






Go 语言:变量、常量与类型
注释
注释用于解释说明代码,提供程序可读性。在编写程序时,我们应该尽量的书写注释。方便后续维护我们的代码。Go 语言提供了两种注释风格:块注释 和 行注释
块注释:与 C 语言的注释风格相同,即使用符号
/*标记注释起始位置,使用*/符号标记注释结束位置。在使用块注释时,需要注意, 在
/* ... */之间,不能嵌入*/这样连续的符号。除此之外,没有其他任何要求
/*
第一行
第二行
*/
行注释:与 C++ 的注释风格相同。即使用
//标记注释起始位置,随后直到该物理行整行都是注释内容
// 行注释
// 行注释
在 Go 语言中 行注释是常态。但在 表达式内 或要 禁用大量代码 时,块注释也很有用。对函数、结构体进行注释时,习惯把注释写在上面;对包进行注释会写在 package 之上
// main 包注释,解释包的作用
package main
import "fmt"
// add takes two integers and returns the sum of them
// 这是函数的说明文档
func add(a, b int) int {
// This is a comment
return a + b
}
func main() {
/* this is also a comment */
result := add(1, 2) // Call function add
fmt.Println(result) // Print result (3)
}
此外,Go 语言可以使用一些提示词进行注释,方便进行文档生成
// TODO: 将来完成,推荐
// NOTE: 请注意
// Deprecated: 告知已经过期,建议不要使用。未来某个版本可能移除
第一个 Go 程序
学习一门语言最好的方式就是使用它编写程序。下面我们开始第一个 Go 程序 hello.go 的编写。
首先,我们在 vscode 中打开一个目录,新建一个 hello.go 的文件并键入如下内容
package main
import "fmt"
func main() {
fmt.Printf("hello, world!\n")
}
然后,打开终端,使用 go run 执行上述代码的结果为
➜ go run hello.go
hello, world!
当然,我们也可以利用之前安装的 Go 调试工具,按 F5 运行,可能有如下提示
go: go.mod file not found in current directory or any parent directory; see 'go help modules' (exit status 1)
这是应为从 Go1.16 版本开始默认启用 go mod 管理 Go 程序依赖。我们只需要在命令行中执行如下命令即可
➜ go mod init github.com/duyupeng36/go/hello
go: creating new go.mod: module github.com/duyupeng36/go/hello
go: to add module requirements and sums:
go mod tidy
关于 Go 包管理我们后续介绍,现在只需要知道这个概念即可
现在,再次按下 F5,此时就会输出如下内容

向控制台输出
"hello, world!\n"是大部分编程语言书籍中的第一个示例程序,它源自于 《The C Programming Language》
我们的第一个程序已经成功运行,下面我们逐行解释这个程序
// package xxx这条语句用于声明包。main 包是一个特殊的包
package main
// import xxx 这条语句用于导入 Go 程序依赖的包
import "fmt"
// main 函数,这是 Go 可执行程序的入口函数
func main() {
// fmt.Printf() 是调用 fmt 包中的 Printf() 可执行程序的入口函数
fmt.Printf("hello, world!\n")
}
main 包是编写可执行 Go 程序的入口包。main() 函数是可执行程序的入口函数
包
Go 程序是由不同的包组成的。程序从main 包开始运行。导入包时,Go 编译器会更具源码中提供的 包路径 加载包。按照惯例,包的名称与导入路径的最后一个元素相同。如下例程,包的导入路径为 "fmt" 和 "math/rand"。
package main
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("My favorite number is", rand.Intn(10))
}
导入包
import 关键字用于导入 Go 包,每次可以导入多个包,需要使用圆括号 () 将需要导入的包括起来,每个包独占一行。这样形成了一个包导入 分组
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("Now you have %g problems.\n", math.Sqrt(7))
}
当然,也可以编写多个导入语句,例如
import "fmt"
import "math"
分组导入是更好的风格
变量与常量
对象 是可以在其中 表示值的一块存储区域。
执行环境中的 数据存储区域,其 内容可用于表示值
在被引用时,对象可以具有特定的类型
变量
变量就是对象的一个例子。变量本质上就是一块 数据存储区域,其中存储的 位模式 可用于表示 值。变量 被引用 时,会 根据特定的 类型 解释其内容(位模式)
类型 决定了存储区域的尺寸,以及其中存储的 位模式表示的内容,
如何引用一个变量呢?在大部分程序设计语言中,采用 变量名 引用一块内存区域(对象)。下图形象的表示一个变量
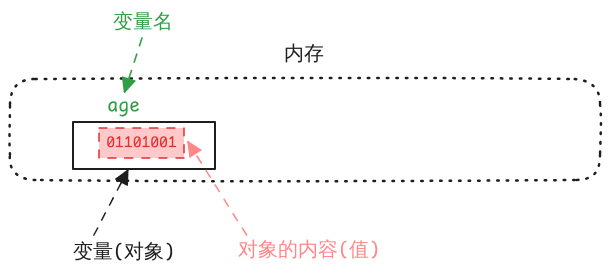
使用变量的第一步就是要 声明变量。在 Go 语言中,使用关键字 var 进行声明。一个较为完整的声明语句如下
var <变量名1>, <变量名2> ... <类型> [= 初始值1, 初始值2, ...]
类型:用来说明变量所存储的数据的种类。目前,我们将只限定在两种类型范围内:int 类型和 float64 类型
-
int(integer)型变量可以存储 整数,如01392或-2553 -
float64(floating-point)型变量可以存储比int型变量大得多的数值。float64类型的变量可以存储 带小数的数,如379.125
请注意:
float64型变量所存储的数值往往只是实际数值的一个近似值。如果在一个float64型变量中存储0.1,以后可能会发现变量的值为0.099 999 999 999 999 87,这是舍入造成的误差
变量名:指代一个对象。请注意, 这里的 对象 是一个表示 数据存储区域。当这块数据存储区域被引用时,保存在此的位模式就会按照 类型 进行解释
初始值:指定数据存储区域中最开始的位模式。在 Go 语言中,所有的变量都会默认初始化为 零值,这种机制称为 零值初始化,确保每个声明的变量总是有一个良好定义的值,因此 在 Go语言中不存在未初始化的变量
例如,声明几个相同类型的变量
var height, length, width, volume int
var profit, loss float64
变量通过 赋值 的方式获得值。一旦变量被赋值,就可以用它来辅助计算其他变量的值
height = 8;
length = 12;
width = 10;
/* 通过变量名引用对象的值 */
volume = height * length * width; /* volume 现在是 960 */
出来这种基本的变量声明方式外,Go 语言还支持其他的变量声明方式
批量声明
在声明变量时,我们可以使用圆括号() 批量声明不同类型的变量
var (
<变量名1> <类型1> [=初始值1]
<变量名2> <类型2> [=初始值2]
...
)
类型自动推导
在声明变量时,如果提供了初始值,可以省略 <类型>。因为, Go 编译器可以从初始值中推断变量的类型。也就是说,我们可以简化变量的声明语句为
var <变量名1>, <变量名2> ... = 初始值1, 初始值2 ... // 类型推导
或者
var (
<变量名1> = 初始值1
<变量名2> = 初始值2
....
)
短变量声明
如果在函数内部声明变量,可以使用 短变量声明
func main() {
<变量名1>, <变量名2> ... := <初始值1>, <初始值2> ...
}
注意:使用简短变量,必须在函数内部。并且 必须提供初始值。不提供初始值是不可能进行短变量声明的
这种声明应该只用在可以提高代码可读性的地方。并且,:= 是声明语句,而 = 是变量赋值操作
i, j = j, i // 交换 i 和 j 的值
简短变量声明语句 也可以用函数的返回值来声明和初始化变量,像下面的 os.Open 函数调用将返回两个值
f, err := os.Open(name)
if err != nil {
return err
}
// ....
f.Close()
在下面的代码中,第一个语句声明了 in 和 err 两个变量。在第二个语句只声明了 out 一个变量,然后对已经声明的 err 进行了赋值操作。
in, err := os.Open(infile)
// ...
out, err := os.Create(outfile)
简短变量声明语句中 至少有一个新的变量,下面的代码将不能编译通过
f, err := os.Open(infile)
// ...
