






论文标题:Propagation Tree Is Not Deep: Adaptive Graph Contrastive Learning Approach for Rumor Detection
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/27757
论文来源:AAAI 2024
一、概述
现有的一些谣言检测研究表明,帖子的传播结构完全包含了回复之间的相互关系,并利用了群体智能,这对于揭露谣言是非常宝贵的。一般来说,基于谣言传播结构学习的谣言检测模型从回复之间的相互关系中提取了谣言的判别特征,将回复立场的特定模式作为帖子分类的基础,因为谣言帖子和非谣言帖子的回复立场存在明显区别。这些模型擅长区分这些差异,这构成了基于谣言传播结构学习的谣言检测方法的一个基本假设。这个假设在一定程度上依赖于谣言传播树的深层结构。但是谣言传播树真的是深度的吗?
考虑到这个问题,本文进行了统计分析来探索谣言传播树的结构特征。统计结果表明,在通常使用的谣言检测数据集和现实世界的社交媒体平台中,帖子的树状结构通常是浅层的。绝大多数回复是一级回复,其余部分主要由二级回复组成,只有一小部分更深层的回复。这意味着谣言传播树本质上不是深层树状结构,而是宽状的结构。
根据本文的统计分析,谣言传播树中的大多数节点是一级回复,都直接指向根节点(即源帖子),这突显了根节点的重要性。进一步地,由于大多数一级回复缺乏更深层的进一步回复,与拥有更广泛路径的节点相比,其可能在谣言识别中包含的信息价值较低。基于这些发现,本文提出了RAGCL方法。RAGCL利用节点中心性度量来生成谣言传播树的增强视图,并运用图对比学习方法帮助图神经网络从谣言传播树的深层部分学习关键的谣言区分特征。本文进行的大量实验验证了RAGCL的有效性。
总结来说,本文研究内容的主要贡献如下:
本文的统计调查揭示了谣言传播树主要表现为宽度的树状结构,打破了以往研究中对其为深度结构的固有看法,这或许会改变人们对社交媒体平台上信息传播过程的理解。
基于谣言传播树的结构特性,并受到当前关于图自监督学习研究的启发,本文提出了RAGCL方法来学习用于谣言检测的区分性特征。
鉴于谣言传播树独特的树状结构,本文提出了三个指导原则,用于设计应用于谣言传播树的自适应数据增强方法。
本文的实验结果突显了RAGCL与当前SOTA方法相比的卓越性能,并证实了本文三个原则的有效性。
二、问题分析
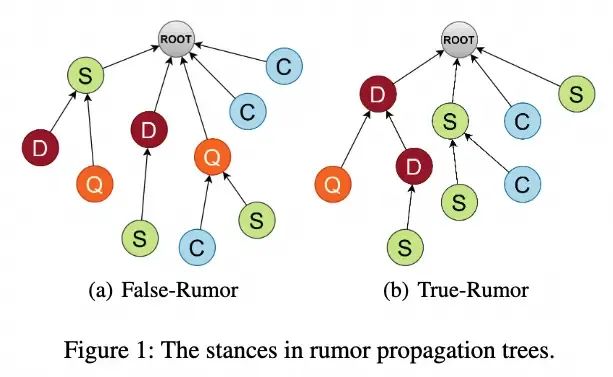
如下图所示,当前基于传播结构学习的谣言检测方法致力于收集回复与其源帖子之间或者多个回复之间的支持(Support,S)、否认(Deny,D)、质疑(Question,Q)、评论(Comment,C)等立场。对于不同类别的帖子,它们的立场模式存在明显差异,这些差异可以作为谣言识别的判别特征。例如,D-D关系的真实立场是S,而D-S关系的真实立场是D。当前的传播结构学习方法利用谣言传播树同一分支上顺序节点之间的立场特征进行谣言检测。然而,这些特征依赖于谣言传播树的深度结构。但是,谣言传播树真的是深层的吗?
