






k近邻算法详解及Python实现
之前写了一篇文章关于K近邻算法(KNN),且在文中对于使用Python来实现KNN给了详细的解释。但总感觉少了些什么,下面我们就用简单的语言来探讨KNN算法的原理,这篇文章深入浅出的介绍了KNN算法,同时对于Python学的不好的同学呢也有照顾,因为你将会看到简单的Python实现KNN。原因在于我们采用Scikit learn,在scikit learn 中,KNN已经被封装好了,我们需要做的仅仅是调用。。。调用。。调用。。重要的事情说三遍。
关于KNN呢,因为它简单有效同时易于理解,常常作为我们进入机器学习领域的入门算法。虽然KNN算法较为简单,但是其中也蕴含着丰富的机器学习概念!!!本文主要从以下几个方面解释:
什么是KNN
KNN中的关键概念
使用KNN进行分类
什么是KNN
K近邻又称KNN,是一种常用的分类方法,同时也可以用于回归。下面我们通过一个例子来解释KNN的用处。(例子来源于算法图解)假如我们有一堆水果,里面包含橙子和柚子(橙子:小而黄,柚子大而红)。如果我们已经知道这一堆水果的具体类别,那么对于一个新的水果,我们该怎样对其分类。
很多人会说直接用眼睛看就行了,这种方法也可以,同时几乎不可能出错。但是我们现在考虑的问题是有没有一种识别的机器可以直接对水果进行分类(直接由机器得到水果的类别)。答案是肯定的。因为如果都是橙子的话,那么他们的大小应该差不多,同样颜色应该也是类似的。换句话说,如果我们把水果的特征(大小和颜色)进行量化以后,橙子与橙子的特征的相似度应该大于橙子与柚子,这样我们可以根据待分类水果与哪种水果的特征最相似,把待分类水果分到相应的类别。如果你也是这样认为的话,那么恭喜你已经get到了KNN的精髓,当然我举例用的是最相似的水果,即k=1,此时的算法也可以称为最近邻算法。然而最近邻算法有用,但是由于噪声的存在,最近邻算法的结果不是很稳定,因此我们可以得到k个与待分类水果待分类水果的类别最近的水果,然后根据k个水果的类别判断。
细心的同学可能会发现在上面的例子中存在以下问题:
在判断未知水果的类别是,说要选k个最近邻的水果,那么k是多少呢?有没有一个固定的k?在实际应用中我该如何选择K?
我们之前需要衡量两个水果之间的相似度,该如何度量?
我们找到了与待分类水果最近的k个水果,那么我们该怎么综合这些水果类别得到待分类水果的类别?
以上三点可以简单地描述为:k值的选择;距离的度量;判别规则的选取
下面我们先看K值的选择:
通常我们判断一个机器学习算法性能的方法是泛化误差,我们的目的是得到泛化误差小的机器学习算法。关于为什么我们选择泛化误差小的算法的原因在于我们的机器学习算法的主要用于未知数据的预测,也就是说训练好的学习算法以后面对的数据是自己从未见到的,因此我们特别关注我们的算法对于未见数据的泛化能力。
故在训练之前我们把我们的数据集分为训练集,验证集和测试集。其中训练集用于训练算法(对于KNN没有显式的训练过程),针对模型的不同参数,例如k值,我们通过判断k为何值时,验证集的分类性能最好,此时的k作为最后的k值。使用训练好的算法对测试集进行预测,把测试误差作为泛化误差的近似。下面我们通过Python利用scikit learn来告诉大家如何进行k值的选择:
在本次实验中我们对scikit learn 内置的手写体数据集进行分类,具体内容见程序注释:
代码块
#coding=utf-8
from sklearn import cross_validation,neighbors,datasets
import matplotlib.pyplot as plt
def chooseK():
digits = datasets.load_digits() #导入手写体数据集
X_train,X_test,Y_train,Y_test = cross_validation.train_test_split(digits.data,digits.target,
random_state=33,test_size=0.25)
#对数据进行随机划分,其中测试集的比例为25%
ks = range(1,100) #k的取值范围,1到训练数据集的大小
trainScore = [] #存储训练集的得分
testScore = [] #存储测试集的得分,得分越高越好
for k in ks:
clf = neighbors.KNeighborsClassifier(n_neighbors=k)#调用KNN分类,把KNN中的k设为K
clf.fit(X_train,Y_train)#训练KNN
trainScore.append(clf.score(X_train,Y_train))#不同k值的分类器在训练数据集的得分
testScore.append(clf.score(X_test,Y_test))#不同k值的分类器在测试数据集的得分
fig = plt.figure()#下面主要是画图,把k值与训练数据与测试数据的得分的关系表示出来
ax = fig.add_subplot(111)
ax.plot(ks,trainScore,label='train score')
ax.plot(ks,testScore,label='test score')
ax.set_xlabel('ks')
ax.set_ylabel('score')
ax.set_ylim(0,1)
ax.legend()
plt.show()
>>>chooseK()#运行程序
运行结果如下:
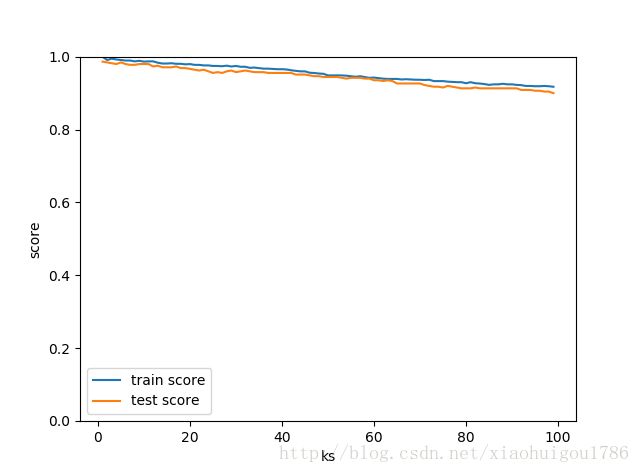
由上图可以看出在这种情况下,训练集和测试集的得分随着k的增大而减少,因此我们可以很自然的选择k为1。但其实很多情况并不是这样的,而是随着k的增大,测试误差先减少后增大,我们此时就可以选择对应于最小测试误差的k值。















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