f, err := os.Create(outfile)
// compile error: no new variables on left side of :=
常量
常量本质和变量一样,唯一不同的就是 数据存储区域中的 位模式不能被修改。在 Go 语言中,支持三种常量:字面值常量 和 const 常量
字面值常量
在高级程序设计语言中,写出来就代表了一个确定的 值,它是一个常量,不能被修改
例如,日常生活中使用的数字
Go 语言,包大部分语言中,字面值都会有一个默认的类型。关于字面值的默认类型,我们在后续基本数据类型中介绍
下面,我们看 Go 语言支持的集中字面值:数字字面值、字符字面值 、字符串字面值、bool 字面值、预定义常量
// 数字字面值
100
0x6162 0x61_62_63
3.14
3.14e2
3.14E-2
// 字符字面值
'测'
'\u6d4b'
'\x31'
'1'
'\n'
// 字符串字面值
"abc" "\x61b\x63"
"测试" "\u6d4b试"
"\n"
// bool 字面值
true
false
// 预定义常量
iota
// 零值常量
nil
声明常量
在 Go 语言中,使用 const 关键字声明一个常量,其语法与变量的声明的语法类似。
const RED int = 0x01
const GREEN int = 0x04
const BLUE int = 0x08
请注意,常量必须在声明时赋初始值,声明完成之后不允许修改。例如
const a int // 声明完成后,a 的值一定是 0 并且不能被修改
常量在声明时必须提供初始值,因此,通常情况下,我们声明常量时都会省略类型
const a = 10 // 自动确定类型
类型化与非类型化常量
Go 将常量分为两种类型:类型化常量(typed constant)和非类型化常量(untyped constant)
类型化常量:使用
const关键字定义常量时,明确说明了这个常量的类型
例如,常量 age 如下声明,明确了 age 是 int 类型
const age int = 10 // age 是类型化常量
非类型化常量:使用
const关键字定义常量是,没有说明这个常量的类型
例如,常量 name 如下声明,没有指定 name 是什么类型。
const name = "dyp" // name 是非类型化的常量
重要: 所有的字面值都是非类型化常量,非类型化常量具有一个 默认类型。后续会介绍各种字面值的默认类型。
非类型化常量可以赋值给类型化常量或变量,因为在需要的时候,非类型化常量可以被 Go 编译器 自动转换 为当前上下文需要的类型。如下示例,说明了非类型化常量可以自动进行类型转换
const a = 10
var b float64 = 10
result := a + b // 非类型化常量 a 被编译器自动转换为了 float64
fmt.Println(result) // 20
如果 a 是类型化常量,a + b 则会报错
const a int = 10 // 类型化常量
var a float64 = 10
result := a + age
// invalid operation: a + age (mismatched types float64 and int)
fmt.Println(result)
警告:并非所有非类型化常量都能自动转换完成。Go 自动类型转换是 禁止窄化类型转换。例如,
const PI = 3.1415926535
var r = 10
result := PI * r * r
// 错误 PI (untyped float constant 3.14159) truncated to int
这里 PI 是非类型化常量,在执行类转换时,将 float64 类型转换为 int 类型发生截断。Go 不允许这样的自动类型转换
批量声明常量
与变量声明一样,常量也可以进行批量声明。在变量声明的语法基础上,将 var 关键字替换 const 即可
const (
RED int = 0x01
GREEN int = 0x04
BLUE int = 0x08
)
执行批量常量声明时,除第一个常量声明外,其余常量均可以 省略初始值。如果省略初始值,则初始值使用 上一行表达式重新计算的值
const (
k = 1 // 第一行不能省略
m // 等于上一行的表达式的值
g // 1
t = k + 10 // 新的表达式
p // 上一行表达式 k + 10 的值是,因此 p 的值也是 11
q // 11
)
预定义常量 iota
在批量声明常量的语法中,我们可以使用一个预定义的常量 iota,它会在 const 关键字出现时被设置为
0
0
0,然后每增加一行常量声明,iota 的值就会被编译器加
1
1
1
下列程序验证了每次 const 已出现,预定义常量 iota 的值就被编译器设置为了
0
0
0
package main
import "fmt"
func main() {
const iota1 = iota // iota 是一个特殊的常量,可以被编译器修改的常量
const iota2 = iota
fmt.Println(iota1, iota2) // 0 0
}
通常,要在批量常量声明时,才会使用预定义常量 iota。const 中每新增一行常量声明将使 iota 计数一次(加1)
const (
a, b = iota + 1, iota + 2 // 1, 2
c, d // 2, 3
e, f // 3, 4
)
可以将
iota立即常量批量声明中的 行索引。与在同一行声明的常量个数无关,只与行数有关
const 声明的常量标识符只有一个下划线(_) 时,称为 匿名常量。该常量的 值会被丢弃,就像黑洞一样,不能使用 _ 引用常量值
// 批量写iota从0开始,即使第一行没有写iota,iota也从第一行开始从0开始增加
const (
a = iota // 0
b // 1
c // 2
_ // 按道理是3,但是丢弃了
d // 4
e = 10 // 10
f // 10
g = iota // 6
h // 7
)
// 可以认为 Go 的 const 批量定义实现了一种重复上一行机制的能力
声明变量时也可以声明匿名变量
Go 语言的 const 批量声明实现了一种重复上一行表达式的能力。应用这个能力,我们可以声明一批符合我们期望的常量。例如,声明一批偶数
// 批量写iota从0开始,智能重复上一行公式
const (
a = 2 * iota // 0
b // 2
c // 4
d // 6
)
利用 iota 智能重复计算上一行表达式的值,可以用于定义一些枚举值。例如,定义数量级
package main
import "fmt"
func main() {
const (
_ = iota
KB = 1 << (10 * iota) // 1 << (10 * 1)
MB // 1 << (10 * 2)
GB // 1 << (10 * 3)
TB // 1 << (10 * 4)
PB // 1 << (10 * 5)
)
fmt.Println(KB, MB, GB, TB, PB)
}
这里的 << 表示 左移操作,1 << 10表示将 1 的二进制表示向左移 10 位, 也就是由 1 变成了 0b10000000000,也就是十进制的 1024。 同理 2<<2 表示将 2 的二进制表示向左移 2 位,也就是由 0b10 变成了 0b1000, 也就是十进制的 8
