






Go 语言:线性数据结构
类型与数据结构
类型
什么是类型?计算机内存中保存的始终是 位模式。给定长度为
1
1
1 字节的位模式 0x63,它究竟代表什么是不可知的;它可能是整数、可能浮点数、还可能是字符
内存中保存的始终是位模式( 0 0 0 和 1 1 1 的序列),相同序列可能代表了不同类型的数据
本来 0x63 表示数字,但是字符必须编码成为 0 和 1 的序列,才能记录在计算机系统中。在计算机世界里,一切都是数字,但是一定需要 指定类型 才能正确的理解它的含义
如果 0x63 是整数,它就属于整数类型,它是整数类型的一个具体的实例。整数类型就是一个抽象的概念,它是对一类有着共同特征的事物的抽象概念。它展示出来就是 99,因为多数情况下,程序按照人们习惯采用十进制输出
如果 0x63 是 byte 类型或 rune 类型,在 Go 语言中,它是不同于整型的类型,但是展示出来同样是 99
如果 0x63 是 string 类型,则展示出一个字符的字符串 "c"
package main
import "fmt"
func main() {
var a = 0x63
fmt.Printf("%T %d %c\n", a, a, a) // int 99 'c'
var b byte = 0x63
fmt.Printf("%T %d %c\n", b, b, b) // uint8 99 'c'
var c rune = 0x63
fmt.Printf("%T %d %c\n", c, c, c) // int32 99 'c'
var d = "\x63"
fmt.Printf("%T %s\n", d, d) // string "c"
fmt.Printf("%T %s\n", a, string(a)) // int "c"
}
类型只是应用程序使用的概念,计算机内存中保存的始终是 位模式。对于相同的位模式,不同的类型表现形式不同
通过上面的解释,我们知道 类型 是一种抽象的概念,它代表了一组相同的数据,这些数据通常称为 实例。例如,12 93 等就是整数这个概念的实例。
数据结构
数据结构 是计算机科学的基础。它们提供了一种 组织 和 存储 某种类型的实例(数据)的特定方法,以便可以 有效地访问和使用这些数据
在计算机科学中,谈及数据结构可能涉及两种类型:逻辑结构 和 物理结构
物理结构:物理结构是指数据在计算机内存中是怎样存储的。
- 顺序结构:数据一个挨着一个的存储
- 链式结构:存储数据时要同时存储与这个数据关联的另一个数据在内存中的位置
我们在谈论数据结构时,通常是指逻辑结构
逻辑结构:所谓的逻辑结构就是数据与数据之间的关系。常见的逻辑结构包括
- 线性结构:数据之间存在 一一对应的关系
- 线性表
- 栈
- 队列
- 非线性结构
- 散列表
- 树
- 图
下面我们将要学习的是线性数据结构中的 线性表。Go 语言内建了线性表的顺序存储实现——数组和切片。不过在此之前,首先需要了解线性表的相关概念
线性表
线性表,顾名思义,就是 具有像线一样的性质的序列。数学符号的记法如下:线性表记为 ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots, a_n) (a1,a2,⋯,an)
- a i − 1 a_{i-1} ai−1 领先于 a i a_i ai,称 a i − 1 a_{i-1} ai−1 是 a i a_i ai 的 直接前驱元素
- a i a_i ai 领先于 a i + 1 a_{i+1} ai+1 ,称 a i + 1 a_{i+1} ai+1 是 i _{i} i 的 直接后继元素
线性表的第一个元素没有直接前驱;最后一个元素没有直接后继
如下图所示

线性表的元素个数 n ( n ≥ 0 ) n(n \ge 0) n(n≥0) 称为 线性表的长度,当 n = 0 n=0 n=0 是称为 空表。在 非空表中的每个元素都有一个确定的位置
例如, 1 1 1 是第一个数据元素, n n n 是最后一个数据元素, i i i 是第 i i i 个数据元素,称 i i i 为数据元素 i i i 在线性表中的 位序
一年里的星座列表是不是线性表?毫无疑问是的

班级同学的花名册也是线性表。首先,它是有限的序列,类型相同。其次,每个元素除学生学号外还可以有其他的信息
比较复杂的线性表中,一个 数据元素 可以由若干 数据项 组成
顺序表
线性表
(
a
1
,
a
2
,
⋯
,
a
n
)
(a_1, a_2, \cdots, a_n)
(a1,a2,⋯,an) 的顺序存储示意图如下
