{t+1}|i_{t}) P(it+1∣it,it−1,⋯,i1,ot,ot−1,⋯,o1)=P(it+1∣it)
- 观测独立假设
任意时刻的观测只依赖于当前时刻的状态,即:
P ( o t ∣ i t , i t − 1 , ⋯ , i 1 , o t − 1 , ⋯ , o 1 ) = P ( o t ∣ i t ) P(o_{t}|i_{t},i_{t-1},\cdots ,i_{1},o_{t-1},\cdots ,o_{1})=P(o_{t}|i_{t}) P(ot∣it,it−1,⋯,i1,ot−1,⋯,o1)=P(ot∣it)
4. 三个问题
- Evaluation
已知模型的参数 λ = ( π , A , B ) \lambda =(\pi ,A,B) λ=(π,A,B),计算某个观测序列发生的概率,即求:
P ( O ∣ λ ) P(O|\lambda ) P(O∣λ)
- Learning
已知观测序列,使用EM算法求参数 λ \lambda λ:
λ M L E = a r g m a x λ P ( O ∣ λ ) \lambda _{MLE}=\underset{\lambda }{argmax}\; P(O|\lambda ) λMLE=λargmaxP(O∣λ)
- Decoding
已知观测序列 O O O和参数 λ \lambda λ,求使概率 P ( I ∣ O ) P(I|O) P(I∣O)最大的状态序列 I I I,即:
I ^ = a r g m a x I P ( I ∣ O ) \hat{I}=\underset{I}{argmax}\; P(I|O) I^=IargmaxP(I∣O)
二、Evaluation问题
对于下图中的隐马尔可夫模型,Evaluation问题是在已知参数 λ \lambda λ的情况下,求解 P ( O ∣ λ ) P(O|\lambda ) P(O∣λ):
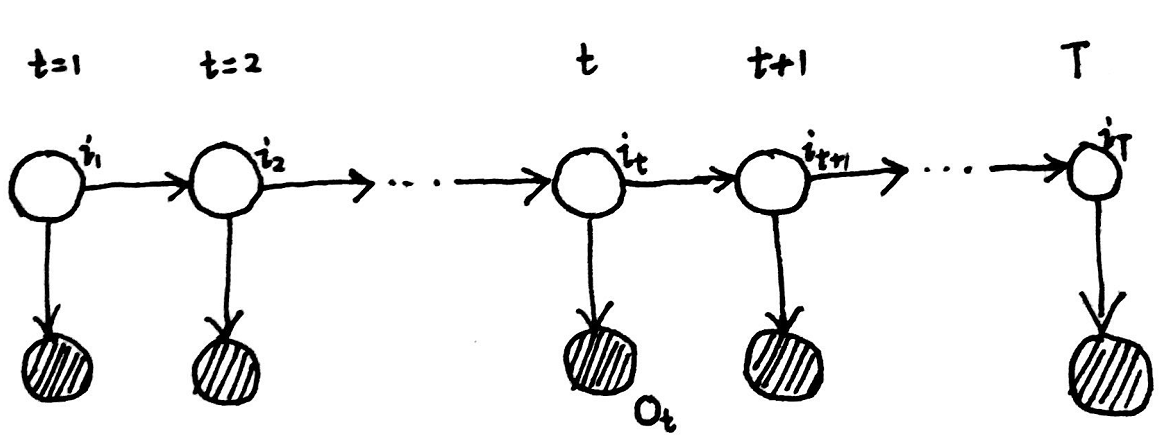
1. 前向算法
首先我们有:
P ( O ∣ λ ) = ∑ I P ( I , O ∣ λ ) = ∑ I P ( O ∣ I , λ ) P ( I ∣ λ ) P(O|\lambda )=\sum _{I}P(I,O|\lambda )=\sum _{I}P(O|I,\lambda )P(I|\lambda ) P(O∣λ)=I∑P(I,O∣λ)=I∑P(O∣I,λ)P(I∣λ)
对于上式中的 P ( I ∣ λ ) P(I|\lambda ) P(I∣λ),有:
P ( I ∣ λ ) = P ( i 1 , i 2 , ⋯ , i T ∣ λ ) = P ( i T ∣ i 1 , i 2 , ⋯ , i T − 1 , λ ) ⋅ P ( i 1 , i 2 , ⋯ , i T − 1 ∣ λ ) 根 据 齐 次 M a r k o v 假 设 : P ( i t ∣ i 1 , i 2 , ⋯ , i t − 1 , λ ) = P ( i t ∣ i t − 1 ) = a i t − 1 i t 所 以 : P ( I ∣ λ ) = π ( i 1 ) ∏ t = 2 T a i t − 1 i t P(I|\lambda )=P(i_{1},i_{2},\cdots ,i_{T}|\lambda )=P(i_{T}|i_{1},i_{2},\cdots ,i_{T-1},\lambda )\cdot P(i_{1},i_{2},\cdots ,i_{T-1}|\lambda )\\ 根据齐次Markov假设:\\ P(i_{t}|i_{1},i_{2},\cdots ,i_{t-1},\lambda )=P(i_{t}|i_{t-1})=a_{i_{t-1}i_{t}}\\ 所以:\\P(I|\lambda )=\pi (i_{1})\prod_{t=2}^{T}a_{i_{t-1}i_{t}} P(I∣λ)=P(i1,i2,⋯,iT∣λ)=P(iT∣i1,i2,⋯,iT−1,λ)⋅P(i1,i2,⋯,iT−1∣λ)根据齐次Markov假设:P(it∣i1,i2,⋯,it−1,λ)=P(it∣it−1)=ait−1it所以:P(I∣λ)=π(i1)t=2∏Tait−1it
对于上式中的 P ( O ∣ I , λ ) P(O|I,\lambda ) P(O∣I,λ),有:
P ( O ∣ I , λ ) = ∏ i = 1 T b i t ( o t ) P(O|I,\lambda )=\prod_{i=1}^{T}b_{i_{t}}(o_{t}) P(O∣I,λ)=i=1∏Tbit(ot)
因此可得:
P ( O ∣ λ ) = ∑ I π ( i 1 ) ∏ t = 2 T a i t − 1 i t ∏ i = 1 T b i t ( o t ) = ∑ i 1 ∑ i 2 ⋯ ∑ i T π ( i 1 ) ∏ t = 2 T a i t − 1 i t ∏ i = 1 T b i t ( o t ) ⏟ 复 杂 度 : O ( N T ) P(O|\lambda )=\sum _{I}\pi (i_{1})\prod_{t=2}^{T}a_{i_{t-1}i_{t}}\prod_{i=1}^{T}b_{i_{t}}(o_{t})=\underset{复杂度:O(N^{T})}{\underbrace{\sum _{i_{1}}\sum _{i_{2}}\cdots \sum _{i_{T}}\pi (i_{1})\prod_{t=2}^{T}a_{i_{t-1}i_{t}}\prod_{i=1}^{T}b_{i_{t}}(o_{t})}} P(O∣λ)=I∑π(i1)t=2∏Tait−1iti=1∏Tbit(ot)=复杂度:O(NT) i1∑i2∑⋯iT∑π(i1)t=2∏Tait−1iti=1∏Tbit(ot)