标识符命名
变量名和常量名也被称为 标识符,标识符是一个更通用的概念,它表示程序中对象的名字。标识符在命名时必须遵循一些 规则 和 规范。规则是不可以违背的;规范必须遵守
规则
在命名标识符时,必须遵守如下规则
- 标识符只能包含 数字 字母(Unicode) 和 下划线
- 数字不能出现在标识符的开头
- 标识符不能是 Go 语言的 关键字
规范
在命名标识符时,必须遵守如下规则
- 采用
CamelCase驼峰命名法。首字母的大小写决定标识符在包外是否可见- 大写:包外可见
- 小写:仅包内可见
- 最好不要使用 Go 的 预定义标识符
- 对约定俗成的名字采用全大写形式;例如
PI - 包以小写单个单词命名。与包路径最后一部相同
- 接口优先采用单个单词命名,一般加
er后缀
此外,还有一些建议
- 不使用中文
- 非必要不要使用拼音
- 尽量遵守上面的命名规范,或 形成一套行之有效的命名规则
关键字
关键字,语言保留的标识符,这些标识符被 Go 编译器使用,不能用于定义标识符
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
预定义标识符
预定义标识符是语言提供的具有默认含义的标识符。不建议使用这些预定义标识符 作为自定义标识符
Types: 类型
any bool byte comparable
complex64 complex128 error float32 float64
int int8 int16 int32 int64 rune string
uint uint8 uint16 uint32 uint64 uintptr
Constants: 预定义常量
true false iota
Zero value: 零值
nil
Functions: 内置函数
append cap close complex copy delete imag len
make new panic print println real recover
基本数据类型
Go 语言提供了丰富的数据类型以及内建数据结构。首先介绍 Go 语言支持基本数据类型
- 布尔类型:
bool - 整数类型:
intuint - 字符类型:
byterune - 浮点数类型:
float32float64 - 字符串类型:
string - 复数类型:
complex64complex128
布尔类型
布尔类型用于表示逻辑值。在 Go 语言中,类型 bool的值只有两个预定常量,分别是 true 和 false
请注意:Go 语言与其他语言不同。类型
bool是一个独立的类型,
如果你学过 Python 语言或者其他语言,你可能见过这样的表达式
x = 1 + True
这种表达式在 Go 语言中是不成立,会抛出语法错误。因为,Go 语言中的 bool 类型不能转换为其他类型。
整数类型
Go 语言将整数区分为 有符号整数 和 无符号整数;同时,按照 尺寸 分为下面几种 不同的整数类型
| 有符号数/无符号数 | 大小 | 范围 |
|---|---|---|
int8 | 8 8 8 位 | [ − 128 , 127 ] [-128, 127] [−128,127] |
int16 | 16 16 16 位 | [ − 32768 , 32767 ] [-32768, 32767] [−32768,32767] |
int32 | 32 32 32 位 | [ − 2147483648 , 2147483647 ] [-2147483648, 2147483647] [−2147483648,2147483647] |
int64 | 64 64 64 位 | [ − 2 63 , 2 63 − 1 ] [-2^{63}, 2^{63}-1] [−263,263−1] |
uint8 | 8 8 8 位 | [ 0 , 255 ] [0, 255] [0,255] |
uint16 | 16 16 16 位 | [ 0 , 65535 ] [0, 65535] [0,65535] |
uint32 | 32 32 32 位 | [ 0 , 2 32 − 1 ] [0, 2^{32}-1] [0,232−1] |
uint64 | 64 64 64 位 | [ 0 , 2 64 − 1 ] [0, 2^{64}-1] [0,264−1] |
上表中列出的整数类型都是是与机器无关的类型。同时 Go 还提供了两种对应特定 CPU 平台机器字大小的有符号和无符号整数 int 和 uint
| 类型 | 大小 | 符号 | 备注 |
|---|---|---|---|
int | 取决于平台 | 有 | 32 32 32 位平台占 32 32 32 位; 64 64 64 位平台占 64 64 64 位 |
uint | 取决于平台 | 无 | 32 32 32 位平台占 32 32 32 位; 64 64 64 位平台占 64 64 64 位 |
此外,Go 还支持一种无符号的整数类型 uintptr,没有指定具体的 大小但是 足以容纳指针。uintptr 类型只有在底层编程时才需要,特别是 Go 语言和 C 语言函数库或操作系统接口相交互的地方
| 类型 | 大小 | 备注 |
|---|---|---|
uintptr | 取决于平台 | 存储地址 |
uintptr只是存储地址,不会引用改地址的对象。
请注意:在 Go 中这些整数类型是 完全不同的类型。不管它们的具体大小
int、uint和uintptr是不同类型的兄弟类型int和int32也是不同的类型,即使int的大小也是32bit,在需要将int当作int32类型的地方需要一个显式的类型转换操作
整数字面值
整数字面值表示 整数常量 的数字序列。通过前缀指定不同的表示方式,默认采用 十进制
0b或0B表示 二进制00o或0O表示 八进制0x或0X表示 十六进制。Go 1.13 版本开始支持
请注意:单个 0 被视为十进制零。在十六进制字面值中,字母 a 到 f 和 A 到 F 代表值 10 到 15
整数字面值都是
untyped constant,默认的类型为int
package main
import "fmt"
func main() {
// 有符号整数
var i1 int8 = 127 // 十进制
var i2 int8 = -0x7f // 十六进制
var i3 int8 = 0o177 // 八进制
fmt.Println(i1, i2, i3)
// 无符号整数
var u1 uint8 = 256
// cannot use 256 (untyped int constant) as uint8 value in variable declaration
var u2 uint8 = 0xFF
var u3 uint8 = 0o377
fmt.Println(u1, u2, u3)
}
当我们使用整数字面值赋值给一个变量时,Go 语言不允许使用超出类型的取值范围的字面值给变量赋值(溢出)
数字系统
数字系统(或数码系统)定义了如何用独特的语言符号来表示一个数字。任何语言的符号的数量都是有限的,需要重复并组合它们。由于我们使用有限的数字符号来表示数字,这意味着符号需要重复使用
如今广泛使用的数字系统有:位置化系统 和 非位置化系统。我们主要关注位置化系统。在 位置化数字系统 中,数字中符号所占据的位置诀定了其表示的值。在该数字系统中,数字的表示形式为