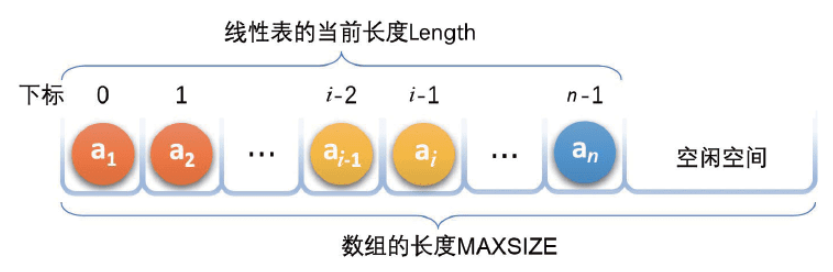
图片来源于 《大话数据结构》
顺序存储就是使用一段 连续的存储单元 依次存储线性表的数据元素。只需要知道内存空间的起始位置 ptr,内存空间存储元素的容量 MAXSIZE 和当前内存空间中已存储的元素格式 Length,就可以定位每一个元素
存储器中每个存储单元都有自己的编号,称为索引。假设线性元素占用的 c c c 个存储单元,那么线性表中第 i i i 个元素的地址可以通过如下关系得到
LOC ( a i ) = LOC ( a 1 ) + ( i − 1 ) ∗ c \text{LOC}(a_i) = \text{LOC}(a_1) + (i-1) * c LOC(ai)=LOC(a1)+(i−1)∗c
显然,对于顺序表而言,只要知道元素所在的位置,只需要通过简单的一步计算就能找到该元素。也就是说,顺序表中的元素可以 随机访问,访问效率非常高
插入
当需要向顺序表中插入一个新元素时,就会将 插入位置及之后的元素整体向后移动一个位置。最好的情形就是插入在顺序表的末尾,这样就不需要移动任何元素。然而,当插入在顺序的开头时,就需要将顺序表中的所有元素都向后移动一个位置;这样会有大量的时间浪费在移动元素的操作上。
下图展示了插入操作的过程
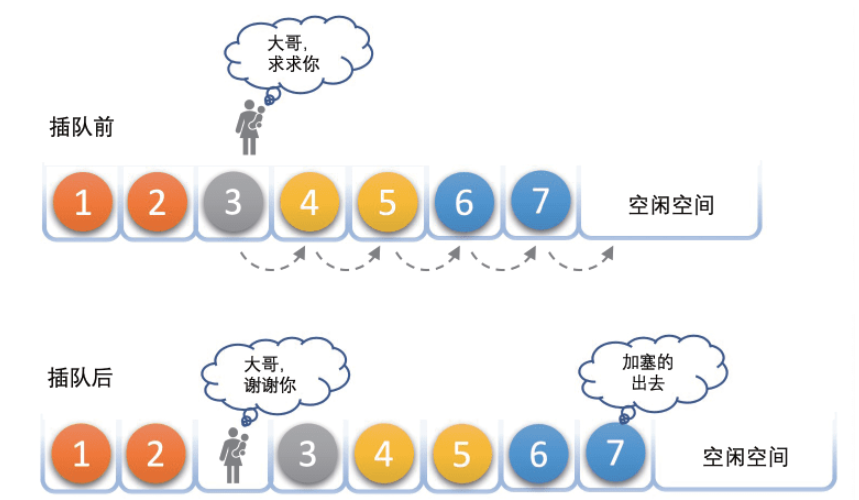
图片来源于 《大话数据结构》
删除
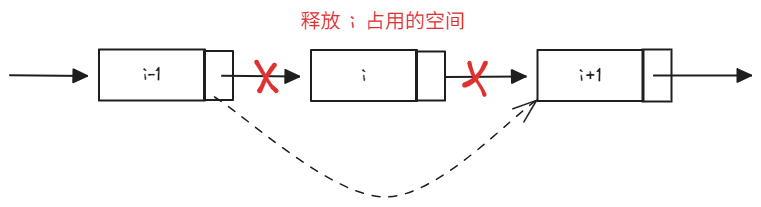
当从顺序表中删除一个元素时,为了保证满足顺序表中的元素连续存放,就需要 向前移动元素。
和插入数据一样。最好的情况就是在顺序表末尾删除元素,这样就不用移动任何元素;然而,删除操作通常是在顺序表中间,甚至是开头,这样就需要移动大量的元素
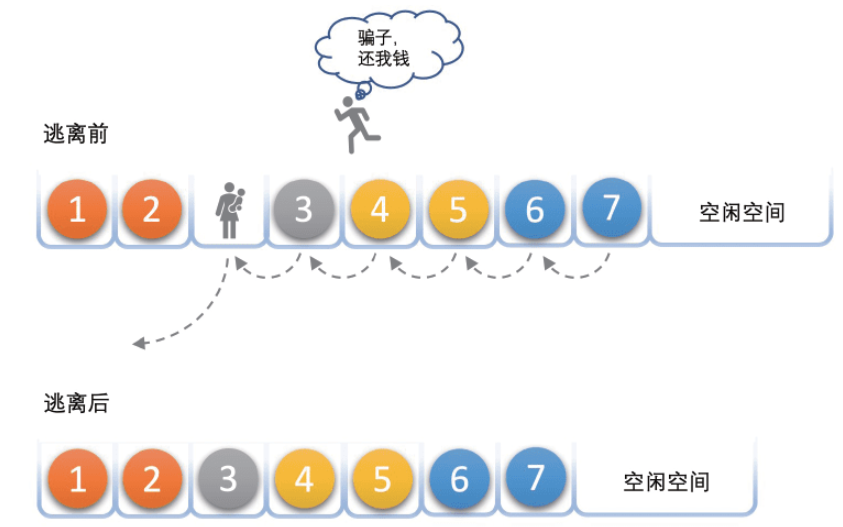
图片来源于 《大话数据结构》
链表
在顺序表中,插入和删除都需要找到插入位置和删除的位置,这是无法避免的开销。插入之前需要移动元素,将插入位置空出来;删除之后需要移动元素填充被移出的元素空闲位置。
为了避免插入之前和删除之后移动元素带来的开销,我们允许表的数据元素可以 不连续存储,这样就避免插入之前和删除之后带来的元素移动性能损耗。下图是链表的描述
由于数据元素的存储不连续,因此,为了表示每个数据元素 a i a_i ai 与其直接后继数据元素 a i + 1 a_{i+1} ai+1 之间的逻辑关系。对于数据 a i a_i ai 来说,除了存储其 本身的信息 外,还需要存储一个 表示其直接后继的信息,即 直接后继的存储位置
- 把存储数据元素信息的域称为 数据域
- 存储直接后继位置的域称为 指针域
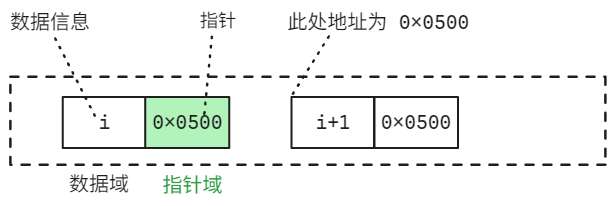
n n n 个结点链接成一个链表,即线性表 ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots,a_n) (a1,a2,⋯,an) 的链式存储结构
对于链表而言,我们需要知道 第一个元素所在的位置。只需要记录第一个元素的指针,整个链表的存取就必须从头指针开始,之后的每一个节点就是上一个的的后继指针指向的位置。链表的 最后一个结点指针为空,通常用 NULL 表示
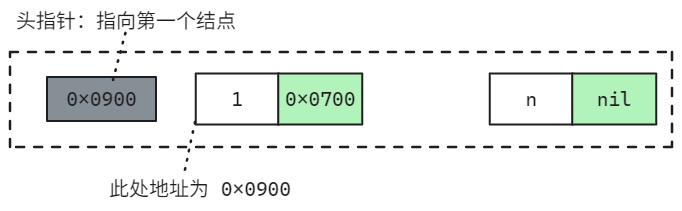
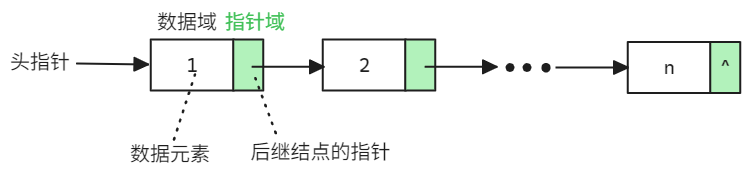
由于链表将逻辑关系存储为了结点指向其后继元素的指针。因此,我们将链表显示表示为
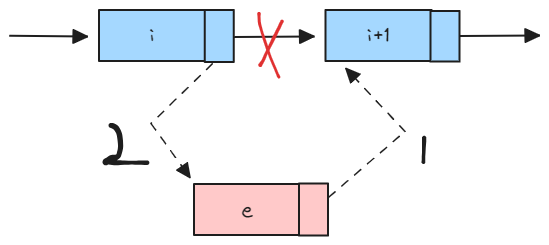
插入
假设存储元素 e 的结点为 s,插入后,结点 s 的前驱节点为 p,后继结点为 p->next,如图
删除
删除操作只需要将 前一个结点的指针域指向后一个结点即可
数组
Go 的内建数据结构——数组,它是线性表的顺序存储实现。Go 语言中的数组声明如下
var arrName [N]Type [= [N]Type{value1, value2, value3, ....}]
arrName是数组名N是数组的长度。注意:必须是一个常量表达式Type是数组元素的类型
请注意:数组的类型是 [N]Type,也就是说 N 是数组的类型。换句话说,一旦数组声明完成,那么长度就确定下来了,此时数组的长度就不能再修改了。
package main
import "fmt"
const N = 5
func main() {
var arr [N]int = [N]int{1, 2, 3, 4, 5}