在本文研究中,我们对谣言传播树固有的结构特性进行了全面的统计分析。本文调研的数据集包括Weibo、DRWeibo、Twitter15和Twitter16。此外,本文还调查了两个大规模无标注数据集,即UWeibo和UTwitter。这两个无标注数据集的数据来源于微博和Twitter平台上的热门帖子,反映了社交媒体环境中帖子的普遍特征。统计结果显示在下表中。表中虚线下方的条目分别代表数据集中每个帖子的平均回复数、一级回复数、二级回复数、更深层(>2)回复数,以及有后续回复的一级回复数。从这些统计结果中可以得出以下结论:
谣言传播树更像是宽树而非深树。 在谣言传播树中,一级回复构成了所有回复的大多数,其比例分别为四个有标注数据集的65.1%、77.8%、70.7%和64.2%。
谣言传播树中的一级回复只有很小一部分会产生后续回复。 在所有谣言传播树的一级回复中,只有一小部分产生了进一步的回复,其百分比分别为9.7%、6.4%、10.4%和10.8%。
在谣言传播树中观察到的深层回复很少。 深层回复在所有谣言传播树中的回复中只占很小一部分,其百分比分别为13.8%、4.4%、17.3%和23.4%。这表明模型只能从有限的回复集合中学习前述立场特征。

UWeibo和UTwitter数据集也展示出了了这三个特点,这表明这些特征是社交媒体平台上帖子的普遍特性。对这些数据集的调研体现了谣言传播树的一般结构,本文按照其特点在下图中展现了一个谣言传播树大致的直观样貌。值得注意的是,下图中框内的节点才具有前述的立场特征,而树中的大多数节点是没有进一步回复的一级回复节点(没有深层结构)。
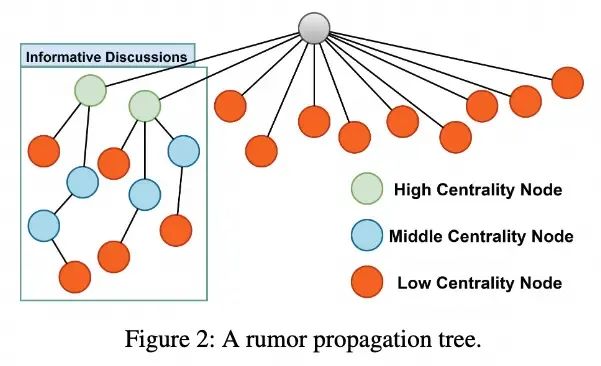
基于上述观察到的内容,本文可以将谣言传播树概念化为一个高度不平衡的图,这种不平衡体现在以下两个方面:
谣言传播树根节点处具有高度密集的连接,而其余节点处的连接则较稀疏。
富有信息量的深入讨论和谣言传播树的信息密集部分主要集中在有限数量的一级回复中(上图中的两个绿色节点)。相比之下,大多数没有进一步深层回复的一级回复更加缺乏有助于识别谣言的鉴别特征。
这些特点是由社交媒体用户的使用习惯和平台展示评论的顺序决定的。通常情况下,用户倾向于直接回复源帖子,而不是其他用户的评论。此外,像微博和Twitter这样的平台倾向于根据回复的受欢迎程度而非发布时间来排序回复。这导致了传播树内信息分布的不平衡。为了增强模型对谣言传播树中激烈和信息丰富讨论的关注,并减少大量未被进一步回应的一级回复的影响,本文提出了RAGCL方法。RAGCL的目标是强调那些在谣言传播树内有激烈回复的评论的重要性,同时也考虑到谣言传播树的宽状结构,其通过将其他节点的信息聚集向根节点来更加来关注根节点。
