







随着人工智能技术的不断发展,开源大模型因其高度的灵活性和可定制性,受到了越来越多开发者和研究人员的青睐。虽然GPU(比如:Nvida的A100, A800,L20等)是大模型运行必备,并且备受青睐。但是考虑到成本限制,尤其是刚接触入门的小白,可能需要基于手头电脑cpu资源环境,跃跃欲试,做下先行探索。
本文基于自己的实践经验,指导您如何在Linux纯CPU环境下部署和运行开源大模型。
实验环境:
一台单机linux系统电脑,纯CPU运行环境:8核心、32G内存、无显存
实操过程
在本地部署运行时,重点尝试下面三种方式:
1、使用Ollame部署和运行大模型
Ollama 是一个强大的框架,设计用于在 Docker 容器中部署 LLM。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型。只需要简单两步:
(1)安装环境(docker安装,较简单)
1)Docker Pull Command
docker pull ollama/ollama该命令是从ollma镜像库中拉取和安装ollama环境。
目前镜像是默认连接github下载,如果尝试多次都是连接timeout,建议手动从ollama官网下载安装:
下载地址: Download Ollama on macOSGet up and running with large language models.![]() https://ollama.com/download
https://ollama.com/download
如果下载仍然失败(或者访问github太慢),建议多试两次。
或者通过访问gitcode,尝试手动下载安装(点击上图中的蓝色框链接)
linux手动安装指南:GitCode - 全球开发者的开源社区,开源代码托管平台
2)Start the container
此处基于Nvidia GPU 运行(CPU或者AMD GPU见这一节最后参考链接)
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama3) Run model locally
docker exec -it ollama ollama run llama2上面操作,进入ollama容器,(docker exec -it ollama ollama)启动ollama,并且自动运行llama2大模型。
如果手动启动ollama服务,可以运行如下:
sudo systemctl start ollama #启动ollama服务(2)下载大模型和运行
Ollama官方地址:https://ollama.com/library
搜索qwen,进入通义千问qwen1.5系列模型链接: qwenGet up and running with large language models.![]() https://ollama.com/library/qwen
https://ollama.com/library/qwen
默认可以看到6个模型,在下拉框选择tags中,可以看到更多量化版本的模型,可以尝试。
- 6 model sizes, including 0.5B, 1.8B, 4B (default), 7B, 14B, 32B (new) and 72B
-
- ollama run qwen:0.5b
- ollama run qwen:1.8b
- ollama run qwen:4b
- ollama run qwen:7b
- ollama run qwen:14b
- ollama run qwen:32b
- ollama run qwen:72b
- ollama run qwen:110b
在下拉框更多tag中,可以看到更多量化版本的大模型,也可以直接运行使用,截图如下:
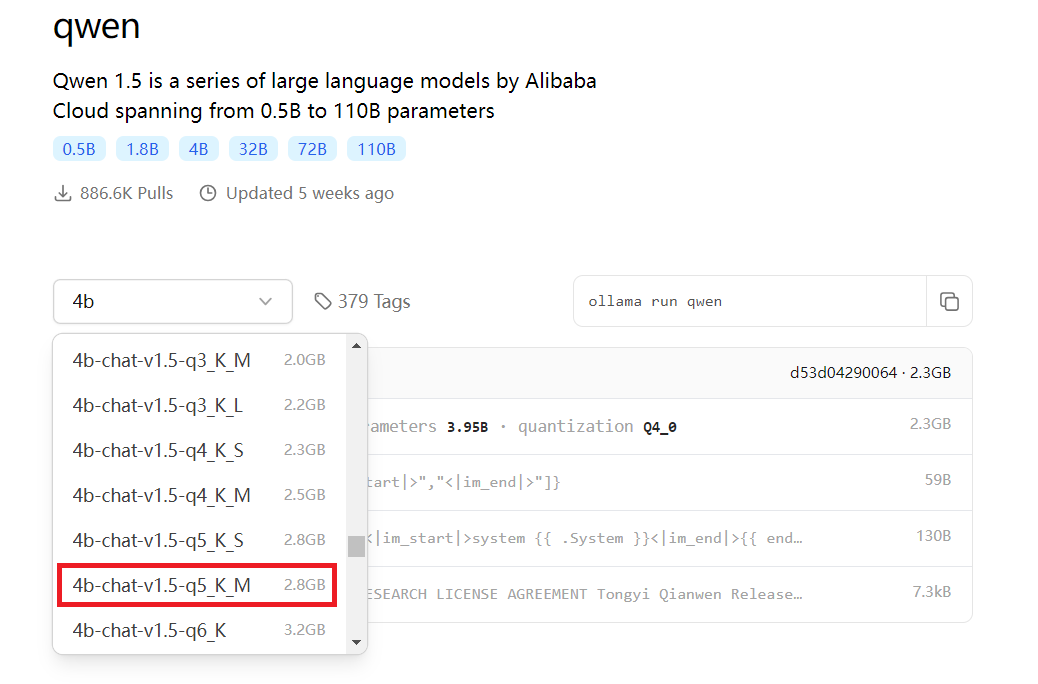
选择对应的模型,运行命令
ollama run qwen:4b自动下载和运行,可以愉快进行对话了!