fmt.Printf("arr = %v; %T\n", arr, arr)// arr = [1 2 3 4 5]; [5]int
}
初始化
请注意:
[N]Type{value1, value2, value3, ....}称为数组类型的字面值。
当声明数组时提供了初始值,那么就可以让编译器进行自动类型推导
var b = [4]int{1: 2, 3: 2}
fmt.Printf("%#v\n", b) // [4]int{0, 2, 0, 2}
此外,数组的长度也可以让编译器自动推导
var c = [...]int{10, 2, 30, 9: 20} // 长度推断为 10
fmt.Printf("%#v\n", c) // [10]int{10, 2, 30, 0, 0, 0, 0, 0, 0, 20}
初始化表达式中的
index: value用于指定初始化索引为index的数组元素。类似于 C99 标准中的 指示器
索引
数组的每个元素可以通过索引下标来访问,索引下标的范围是从 0 开始到数组长度减 1 的位置
- 内置函数
len()可以计算数组中元素的个数
var a [3]int // 3 个整数的数组
fmt.Println(a[0]) // 数组的第一个元素
fmt.Println(a[len(a)-1]) // 数组的最后一个元素
a[2] = 10
a[3] = 10 // invalid argument: index 3 out of bounds。编译期错误
注意:Go 数组 不支持负索引。索引不能越界,越界的访问将导致编译失败
遍历
遍历数组元素有两种方法:使用 索引 和 range 关键字
var a [3]int // 3 个整数的数组
// 使用索引遍历数组
for i := 0; i < len(a); i++ {
fmt.Println(i, a[i])
}
// 使用 range 关键字
for i, v := range a {
// i 索引
// v 是元素
fmt.Println(i, v)
}
内存模型
理解 Go 数组的内存模型有助于后续学习切片。下面我们详细介绍 Go 数组的内存模型
当我们声明一个数组时,会立即在内存中分配一片大小 N * sizeof(Type) 字节的内存空间
sizeof(Type)表示类型Type占用的字节数
如下图所示
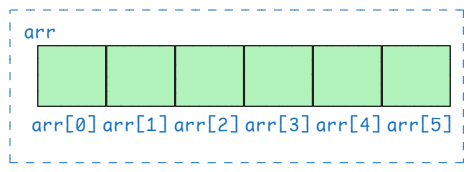
假设 Type 为 int32 类型,如下声明 [6]int32 数组
var arr = [6]int32{} // 声明一个长度为 6 数组
// 当我们给 arr[i] 赋值时
arr[0] = 10 // 会将 10 拷贝到 arr[0] 这个位置
我们可以将
arr[i]理解为一个盒子,在盒子里面装了一个int32的值。换句话说,arr[i]就是一个变量
值类型
请注意:Go 语言中的数组是 值类型。我们可以将一个数组变量赋值给另一个数组变量,前提是它们具有相同的长度和元素类型
package main
import "fmt"
func main() {
var a [3]int
var b = a // 将一个数组赋值给另一个数组变量,此时,会复制一份
fmt.Printf("&a=%p &b=%p\n", &a, &b)
b[1] = 100
fmt.Printf("a=%v b=%v\n", a, b)
fmt.Println("----------------------------")
c := showAddr(a)
fmt.Printf("从函数返回: &c=%p\n", &c)
fmt.Printf("从函数返回: c=%v\n", c)
}
func showAddr(arr [3]int) [3]int {
fmt.Printf("函数内部: &arr = %p\n", &arr)
arr[0] = 200
fmt.Printf("函数内部: arr = %v\n", arr)
return arr
}
执行上述代码输出的结果为
➜ go run array.go
&a=0xc000014078 &b=0xc000014090 # a 和 b 是两个不同的数组
a=[0 0 0] b=[0 100 0] # 修改 b 不会影响到 a
----------------------------
函数内部: &arr = 0xc0000140f0
函数内部: arr = [200 0 0]
从函数返回: &c=0xc0000140d8
从函数返回: c=[200 0 0]