三、方法
本节将介绍RAGCL方法如何利用节点中心性度量来自适应地进行图对比学习,从而鲁棒且高效地进行谣言的识别。
1. 符号表示
谣言检测任务可以定义为一个图级的分类任务。具体来说,本文将一个有标注的帖子数据集表示为 ,其中 代表第 个帖子, 代表有标注帖子的数量。每个有标注的帖子 由其真实标签 (即Non-rumor或Rumor)或细粒度标签 (即Non-rumor、False Rumor、True Rumor和Unverified Rumor)以及其传播结构 组成,其中 和 分别代表节点集(一个源帖子及其回复)和边集(回复对之间的关系或源帖子和回复之间的关系)。所有帖子对应的传播结构图集合是 。谣言检测任务的目标是利用数据集 来学习一个分类器 。
2. 模型框架
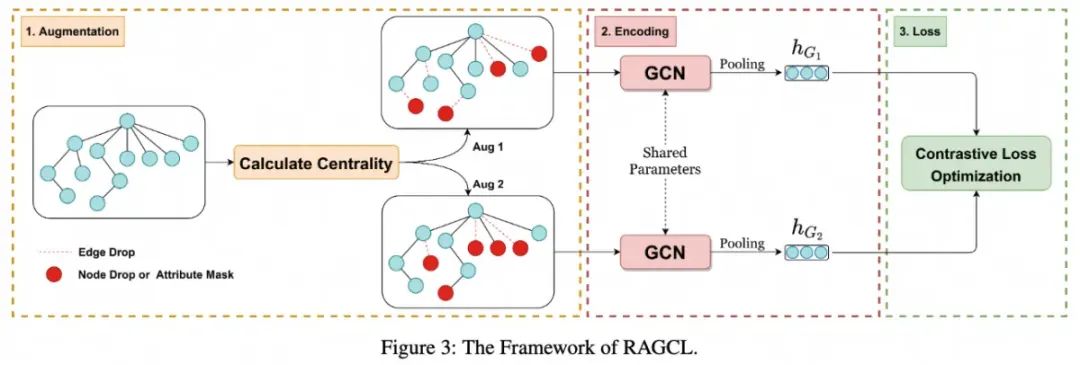
从前述分析中,可以看出从深层结构的节点(例如,图2中方框内的节点)学习鉴别性特征是很重要的。这些节点及其对应的边相比于位于方框外的节点具有明显更高的重要性。基于这个想法,本文提出了RAGCL,一个为谣言检测特别设计的自适应图对比学习框架。RAGCL根据所选的节点中心性度量为谣言传播树内的节点和边赋予不同级别的重要性。随后,根据这些得分来确定不同的丢弃或掩码概率,用于自适应生成谣言传播树的两个增强视图,这涉及节点丢弃、属性掩码或边丢弃操作。接着,通过最小化对比损失来学习谣言传播树的表示。RAGCL方法的整体框架展示在下图中。
3. 数据增强原则
节点中心性是衡量图中节点重要性的一个指标。RAGCL使用了三种推荐的节点中心性度量,包括度中心性(Degree Centrality)、介数中心性(Betweenness Centrality)和 PageRank 中心性:
度中心性 以节点的度作为节点中心性的衡量标准。其核心思想是,在谣言传播树中,拥有多个回复的帖子是重要的。RAGCL使用谣言传播树的自顶向下有向图的节点出度作为度中心性的衡量标准。
介数中心性 计算图中任意两个节点的所有最短路径。如果大量这样的最短路径通过一个节点,那么其介数中心性数值将会很高。RAGCL利用自顶向下或自底向上有向图来确定介数中心性。
PageRank中心性 常用于网页排名。其基本思想是,互联网上一个页面的重要性取决于指向它的入站链接的数量和质量。RAGCL利用谣言传播树自底向上有向图来计算PageRank中心性。
