







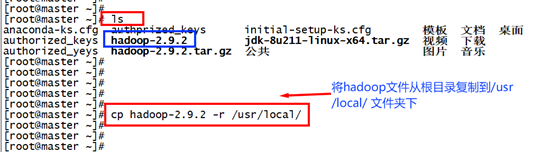
步骤一:在Master主机上下载并解压hadoop文件夹。
[root@master ~]# ls
使用此命令,查看自己文件夹下hadoop存放的位置,这里我存放的是在根目录下。如果自己的hadoop文件不是在根目录下,需要先查找之后,进入指定的目录再解压。
[root@master ~]# tar -xvf hadoop-2.9.2.tar.gz //此命用于加压hadoop文件
[root@master ~]# cd /usr/local/
[root@master local]# mv hadoop-2.9.2 hadoop

步骤二:在/usr/local/hadoop目录下,建立4个文件夹,分别为tmp、hdfs、hdfs/data和hdfs/name。
[root@master local]# cd hadoop/ // 如果现在不是处于hadoop目录下,先进入/usr/local/hadoop目录下。
如果已经进入,不需要此步骤!
[root@master hadoop]#
[root@master hadoop]# mkdir tmp
[root@master hadoop]# mkdir hdfs
[root@master hadoop]# mkdir hdfs/data
[root@master hadoop]# mkdir hdfs/name

步骤三:在/usr/local/hadoop/etc/hadoop目录下,修改7个步骤。
下面这7个步骤是hadoop的配置,千万不要配置错了,如果配置错了,hadoop就启动不起来了。
建议,可以指直接复制下面的脚本进入。
还有,一定要进入/usr/local/hadoop/etc/hadoop,此目录下修改!!!
1) 编辑slave文件,在文件下添加此脚本
[root@master ~]# cd /usr/local/hadoop/etc/hadoop
[root@master hadoop]# vi slaves
进入slaves文件时,按“i”进入编辑模式,添加slave节点的IP地址,这个地方根据自己slave虚拟机设定的IP地址,千万不要填写错了,有几台slave虚拟机,就填写几个ip地址。
添加完成之后,按esc,之后输入“:wq”,保存并退出!


2) 编辑core-site.xml文件,在文件下添加此脚本
[root@master hadoop]# vi core-site.xml
下面的脚本,可以直接复制但是IP地址一定要修改成自己的master虚拟机的IP地址,添加到之间,参照图所示!
<configuration>
... ...
</configuration>
==================================
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.12.100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
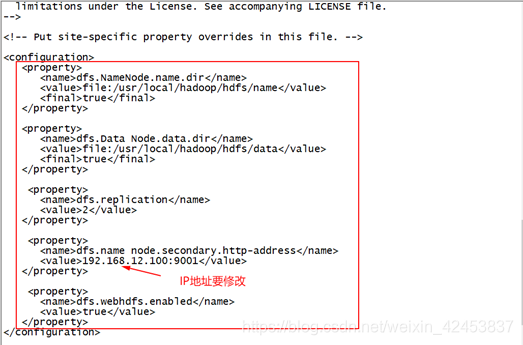
3) 编辑hdfs-site.xml文件,在文件下添加此脚本。
[root@master hadoop]# vi hdfs-site.xml
下面的脚本,可以直接复制,添加到之间,参照图所示!
<configuration>
... ...
</configuration>
=====================================
<property>
<name>dfs.NameNode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.DataNode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.12.100:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
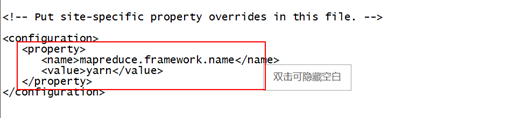
4) 编辑mapred-site.xml文件,在文件下添加此脚本。
[root@master hadoop]# vi mapred-site.xml.template
此处,我使用tab补全之后,显示的文件为mapred-site.xml.template。大家可以不用修改,按照tab补全的命令,正常不会出错的!!!
不同的系统的版本出现的文件,可能会是mapred-site.xml,尽量使用tab补全,以免出错!
下面的脚本,可以直接复制,添加到之间,参照图所示!
<configuration>
... ...
</configuration>
======================================
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5) 编辑yarn-site.xml文件,在文件下添加此脚本。
[root@master hadoop]# vi yarn-site.xml
下面的脚本,可以直接复制,添加到之间,参照图所示!
<configuration>
... ...
</configuration>
=============================
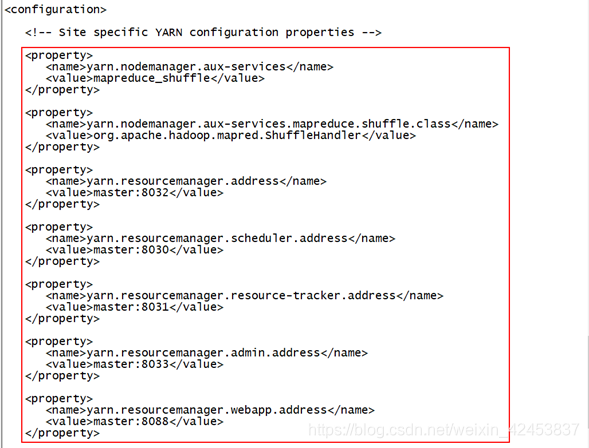
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
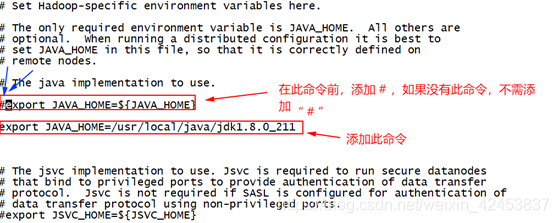
6) 编辑hadoop-env.sh文件,
[root@master hadoop]# vi hadoop-env.sh
添加如下脚本到图所示的位置

7) 编辑yarn-env.sh文件
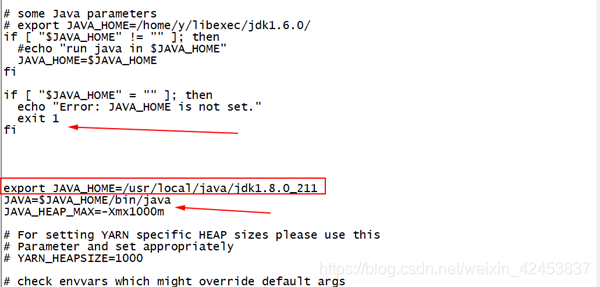
[root@master hadoop]# vi yarn-env.sh
添加如下脚本到图所示的位置

步骤三:复制Master到Slave节点上
[root@master ~]# scp -r /usr/local/hadoop/ root@192.168.12.111:/usr/local
或者
[root@master ~]# scp -r /usr/local/hadoop/ root@slave:/usr/local
有几个节点复制几次,要想使用第二种方法复制,需要在/etc/hosts文件下编辑 主机名和IP地址,前面有介绍怎么使用!!!
复制完成之后,可以检查是否复制成功!!!在slave节点上检查!!!

注意,复制hadoop到slave节点上,显示872M是比较完整的复制,如果是相比872M很多的文件,一定要注意,是否远程传输完整!!!














 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