Go 语言在 赋值 传参和 从函数返回 时都对数组进行了 值拷贝,都生成了一份副本
比较
Go 语言支持使用 == 和 != 运算符比较两个相同类型的数组中的元素是否相等
package main
import "fmt"
func main() {
var a [3]int = [3]int{1, 2, 3}
var b = a // 将会复制一份
fmt.Printf("a == b: %t\n", a == b) // a == b: true
}
切片
通常,我们不会在 Go 程序中直接使用数组。因为数组存在局限性。必须预估一个数组的长度。预估是不准确;如果预估过多,则会浪费内存;预估过少,则会导致程序异常
切片 是 Go 语言对数组的一层封装,可以理解为 动态数组。Go 运行时会根据切片长度动态的扩展切片的容量。
与数组一样,切片中每个元素都有相同的类型。一个 slice 类型一般写作 []Type,其中 Type 代表 slice 中元素的类型;slice 的语法和数组很像,只是 没有固定长度 而已
数组和切片之间有着紧密的联系。切片是一个轻量级的数据结构,提供了访问数组子序列(或者全部)元素的功能。切片持有一个数组的地址,一个切片由三个部分构成:指针 长度 和 容量
- 指针:指向切片的第一个元素所在的地址,要注意的是切片的第一个元素并不一定就是数组的第一个元素
- 长度:对应切片中元素的数目;长度不能超过容量
- 容量:从切片的开始位置到底层数据的结尾位置,能够容纳元素的个数
内置函数 len() 和 cap() 分别返回切片的长度和容量
声明切片
切片的类型为 []Type,为了声明一个切片,其语法如下
var Slice []Type = []Type{....} // 定义切片
和数组一样,可以省略 []Type 和 []Type{...} 中的一个
- 如果省略
[]Type,类型从初始化表达式中推断,同时会开辟初始元素个数的底层数组。长度和容量相等 - 如果省略初始化表达式
[]Type{....},Go 语言不会在内存中不会开辟底层数组。即,指针为nil,长度和容量都等于 0 0 0
省略了初始化表达式
[]Type{....}仅仅只是创建了一个切片变量,还没有底层数组被这个切片管理
package main
import "fmt"
/* 创建切片的方法 */
func main() {
var slice []int // 仅仅只是声明的一个切片,它还没有管理任何底层数组
fmt.Println(slice[0]) // panic: runtime error: index out of range [0] with length 0
fmt.Println(slice == nil) // true
}
与数组不同的,切片是引用类型,默认值为 nil。因此,声明切片就必须初始化之后才能被使用
make()
创建切片最常用并且最安全的方式是使用内置函数 make(),它 创建任意长度和容量的切片
如下所示,使用内置函数 make() 创建切片对象时,需要提供三个参数
make([]Type, len, cap)
[]Type:指定切片的类型len:切片长度cap:切片的容量
如下所示,演示了 make() 函数的使用
package main
import "fmt"
func main() {
a := make([]int, 2, 10) // 长度为 2 容量为 10
fmt.Println(a) //[0 0]
fmt.Println(len(a)) //2
fmt.Println(cap(a)) //10
a = make([]int, 10) // 长度和容量均为 10
fmt.Println(a)
fmt.Println(len(a))
fmt.Println(cap(a))
}
切片表达式
当我们在内存中已经存在数组或切片时,可以使用 切片表达式 从一个数组或切片中创建另一个切片
下面的代码声明了一个数组,表示一年中每个月份名字的字符串数组
months := [...]string{
1: "January",
2: "February",
3: "March",
4: "April",
5: "May",
6: "June",
7: "July",
8: "August",
9: "September",
10: "October",
11: "November",
12: "December",
}
这样,一月份是 months[1],十二月份是 months[12]。数组的第一个元素从索引0开始,但是月份一般是从 1 开始的,因此我们声明数组时直接跳过第 0 个元素,第 0 个元素会被自动初始化为空字符串