使用qwen:4b运行, 速度有些慢(回答问题需要等待10秒钟左右),
采用量化版本运行:
ollama run qwen:4b-chat-v1.5-q5_K_M运行速度快了很多,效果与4b相比,没有相差太多。
qwen:7b也可以运行,但是更慢了。。(回答问题需要等待1-2分钟)
下次想运行时,输入如下命令
sudo systemctl start ollama ##如果你enable打开了开机自启动,这行可不运行
ollama run qwen:4b2、使用llame.cpp运行大模型
llama.cpp 是一个开源的 C++ 库,用于加载和运行 LLaMA 语言模型。它对Win/Mac/Linux都很友好,可以通过llama.cpp量化部署,在量化策略上支持Q_k_m也是目前最先进的量化策略。另外,llama.cpp在通义千问开源的同时,也几乎第一时间更新了对Qwen模型的支持。
首先,下载和安装llame.cpp,操作如下:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp如果github无法访问,可以考虑使用gitcode代替,参考如下:
git clone git@github.com:ggerganov/llama.cpp.git llama
=> git clone GitCode - 全球开发者的开源社区,开源代码托管平台 llama
然后cd到llama目录,直接运行make直接安装,较为简单。
接下来需要下载模型和运行了。
只要语言模型转换为GGML格式,就可以被llama.cpp加载和使用。而大多数流行的LLM都有可用的GGML版本(二进制格式的量化模型)。
需要注意的重要一点是,在将原始llm转换为GGML格式时,它们就已被量化过了。量化的好处是在不显著降低性能的情况下,减少运行这些大型模型所需的内存。例如,在不到4GB的RAM中可以加载大小为13GB的70亿个参数模型。
通过llama.cpp中自带的工具,可以将llm模型转换为ggml格式,并且进行量化。
例如:执行转换命令,并且将模型量化为5Bit(使用q5_k-m方法)
python convert-hf-to-gguf.py G:\Python\Qwen1.5-4B-Chat --outfile G:\Cpp\qwen_chat_4b.gguf
# 将模型量化为5Bit(使用q5_k-m方法)
quantize.exe G:\Cpp\qwen_chat_4b.gguf qwen_chat_4b-q5_k_m.gguf q5_k_m最好在,控制台运行该模型:
# 注意Qwen模型要使用chatml prompt 模版
main.exe -m qwenchat4b-q5_k_m.gguf -n 512 --chatml例如:Qwen1.5-4B-Chat-GGUF
可以使用modelscope (pip install modelscope) 直接下载相应的模型:
from modelscope.hub.file_download import model_file_download
model_dir = model_file_download(model_id='qwen/Qwen1.5-4B-Chat-GGUF',file_path='qwen1_5-4b-chat-q5_k_m.gguf',revision='master',cache_dir='path/to/local/dir')然后在通过 llama.cpp运行大模型:
make -j && ./main -m /path/to/local/dir/qwen/Qwen1.5-4B-Chat-GGUF/qwen1_5-4b-chat-q5_k_m.gguf -n 512 --color -i -cml -f prompts/chat-with-qwen.txt3、使用 Hugging Face 的 transformers 库加载预训练模型
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "auto" # 将模型加载到的设备
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-7B-Chat-GPTQ-Int8",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat-GPTQ-Int8")
prompt = "请给我一个大型语言模型的简短介绍。"
messages = [
{"role": "system", "content": "您是一名乐于助人的助手。"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-7B-Chat-GPTQ-Int8",
torch_dtype="auto",
device_map="auto"
)
会报错:非法指令 (核心已转储)
该报错信息,参考百度AI解答:
针对于报错 AutoModelForCausalLM.from_pretrained 这个具体问题,它通常表示在尝试使用 Hugging Face 的 transformers 库加载预训练模型时出现了问题。
解决方法:
- 确认环境兼容性:确保你的操作系统、Python版本和CUDA版本(如果使用GPU)与你尝试加载的模型和transformers库版本兼容。
- 更新transformers库:尝试更新到最新版本,使用pip命令:
pip install --upgrade transformers- 检查模型文件:确保你尝试加载的预训练模型文件是完整且未损坏的。
- 降低模型的复杂度:如果是因为硬件资源不足导致的问题,尝试降低模型的复杂度,比如使用更小的模型。
- 检查CUDA兼容性:如果你在使用GPU,确保CUDA的版本与你的显卡驱动程序兼容。
查看了我的运行环境,transformers已经更新到最新。模型文件来自官方。 所以最有可能是:我的硬件环境(只有CPU)与尝试加载的模型需要的资源不兼容。
=》尝试加载: "Qwen/Qwen1.5-4B-Chat", 可以成功加载运行。
总结:
1)无论是ollama环境运行,还是lame.cpp运行,都是较为方便,并且常用的开源大模型(比如llama,qwen1.5系列等),
都已经集成上传到了各个环境库下面,因此推荐使用这两种方法在本地部署运行。
2)不同参数量级的大模型效果差异还是很明显的,结合官方实验参数和自己的业务应用实践,可以尝试找出有“质变”的参数量级。
在资源性能和效果之间做一下平衡。
3)如果是做更深入的微调训练(fine-tune),基于transformers方式加载运行会相对更灵活一些。
4)从硬件资源使用来看,如果达到较好的效果,以及微调训练等,搭配GPU运行,还是非常必要的。















 2495
2495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