基于前文对谣言传播树结构特征的分析,本文总结了以下三个原则,用于给节点和边赋予重要性评分:
原则1:鉴于源帖子的重要性,谣言传播树的根节点应该被排除在数据增强过程之外。
原则2:在谣言传播树的宽度方向上,具有深层回复的节点和边(在图2的方框内的部分)应尽可能地被保留。
原则3:在谣言传播树的深度方向上,低层的节点应比其更深层的后续节点在数据增强中被更多地保留,因为后续节点通常是围绕其父节点进行讨论的,因此它们应该具有相对较低的重要性。
其他节点中心性度量,如特征向量中心性(Eigenvector Centrality)、Katz中心性和接近中心性(Closeness Centrality),由于其固有特性不符合前述原则,因此我们认为不适用于谣言传播树。图2中的节点颜色显示了根据上述原则应获得的节点中心性大小。此外,为了确保符合原则2,考虑到根节点连接密集的特性,RAGCL为根节点赋予了该图中所有节点中心性的最小值。在数据增强过程中,RAGCL通过构成边的两个节点的中心性来衡量边的重要性。过高的根节点中心性会过度地增加连接根节点与未被进一步回复的一级回复的边的重要性,从而违反原则2。
4. 自适应图数据增强
RAGCL根据节点中心性进行自适应数据增强,生成谣言传播树的两个增强视图。它主要使用三种独特的数据增强操作:节点丢弃、属性掩码和边丢弃。在训练阶段,从这三种操作中选择两种。RAGCL利用节点中心性为节点和边分配重要性评分,之后计算以丢弃或掩码进行数据增强的概率。
4.1 节点丢弃
考虑数据集 中任一帖子的传播图 。给定一个节点中心性度量 ,其中 是节点 所在的空间,节点 的最终节点中心性值由 表示。RAGCL中的节点丢弃操作包括为每个节点 赋予一个丢弃概率 ,并根据此概率从节点集 中移除部分节点(连同这些节点连接的边),以产生一个增强视图。值得注意的是,根节点在此操作中从不被丢弃。节点重要性得分 设置为节点中心性值,即 。鉴于节点中心性值可能跨越多个数量级,为了减轻密集连接节点的影响,设置 。节点丢弃概率根据以下归一化的过程导出:
❝
其中 是控制节点丢弃整体概率的超参数, 和 分别代表 的最大值和平均值。
4.2 属性掩码
在RAGCL中,属性掩码被定义为用零向量替换节点集 中部分节点的特征向量。根节点不参与此操作。属性掩码不涉及节点移除;因此,连接到掩码节点的边将被保留。节点 的掩码概率也是 。
4.3 边丢弃