切片表达式 s[i:j],其中 0 <= i <= j <= cap(s),用于创建一个新的切片,引用 s 的第 i 个元素开始到第 j-1 个元素的子序列。新的切片只有 j-i 个元素
- 如果
i位置的索引被省略的话将使用0代替 - 如果
j位置的索引被省略的话将使用len(s)代替
因此,months[1:13] 切片操作将引用全部有效的月份,和 months[1:] 操作等价;months[:] 切片操作则是引用整个数组
让我们分别定义表示第二季度和北方夏天月份的切片,它们有重叠部分
Q2 := months[4:7]
summer := months[6:9]
fmt.Println(Q2, len(Q2), cap(Q2)) // [April May June] 3 9
fmt.Println(summer, len(summer), cap(summer)) // [June July August] 3 7
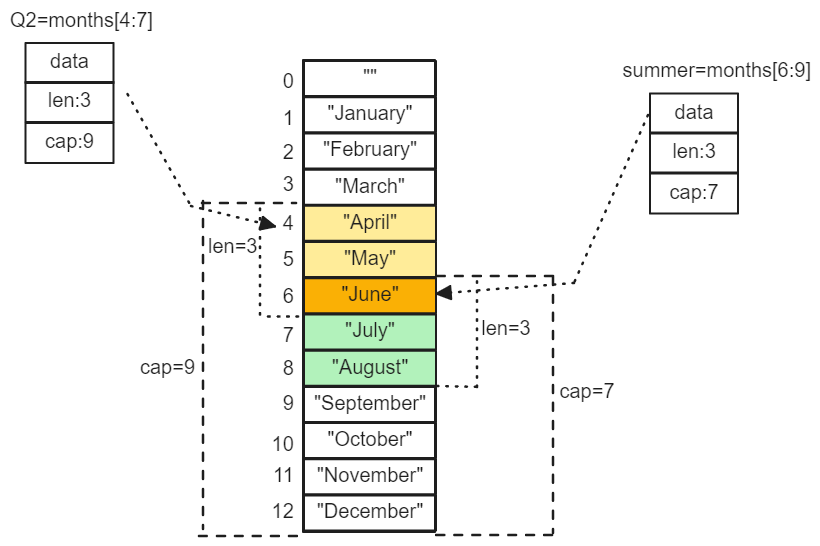
两个 slice 都包含了六月份,下面的代码是一个包含相同月份的测试(性能较低)
for _, s := range summer {
for _, q := range Q2 {
if s == q {
fmt.Printf("%s appears in both\n", s)
}
}
}
如果切片操作超出 cap(s) 的上限将导致一个 panic 异常,但是超出 len(s) 则是意味着扩展了 slice,因为新 slice 的长度会变大
fmt.Println(summer[:20]) // panic: out of range
endlessSummer := summer[:5] // extend a slice (within capacity)
fmt.Println(endlessSummer) // "[June July August September October]"
因为 slice 值包含指向第一个 slice 元素的指针,因此向函数传递 slice 将允许在函数内部修改底层数组的元素。换句话说,复制一个 slice 只是对底层的数组创建了一个新的 slice 别名。下面的 reverse 函数在原内存空间将 []int 类型的 slice 反转,而且它可以用于任意长度的 slice
// reverse reverses a slice of ints in place.
func reverse(s []int) {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
}
多个切片直接可以 共用 底层数组,引用的底层数组 部分区间可能重叠
内存模型
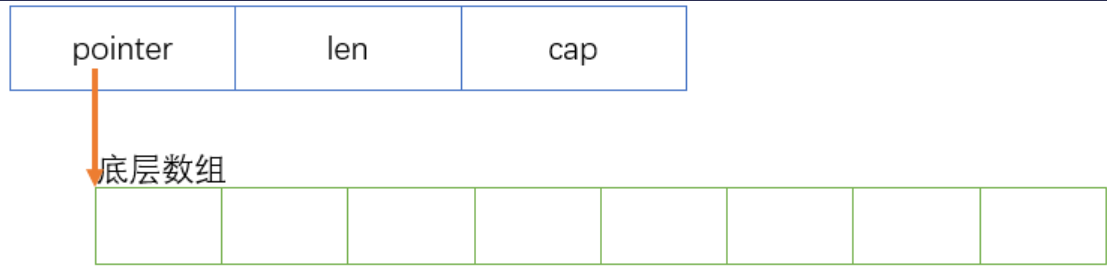
切片本质是对底层数组一个连续 片段 的引用。此片段可以是整个底层数组,也可以是由起始和终止索引标识的一些项的子集。
在 ${GOROOT}/src/runtime/slice.go 中切片的定义如下
type slice struct {
array unsafe.Pointer
len int
cap int
}
也就是说一个 slice 变量仅仅只是一个结构体,只是这个结构体引用了一个底层数组。如下图所示
请注意,Go 结构体 是值类型
var s []int = []int{1, 3, 5, 7}
fmt.Printf("%v, %p, %p\n", s, &s, &s[0])
// [1 3 5 7], 0xc00012e030, 0xc000134020
&s是切片变量的地址,&s[0]是底层数组的地址
比较
和数组不同的是,slice 之间不能比较,因此我们不能使用运算符 == 或 != 来判断两个 slice 是否含有全部相等元素
不过标准库提供了高度优化的 bytes.Equal 函数来判断两个字节型 slice 是否相等([]byte),但是对于其他类型的 slice,我们必须自己展开每个元素
func equal(x, y []string) bool {
if len(x) != len(y) {
return false
}
for i := range x {
if x[i] != y[i] {
return false
}
}
return true
}
添加元素
Go 提供了内置函数 append() 用于向切片中 添加任意多个元素
Slice = append(Slice, element1, element2, ...)