± ( S K − 1 … S 2 S 1 S 0 . S − 1 S − 2 … S − L ) \pm (S_{K-1}\ldots S_2S_1S_0.S_{-1}S_{-2}\ldots S_{-L}) ±(SK−1…S2S1S0.S−1S−2…S−L)
表示的值 N N N
N = ± ( S K − 1 × b K − 1 + … + S 1 × b 1 + S 0 × b 0 + S − 1 × b − 1 … + S − L × b − L ) N = \pm(S_{K-1} \times b^{K-1} + \ldots + S_1\times b^{1}+ S_0\times b^{0}+S_{-1}\times b^{-1}\ldots+S_{-L}\times b^{-L}) N=±(SK−1×bK−1+…+S1×b1+S0×b0+S−1×b−1…+S−L×b−L)
其中, S S S 是数字符号集; b b b 是基数(底),等于数字符号集合 S S S 中符号的个数
在计算机科学中,常用的数字系统有 4 4 4 种,如下表列出
| 数字系统 | 符号集合 | 基数 |
|---|---|---|
| 十进制 | { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9\} {0,1,2,3,4,5,6,7,8,9} | 10 10 10 |
| 二进制 | { 0 , 1 } \{0, 1\} {0,1} | 2 2 2 |
| 八进制 | { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , } \{0, 1, 2, 3, 4, 5, 6, 7,\} {0,1,2,3,4,5,6,7,} | 8 8 8 |
| 十六进制 | { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , A , B , C , D , E , F } \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F\} {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} | 16 16 16 |
同一个数字可以使用不同的数字系统进行表示。它们之间可以相互转换。
其他进制 => 十进制
最简单的转换规则就是将 其他进制的数字转换为十进制数字。下图展示转换过程:将数码乘以源系统中的位置量并求和
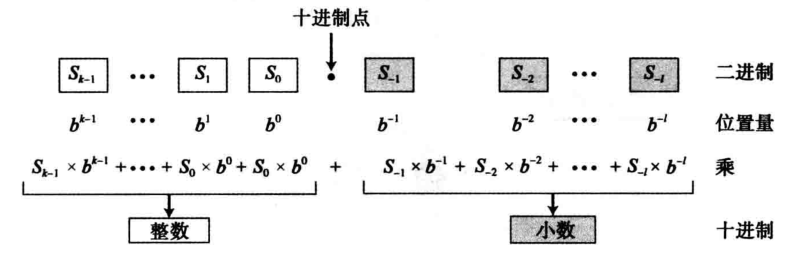
十进制 => 其他进制
将十进制数转换到与其等值的其他进制。需要两个过程,一个用于 整数部分,另一个用于 小数部分
整数部分的转换使用 连除。我们称 十进制数的整数部分为源,转换后的整数部分为目标
-
我们先创建一个空目标.接着 反复除以源并得到 商 和 余数
-
余数插入目标的 左边,商变为 新的源
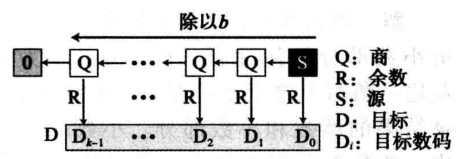
小数部分的转换可使用 连乘法。我们称十进制数的小数部分为源,转换后的小数部分的数为目标 -
我们先创建一个空目标。接着反复乘以源并得到结果
-
结果的整数部分插入目标的右边,而小数部分成为新的源
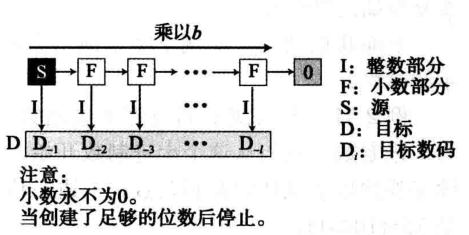
八进制-二进制-十六进制之间的相互转换
二进制-十六进制的相互转换规则:二进制中的 4 4 4 位恰好是十六进制中的 1 1 1 位
二进制-八进制的相互转换规则:二进制中的 3 3 3 位恰好是八进制中的 1 1 1 位
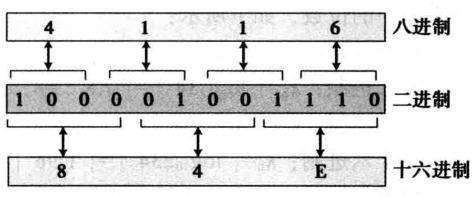
借助二进制作为桥梁,可以很方便的实现 八进制-十六进制之间的相互转换
整数编码
数据以不同的形式出现:数字、文本、音频、图像 和 视频。人们需要能够处理许多不同的数据类型
所有计算机外部的数据类型的数据都采用 统一的数据表示法 转换后存入计算机中,当数据从计算机输出时再还原回来。这种通用的格式称为 位模式。位模式是由 位 组成的序列
位是存储在计算机中最小的单位;它是 0 0 0 或 1 1 1。代表设备的某一状态,这些设备只能处于两种状态之一
位模式 是一些位组成的 位序列,也称 位流。长度为 8 8 8 的位模式被称为 1 1 1 字节。属于不同数据类型的数据可以采用相同的位模式存储在存储器中
也就是说,在计算机内部所有的数据都是 0 0 0 和 1 1 1 的序列
下面我们介绍整数在计算机内部是如何存储的。整数分为 正数 和 负数,想要完整的存储所有整数,就需要解决符号在计算机中如何表示。目前,常用的规则有两种:无符号 和 补码
无符号编码
假设一个整数数据类型有 w w w 位。我们可以将位模式 x ⃗ = [ x w − 1 , x w − 2 ⋯ , x 2 , x 1 , x 0 ] \vec x = \left[x_{w-1}, x_{w-2} \cdots, x_2,x_1,x_0\right] x=[xw−1,xw−2⋯,x2,x1,x0] 看作一个二进制表示的数,就获得了 x ⃗ \vec x x 的无符号表示
在这个编码中,每个位 x i x_i xi,都取值为 0 0 0 或 1 1 1。当 x i x_i xi 取值为 1 1 1 时,意味着数值 2 i 2^i 2i 应为数字值的一部分
无符号数编码的定义为:对于位向量 x ⃗ = [ x w − 1 , x w − 2 ⋯ , x 2 , x 1 , x 0 ] \vec x = \left[x_{w-1}, x_{w-2} \cdots, x_2,x_1,x_0\right] x=[xw−1,xw−2⋯,x2,x1,x0]
B 2 U w ( x ⃗ ) = ∑ i = 0 w − 1 x i ⋅ 2 i B2U_w(\vec x) = \sum_{i = 0}^{w-1}x_i\cdot2^i B2Uw(x)=i=0∑w−1xi⋅2i
函数 B 2 U w B2U_w B2Uw 将一个长度为 w w w 位的 0 , 1 0, 1 0,1 串映射到非负整数。例如
B 2 U 4 ( [ 0001 ] ) = 0 ⋅ 2 3 + 0 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 0 + 0 + 0 + 1 = 1 B 2 U 4 ( [ 0101 ] ) = 0 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 0 + 4 + 0 + 1 = 5 B 2 U 4 ( [ 1011 ] ) = 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 8 + 0 + 2 + 1 = 11 B 2 U 4 ( [ 1111 ] ) = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 8 + 4 + 2 + 1 = 15 \begin{aligned} &B2U_4([0001]) = 0 \cdot 2^3 + 0 \cdot 2^2 + 0 \cdot 2^1 + 1 \cdot 2^0 = 0 + 0 + 0 + 1 = 1 \\ &B2U_4([0101]) = 0 \cdot 2^3 + 1 \cdot 2^2 + 0 \cdot 2^1 + 1 \cdot 2^0 = 0 + 4 + 0 + 1 = 5\\ &B2U_4([1011]) = 1 \cdot 2^3 + 0 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = 8 + 0 + 2 + 1 = 11 \\ &B2U_4([1111]) =1 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = 8 + 4 + 2 + 1 = 15 \end{aligned} B2U4([0001])=0⋅23+0⋅22+0⋅21+1⋅20=0+0+0+1=1B2U4([0101])=0⋅23+1⋅22+0⋅21+1⋅20=0+4+0+1=5B2U4([1011])=1⋅23+0⋅22+1⋅21+1⋅20=8+0+2+1=11B2U4([1111])=1⋅23+1⋅22+1⋅21+1⋅20=8+4+2+1=15