在RAGCL中采用谣言传播树的自顶向下有向图。边丢弃操作包括为每条边 设置一个丢弃概率 ,随后利用这个概率从边集 中移除某些边,以生成一个增强视图。 应反映边的重要性,这意味着重要边的 应该低于不太重要边的 。注意,根节点的中心性被赋予为图中所有节点中最小的中心性值。边的重要性得分 定义为其两个连接节点中心性的平均值:
❝
然后根据边 的重要性得分导出丢弃概率。同样地,设置 ,以减轻密集连接节点的影响。概率的计算方法与节点丢弃和属性掩码类似,如下所示:
❝
其中 是一个超参数,用于调节边丢弃的整体概率, 和 分别代表 的最大值和平均值。
5. 对比损失优化
对谣言传播图 的数据增强产生两个增强视图,即 和 。这些视图通过一个GCN编码器处理,以获得两个表示: 和 。在RAGCL中,对应于数据集 的图集 上的无监督对比损失按如下方式计算:
❝
其中 表示 遵循的分布; 表示从 中抽取的输入样本; 是从 中抽取的负样本; 是余弦相似度。
RAGCL将 用作有监督损失 (由 计算)的正则化项,并在训练阶段优化以下损失函数。
❝
其中 是一个可调的超参数。
四、实验设计与结果分析
在这一部分中,我们首先介绍了实验中使用的数据集和与所提出方法进行对比的基准方法。本文将RAGCL的性能与基线进行比较,并进行消融研究,以探索未被回应的一级回复、不同节点中心性度量以及数据增强方法组合的影响。
1. 实验设置
本文在四个真实世界的基准数据集上进行了实验,分别是Weibo、DRWeibo、Twitter15和Twitter16,以评估RAGCL的性能。Weibo和DRWeibo是中文二分类数据集,而Twitter15和Twitter16是英文多分类数据集。表1显示了数据集的统计数据。
本文与以下基线方法进行了比较:
PLAN是一种基于Transformer架构的谣言检测模型,其StA-PLAN版本使用谣言传播树的结构信息。
BiGCN是一种基于GCN的谣言检测模型。它使用两个编码器,一个自顶向下和一个自底向上,并使用根节点特征增强策略进行谣言分类。
UDGCN直接使用GCN进行谣言检测,将谣言传播树的无向图作为模型输入,并使用根节点特征增强策略。
GACL基于对比学习和对抗训练进行谣言分类。
DDGCN是一种谣言检测模型,能够在一个统一框架中建模多种类型的信息。