调用 append() 时,需要指定元素添加在那个切片中
- 如果切片的底层数组可以容纳新添加的元素,
append()只会导致切片的长度变化 - 如果切片的底层数组无法容纳新添加的元素,
append()会触发扩容机制,从而替换切片的底层数组
由于切片本质就是一个结构体,参数传递时执行值拷贝,被调函数内部的修改无法影响到调用函数中变量的值,因此 append() 会返回被修改后的切片
package main
import "fmt"
func main() {
s1 := make([]int, 3, 5)
fmt.Printf("s1: %p, %p, len=%d, cap=%d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
s2 := append(s1, 1, 2) // append 会返回一个新的切片
fmt.Printf("s2: %p, %p, len=%d, cap=%d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
}
上述代码运行的结果为
s1: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
---------------------------------------------------------------------
s1: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
s2: 0xc000116000, 0xc00001c0c0, len=5, cap=5, [0 0 0 1 2]
使用内存模型图可以观察的更仔细
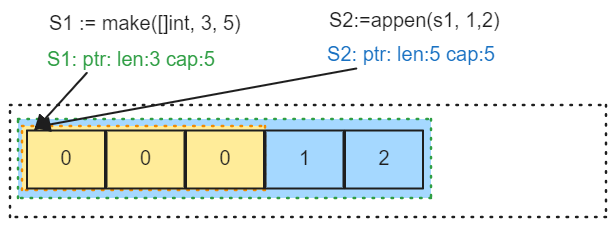
由于切片
s1的底层数组还能容纳额外 2 2 2 个元素,所以此时append()未触发扩容机制,底层数组没有被替换
继续向 s1 中添加元素
// 继续向 s1 中添加元素 -1
s3 := append(s1, -1)
fmt.Println("---------------------------------------------------------------------")
fmt.Printf("s1: %p, %p, len=%d, cap=%d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2: %p, %p, len=%d, cap=%d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3: %p, %p, len=%d, cap=%d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
这段代码的输出结果为
---------------------------------------------------------------------
s1: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
s2: 0xc000010048, 0xc00001c0c0, len=5, cap=5, [0 0 0 -1 2]
s3: 0xc000010090, 0xc00001c0c0, len=4, cap=5, [0 0 0 -1]
观察下列内存模型图
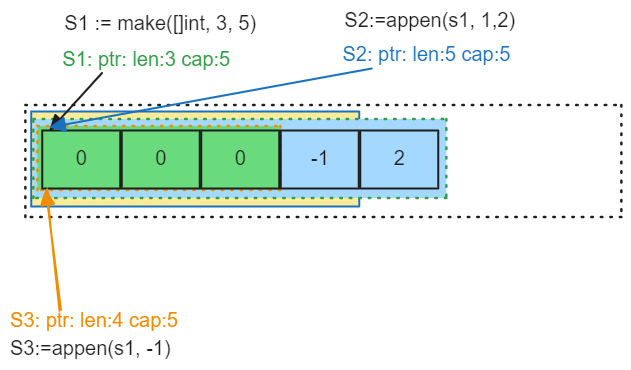
由于切片
s1长度为3,此时添加元素-1就会在切片s1的末尾新增一个元素。目前三个切片底层用同一个数组,只不过长度不一样
现在,向 s3 中添加元素 3, 4, 5
// 向 s3 中添加元素 3, 4, 5
s4 := append(s3, 3, 4, 5)
fmt.Println("---------------------------------------------------------------------")
fmt.Printf("s1: %p, %p, len=%d, cap=%d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2: %p, %p, len=%d, cap=%d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3: %p, %p, len=%d, cap=%d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
fmt.Printf("s4: %p, %p, len=%d, cap=%d, %v\n", &s4, &s4[0], len(s4), cap(s4), s4)
这段代码的执行结果为
---------------------------------------------------------------------
s1: 0xc00012e000, 0xc000130000, len=3, cap=5, [0 0 0]
s2: 0xc00012e030, 0xc000130000, len=5, cap=5, [0 0 0 -1 2]
s3: 0xc00012e078, 0xc000130000, len=4, cap=5, [0 0 0 -1]
s4: 0xc00012e0d8, 0xc000144000, len=7, cap=10, [0 0 0 -1 3 4 5]
内存模型下图
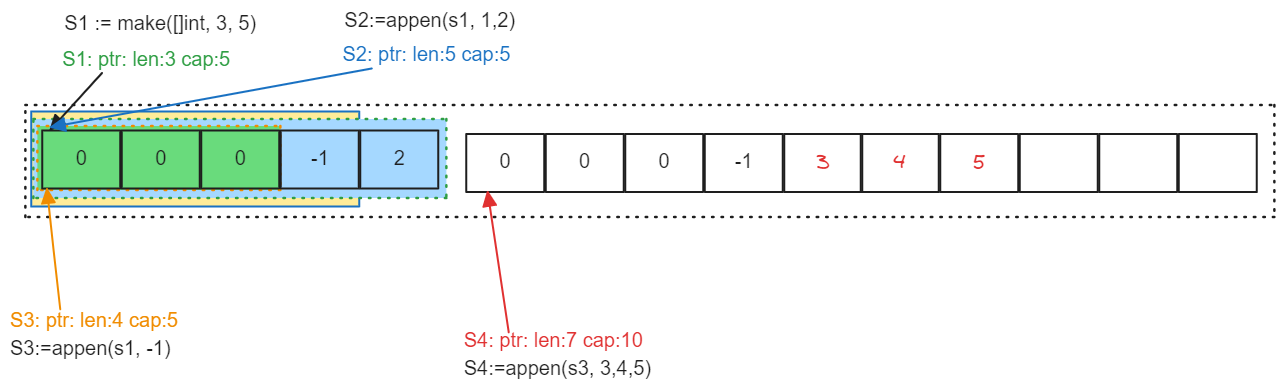
底层数组变了,容量也增加了
在 s4 的基础上,继续添加元素 6, 7, 8, 9
s5 := append(s4, 6, 7, 8, 9)
fmt.Println("---------------------------------------------------------------------")
fmt.Printf("s1: %p, %p, len=%d, cap=%d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2: %p, %p, len=%d, cap=%d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3: %p, %p, len=%d, cap=%d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
fmt.Printf("s4: %p, %p, len=%d, cap=%d, %v\n", &s4, &s4[0], len(s4), cap(s4), s4)
fmt.Printf("s5: %p, %p, len=%d, cap=%d, %v\n", &s5, &s5[0], len(s5), cap(s5), s5)
这段代码的执行结果为
---------------------------------------------------------------------
s1: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
s2: 0xc000010048, 0xc00001c0c0, len=5, cap=5, [0 0 0 -1 2]
s3: 0xc000010090, 0xc00001c0c0, len=4, cap=5, [0 0 0 -1]
s4: 0xc0000100f0, 0xc0000ae000, len=7, cap=10, [0 0 0 -1 3 4 5]
