







一、Generation
generation的目的是生成有结构的某些东西,比如句子、图片等。比如我们可以使用RNN来生成句子,如下图,我们在训练RNN时可以输入当前字然后使得RNN输出下一个字,如此就可以使得模型输出一个句子:

我们也可以尝试将生成句子的RNN模型用于生成图片上,在这里我们将图片的每个像素看做一个word,如下图:

然后使用类似上面的模型进行训练就可以生成一张图片,但是使用这种方法有一个问题。我们可以看到图片的像素是按照以下顺序产生的:
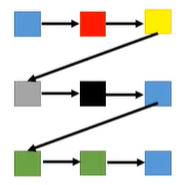
显然模型忽视了像素之间的几何关系,也就是说比如左边的像素收到上面的像素影响比收到上面右方像素的影响要大一些,而使用这种网络结构很难学到这种关系,我们希望模型能够学习到以下像素之间的相互影响关系:
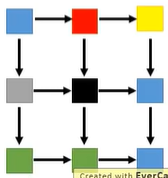
为了解决这个问题,我们可以采用3D的LSTM来进行图片的生成,如下图,每个3D LSTM的cell接受来自三个方向的输入然后向三个方向进行输出:
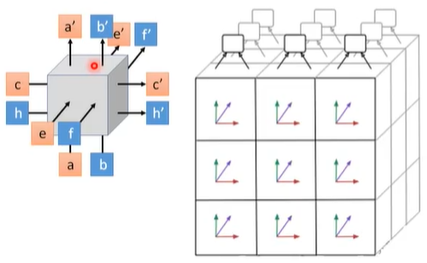
使用一个卷积核在图片上移动就可以按上述像素影响关系产生图片:

二、Conditional Generation
条件生成要求神经网络不只是随机地生成一些图片或者句子等,还要根据需要产生相应的输出,比较典型的场景如下:

- Image Caption Generation
比如一个任务是为模型输入一张图片,模型要产生图片的说明,一个可行的做法是将图片丢进一个CNN里提取特征,然后将提取到的特征向量输入到RNN里,使得RNN产生这张图片的描述,为了使得模型每个时刻的输出都会考虑到图片的影响,可以将特征向量输入给每一个时刻,该过程的流程图如下:
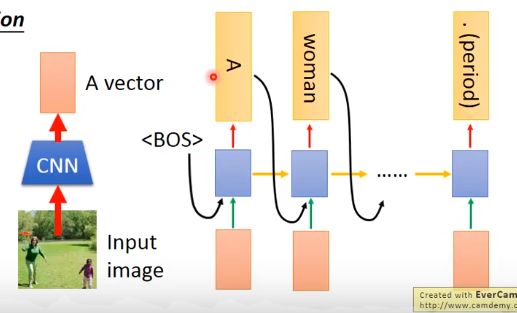
- Machine translation
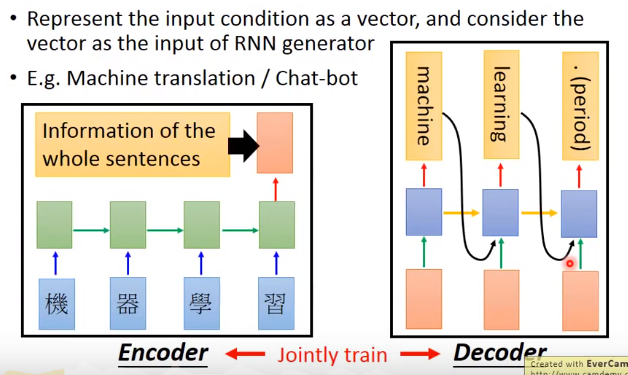
在做机器翻译时可以将中文输入到一个RNN中,然后取最后一个时间点的输出,这个输出可以认为包含了整个中文句子的信息,然后将输出的这个向量输入到另一个RNN中的每个时间点,使这个RNN来输出对应的英文翻译结果。
需要注意这里的两个RNN是一起训练的(jointly train),同时两个RNN的参数既可以使用同样的参数,也可以使用不一样的参数。通常在数据量比较小时使用同样的参数即可,这样参数比较少,比较容易避免过拟合。
- Chat-bot
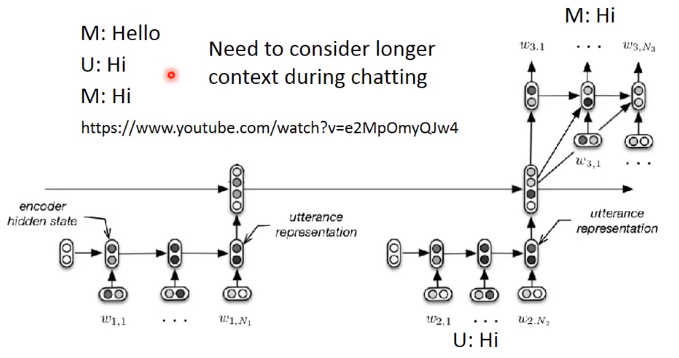
在做聊天机器人时经常会遇到一个问题,就是模型只考虑上一个时刻的状态,而忽略了之前时刻的状态,这也就导致了下图中模型会和用户打两次招呼的问题。因此我们需要模型能够考虑到longer context的影响。解决这个问题的方式是使用一个双层的Encoder,也就是再加入一个RNN来记录对话,第一层RNN会输入人和机器聊天的句子然后获得每个句子对应的输出,然后第二层RNN会将这些输出作为输入然后将自己的输出作为另一个RNN的输入来获得Chat-bot的回答:
三、Attention
- 基本过程
同样以机器翻译为例,在上面的机器翻译方法中,我们每次都把由Encoder RNN提取的包含整个序列信息的向量输入到Decoder RNN中的每个时间点,但是可以想象如果在翻译“machine”时,只关注“机器”这两个字的信息而不是整个序列的信息,翻译的效果会更好一些,同样地翻译“learning”时只关注“学习”。Attention-based model可以帮助我们做到这件事。
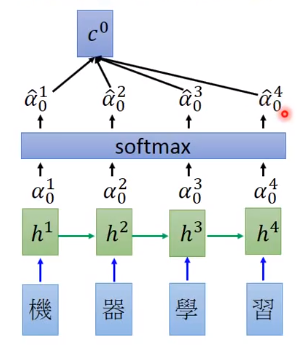
下图展示了Attention机制的流程,首先先将要翻译的序列通过RNN获取RNN的隐层的状态,然后有另一个向量 z 0 z^0 z0( z 0 z^0 z0可以当做网络的参数,可以通过学习得到), z 0 z^0 z0要和每个 h t h^t ht通过一个match函数来获得对应的每个输出标量 α 0 1 \alpha _0^1 α01。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fyU3lz4i-1604115531132)(https://upload-images.jianshu.io/upload_images/22097296-b0cbf14a964fb9f5.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/300)]
对于使用的match函数可以自定义来设计,举例来说有以下但不限于这些方式:
①计算
z
z
z和
h
h
h的余弦相似度,这时候两个向量维度要一样;
②一个小的神经网络,输入
z
z
z和
h
h
h,输出一个标量;
③
α
=
h
T
W
z
\alpha =h^TWz
α=hTWz。
如果match函数中有参数,则这些参数应该和整个网络一起学习得到:

然后将得到的每个 α \alpha α通过一个softmax层来获得和为 1 1 1的 α ^ 0 t \hat{\alpha }_{0}^{t} α^0t:
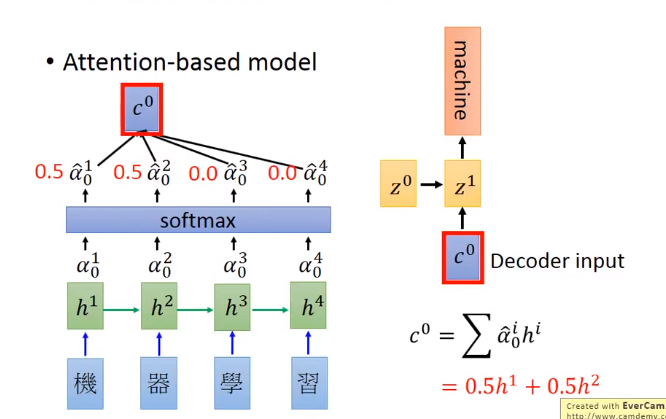
然后计算得到 c 0 c^0 c0作为翻译Decoder的输入,计算公式为:
c 0 = ∑ α 0 i h i c^{0}=\sum \alpha _{0}^{i}h^{i} c0=∑α0ihi
c 0 c^0 c0作为翻译Decoder的输入,然后Decoder RNN得到翻译结果,这里通过学习就可以得到类似下图中的 α ^ 0 t \hat{\alpha }_{0}^{t} α^0t的值,就实现了翻译“machine”时只关注“机器”:
然后用Decoder RNN的隐层状态 z 1 z^1 z1来做和 z 0 z^0 z0同样的流程:

需要注意的是这里可以用RNN的隐层状态作为 z 1 z^1 z1,但是这里的方法并不固定,比如还可以用RNN的隐层状态再通过一个隐藏层的输出作为 z 1 z^1 z1,具体方法可以自行选择,重要的是理解Attention机制。
上述过程将会一直进行下去直到翻译结束得到“.”才结束。
- 应用
- Speech Recognition
可以将Attenton机制应用在语音辨识任务上,这个任务是指将输入的声音讯号转换成文字。
下图表示了使用Attenton来做语音辨识的效果,下图中上面的声音讯号可以看做一个个列向量,下面的列向量表示了每个时刻attention的结果,黑白色块的颜色代表了attention的权重大小:

下表对比了Attenton的方法与传统的语音辨识方法:
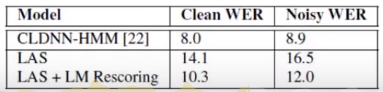
WER指字错误率,这个值越低表示识别效果越好,可以看到LAS的方法比起传统方法还是逊色了一些,LAS是指论文《Listen,Attend and Spell》中的方法,即Attention的方法。
虽然效果上不如传统方法,但是Attention的这种方法比起传统方法更加地简便,只需要直接进行训练就可以了。
- Image Caption Generation
在做图片的内容描述时也可以用到Attention这种技术,首先需要使用CNN提取特征向量,这里使用的是在将卷积核的输出作为特征向量,也就是未做flatten(展平)之前的卷积核的输出:
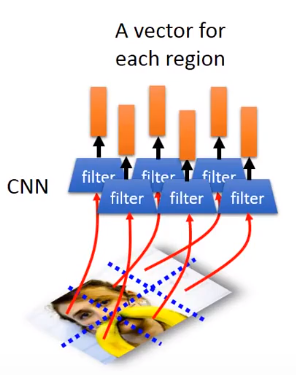
然后使用attention来使得神经网络实现“看图说话”的功能:
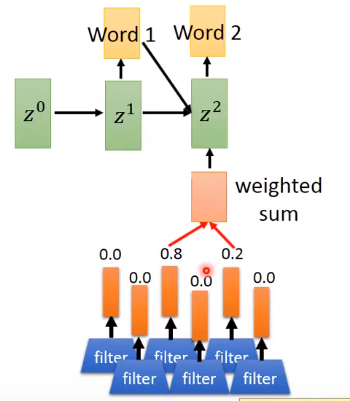
下图展示了效果,每张图的白色的地方是指在生成划线的单词时所attent到的地方:

这里也有一些失败的例子,使用Attention也可以看到为什么会产生失败的结果:

也可以用Attention来看一段视频产生一些说明,如下图,Ref指的正确的说明,柱状图和词的颜色表明了网络在产生这个说明时所attent到的视频帧:

四、Memory Network
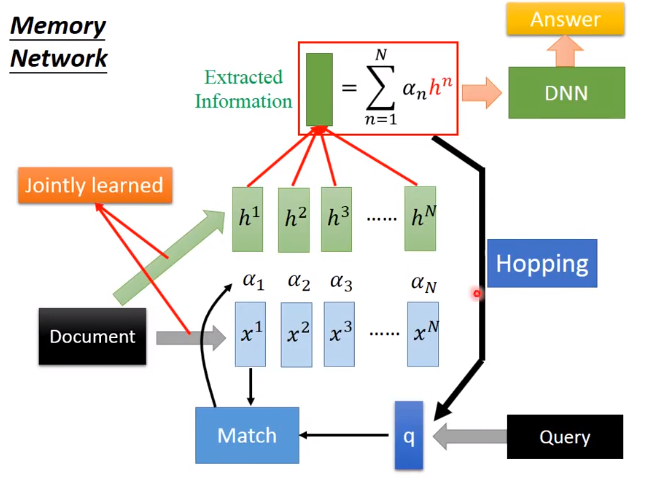
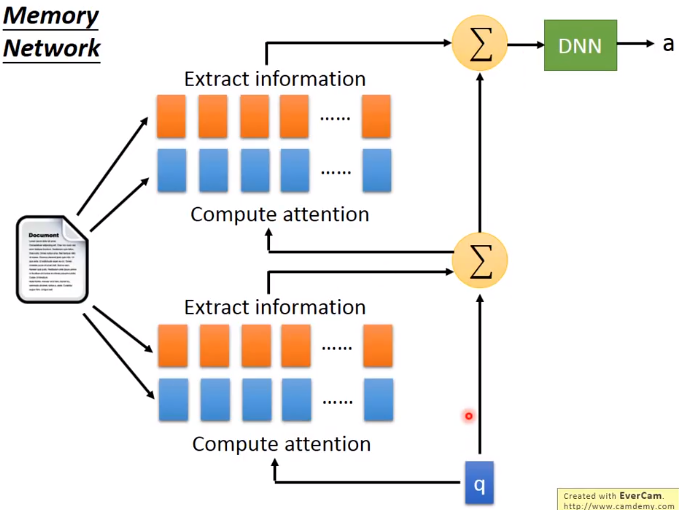
将Attention的机制应用在Memory Network上会有不错的效果,使用Memory Network可以进行阅读理解,主要形式是我们有一篇文章(document),一个问句(query),然后神经网络要生成一个答案(answer)。
首先我们需要将document中的句子表示成一些向量,这里可以使用paragraph2vec或者bag of words都可以,同样地query也要表示成一个向量。然后我们需要使用query向量在document的若干向量上做Attention,然后得到权值 a 1 , a 2 , … , a N a_1,a_2,\dots ,a_N a1,a2,…,aN,然后将document的若干向量做weighted sum,加和后要将得到的向量和query向量一起输入进一个DNN中,最终输出answer。这整个过程,包括对文章做Embedding的部分是可以一起训练的(jointly train)。整个过程流程图如下:

Memory Network还有一个更加复杂的版本,在这个架构中document被表示成两组向量
x
1
,
x
2
,
…
,
x
N
x^1,x^2,\dots ,x^N
x1,x2,…,xN和
h
1
,
h
2
,
…
,
h
N
h^1,h^2,\dots ,h^N
h1,h2,…,hN,其中一组用来计算
权值
a
1
,
a
2
,
…
,
a
N
a_1,a_2,\dots ,a_N
a1,a2,…,aN,然后将这组权重乘到另一组上来抽取信息,然后输入到DNN中得到answer。另外,还可以将做了weighted sum的
h
1
,
h
2
,
…
,
h
N
h^1,h^2,\dots ,h^N
h1,h2,…,hN跟query向量再加起来然后将加起来的向量再做attention,也就是重复上述过程多次,这个过程叫做Hopping:
接下来将上图展开具体介绍一下Hopping的过程。在下图中,我们可以将Hopping的过程看成多层网络叠加在一起。下图以两层为例,我们将Attention的结果再与query加起来,然后再在另外两组document的Embedding上做Attention,然后输入到DNN中然后输出answer。图中docment的四组Embedding向量可以用四组不一样的,也可以用两组一样的,这取决于设置的参数共享方式,使用两组一样的可以减少参数,使用四组不一样的可以增强效果:
五、Neural Turing Machine
相比于Memory Network,Neural Turing Machine不仅可以从memory中读取信息,也可以通过Attention机制来修改memory。
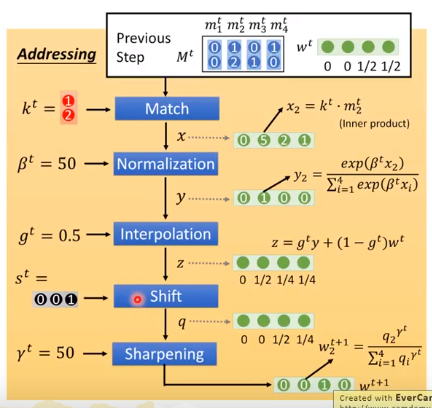
首先我们有一组初始的memory
m
0
1
,
m
0
2
,
⋯
,
m
0
4
m_{0}^{1},m_{0}^{2},\cdots ,m_{0}^{4}
m01,m02,⋯,m04和初始的Attention的权重
α
^
0
1
,
α
^
0
2
,
⋯
,
α
^
0
4
\hat{\alpha }_{0}^{1},\hat{\alpha }_{0}^{2},\cdots ,\hat{\alpha }_{0}^{4}
α^01,α^02,⋯,α^04。然后我们将这组memory和权重做weighted sum得到
r
0
r^0
r0,然后与
x
1
x^1
x1一起输入到controller f中,f可以是DNN也可以是LSTM或者GRU等,然后f将会输出三个向量
k
1
,
e
1
,
a
1
k^1,e^1,a^1
k1,e1,a1。其中
k
1
k^1
k1通过计算和memory的余弦相似度然后通过softmax层得到下一组Attention的值
α
^
1
1
,
α
^
1
2
,
⋯
,
α
^
1
4
\hat{\alpha }_{1}^{1},\hat{\alpha }_{1}^{2},\cdots ,\hat{\alpha }_{1}^{4}
α^11,α^12,⋯,α^14。该过程如下图所示:

通过 k 1 k^1 k1和memory计算余弦相似度来获得Attention的值是一种简化版本,真正的Neural Turing Machine获取Attention的值是通过下图的方式:
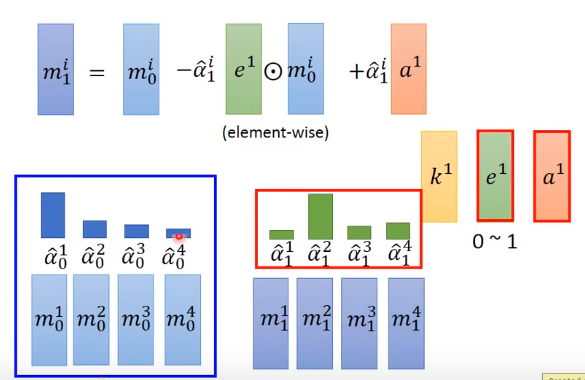
另外 e 1 e^1 e1和 a 1 a^1 a1的值是用来修改memory中的值,其中 e 1 e^1 e1的每一个维度都是介于 0 0 0和 1 1 1之间,用于清空memory中的值, a 1 a^1 a1用于修改memory中的值。对于每一个memory向量都做下图中的运算得到新的memory m 1 1 , m 1 2 , ⋯ , m 1 4 m_{1}^{1},m_{1}^{2},\cdots ,m_{1}^{4} m11,m12,⋯,m14,通常Attention的值会非常sharp,也就是只有一个值会接近 1 1 1,其余权值都比较小,这保证了每次都只有一个memory被较大地修改:
然后用新的memory和Attention的权重做上述同样的过程产生 r 1 r^1 r1。如果使用的controller是循环神经网络的话也会产生其本身的隐层状态 h 1 h^1 h1,然后将这个隐层状态输入到下一个时间点:

以上就是对Neural Turing Machine的简单介绍。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