对于数据集中的文本,首先标准化文本中存在的不同字体,然后将用户@活动和网页链接标识为特殊词元<@user> 和 <url>。接下来,本文分别使用NLTK工具包中的TweetTokenizer和jieba分词引擎来对英文和中文数据集中的原始文本进行分词。此外,使用emoji包将文本中的表情符号翻译成文本字符串词元。所有模型均使用PyTorch实现,且基线方法均为重新实现。GACL使用BERT来提取传播树中每个帖子的初始特征向量。除了GACL外,其他模型对于Twitter15和Twitter16使用5000维的词频向量作为初始特征向量,对于Weibo和DRWeibo则使用200维的word2vec词嵌入作为初始特征向量。
对于Weibo和DRWeibo,和均使用0.3,而对于Twitter15和Twitter16则使用0.2。wo men将设置为1e-3,批处理大小设置为32,学习率设置为1e-3,GCN编码器层数设置为3,并使用Adam优化器优化损失函数。本文使用求和池化(sum-pooling)从节点表示中获取图表示。模型训练使用的是单个Nvidia GeForce RTX 3090 GPU。对于Weibo和DRWeibo,本文评估两个类别上的准确率(Acc.)和每个类别的精确度(Prec.)、召回率(Rec.)、F1值(F1)。对于Twitter15和Twitter16,本文评估四个类别上的准确率和每个类别的F1值。实验结果是数据集10次随机划分的平均结果。本文还报告了准确率的标准差,以反映多次实验结果的稳定性。本文报告了在不同节点中心性和数据增强组合下RAGCL可以达到的最佳性能。RAGCL的源代码可在https://github.com/CcQunResearch/RAGCL获取。
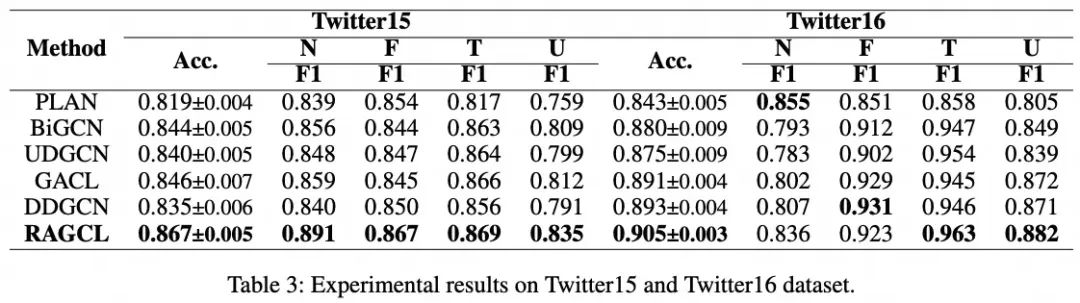
2. 实验结果与分析
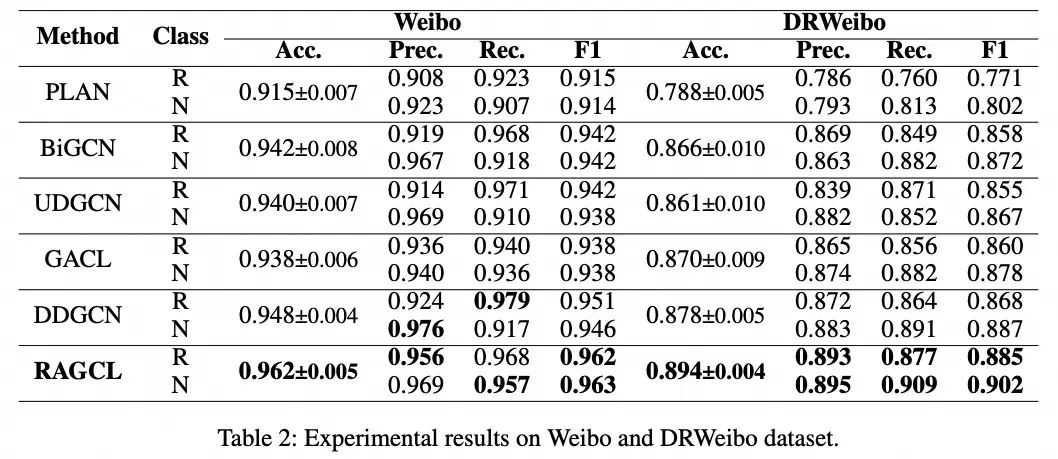
下面两张表中的结果显示,RAGCL在所有数据集上均优于基线模型。PLAN在所有数据集上的表现相对较差,且由于Transformer架构,消耗了更多的GPU资源。BiGCN是一个典型的基于谣言传播树深度结构构建的模型,它假设谣言传播树中的信息流呈现为自顶向下的传播和自底向上的扩散过程。然而,本文的研究发现实际上谣言传播树表现为宽状结构。这表明,对于像谣言传播树这样的树结构,除了深度方向的信息流动外,宽度方向上信息的不均衡分布也是一个重要特征,这是现有技术目前忽视的。另外,虽然GACL使用BERT来提取初始特征向量,但它并没有比其他基线有显著提高。此外,GACL利用监督对比学习来学习帖子表示,而采用无监督对比损失的RAGCL也实现了卓越的性能。应用无监督损失允许模型在不依赖标签的情况下学习良好的表示。这表明使用RAGCL在社交媒体平台(如UWeibo和UTwitter)上的大规模无标注数据集上进行预训练,以进一步增强模型的谣言检测能力是可行的。