s5: 0xc000010168, 0xc0000260a0, len=11, cap=20, [0 0 0 -1 3 4 5 6 7 8 9]
内存模型图为

下面我们总结一下 append() 函数
append()一定返回一个新的切片append()可以增加若干元素- 如果增加元素时,当前
长度 + 新增个数 <= cap则不扩容- 原切片使用原来的底层数组,返回的新切片也使用这个底层数组
- 返回的新切片有新的长度
- 原切片长度不变
- 如果增加元素时,当前
长度 + 新增个数 > cap则需要扩容- 生成新的底层数组,新生成的切片使用该新数组,将旧元素复制到新数组,其后追加新元素
- 原切片底层数组、长度、容量不变
- 如果增加元素时,当前
简单来讲,使用
append()函数时,通过让其返回的切片直接覆盖原来切片
扩容策略
分析上面的输出,我们模拟下一 append() 函数的执行过程
- 需要返回一个新切片
- 根据添加元素个数判断是否需要扩容
- 目前来看,扩容只是简单的容量翻倍
func appendInt(x []int, y ...int) []int {
// 新切片:返回的切片
var z []int
zlen := len(x) + len(y) // 新切片的长度
// 判断是否还有容量可以存放元素
if zlen <= cap(x) {
// 我们还有成长的空间。扩展切片
z = x[:zlen]
} else {
// 需要扩容
// 重新分配空间
zcap := zlen
if zcap < 2*cap(x) {
zcap = 2 * cap(x)
}
z = make([]int, zlen, zcap)
// 将原来的元素复制到新的空间
copy(z, x)
}
// 添加元素
for i, v := range y {
z[len(x)+i] = v
}
return z
}
内置函数
copy(dst, src)可以方便的把src切片中的元素复制到dst切片中
测试 appendInt
var a = make([]int, 3, 5)
fmt.Printf("a: %p, %p, len=%d, cap=%d, %v\n", &a, &a[0], len(a), cap(a), a)
b := appendInt(a, 1, 2)
fmt.Println("---------------------------------------------------------------------")
fmt.Printf("a: %p, %p, len=%d, cap=%d, %v\n", &a, &a[0], len(a), cap(a), a)
fmt.Printf("b: %p, %p, len=%d, cap=%d, %v\n", &b, &b[0], len(b), cap(b), b)
c := appendInt(b, 2, 3)
fmt.Println("---------------------------------------------------------------------")
fmt.Printf("a: %p, %p, len=%d, cap=%d, %v\n", &a, &a[0], len(a), cap(a), a)
fmt.Printf("b: %p, %p, len=%d, cap=%d, %v\n", &b, &b[0], len(b), cap(b), b)
fmt.Printf("c: %p, %p, len=%d, cap=%d, %v\n", &c, &c[0], len(c), cap(c), c)
输出结果为
a: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
---------------------------------------------------------------------
a: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
b: 0xc000100000, 0xc00001c0c0, len=5, cap=5, [0 0 0 1 2]
---------------------------------------------------------------------
a: 0xc000010018, 0xc00001c0c0, len=3, cap=5, [0 0 0]
b: 0xc000100000, 0xc00001c0c0, len=5, cap=5, [0 0 0 1 2]
c: 0xc000100048, 0xc000106000, len=7, cap=10, [0 0 0 1 2 2 3]
在 $GOROOT/src/runtime/slice.go 源码中,与扩容相关代码如下:
// nextslicecap computes the next appropriate slice length.
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap // 首先将容量翻倍
// 如果申请的空间大于原来空间的两倍,则直接返回申请的容量
if newLen > doublecap {
return newLen
}
// 设定一个阈值
const threshold = 256
// 申请的空间小于原来空间的两倍 并且 原始容量小于阈值,将容量翻倍
if oldCap < threshold {
return doublecap
}
// 申请的空间小于原来空间的两倍 并且 原始容量大于或等于阈值
for {
// 从小切片增长 2 倍过渡到大切片增长 1.25 倍。这个公式可以在两者之间实现平滑过渡
newcap += (newcap + 3*threshold) >> 2 // newcap = newcap + newcap / 4 + 3 * 256 / 4 => newcap = 1.25 * newcap + 192
// 我们需要检查 `newcap >= newLen` 和 `newcap` 是否溢出。
// newLen 保证大于零,因此当 newcap 溢出时,`uint(newcap) > uint(newLen)`。
// 这样就可以通过相同的比较对两者进行检查。
if uint(newcap) >= uint(newLen) {
break
}
}
// 当 newcap 计算溢出时,将 newcap 设置为请求的上限。
if newcap <= 0 {
return newLen
}
return newcap
}
(新版本1.18+) 阈值变成了
256
256
256,当扩容后的 cap<256 时,扩容翻倍,容量变成之前的 2 倍;当 cap>=256 时,newcap +=(newcap + 3*threshold)/4 计算后就是 newcap = newcap + newcap/4 + 192,即 1.25 倍后再加 192
(老版本)实际上,当扩容后的 cap<1024 时,扩容翻倍,容量变成之前的 2 倍;当 cap>=1024 时,变成之前的 1.25 倍
扩容是耗时操作:因为需要将元素拷贝到新的内存空间
扩容是 创建新的内部数组,把原内存数据 拷贝到新内存空间,然后在新内存空间上执行元素追加操作
切片频繁扩容成本非常高,所以尽量早估算出使用的大小,一次性给够,建议使用
make。常用make([]int, 0, 100)。
思考一下:如果 s1 := make([]int, 3, 100) ,然后对 s1 进行 append 元素,会怎么样?