下图展示上面几种情况下 B 2 U B2U B2U 给出的从位向量到整数的映射
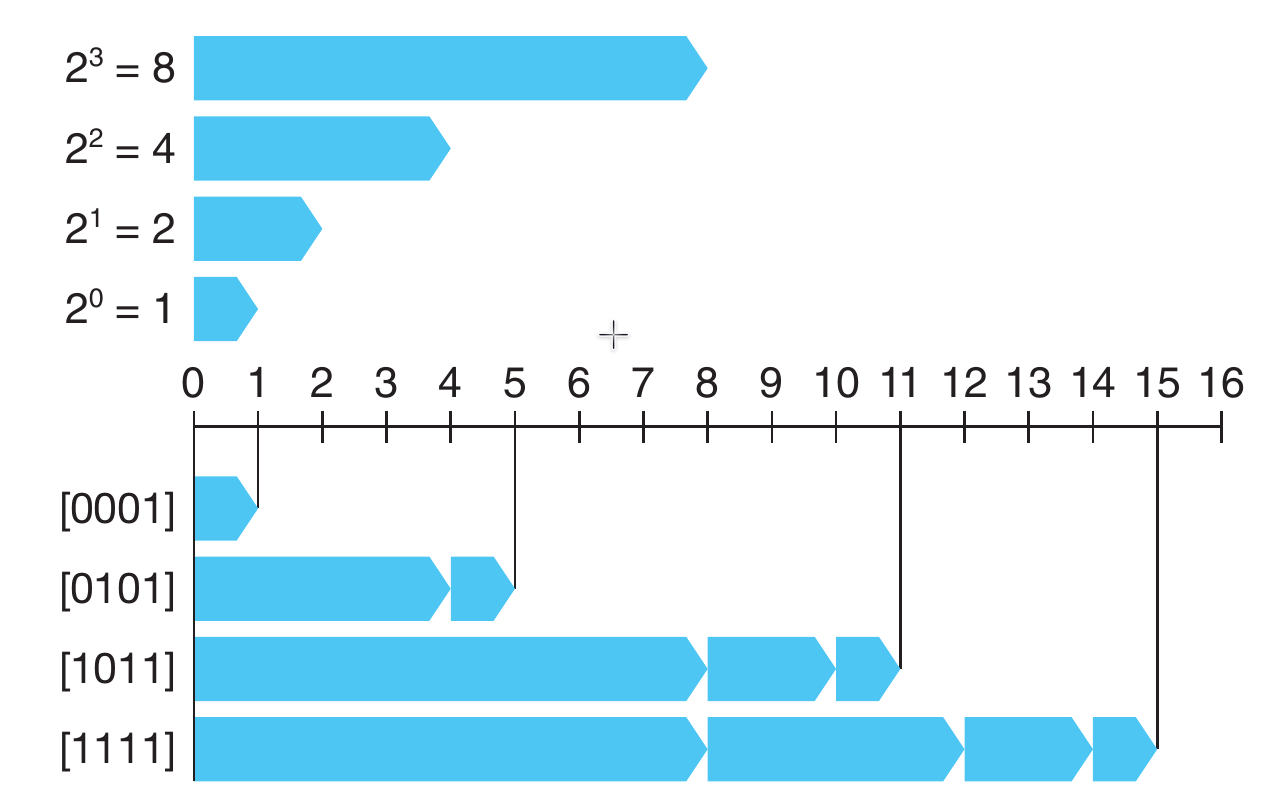
在图中,我们用长度为
2
i
2^i
2i 的指向右侧箭头的条表示每个位的位置
i
i
i 。每个位向量对应的数值就等于所有值为
1
1
1 的位对应的条长度之和。
一个长度为 w w w 位的位模式能表示的无符号数值的范围
- 最小值 使用位向量 [ 0 , 0 , ⋯ , 0 , 0 ] [0,0,\cdots, 0,0] [0,0,⋯,0,0] 表示,也就是整数 0 0 0
- 最大值 使用位向量 [ 1 , 1 , ⋯ , 1 , 1 ] [1,1,\cdots,1,1] [1,1,⋯,1,1] 表示,也就是整数 U M a x w = ∑ i = 0 w − 1 2 i = 2 w − 1 UMax_{w}=\sum_{i=0}^{w-1}2^i=2^w-1 UMaxw=∑i=0w−12i=2w−1
无符号数的二进制表示有一个很重要的属性,也就是每个介于 0 ∼ 2 w − 1 0 \sim 2^w - 1 0∼2w−1 之间的数都有唯一一个 w w w 位的值编码
补码编码
对于许多应用,我们还希望表示负数值。最常见的有符号数的计算机表示方式就是 补码。在这个定义中,将字的最高有效位解释为负权。也就是说,补码编码的定义:对于位向量 x ⃗ = [ x w − 1 , x w − 2 ⋯ , x 2 , x 1 , x 0 ] \vec x = \left[x_{w-1}, x_{w-2} \cdots, x_2,x_1,x_0\right] x=[xw−1,xw−2⋯,x2,x1,x0]
B 2 T w ( x ⃗ ) = − x w − 1 ⋅ 2 w − 1 + ∑ i = 0 w − 2 x i ⋅ 2 i B2T_{w}(\vec{x}) = -x_{w-1}\cdot 2^{w-1} + \sum_{i=0}^{w-2}x_{i}\cdot 2^{i} B2Tw(x)=−xw−1⋅2w−1+i=0∑w−2xi⋅2i
最高有效位 x w − 1 x_{w-1} xw−1 也称为 符号位,它的 权重 为 — 2 w − 1 —2^{w-1} —2w−1 ,是无符号表示中权重的负数
- 符号位被设置为 1 1 1 时,表示值为负
- 符号位被设置为 0 0 0 时,值为非负
例如
B 2 T 4 ( [ 0001 ] ) = − 0 ⋅ 2 3 + 0 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 0 + 0 + 0 + 1 = 1 B 2 T 4 ( [ 0101 ] ) = − 0 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 0 + 4 + 0 + 1 = 5 B 2 T 4 ( [ 1011 ] ) = − 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = − 8 + 0 + 2 + 1 = − 5 B 2 T 4 ( [ 1111 ] ) = − 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = − 8 + 4 + 2 + 1 = − 1 \begin{aligned} &B2T_4([0001]) = - 0 \cdot 2^3 + 0 \cdot 2^2 + 0 \cdot 2^1 + 1 \cdot 2^0 = 0 + 0 + 0 + 1 = 1 \\ &B2T_4([0101]) = - 0 \cdot 2^3 + 1 \cdot 2^2 + 0 \cdot 2^1 + 1 \cdot 2^0 = 0 + 4 + 0 + 1 = 5\\ &B2T_4([1011]) = -1 \cdot 2^3 + 0 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = -8 + 0 + 2 + 1 = -5 \\ &B2T_4([1111]) =-1 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = -8 + 4 + 2 + 1 = -1 \end{aligned} B2T4([0001])=−0⋅23+0⋅22+0⋅21+1⋅20=0+0+0+1=1B2T4([0101])=−0⋅23+1⋅22+0⋅21+1⋅20=0+4+0+1=5B2T4([1011])=−1⋅23+0⋅22+1⋅21+1⋅20=−8+0+2+1=−5B2T4([1111])=−1⋅23+1⋅22+1⋅21+1⋅20=−8+4+2+1=−1
下图展示了上述几种情况下 B 2 T B2T B2T 给出的从位向量到整数的映射
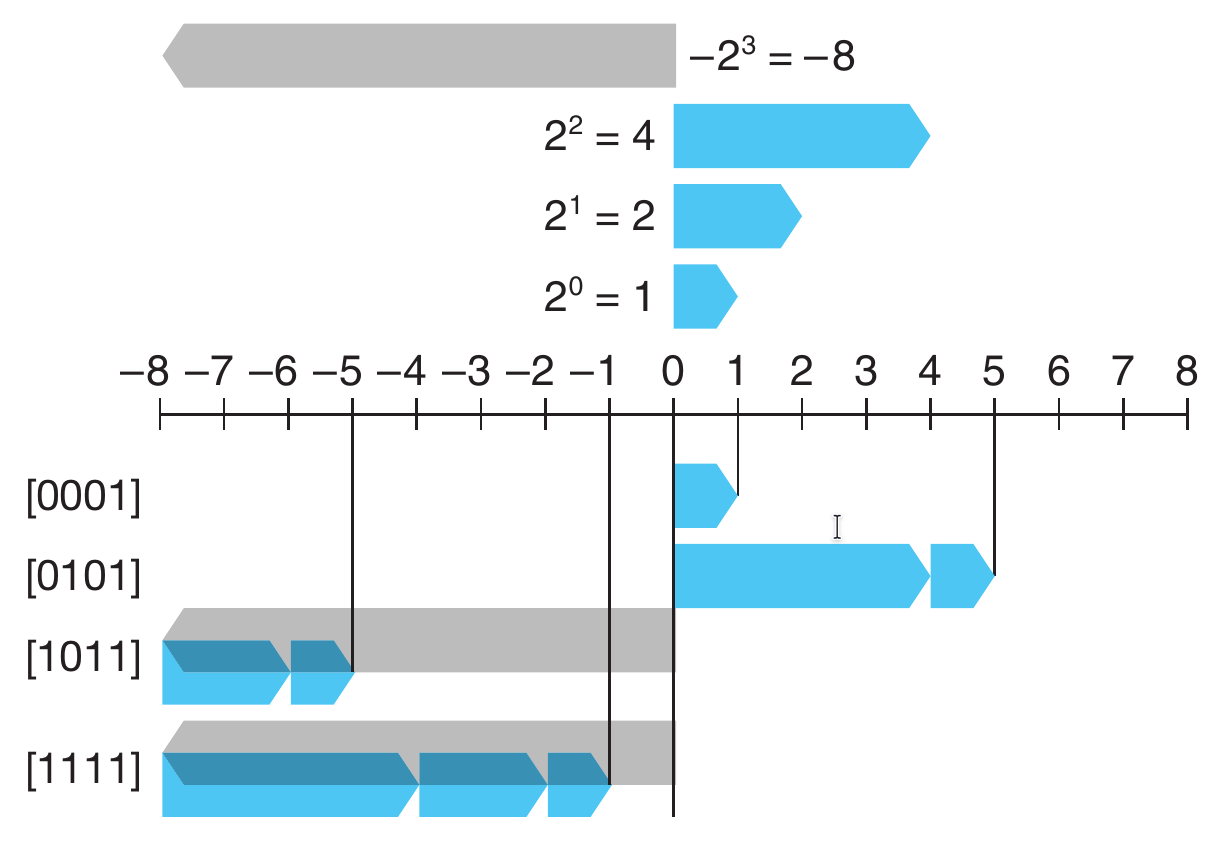
让我们来考虑一下
w
w
w 位补码所能表示的值的范围
- 最小值:补码编码能表示的最小值的位向量为 [ 1 , 0 , ⋯ , 0 , 0 ] [1,0,\cdots,0,0] [1,0,⋯,0,0],也就是设置这个位为负权,但是清除其他所有的位;其整数值为 T M i n w = − 2 w − 1 TMin_{w} = -2^{w}-1 TMinw=−2w−1
- 最大值: 补码编码能表示的最大值的位向量为 [ 0 , 1 , ⋯ , 1 , 1 ] [0,1,\cdots,1,1] [0,1,⋯,1,1],也就是清除具有负权的位,而设置其他所有的位;其整数值为 T M a x w = 2 w − 1 − 1 TMax_{w} = 2^{w-1}-1 TMaxw=2w−1−1
如何获将十进制负整数转换为二进制补码表示?这里我们需要补充两个概念:补数 与 减补数
自然数 a a a 在给定进制 N N N 下的 补数 定义为:对于给定的 进制 N,与自然数 a a a 相加后使得 位数 增加 1 1 1 的最小的数
b b b 进制数 a a a 关于 基数的补数 ( b b b 的补数): b n − a b^n−a bn−a
b b b 进制数 a a a 关于 减基数的补数 ( b − 1 b - 1 b−1 的补数),简称 减补数、侪补数): b n − a − 1 b^n-a-1 bn−a−1
其中 n n n 为当前 b b b 进制数 a a a 的位数
例如,在 10 10 10 进制下, 79 79 79 的补数就是 1 0 2 − 79 = 21 10^2 - 79=21 102−79=21