上面的求和是对所有的观测变量求和,所以复杂度为 O ( N T ) O(N^{T}) O(NT)
下面记:
α t ( i ) = P ( o 1 , o 2 , ⋯ , o t , i t = q i ∣ λ ) \alpha _{t}(i)=P(o_{1},o_{2},\cdots ,o_{t},i_{t}=q_{i}|\lambda ) αt(i)=P(o1,o2,⋯,ot,it=qi∣λ)
所以:
α T ( i ) = P ( O , i T = q i ∣ λ ) \alpha _{T}(i)=P(O,i_{T}=q_{i}|\lambda ) αT(i)=P(O,iT=qi∣λ)
所以可以得到:
P ( O ∣ λ ) = ∑ i = 1 N P ( O , i t = q i ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda )=\sum_{i=1}^{N}P(O,i_{t}=q_{i}|\lambda )=\sum_{i=1}^{N}\alpha _{T}(i) P(O∣λ)=i=1∑NP(O,it=qi∣λ)=i=1∑NαT(i)
对于 α t + 1 ( j ) \alpha _{t+1}(j) αt+1(j):
α t + 1 ( j ) = P ( o 1 , ⋯ , o t , o t + 1 , i t + 1 = q j ∣ λ ) = ∑ i = 1 N P ( o 1 , ⋯ , o t , o t + 1 , i t + 1 = q j , i t = q i ∣ λ ) = ∑ i = 1 N P ( o t + 1 ∣ o 1 , ⋯ , o t , i t = q i , i t + 1 = q j , λ ) P ( o 1 , ⋯ , o t , i t = q i , i t + 1 = q j ∣ λ ) = ∑ i = 1 N P ( o t + 1 ∣ i t + 1 = q j , λ ) P ( o 1 , ⋯ , o t , i t = q i , i t + 1 = q j ∣ λ ) = ∑ i = 1 N b j ( o t + 1 ) P ( i t + 1 = q j ∣ o 1 , ⋯ , o t , i t = q i , λ ) P ( o 1 , ⋯ , o t , i t = q i ∣ λ ) = ∑ i = 1 N b j ( o t + 1 ) P ( i t + 1 = q j ∣ i t = q i , λ ) α t ( i ) = ∑ i = 1 N b j ( o t + 1 ) a i j α t ( i ) \alpha _{t+1}(j)=P(o_{1},\cdots ,o_{t},o_{t+1},i_{t+1}=q_{j}|\lambda )\\ =\sum_{i=1}^{N}P(o_{1},\cdots ,o_{t},o_{t+1},i_{t+1}=q_{j},i_{t}=q_{i}|\lambda )\\ =\sum_{i=1}^{N}{\color{Red}{P(o_{t+1}|o_{1},\cdots ,o_{t},i_{t}=q_{i},i_{t+1}=q_{j},\lambda )}}P(o_{1},\cdots ,o_{t},i_{t}=q_{i},i_{t+1}=q_{j}|\lambda )\\ =\sum_{i=1}^{N}{\color{Red}{P(o_{t+1}|i_{t+1}=q_{j},\lambda )}}P(o_{1},\cdots ,o_{t},i_{t}=q_{i},i_{t+1}=q_{j}|\lambda )\\ =\sum_{i=1}^{N}{\color{Red}{b_{j}(o_{t+1})}}{\color{Blue}{P(i_{t+1}=q_{j}|o_{1},\cdots ,o_{t},i_{t}=q_{i},\lambda )}}{\color{DarkOrange}{P(o_{1},\cdots ,o_{t},i_{t}=q_{i}|\lambda )}}\\ =\sum_{i=1}^{N}{\color{Red}{b_{j}(o_{t+1})}}{\color{Blue}{P(i_{t+1}=q_{j}|i_{t}=q_{i},\lambda )}}{\color{Orange}{\alpha _{t}(i)}}\\ =\sum_{i=1}^{N}{\color{Red}{b_{j}(o_{t+1})}}{\color{Blue}{a_{ij}}}{\color{Orange}{\alpha _{t}(i)}} αt+1(j)=P(o1,⋯,ot,ot+1,it+1=qj∣λ)=i=1∑NP(o1,⋯,ot,ot+1,it+1=qj,it=qi∣λ)=i=1∑NP(ot+1∣o1,⋯,ot,it=qi,it+1=qj,λ)P(o1,⋯,ot,it=qi,it+1=qj∣λ)=i=1∑NP(ot+1∣it+1=qj,λ)P(o1,⋯,ot,it=qi,it+1=qj∣λ)=i=1∑Nbj(ot+1)P(it+1=qj∣o1,⋯,ot,it=qi,λ)P(o1,⋯,ot,it=qi∣λ)=i=1∑Nbj(ot+1)P(it+1=qj∣it=qi,λ)αt(i)=i=1∑Nbj(ot+1)aijαt(i)
上式利用两个假设得到了一个递推公式,这个算法叫做前向算法,其复杂度为 O ( T N 2 ) O(TN^{2}) O(TN2)。