3. 消融实验
本文进行了一系列消融实验,以验证未被进一步回复的一级回复、数据增强组合、节点中心性度量以及图的方向等不同因素对模型性能的影响。
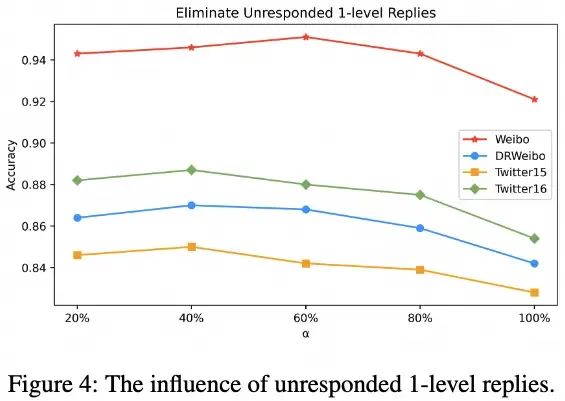
3.1 未被进一步回复的一级回复
为了验证谣言传播树中未被回应的一级回复的影响,本文在下图所示的四个数据集上进行了实验。本文在每个谣言传播树中去除了的未被回应的一级回复,随后使用BiGCN进行分类。随着的增加,可以观察到模型性能保持稳定,甚至在某种程度上有所提高。这表明这些未被回应的一级回复,正如本文之前推测的,对谣言分类过程的重要性较低,甚至可能属于一种噪声,因此RAGCL丢弃它们是合理的。
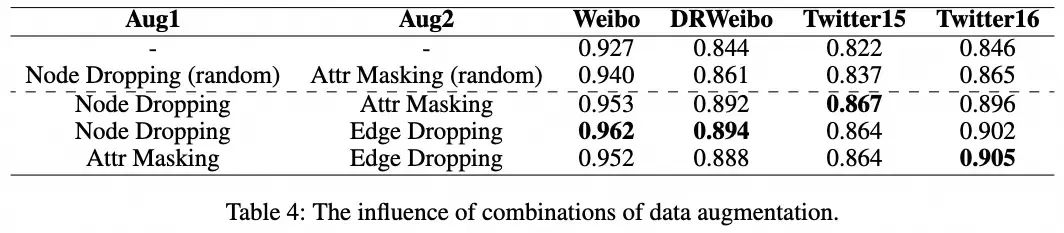
3.2 数据增强组合
下表展示了不同数据增强组合的影响,本文在其中报告了每个数据集上的准确率。实验结果表明,在中文数据集(Weibo和DRWeibo)中使用属性掩码会降低模型性能。对于英文数据集,各种数据增强组合对结果的影响微乎其微。不同的数据增强组合相较于仅使用GCN进行监督分类且不应用对比损失,均取得了显著的性能提升。此外,结果还表明,自适应数据增强优于随机数据增强,进一步验证了本文理论的可靠性。
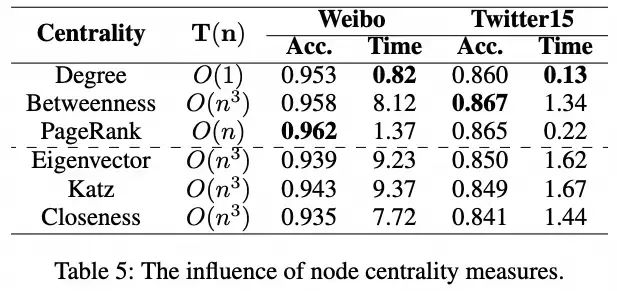
3.3 节点中心性度量
本文在下表中进行的实验旨在探索不同节点中心性度量的影响。本文报告了RAGCL在不同节点中心性度量下所达到的准确率,以及计算每个谣言传播树中心性的平均时间成本(以秒为单位)。度中心性可以迅速计算,因此在大型数据集中可以快速有效地确定节点中心性。然而,它仅关注边的数量,没有满足原则3,这突显了度中心性的局限性。例如,具有相同回复数量的父节点和其子节点将被赋予相同的中心性。实际上,度中心性的表现也相对较差。介数中心性很好地符合这三个原则。对于RPT来说,介数中心性是衡量节点重要性的非常直观的指标。拥有众多后继节点的节点将有许多最短路径通过它,从而导致相应的介数中心性升高。然而,计算介数中心性比其他度量更复杂和耗时。另一方面,PageRank中心性不仅很好地符合基本原则,而且还受益于相对快速的计算过程,使其更有利于RAGCL的训练阶段。本文还检验了特征向量中心性、Katz中心性和紧密度中心性的效果,以验证本文三个指导原则的有效性。鉴于它们各自的特点,这些度量未能满足原则2和3,导致表现不佳。此外,它们的计算复杂度相对较高。因此,本文不建议在RAGCL中使用这些中心性度量。