对于 N N N 进制的自然数 a = a r a r − 1 a r − 2 ⋯ a 1 a 0 a=a^ra^{r−1}a^{r−2} \cdots a^1a^0 a=arar−1ar−2⋯a1a0 规定数 b b b 的各位为 b i = ( N + 1 ) + a i b_i=(N+1)+a_i bi=(N+1)+ai。称数 b b b 为 a a a 关于 N + 1 N+1 N+1 的 补数
在二进制下,求 1 1 1 补数只需简单地将 0 0 0 与 1 1 1 相互替换。求 2 补数 (即 补码),只需要将 1 1 1 补数加 1 1 1。所以,为了求一个二进制数的 2 2 2 补数,只需要先求 1 1 1 补数,然后在加 1 1 1 即可
求十进制负整数的二进制补码表示,需要将该十进制负整数的绝对值转换为二进制表示,然后先对该二进制表示求 1 1 1 补数,然后加 1 1 1 即可得到该负数的二进制补码表示
例如,对于 − 1 -1 −1 采用 8 8 8 位位模式表示时,其绝对值 1 1 1 的二进制表示为 00000001 00000001 00000001,求 1 1 1 补数之后为 11111110 11111110 11111110,在加 1 1 1 得到 11111111 11111111 11111111
-1 的绝对值 1 的 8 位二进制表示为
0000 0001
其 1 补数为
1111 1110
2补数等于 1补数加1
1111 1111
字符类型
在 Go 中,对字符的处理与 C 语言一样,都是 将字符当做一个整数进行处理的。不同的是,Go 在处理字符时 采用了 Unicode 编码 字符。同时,也提供了对 ASCII 编码 字符的处理
在 Go 中类型 rune 是用于存储单个字符的标准类型,它是 int32 的一个别名,占
4
4
4 个字节,足以存储 Unicode 字符的编码值
type rune = int32
此外,还有另外一个类型 byte,它是 uint8 的别名,通常用于处理字节相关,无关类型的。例如,文件IO,网络IO 等。它也可以用于处理 ASCII 编码的字符
type byte = uint8 // byte 是 uint8 的别名,1 个字节
package main
import "fmt"
func main() {
var c rune
c = '中' // 字面值,代表了字符 '中' 的 Unicode 码点
fmt.Printf("%v %#[1]x\n", c) // 20013 0x4e2d
c = 0x4e2d // 可以直接给 rune 赋值整数,表示 Unicode 码点
fmt.Printf("%c\n", c) // 中
}
字符编码
在任何地区的语言中,文本 片段是用来 表示该语言中某个意思的一系列的符号
例如,在英语中使用
26
26
26 个符号(A, B, C, ...., Z) 来表示大写字母,
26
个
26个
26个 符号 (a, b, c, ...., z) 表示小写字母,
10
10
10 个符号(0, 1, 2, ...., 9)来表示数字字符(不是实际的数字;后面将看到它们的不同之处),以及符号 (. ? : ; .... !) 来表示标点。另外一些符号 (空格、换行和制表符) 被用于文本的对齐和可读性
为了在计算机中存储文本,我们 可用 位模式 来表示任何一个符号。换句话说,如
4
4
4 个符号组成的文本 "CATS" 用
4
4
4 个
n
n
n 位模式表示,任何一个位模式定义一个单独的符号
不同的位模式集合被设计用于表示文本符号。其中每一个位模式我们称之为代码, 表示符号的过程被称为 编码
- 位模式的长度取决于符号的数量,但是它们的关系并不是线性的,而是对数的;即,如果需要编码 N N N个符号,长度将是 log 2 N \log_2 N log2N
例如,编码 n n n 个字符需要的位模式长度为 log 2 n \log_{2}{n} log2n
下面我们介绍目前使用最为广泛的字符编码
ASCII 编码
美国国家标准协会(ANSI)开发了一个被称为 美国信息交换标准码(ASCII)的字符编码集。该编码集使用 7 7 7 位表示每个符号。即该代码可以定义 2 7 = 128 2^7=128 27=128 种不同的符号。
ASCII 字符集可以被分为 可打印字符 和 控制字符。下表来源于 ASCII 字符集。
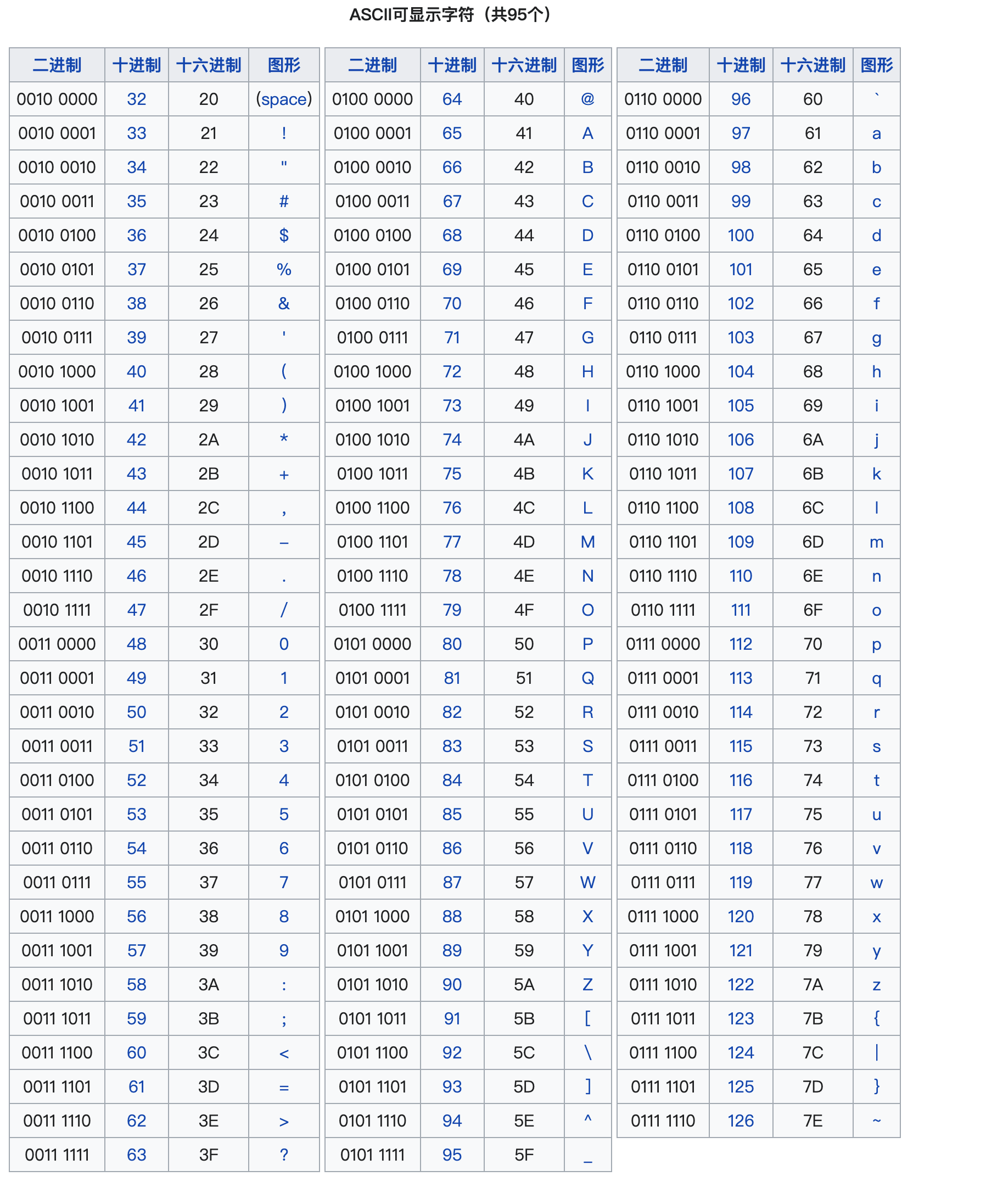
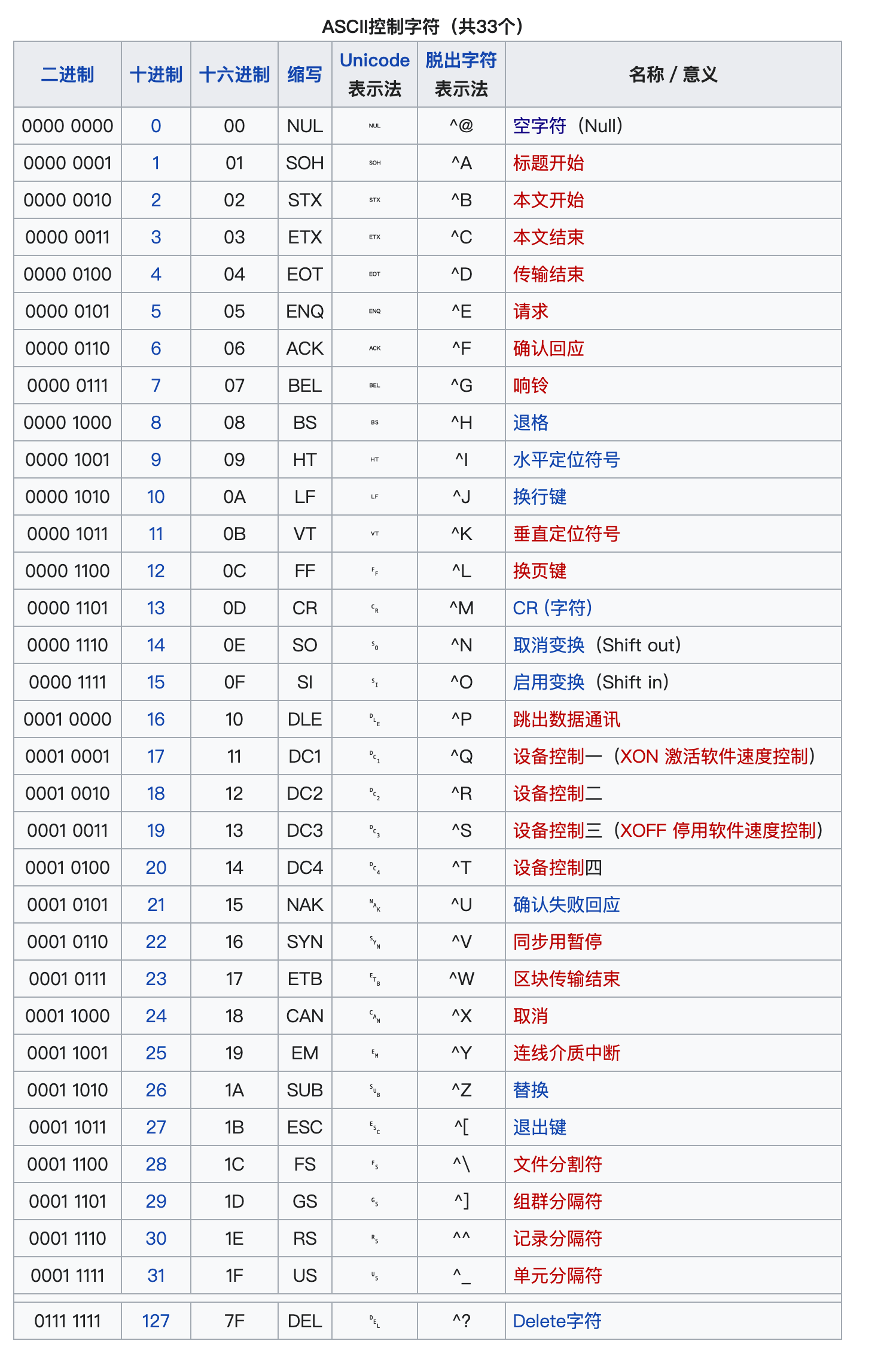
关于 ASCII 字符集我们需要记忆几个关键的字符的编码
| 字符 | 位模式 | 十进制 | 十六进制 |
|---|---|---|---|
NULL 字符 ('\0') | 000 0000 | 0 | 0x00 |
SPACE 字符 (' ') | 010 0000 | 32 | 0x20 |
HT 字符 ('\t') | 000 1001 | 9 | 0x09 |
CR 字符 ('\r') | 000 1101 | 13 | 0x0d |
LF 字符 ('\n') | 000 1010 | 10 | 0x0a |
VT 字符 ('\v') | 000 1011 | 11 | 0x0b |
FF 字符 ('\f') | 000 1100 | 12 | 0x0c |
字符 '0' | 011 0000 | 48 | 0x30 |
字符 '1' | 011 0001 | 49 | 0x31 |
字符 'A' | 100 0001 | 65 | 0x41 |
字符 'a' | 110 0001 | 97 | 0x61 |
Unicode 编码
随着计算机在全世界的普及和互联网的发展,让计算机能处理特定区域的文本迫在眉睫。每个地区都设计了能够处理当地文本的字符集。例如,中国的 GB/T 2312, GBK,日本的 Shift JIS 等编码
由于不同地区使用的字符集编码方式不同,在不同国家间就会经常出现不兼容的情况。很多传统的编码方式都有共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。
同一个位模式在不同的字符集中可能表示不同的字符,从而会造成乱码的情况
为此,硬件和软件制造商联合起来共同设计了一种名为 Unicode 的代码,称为 统一码。它 为每一个字符而非字形定义唯一的代码(即一个整数)
统一码以一种抽象的方式(即数字)来处理字符。并将字体大小、外观形状、字体形态、文体等工作留给其他软件来处理
Unicode 编码系统可分为 编码方式 和 实现方式 两个层次
编码方式
Unicode 最基本的编码方式是 UCS-2 使用 2 2 2 字节存储每个编码,这样理论上最多可以表示 2 16 = 65536 2^{16} = 65536 216=65536 个字符。然而,当前 Unicode 编码并未使用这种基本的方式,而是采用 4 4 4 字节编码,保留了大量空间以作为特殊使用或将来扩展;这种编码方式称为 UCS-4
最新(但未实际广泛使用)的统一码版本定义了 16 16 16 个辅助平面,两者合起来至少需要占据 21 21 21 位的编码空间,比 3 3 3 字节略少。但事实上辅助平面字符仍然占用 4 4 4 字节编码空间,与 UCS-4 保持一致
实现方式
Unicode 编码方式确定了字符的二进制表示。但是,需要存储字符串时,如何存储呢?首先就是直接存储这些编号的位模式。如下实例
"hello, 世界!"