2. 后向算法
定义:
β t ( i ) = P ( o t + 1 , ⋯ , o T ∣ i t = q i , λ ) \beta _{t}(i)=P(o_{t+1},\cdots ,o_{T}|i_{t}=q_{i},\lambda ) βt(i)=P(ot+1,⋯,oT∣it=qi,λ)
所以:
P ( O ∣ λ ) = P ( o 1 , ⋯ , o T ∣ λ ) = ∑ i = 1 N P ( o 1 , ⋯ , o T , i 1 = q i ∣ λ ) = ∑ i = 1 N P ( o 1 , ⋯ , o T ∣ i 1 = q i , λ ) P ( i 1 = q i ∣ λ ) ⏟ π i = ∑ i = 1 N P ( o 1 ∣ o 2 , ⋯ , o T , i 1 = q i , λ ) P ( o 2 , ⋯ , o T ∣ i 1 = q i , λ ) ⏟ β 1 ( i ) π i = ∑ i = 1 N P ( o 1 ∣ i 1 = q i , λ ) β 1 ( i ) π i = ∑ i = 1 N b i ( o 1 ) β 1 ( i ) π i P(O|\lambda )=P(o_{1},\cdots ,o_{T}|\lambda )\\ =\sum_{i=1}^{N}P(o_{1},\cdots ,o_{T},i_{1}=q_{i}|\lambda )\\ =\sum_{i=1}^{N}P(o_{1},\cdots ,o_{T}|i_{1}=q_{i},\lambda )\underset{\pi _{i}}{\underbrace{P(i_{1}=q_{i}|\lambda )}}\\ =\sum_{i=1}^{N}P(o_{1}|o_{2},\cdots ,o_{T},i_{1}=q_{i},\lambda )\underset{\beta _{1}(i)}{\underbrace{P(o_{2},\cdots ,o_{T}|i_{1}=q_{i},\lambda )}}\pi _{i}\\ =\sum_{i=1}^{N}P(o_{1}|i_{1}=q_{i},\lambda )\beta _{1}(i)\pi _{i}\\ =\sum_{i=1}^{N}b_{i}(o_{1})\beta _{1}(i)\pi _{i} P(O∣λ)=P(o1,⋯,oT∣λ)=i=1∑NP(o1,⋯,oT,i1=qi∣λ)=i=1∑NP(o1,⋯,oT∣i1=qi,λ)πi P(i1=qi∣λ)=i=1∑NP(o1∣o2,⋯,oT,i1=qi,λ)β1(i) P(o2,⋯,oT∣i1=qi,λ)πi=i=1∑NP(o1∣i1=qi,λ)β1(i)πi=i=1∑Nbi(o1)β1(i)πi
因此如果我们能找到 β t ( i ) \beta _{t}(i) βt(i)到 β t + 1 ( j ) \beta _{t+1}(j) βt+1(j)的递推式,就可以由通过递推得到 β 1 ( i ) \beta _{1}(i) β1(i),从而计算 P ( O ∣ λ ) P(O|\lambda ) P(O∣λ):
β t ( i ) = P ( o t + 1 , ⋯ , o T ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , ⋯ , o T , i t + 1 = q j ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , ⋯ , o T ∣ i t + 1 = q j , i t = q i , λ ) P ( i t + 1 = q j ∣ i t = q i , λ ) = ∑ j = 1 N P ( o t + 1 , ⋯ , o T ∣ i t + 1 = q j , λ ) a i j = ∑ j = 1 N P ( o t + 1 ∣ o t + 2 , ⋯ , o T , i t + 1 = q j , λ ) P ( o t + 2 , ⋯ , o T ∣ i t + 1 = q j , λ ) a i j = ∑ j = 1 N P ( o t + 1 ∣ i t + 1 = q j , λ ) β t + 1 ( j ) a i j = ∑ j = 1 N b j ( o t + 1 ) a i j β t + 1 ( j ) \beta _{t}(i)=P(o_{t+1},\cdots ,o_{T}|i_{t}=q_{i},\lambda )\\ =\sum_{j=1}^{N}P(o_{t+1},\cdots ,o_{T},i_{t+1}=q_{j}|i_{t}=q_{i},\lambda )\\ =\sum_{j=1}^{N}{\color{Red}{P(o_{t+1},\cdots ,o_{T}|i_{t+1}=q_{j},i_{t}=q_{i},\lambda)}}{\color{Blue}{P(i_{t+1}=q_{j}|i_{t}=q_{i},\lambda )}}\\ =\sum_{j=1}^{N}{\color{Red}{P(o_{t+1},\cdots ,o_{T}|i_{t+1}=q_{j},\lambda)}}{\color{Blue}{a_{ij}}}\\ =\sum_{j=1}^{N}{\color{Orange}{P(o_{t+1}|o_{t+2},\cdots ,o_{T},i_{t+1}=q_{j},\lambda)}}{\color{Orchid}{P(o_{t+2},\cdots ,o_{T}|i_{t+1}=q_{j},\lambda)}}{\color{Blue}{a_{ij}}}\\ =\sum_{j=1}^{N}{\color{Orange}{P(o_{t+1}|i_{t+1}=q_{j},\lambda)}}{\color{Orchid}{\beta _{t+1}(j)}}{\color{Blue}{a_{ij}}}\\ =\sum_{j=1}^{N}{\color{Orange}{b_{j}(o_{t+1})}}{\color{Blue}{a_{ij}}}{\color{Orchid}{\beta _{t+1}(j)}} βt(i)=P(ot+1,⋯,oT∣it=qi,λ)=j=1∑NP(ot+1,⋯,oT,it+1=qj∣it=qi,λ)=j=1∑NP(ot+1,⋯,oT∣it+1=qj,it=qi,λ)P(it+1=qj∣it=qi,λ)=j=1∑NP(ot+1,⋯,oT∣it+1=qj,λ)aij=j=1∑NP(ot+1∣ot+2,⋯,oT,it+1=qj,λ)P(ot+2,⋯,oT∣it+1=qj,λ)aij=j=1∑NP(ot+1∣it+1=qj,λ)βt+1(j)aij=j=1∑Nbj(ot+1)aijβt+1(j)
上式中红色的一步变换利用了概率图模型中有向图head to tail结构的性质:
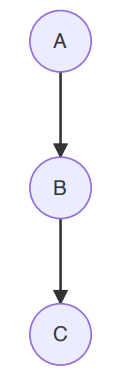
这种结构满足:
A ⊥ C ∣ B ⇔ 若 B 被 观 测 , 则 路 径 被 阻 塞 。 A\perp C|B\Leftrightarrow 若B被观测,则路径被阻塞。 A⊥C∣B⇔若B被观测,则路径被阻塞。
到此为止便得到了递推式。这就是后向算法,其复杂度也为 O ( T N 2 ) O(TN^{2}) O(TN2)。
三、Learning问题
Learning问题的目标是求解求参数 λ \lambda λ,使用的是Baum Welch算法(也就是EM算法)。
EM算法的迭代公式如下:
θ ( t + 1 ) = a r g m a x θ ∫ Z l o g P ( X , Z ∣ θ ) ⋅ P ( Z ∣ X , θ ( t ) ) d Z \theta ^{(t+1)}=\underset{\theta }{argmax}\int _{Z}log\; P(X,Z|\theta )\cdot P(Z|X,\theta ^{(t)})\mathrm{d}Z θ(t+1)=θargmax∫ZlogP(X,Z∣θ)⋅P(Z∣X,θ(t))dZ
在隐马尔可夫模型中,隐变量 Z Z Z即为 I I I,观测变量 X X X即为 O O O,参数 θ \theta θ即为 λ \lambda λ,因此隐马尔可夫模型的EM算法迭代公式可以写为:
λ ( t + 1 ) = a r g m a x λ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( I ∣ O , λ ( t ) ) \lambda ^{(t+1)}=\underset{\lambda}{argmax}\sum _{I}log\; P(O,I|\lambda )\cdot P(I|O,\lambda ^{(t)}) λ(t+1)=λargmaxI∑logP(O,I∣λ)⋅P(I∣O,λ(t))
上式中 P ( I ∣ O , λ ( t ) ) = P ( O , I ∣ λ ( t ) ) P ( O ∣ λ ( t ) ) P(I|O,\lambda ^{(t)})=\frac{P(O,I|\lambda ^{(t)})}{P(O|\lambda ^{(t)})} P(I∣O,λ(t))=P(O∣λ(t))P(O,I∣λ(t)),由于在Learning问题中,观测序列 O O O是已知的,所以 P ( O ∣ λ ( t ) ) P(O|\lambda ^{(t)}) P(O∣λ(t))是个常数,迭代公式可以写为:
λ ( t + 1 ) = a r g m a x λ ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ ( t ) ) \lambda ^{(t+1)}=\underset{\lambda}{argmax}\sum _{I}log\; P(O,I|\lambda )\cdot P(O,I|\lambda ^{(t)}) λ(t+1)=λargmaxI∑logP(O,I∣λ)⋅P(O,I∣λ(t))
根据之前的计算对 Q Q Q函数进行整理:
Q ( λ , λ ( t ) ) = ∑ I l o g P ( O , I ∣ λ ) ⋅ P ( O , I ∣ λ ( t ) ) = ∑ I [ l o g π ( i 1 ) ∏ t = 2 T a i t − 1 i t ∏ i = 1 T b i t ( o t ) ⋅ P ( O , I ∣ λ ( t ) ) ] = ∑ I [ ( l o g π ( i 1 ) + ∑ t = 2 T l o g a i t − 1 i t + ∑ i = 1 T l o g b i t ( o t ) ) ⋅ P ( O , I ∣ λ ( t ) ) ] Q(\lambda ,\lambda ^{(t)})=\sum _{I}log\; P(O,I|\lambda )\cdot P(O,I|\lambda ^{(t)})\\ =\sum _{I}[log\pi (i_{1})\prod_{t=2}^{T}a_{i_{t-1}i_{t}}\prod_{i=1}^{T}b_{i_{t}}(o_{t})\cdot P(O,I|\lambda ^{(t)})]\\ =\sum _{I}[(log\pi (i_{1})+\sum_{t=2}^{T}log\; a_{i_{t-1}i_{t}}+\sum_{i=1}^{T}log\; b_{i_{t}}(o_{t}))\cdot P(O,I|\lambda ^{(t)})] Q(λ,λ(t))=I∑logP(O,I∣λ)⋅P(O,I∣λ(t))=I∑[logπ(i1)t=2∏Tait−1iti=1∏Tbit(ot)⋅P(O,I∣λ(t))]=I∑[(logπ(i1)+t=2∑Tlogait−1it+i=1∑Tlogbit(ot))⋅P(O,I∣λ(t))]