- 添加元素个数少于
97时,不会触发扩容策略 - 添加元素个数大于
97时,触发扩容策略
引用类型
package main
import "fmt"
func main() {
s1 := []int{10, 20, 30} // 创建一个切片类型的变量
// 切片地址(&s1) 底层数组地址(&s1[0]) 切片管理元素的个数即长度(len(s1)) 底层数组的长度即容量(cap(s1))
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
s2 := s1 // 使用 s1 创新创建了一个切片,共用同一个底层数组
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
s3 := showAddr(s1)
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3 %p, %p, %d, %d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
func showAddr(s []int) []int {
fmt.Printf("调用 append 之前: %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
// 修改一个元素
if len(s) > 0 {
s[0] = 123
}
fmt.Printf("调用 append 之前,修改s[0] 之后: %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
s = append(s, 100, 200) // 覆盖s,请问s1会怎么样
fmt.Printf("调用 append 之后: %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
return s
}
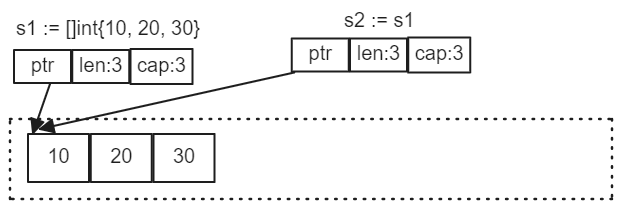
s1 := []int{10, 20, 30} 将创建一个切片,并管理一个长度为
3
3
3 底层数组。执行 s2 := s1 将创建另一个切片,管理与 s1 相同的底层数组
调用 showAddr(s1) 时,会将 s1 中的内容拷贝到 showAddr 的形参 s 中。当执行 s[0] = 123 之后,导致所有的切片都能观察到底层数组的改变
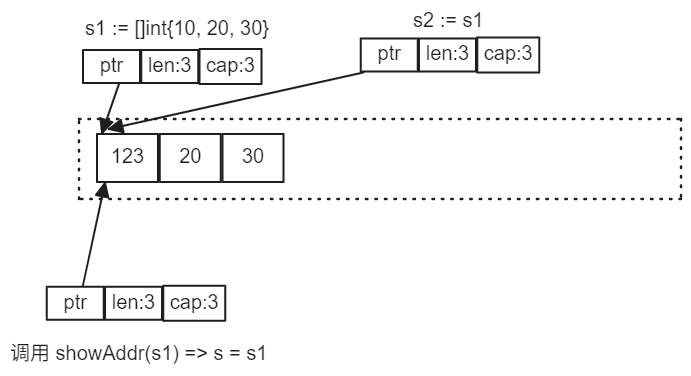
当代码执行了 s = append(s, 100, 200) 之后。内存模型变成了
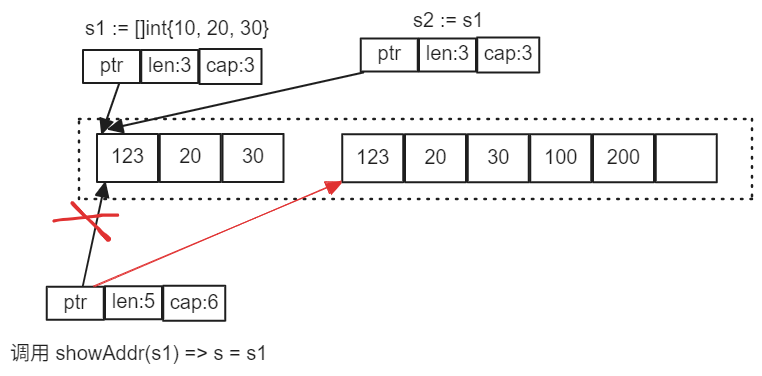
当 showAddr(s1) 返回后,内存模型变成了
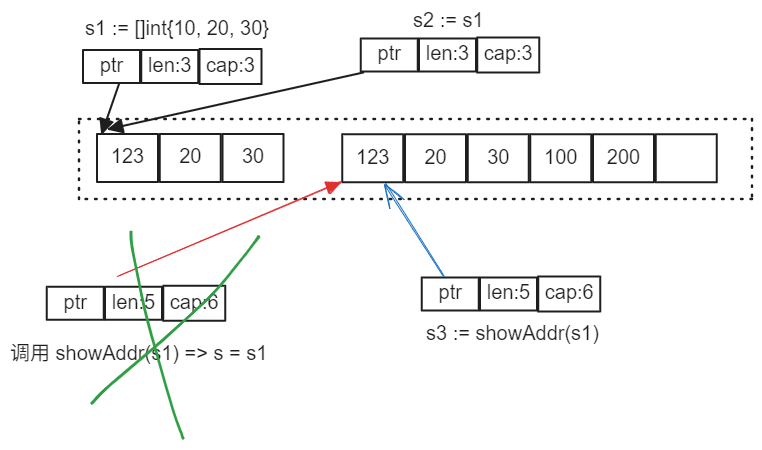
根据上述分析,这段代码的执行结果为
s1 0xc000010018, 0xc0000180c0, 3, 3, [10 20 30]
s2 0xc000100000, 0xc0000180c0, 3, 3, [10 20 30]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
调用 append 之前: 0xc000100048, 0xc0000180c0, 3, 3, [10 20 30]
调用 append 之前,修改s[0] 之后: 0xc000100048, 0xc0000180c0, 3, 3, [123 20 30]
调用 append 之后: 0xc000100048, 0xc00010e000, 5, 6, [123 20 30 100 200]
s1 0xc000010018, 0xc0000180c0, 3, 3, [123 20 30]
s2 0xc000100000, 0xc0000180c0, 3, 3, [123 20 30]
s3 0xc000100030, 0xc00010e000, 5, 6, [123 20 30 100 200]
可以看出,切片其实还是值拷贝,不过拷贝的是切片的标头值(Header)。标头值内指针也被复制,刚复制完大家指向同一个底层数组罢了
但是仅仅知道这些不够,因为一旦操作切片时扩容了,或另一个切片增加元素,那么就 不能简单归结为“切片是引用类型,拷贝了地址” 这样简单的话来解释了。要具体问题,具体分析。
总结
- 切片仅仅只是一个结构体,只是携带了 底层数组的指针、当前管理的元素个数(长度) 和 底层数组的长度(容量)
在 Go 中这样携带底层数据结构的指针的类型称为 引用类型。不要混淆其他语言中的引用类型
Go 实参传递:全是值传递
- Go 语言中的函数 实参传递 全是 值传递,整型、数组这样的类型的值是完全复制,
slice、map、channel、interface、function这样的引用类型也是值拷贝,不过复制的是标头值


















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