字符 编号(hex) 位模式
h 68 01101000
e 65 01100101
l 6c 01101100
l 6c 01101100
o 6f 01101111
, 2c 00101100
20 00100000
世 4E16 01001110 00010110
界 754C 01110101 01001100
! 21 00100001
011010000110010101101100011011000110111100101100001000000100111000010110011101010100110000100001
直接存储字符的位模式有一个棘手的问题!如何区分字符边界?
首先想到的就是按照编码最长的位模式存储,不足的在左边使用
0
0
0 补齐位模式。比如,按照 UCS-2 标准编码的字符,需要如下方式存储 "hello, 世界!"
00000000 01101000
00000000 01100101
00000000 01101100
00000000 01101100
00000000 01101111
00000000 00101100
00000000 00100000
01001110 00010110
01110101 01001100
00000000 00100001
好多字节存储的都是 0 0 0,这些 0 0 0 都是无效为,比较浪费内存
一个字符的 Unicode 代码是确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及 出于 节省空间 的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为 Unicode 转换格式(Unicode Transformation Format,简称为UTF)。最常用的 UTF-8(8-bit Unicode Transformation Format) 编码。UTF-8 转换格式采用了如下转换模板
U+0000 .... U+007F(0 ~ 127) 0xxxxxxx
U+0080 .... U+07FF(128~2047) 110xxxxx 10xxxxxx
U+0800 .... U+FFFF(2048~65535) 1110xxxx 10xxxxxx 10xxxxxx
UTF-8 使用 1 ∼ 6 1 \sim 6 1∼6 个字节为每个字符编码(尽管如此,2003年11月 UTF-8 被 RFC 3629 重新规范,只能使用原来 Unicode 定义的区域,U+0000 到 U+10FFFF,也就是说 最多四个字节)。比如
"hello, 世界!"
字符 编号(hex) 位模式
h 68 01101000
e 65 01100101
l 6c 01101100
l 6c 01101100
o 6f 01101111
, 2c 00101100
20 00100000
世 4E16 01001110 00010110
界 754C 01110101 01001100
! 21 00100001
01101000 01100101 01101100 01101100 01101111 00101100 00100000 11100100 10111000 10010110 11100111 10010101 10001100 00100001
UTF-8 编码 UCS-4 的编码范围为
U+0000到U+10FFFF
下图展示了 Unicode 与 UTF-8 的转换过程

转义字符序列
在介绍 ASCII 编码时,我们知道字符分为 可打印字符 和 控制字符。现代计算机输入设备 键盘 只能输入可打印字符,对于那些控制字符该如何输入呢?
在 Go 语言中,想要输入这些非打印字符需要使用 转义字符序列。Go 语言支持两种类型的转义字符:字符型 和 数字型
字符型转义字符
字符型转义字符序列使用反斜线 \ 开头,后面跟随一个字符,这样的字符序列被当做转义字符,用于表示特殊的字符。下表列出了常用的转义字符序列
| 名字 | 转义序列 | Unicode 代码点 | |
|---|---|---|---|
| 响铃符 | '\a' | U+0007 | |
| 回退符 | '\b' | U+0008 | |
| 换页符 | '\f' | U+000C | |
| 换行符 | '\n' | U+000A | |
| 回车符 | '\r' | U+000D | |
| 水平制表符 | '\t' | U+0009 | |
| 垂直制表符 | \v | U+000B | |
| 反斜杠 | '\\' | U+005C | |
| 问号 | '\?' | ||
| 单引号 | '\'' | U+0027 | |
| 双引号 | '\"' | U+0022 |
请注意:转义字符序列本质上只是一个字符,而不是多个字符
数字型转义字符
字符型转义字符很好用。但是,存在缺陷:不能表示所有的非打印字符。为了解决这个缺陷,Go 语言允许我们使用字符编码的 十六进制 或 八进制 作为转义字符。
- 十六进制的转义形式是
'\xhh',其中两个h表示十六进制数字(大写或小写都可以) - 八进制转义形式是
'\ooo',包含三个八进制的o数字
请注意:Go 语言限制数字型转义字符序列能够使用的编码范围是 0 ∼ 255 0 \sim 255 0∼255。换句话说,单个数字型转义字符使用的数字必须能够在一个字节表示的范围内
有很多 Unicode 字符很难直接从键盘输入,并且还有很多字符有着相似的结构;有一些甚至是不可见的字符。Go 语言字符字面值中的 Unicode 转义字符让我们可以通过 Unicode 码点输入特殊的字符。有两种形式
'\uhhhh'对应 16 16 16 位的码点值'\Uhhhhhhhh'对应 32 32 32 位的码点值。h表示一个十六进制数字
一般很少需要使用 32 32 32 位的形式。每一个对应码点的 UTF8 编码。例如,下面三个字符是等价的
'世' '\u4e16' '\U00004e16'
对于小于
256
256
256 码点值可以写在一个十六进制转义字节中,例如 '\x41' 对应字符 'A',但是对于更大的码点则必须使用 '\u' 或 '\U' 转义形式
例如,
'\xe4\xb8\x96'并不是一个合法的rune字符,虽然这三个字节对应一个有效的 UTF8 编码的码点
浮点数
Go 语言提供了两种精度的浮点数,float32 和 float64。它们的算术规范由 IEEE 754 浮点数国际标准定义,该浮点数规范被所有现代的 CPU 支持
| 类型 | 大小 | 范围 | 备注 |
|---|---|---|---|
float32 | 32 32 32 位 | [ − 3.4 × 1 0 38 , 3.4 × 1 0 38 ] [-3.4\times 10^{38}, 3.4\times 10^{38}] [−3.4×1038,3.4×1038] | 最大值定义在 math.MaxFloat32 |
float64 | 64 64 64 位 | [ − 1.8 × 1 0 308 , 1.8 × 1 0 308 ] [-1.8 \times 10^{308}, 1.8 \times 10^{308}] [−1.8×10308,1.8×10308] | 最大值定义在 math.MaxFloat64 |
注意:
float32与float64类型的变量不能相互赋值。是两个不同的数据类型
下面的例子展示了如何声明 float32 类型的变量
package main
import (
"fmt"
"math")
func main() {
var x float32 = 123.78
var y float32 = 3.4e+38
var max_flaot32 = math.MaxFloat32
fmt.Printf("Type: %T, value: %v\n", x, x)
fmt.Printf("Type: %T, value: %v\n", y, y)
fmt.Printf("Type: %T, value: %v", max_flaot32, max_flaot32)
}
float32 类型在采用 IEEE 754 标准的浮点数中尾数只有
23
23
23 位。float64 类型在采用 IEEE 754 标准的浮点数中尾数有
52
52
52 位。float64 类型能够提供更高的精度,应该优先使用 float64 类型,因为 float32 类型的累计计算误差很容易扩散。当整数大于
23
23
23 位能表达的范围时,float32 的表示将出现误差
var f float32 = 16777216 // 1 << 24
fmt.Println(f == f+1) // "true"!