接下来以求解 π ( t + 1 ) \pi ^{(t+1)} π(t+1)为例展示迭代的过程:
π ( t + 1 ) = a r g m a x π Q ( λ , λ ( t ) ) = a r g m a x π ∑ I l o g π ( i 1 ) ⋅ P ( O , I ∣ λ ( t ) ) = a r g m a x π ∑ i 1 ∑ i 2 ⋯ ∑ i T l o g π ( i 1 ) ⋅ P ( O , i 1 , i 2 , ⋯ , i T ∣ λ ( t ) ) = a r g m a x π ∑ i 1 l o g π ( i 1 ) ⋅ P ( O , i 1 ∣ λ ( t ) ) = a r g m a x π ∑ i = 1 N l o g π i ⋅ P ( O , i 1 = q i ∣ λ ( t ) ) \pi ^{(t+1)}=\underset{\pi }{argmax}\; Q(\lambda ,\lambda ^{(t)})\\ =\underset{\pi }{argmax}\sum _{I}log\; \pi (i_{1})\cdot P(O,I|\lambda ^{(t)})\\ =\underset{\pi }{argmax}\sum _{i_{1}}\sum _{i_{2}}\cdots \sum _{i_{T}}log\; \pi (i_{1})\cdot P(O,i_{1},i_{2},\cdots ,i_{T}|\lambda ^{(t)})\\ =\underset{\pi }{argmax}\sum _{i_{1}}log\; \pi (i_{1})\cdot P(O,i_{1}|\lambda ^{(t)})\\ =\underset{\pi }{argmax}\sum _{i=1}^{N}log\; \pi _{i}\cdot P(O,i_{1}=q_{i}|\lambda ^{(t)}) π(t+1)=πargmaxQ(λ,λ(t))=πargmaxI∑logπ(i1)⋅P(O,I∣λ(t))=πargmaxi1∑i2∑⋯iT∑logπ(i1)⋅P(O,i1,i2,⋯,iT∣λ(t))=πargmaxi1∑logπ(i1)⋅P(O,i1∣λ(t))=πargmaxi=1∑Nlogπi⋅P(O,i1=qi∣λ(t))
结合对 π \pi π的约束 ∑ i = 1 N π i = 1 \sum_{i=1}^{N}\pi _{i}=1 ∑i=1Nπi=1,构建拉格朗日函数:
L ( π , η ) = ∑ i = 1 N l o g π i ⋅ P ( O , i 1 = q i ∣ λ ( t ) ) + η ( ∑ i = 1 N π i − 1 ) L(\pi ,\eta )=\sum _{i=1}^{N}log\; \pi _{i}\cdot P(O,i_{1}=q_{i}|\lambda ^{(t)})+\eta (\sum_{i=1}^{N}\pi _{i}-1) L(π,η)=i=1∑Nlogπi⋅P(O,i1=qi∣λ(t))+η(i=1∑Nπi−1)
然后对 π i \pi _{i} πi求导:
∂ L ∂ π i = 1 π i P ( O , i 1 = q i ∣ λ ( t ) ) + η = 0 ⇒ P ( O , i 1 = q i ∣ λ ( t ) ) + π i η = 0 ⇒ ∑ i = 1 N [ P ( O , i 1 = q i ∣ λ ( t ) ) + π i η ] = 0 ⇒ P ( O ∣ λ ( t ) ) + η = 0 ⇒ η = − P ( O ∣ λ ( t ) ) 代 入 P ( O , i 1 = q i ∣ λ ( t ) ) + π i η = 0 ⇒ π i ( t + 1 ) = P ( O , i 1 = q i ∣ λ ( t ) ) P ( O ∣ λ ( t ) ) \frac{\partial L}{\partial \pi _{i}}=\frac{1}{\pi _{i}}P(O,i_{1}=q_{i}|\lambda ^{(t)})+\eta =0\\ \Rightarrow P(O,i_{1}=q_{i}|\lambda ^{(t)})+\pi _{i}\eta =0\\ \Rightarrow \sum_{i=1}^{N}[P(O,i_{1}=q_{i}|\lambda ^{(t)})+\pi _{i}\eta ]=0\\ \Rightarrow P(O|\lambda ^{(t)})+\eta =0\\ \Rightarrow \eta =-P(O|\lambda ^{(t)})\\ 代入P(O,i_{1}=q_{i}|\lambda ^{(t)})+\pi _{i}\eta =0\\ \Rightarrow \pi ^{(t+1)}_{i}=\frac{P(O,i_{1}=q_{i}|\lambda ^{(t)})}{P(O|\lambda ^{(t)})} ∂πi∂L=πi1P(O,i1=qi∣λ(t))+η=0⇒P(O,i1=qi∣λ(t))+πiη=0⇒i=1∑N[P(O,i1=qi∣λ(t))+πiη]=0⇒P(O∣λ(t))+η=0⇒η=−P(O∣λ(t))代入P(O,i1=qi∣λ(t))+πiη=0⇒πi(t+1)=P(O∣λ(t))P(O,i1=qi∣λ(t))