3.4 图的方向
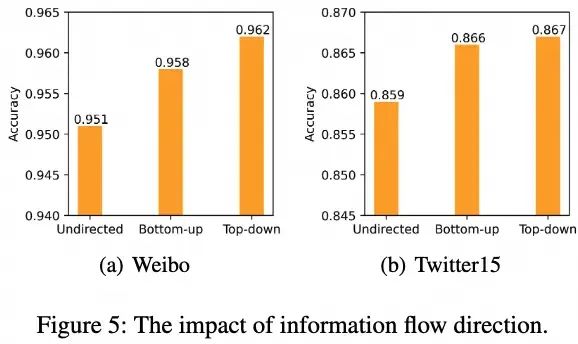
RAGCL兼容自顶向下和自底向上的有向图以及无向图。本文在下图中研究了不同类型的图对性能的影响。结果表明,使用无向图会导致性能下降。这可能是因为在GNN的前向传播过程中,根节点处密集连接的节点将在其邻域视野中相互看到。这些节点相互聚合彼此的信息,最终导致节点特征的独特性丧失,引起过平滑问题(over-smoothing problem)。另一方面,自顶向下和自底向上的有向图能够有效地阻断根节点处节点间过度的信息流动。
3.5 超参数的影响
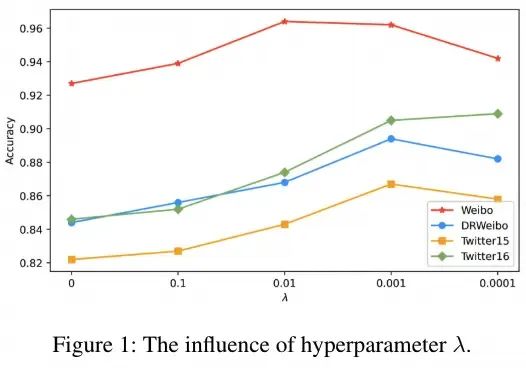
超参数 控制着对比损失对监督损失的影响程度。本文通过下图中的实验来研究 对模型性能的影响。实验结果表明,对于所有数据集来说,1e-3是一个相对合适的设置,因此本文在所有其他实验中通常将 保持在1e-3。
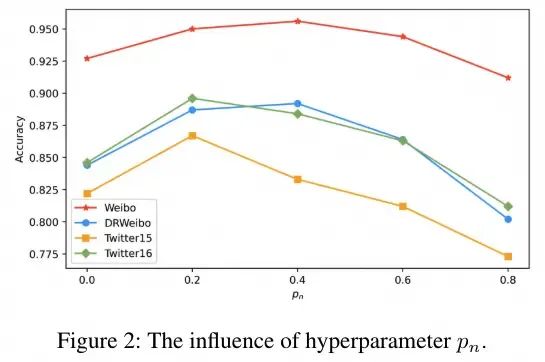
为了探索自适应数据增强中最合适的节点或边丢弃(或掩码)比率,本文进行了下图中展示的实验。本文在这些实验中使用了两种数据增强方法,节点丢弃和属性掩码,并约束它们使用相同的 。然后,本文改变了 的大小,以观察其对模型性能的影响。实验结果表明,对于中文数据集来说,0.3是一个合适的比率,而对于英文数据集,由于其平均帖子回复数较少,较小的丢弃比率大约0.2更为合适。基于这些实验结果,本文在剩余的实验中将中文数据集的 和 设置为0.3,英文数据集设置为0.2。
五、结论
本文进行了关于谣言传播树结构特性的统计分析,发现这些传播树并非之前研究所假设的深度结构,而是呈现出一种不均衡的宽状结构。基于这一发现,本文开发了一种适用于谣言传播树独特结构的自适应图对比学习方法(RAGCL)。该方法通过节点的中心性度量来引导谣言传播树的自适应图数据增强。针对谣言传播树的结构特征,本文提出了三个数据增强的基本准则,并依此选择了几种最适合谣言传播树的节点中心性度量。本文的实验验证了RAGCL方法的有效性,证明了图对比学习技术在谣言检测领域的应用价值,并为后续的研究提供了坚实的基础。














 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