浮点数字面值
浮点字面值是浮点常量的 十进制 或 十六进制 表示形式
十进制浮点字面值
十进制浮点字面值由 整数部分、小数点、小数部分 和 指数部分
- 整数部分 和 小数部分 采用 十进制数表示,其中的某个部分可以省略
- 指数部分由
e或E后的 可选符号(-或+) 和 十进制数 组成。指数值exp将尾数(整数和小数部分)缩放 1 0 exp 10^{\text{exp}} 10exp
下面给出了几个十进制浮点字面值示例
0.
72.40
072.40 // == 72.40
2.71828
1.e+0
6.67428e-11
1E6 // == 1 * 10 ^ 6
.25
.12345E+5 // == 12345.0
1_5. // == 15.0
0.15e+0_2 // == 15.0
十六进制浮点字面值
从 Go 1.13+ 开始支持十六进制的浮点数字面值。十六进制浮点字面值由 **前缀 0x 或 0X **、整数部分(十六进制数字)、小数点、小数部分(十六进制数字) 和 指数部分 组成( p 或 P 后跟可选的符号和十进制数)
- 整数部分 或 小数部分 可以省略其中任意一项
- 小数点也可以省略,但 指数部分是必需的
- 指数值
exp将尾数(整数和小数部分)缩放 2 exp 2^{\text{exp}} 2exp
下面给出了完整十六进制字面值的表示。中括号包围的表示可以省略
{0x | 0X} {0-9 a-f} . {0-9 a-f} p {[+ | -] 0-9}
下面是几个十六进制浮点字面值的示例
0x1p-2 // == 0.25
0x2.p10 // == 2048.0
0x1.Fp+0 // == 1.9375
0X.8p-0 // == 0.5
0X_1FFFP-16 // == 0.1249847412109375
0x15e-2 // == 0x15e - 2 (integer subtraction)
浮点数字面值是
untyped constant,默认类型是float64
浮点数编码
浮点数是带有整数部分和小数部分的数字。尽管可以使用定点表示,但是结果不一定精确或达不到要求精度。同时,很大的整数部分或很小的小数部分不应该采用定点表达式
浮点数表示法中,无论是十进制还是二进制,一个数字由三部分组成

为了使表示法定点数部分统一,小数点左边仅保留一个非零数码,这称为 规范化。规范化之后,只需要存储 符号、指数、尾数 三部分信息即可
- 符号采用 1 1 1 位存储: 0 0 0 表示 + + +, 1 1 1 表示 − - −
- 指数:定义了小数点移动的位数,可正可负
- 尾数:定义了小数点右边的二进制位数,即该数的精度。采用无符号表示法
指数 是有符号数,采用一种称 为移码 的编码方式。该表示法将正数和负数都作为无符号数存储。为了表示正的或负的整数,一个被称为偏移量正整数加到指数中,将它们统一移到非负的一边。这个 **偏移量的值为 2 m − 1 − 1 2^{m-1}-1 2m−1−1, m m m 为存储指数的位数。下图展示了 m = 4 m=4 m=4 时的移码编码

IEEE 标准协会定义了几种存储浮点数的标准。下图展示常用的两种
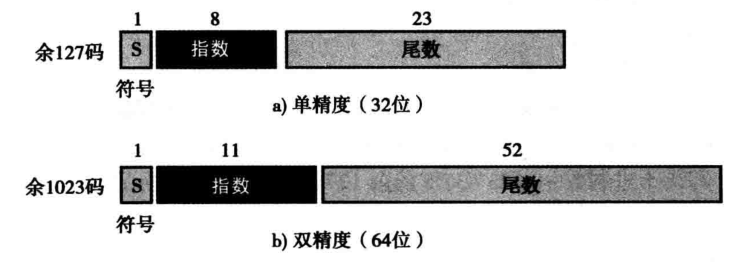
约定符号、指数、尾数都为 0 0 0 时,表示浮点数 0.0 0.0 0.0
复数类型
Go语言提供了两种精度的复数类型:complex64 和 complex128,分别对应 float32 和 float64 两种浮点数精度
内置的 complex 函数用于构建复数,内建的 real 和 imag 函数分别返回复数的实部和虚部
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
如果一个浮点数面值或一个十进制整数面值后面跟着一个 i,例如 3.141592i 或 2i,它将构成一个复数的虚部,复数的实部是 0
fmt.Println(1i * 1i) // (-1+0i) -1
字符串类型
一个字符串是一个 不可改变 的字节序列。字符串可以包含任意的数据,包括 byte 值 0,但是通常是用来包含人类可读的文本。文本字符串通常被解释为采用 UTF-8 编码的 Unicode 码点(rune)序列
在 Go 语言中,使用双引号标识一个字符串。例如,字面值 "hello, world!\n" 的类型就是字符串,其类型为 string
例如,
s := "hello, world!"
var name string = "张三"
len() 函数
请注意:在 Go 语言中,字符串按照 UTF-8 编码存储。内置函数 len() 可以获取字符串的长度
请注意:
len()返回的是字符串占用的 字节数,而非字符数目
package main
import "fmt"
func main() {
s := "hello, world!\n"
var name = "张三"
fmt.Printf("s = %s; len(s) = %d\n", s, len(s))
fmt.Printf("name = %s; len(name) = %d\n", name, len(name))
}
上述代码编译执行的结果如下
➜ hello go run hello.go
s = hello, world!; len(s) = 13
name = 张三; len(name) = 6
我们使用 len() 计算字符串 "张三" 的长度时获得结果是
6
6
6,显然不是字符数
索引
Go 语言支持我们访问字符串中的某一个字节,这种操作称为 索引。在 Go 语言中,索引从 0 开始,到 len(s)-1 结束。也就是说,如果一个字符串的长度为 5,则该字符串支持的索引为 0, 1, 2, 3, 4
package main
import "fmt"
func main() {
s := "hello, world!"
fmt.Println(s[0], s[7]) // 104 119
var name = "张三"
fmt.Println(name[0], name[2]) // 229 160
}
请注意:与其他语言不同的是,Go 语言不支持负索引
当索引超出范围时,将会导致 panic 异常
c := s[len(s)] // panic: index out of range
如果 s[i] 是字符串的第 i 个字节,那么 &s[i] 是无效的,也就是说,尝试获取一个字符串中某个字节的地址是非法的
s := "hello, world!"
fmt.Println(&s[0])
// invalid operation: cannot take address of s[0] (value of type byte)
获取子串
子字符串操作 s[i: j] 基于原始字符串 s 中截取第 i 个字节到第 j 个字节(不包含第 j 个字节本身,从而 生成一个新字符串。生成的新字符串将包含 j - i 个字节
fmt.Println(s[0:5]) // "hello"
注意:在截取子串,要求 j <= len(s) 并且 i <= j,否则将导致 panic 异常。此外,不管 i 还是 j 都可能被忽略,当它们被忽略时将采用 0 作为开始位置,采用 len(s) 作为结束的位置
s := "hello, world!"
fmt.Println(s[:5]) // "hello"
fmt.Println(s[7:]) // "world"
fmt.Println(s[:]) // "hello, world!"
自定义类型和类型别名
自定义类型
在 Go 语言中有一些基本的数据类型,如string、整型、浮点型、 bool 等数据类型, Go 语言中可以使用 type 关键字来定义自定义类型
自定义类型是定义了一个全新的类型, 我们可以基于内置的基本类型定义,也可以基于后面的 结构体类型 定义
// MyInt 将 MyInt 定义为 int 类型
type MyInt int
通过 type 关键字的定义,MyInt 就是一种新的类型,它具有 int 的特性。现在,我们使用 MyInt 定义一个变量,然后查看改变了的类型
package main
import "fmt"
type MyInt int // 使用 int 类型自定义了一个新类型
func main() {
var x MyInt
fmt.Printf("x type: %T\n", x) // x type: main.MyInt
}
自定义类型的目的就是为了非类型绑定方法。我们后续介绍
类型别名
类型别名是 Go1.9 版本添加的新功能。类型别名规定:TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是 同一个类型
- 就像一个孩子小时候有小名、乳名,上学后用学名,英语老师又会给他起英文名, 但这些名字都指的是他本人
类型别名也是使用 type 关键创建的
type TypeAlias = Type
我们之前见过的 rune 和 byte 就是类型别名,它们在 $GOTOOT/src/builtin/builtin.go 中定义
// byte 是 uint8 的别名,在所有方面都等同于 uint8。按照惯例,它用于区分字节值和 8 位无符号整数值。
type byte = uint8
// rune 是 int32 的别名,在所有方面都等同于 int32。它 用于区分字符值和整数值。
type rune = int32
类型定义与类型别名是完全不同的
package main
import "fmt"
// NewInt 类型定义
type NewInt int
// MyInt 类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a: %T\n", a) // type of a: main.NewInt
fmt.Printf("type of b: %T\n", b) // type of b: int
}
a的类型是main.NewInt,表示main包下定义的NewInt类型b的类型是int。MyInt类型只会在代码中存在,编译完成时并不会有MyInt类型



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