同样地, A ( t + 1 ) A^{(t+1)} A(t+1)和 B ( t + 1 ) B^{(t+1)} B(t+1)都以同样的方法求出,然后不断迭代直至收敛,最终求得模型的参数。
四、Decoding问题
Decoding问题是指已知观测序列 O O O和参数 λ \lambda λ,求使概率 P ( I ∣ O ) P(I|O) P(I∣O)最大的状态序列 I I I,即:
I ^ = a r g m a x I P ( I ∣ O ) \hat{I}=\underset{I}{argmax}\; P(I|O) I^=IargmaxP(I∣O)
我们采用动态规划的思想来求解这个问题,首先定义:
δ t ( i ) = m a x i 1 , i 2 , ⋯ , i t − 1 P ( o 1 , o 2 , ⋯ , o t , i 1 , i 2 , ⋯ , i t − 1 , i t = q i ) \delta _{t}(i)={\color{Red}{\underset{i_{1},i_{2},\cdots ,i_{t-1}}{max}}}P(o_{1},o_{2},\cdots ,o_{t},i_{1},i_{2},\cdots ,i_{t-1},i_{t}=q_{i}) δt(i)=i1,i2,⋯,it−1maxP(o1,o2,⋯,ot,i1,i2,⋯,it−1,it=qi)
由于参数 λ \lambda λ是已知的,为简便起见省略了 λ \lambda λ,接下来我们需要找到 δ t + 1 ( j ) \delta _{t+1}(j) δt+1(j)和 δ t ( i ) \delta _{t}(i) δt(i)之间的递推式:
δ t + 1 ( j ) = m a x i 1 , i 2 , ⋯ , i t P ( o 1 , o 2 , ⋯ , o t + 1 , i 1 , i 2 , ⋯ , i t , i t + 1 = q j ) = m a x 1 ≤ i ≤ N δ t ( i ) a i j b j ( o t + 1 ) \delta _{t+1}(j)=\underset{i_{1},i_{2},\cdots ,i_{t}}{max}P(o_{1},o_{2},\cdots ,o_{t+1},i_{1},i_{2},\cdots ,i_{t},i_{t+1}=q_{j})\\ ={\color{Red}{\underset{1\leq i\leq N}{max}}}\delta _{t}(i)a_{ij}b_{j}(o_{t+1}) δt+1(j)=i1,i2,⋯,itmaxP(o1,o2,⋯,ot+1,i1,i2,⋯,it,it+1=qj)=1≤i≤Nmaxδt(i)aijbj(ot+1)
由此我们就找到了动态规划的递推式,同时我们还需要记录路径,因此定义:
ψ t + 1 ( j ) = a r g m a x 1 ≤ i ≤ N δ t ( i ) a i j \psi _{t+1}(j)={\color{Red}{\underset{1\leq i\leq N}{argmax}}}\; \delta _{t}(i)a_{ij} ψt+1(j)=1≤i≤Nargmaxδt(i)aij
因此:
m a x P ( I ∣ O ) = m a x δ t ( i ) max\; P(I|O)=max\; \delta _{t}(i) maxP(I∣O)=maxδt(i)
使 P ( I ∣ O ) P(I|O) P(I∣O)最大的 δ t ( i ) \delta _{t}(i) δt(i)指 t t t时刻 i t = q i i_t=q_i it=qi,然后由 ψ t ( i ) \psi _{t}(i) ψt(i)得到 t − 1 t-1 t−1时刻 i t − 1 i_{t-1} it−1的取值,然后继续得到前一时刻的 i t − 2 i_{t-2} it−2时刻的取值,最终得到整个序列 I I I。
五、总结
HMM 是⼀种动态模型(Dynamic Model),是由混合树形模型和时序结合起来的⼀种模型(类似 GMM + Time)。对于类似 HMM 的这种状态空间模型(State Space Model),普遍的除了学习任务(采⽤ EM )外,还有推断任务。
使用 X X X代表观测序列, Z Z Z代表隐变量序列, λ \lambda λ代表参数。这一类模型需要求解的问题的大体框架为:
{ L e a r n i n g : λ M L E = a r g m a x λ P ( X ∣ λ ) 【 B a u m W e l c h A l g o r i t h m ( E M ) 】 I n f e r e n c e { D e c o d i n g : Z = a r g m a x Z P ( Z ∣ X , λ ) 【 V i t e r b i A l g o r i t h m 】 P r o b o f e v i d e n c e : P ( X ∣ λ ) 【 F o r w a r d A l g o r i t h m 、 B a c k w a r d A l g o r i t h m 】 F i l t e r i n g : P ( z t ∣ x 1 , x 2 , ⋯ , x t , λ ) 【 F o r w a r d A l g o r i t h m 】 S m o o t h i n g : P ( z t ∣ x 1 , x 2 , ⋯ , x T , λ ) 【 F o r w a r d − B a c k w a r d A l g o r i t h m 】 P r e d i c t i o n : { P ( z t + 1 ∣ x 1 , x 2 , ⋯ , x t , λ ) P ( x t + 1 ∣ x 1 , x 2 , ⋯ , x t , λ ) } 【 F o r w a r d A l g o r i t h m 】 \left\{\begin{matrix} Learning:\lambda _{MLE}=\underset{\lambda }{argmax}\; P(X|\lambda ){\color{Blue}{【Baum\; Welch\; Algorithm(EM)】}}\\ Inference\left\{\begin{matrix} Decoding:Z=\underset{Z}{argmax}\; P(Z|X,\lambda ){\color{Blue}{【Viterbi\; Algorithm】}}\\ Prob\; of\; evidence:P(X|\lambda ){\color{Blue}{【Forward\; Algorithm、Backward\; Algorithm】}}\\ Filtering:P(z_{t}|x_{1},x_{2},\cdots ,x_{t},\lambda ){\color{Blue}{【Forward\; Algorithm】}}\\ Smoothing:P(z_{t}|x_{1},x_{2},\cdots ,x_{T},\lambda ){\color{Blue}{【Forward-Backward\; Algorithm】}}\\ Prediction:\begin{Bmatrix} P(z_{t+1}|x_{1},x_{2},\cdots ,x_{t},\lambda )\\ P(x_{t+1}|x_{1},x_{2},\cdots ,x_{t},\lambda ) \end{Bmatrix}{\color{Blue}{【Forward\; Algorithm】}} \end{matrix}\right. \end{matrix}\right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧Learning:λMLE=λargmaxP(X∣λ)【BaumWelchAlgorithm(EM)】Inference⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧Decoding:Z=ZargmaxP(Z∣X,λ)【ViterbiAlgorithm】Probofevidence:P(X∣λ)【ForwardAlgorithm、BackwardAlgorithm】Filtering:P(zt∣x1,x2,⋯,xt,λ)【ForwardAlgorithm】Smoothing:P(zt∣x1,x2,⋯,xT,λ)【Forward−BackwardAlgorithm】Prediction:{P(zt+1∣x1,x2,⋯,xt,λ)P(xt+1∣x1,x2,⋯,xt,λ)}【ForwardAlgorithm】
接下来对Filtering&Smoothing&Prediction问题做一些说明,下面使用 x 1 : t x_{1:t} x1:t代表 x 1 , x 2 , ⋯ , x t x_{1},x_{2},\cdots ,x_{t} x1,x2,⋯,xt,同时也省略已知参数 λ \lambda λ。
1. Filtering问题
P ( z t ∣ x 1 : t ) = P ( x 1 : t , z t ) P ( x 1 : t ) = P ( x 1 : t , z t ) ∑ z t P ( x 1 : t , z t ) ∝ P ( x 1 : t , z t ) = α t P(z_{t}|x_{1:t})=\frac{P(x_{1:t},z_{t})}{P(x_{1:t})}=\frac {P(x_{1:t},z_{t})}{\sum _{z_{t}}P(x_{1:t},z_{t})} \propto P(x_{1:t},z_{t})=\alpha _{t} P(zt∣x1:t)=P(x1:t)P(x1:t,zt)=∑ztP(x1:t,zt)P(x1:t,zt)∝P(x1:t,zt)=αt
因此使用Forward Algorithm来解决Filtering问题。
Filtering问题通常出现在online learning中,当新进入一个数据,可以计算概率 P ( z t ∣ x 1 : t ) P(z_{t}|x_{1:t}) P(zt∣x1:t)。
2. Smoothing问题
P ( z t ∣ x 1 : T ) = P ( x 1 : T , z t ) P ( x 1 : T ) = P ( x 1 : T , z t ) ∑ z t P ( x 1 : T , z t ) P(z_{t}|x_{1:T})=\frac{P(x_{1:T},z_{t})}{P(x_{1:T})}=\frac{P(x_{1:T},z_{t})}{\sum _{z_{t}}P(x_{1:T},z_{t})} P(zt∣x1:T)=P(x1:T)P(x1:T,zt)=∑ztP(x1:T,zt)P(x1:T,zt)
其中:
P ( x 1 : T , z t ) = P ( x 1 : t , x t + 1 : T , z t ) = P ( x t + 1 : T ∣ x 1 : t , z t ) ⋅ P ( x 1 : t , z t ) ⏟ α t = P ( x t + 1 : T ∣ z t ) ⏟ β t ⋅ α t = α t β t P(x_{1:T},z_{t})=P(x_{1:t},x_{t+1:T},z_{t})\\ ={\color{Red}{P(x_{t+1:T}|x_{1:t},z_{t})}}\cdot \underset{\alpha _{t}}{\underbrace{P(x_{1:t},z_{t})}}\\ =\underset{\beta _{t}}{\underbrace{{\color{Red}{P(x_{t+1:T}|z_{t})}}}}\cdot \alpha _{t}\\ =\alpha _{t}\beta _{t} P(x1:T,zt)=P(x1:t,xt+1:T,zt)=P(xt+1:T∣x1:t,zt)⋅αt P(x1:t,zt)=βt P(xt+1:T∣zt)⋅αt=αtβt
红色这一步是使用了有向图的D划分的方法,有关讲解参照概率图模型-表示|机器学习推导系列(十)。这里我们定义A集合为 x 1 : t x_{1:t} x1:t,B集合为 x t + 1 : T x_{t+1:T} xt+1:T,C集合为 z t z_t zt,通过D划分的方法我们可以知道 x A ⊥ x B ∣ x C x_{A}\perp x_{B}|x_{C} xA⊥xB∣xC,即 x t + 1 : T x_{t+1:T} xt+1:T与 x 1 : t x_{1:t} x1:t是相互独立的。
由上面的式子我们可以得出:
P ( z t ∣ x 1 : T ) ∝ P ( x 1 : T , z t ) = α t β t P(z_{t}|x_{1:T})\propto P(x_{1:T},z_{t})=\alpha _{t}\beta _{t} P(zt∣x1:T)∝P(x1:T,zt)=αtβt
因此解决Smoothing问题的算法叫做Forward-Backward Algorithm。
Smoothing问题通常出现在offline learning中,当知道全部观测数据时,来计算概率 P ( z t ∣ x 1 : T ) P(z_{t}|x_{1:T}) P(zt∣x1:T)。
3. Prediction问题
P ( z t + 1 ∣ x 1 : t ) = ∑ z t P ( z t + 1 , z t ∣ x 1 : t ) = ∑ z t P ( z t + 1 ∣ z t , x 1 : t ) ⋅ P ( z t ∣ x 1 : t ) = ∑ z t P ( z t + 1 ∣ z t ) ⋅ P ( z t ∣ x 1 : t ) ⏟ F i l t e r i n g P(z_{t+1}|x_{1:t})=\sum _{z_{t}}P(z_{t+1},z_{t}|x_{1:t})\\ =\sum _{z_{t}}P(z_{t+1}|z_{t},x_{1:t})\cdot P(z_{t}|x_{1:t})\\ =\sum _{z_{t}}P(z_{t+1}|z_{t})\cdot \underset{Filtering}{\underbrace{P(z_{t}|x_{1:t})}} P(zt+1∣x1:t)=zt∑P(zt+1,zt∣x1:t)=zt∑P(zt+1∣zt,x1:t)⋅P(zt∣x1:t)=zt∑P(zt+1∣zt)⋅Filtering P(zt∣x1:t)
上式应用了齐次马尔可夫假设将预测 P ( z t + 1 ∣ x 1 : t ) P(z_{t+1}|x_{1:t}) P(zt+1∣x1:t)的问题进行了转化,使用转移概率和求解Filtering问题的方法就可以计算这个概率。
P ( x t + 1 ∣ x 1 : t ) = ∑ z t + 1 P ( x t + 1 , z t + 1 ∣ x 1 : t ) = ∑ z t + 1 P ( x t + 1 ∣ z t + 1 , x 1 : t ) ⋅ P ( z t + 1 ∣ x 1 : t ) = ∑ z t + 1 P ( x t + 1 ∣ z t + 1 ) ⋅ P ( z t + 1 ∣ x 1 : t ) ⏟ P r e c i t i o n P(x_{t+1}|x_{1:t})=\sum _{z_{t+1}}P(x_{t+1},z_{t+1}|x_{1:t})\\ =\sum _{z_{t+1}}P(x_{t+1}|z_{t+1},x_{1:t})\cdot P(z_{t+1}|x_{1:t})\\ =\sum _{z_{t+1}}P(x_{t+1}|z_{t+1})\cdot \underset{Precition}{\underbrace{P(z_{t+1}|x_{1:t})}} P(xt+1∣x1:t)=zt+1∑P(xt+1,zt+1∣x1:t)=zt+1∑P(xt+1∣zt+1,x1:t)⋅P(zt+1∣x1:t)=zt+1∑P(xt+1∣zt+1)⋅Precition P(zt+1∣x1:t)
上式应用了观测独立假设将预测 P ( x t + 1 ∣ x 1 : t ) P(x_{t+1}|x_{1:t}) P(xt+1∣x1:t)的问题进行了转化,使用发射概率和求解上一个Prediction问题的方法就可以计算这个概率。















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









