






目录
一、磁盘 内存
常识:
磁盘:1.寻址:ms(毫秒)2.带宽:MB/s
内存:1.寻址:ns (纳秒) 2.带宽:GB/s
秒-->毫秒-->微妙-->纳秒
磁盘比内存在寻址上慢了10W倍
速度:内存 > 带宽(带宽可以看作网络的吞吐量 > 磁盘
内存带宽为何会如此重要呢?在回答这一问题之前,先来简单看一看系统工作的过程。基本上当CPU接收到指令后,它会最先向CPU中的一级缓存(L1 Cache)去寻找相关的数据,虽然一级缓存是与CPU同频运行的,但是由于容量较小,所以不可能每次都命中。这时CPU会继续向下一级的二级缓存(L2 Cache)寻找,同样的道理,当所需要的数据在二级缓存中也没有的话,会继续转向L3 Cache(如果有的话,如K6-2+和K6-3)、内存和硬盘。由于系统处理的数据量都是相当巨大的,因此几乎每一步操作都得经过内存,这也是整个系统中工作最为频繁的部件。如此一来,内存的性能就在一定程度上决定了这个系统的表现。
google 工程师Jeff Dean 首先在他关于分布式系统的ppt文档列出来的,到处被引用的很多。
L1 cache reference 读取CPU的一级缓存 0.5 ns Branch mispredict(转移、分支预测) 5 ns L2 cache reference 读取CPU的二级缓存 7 ns Mutex lock/unlock 互斥锁\解锁 100 ns Main memory reference 读取内存数据 100 ns Compress 1K bytes with Zippy 1k字节压缩 10,000 ns Send 2K bytes over 1 Gbps network 在1Gbps的网络上发送2k字节 20,000 ns Read 1 MB sequentially from memory 从内存顺序读取1MB 250,000 ns Round trip within same datacenter 从一个数据中心往返一次,ping一下 500,000 ns Disk seek 磁盘搜索 10,000,000 ns Read 1 MB sequentially from network 从网络上顺序读取1兆的数据 10,000,000 ns Read 1 MB sequentially from disk 从磁盘里面读出1MB 30,000,000 ns Send packet CA->Netherlands->CA 一个包的一次远程访问 150,000,000 ns
Jeff Dean,Google的软件架构天才。Google大型并发编程框架Map/Reduce作者。
在Google,公司最顶尖的编程高手Jeff Dean曾发明过一种先进的方法,该方法可以让一个程序员在几分钟内完成以前需要一个团队做几个月的项目。他还发明了一种神奇的计算机语言,可以让程序员同时在上万台机器上用最短的时间完成极为复杂的计算任务。
Jeff Dean于1999年加入Google,目前是Google系统架构小组的成员。他在Google主要负责开发Google的网页抓取、索引、查询服务以及广告系统等,他对搜索质量实现了多次改进,并实现了Google分布式计算架构的多个部分。
在加入Google之前,他工作于DEC/Compaq的Western实验室,主要从事软件分析工具、微处理器架构以及信息检索等方面的研究。他于1996年在华盛顿大学获得了博士学位,与Craig Chambers一起从事面向对象语言的编译器优化技术方面的研究。在毕业之前,他还在世界卫生组织的艾滋病全球规划署工作过。
除了拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin),在谷歌加州山景城总部,真正的牛人工程师要数杰夫·迪恩(Jeff Dean)了。
下面是谷歌员工 Heej Jones 在 Quora 上发布的关于 Jeff Dean 的一则故事:
来谷歌上班前一天,一个朋友给 Jeff 发邮件介绍了我,所以在上班的第一周,我就邀请他共进午餐。
那时候,我并不知道他是谁,也不了解他在谷歌的情况。只是午饭时,我有注意到其他餐桌的人在盯着他看,也有一些人路过我们的餐桌时会窃窃私语。
慢慢认识了更多的朋友,我才知道关于 Jeff Dean 的一些传奇故事;一位朋友曾经惊呼道:“你和 Jeff Dean 一起吃过午饭?!”。
谷歌员工都认为谷歌搜索惊人的速度都归功于 Jeff Dean,因此他也成了谷歌的名人。
大家对他的崇拜到底有多深?
你有听过关于武术战神查克·诺里斯的一些笑话吗?就像“查克从不洗盘子,盘子会因为恐惧他,自动清洗的”或者“查克被商业航班拒载,因为他的拳头会将飞机击落”等等诸如此类的笑话。
Quora 上有一大堆关于 Jeff Dean 的传奇故事,都是由崇拜他的的谷歌员工和前谷歌员工写的。如果你了解软件工程师,懂得程序员幽默的话,那你会觉得那些故事非常有趣。
有时遇到不理解的,我们也会请求 BI 首席架构师 Pax Dickinson 为我们解释那些笑话。
“编译器从不会给 Jeff Dean 警告的,Jeff Dean 会给编译器警告的。”
解释:当你的代码有误时,编译器会给出警告,但是 Jeff 比编译器还牛叉。
“Jeff Dean 提交代码前会编译和运行他的代码,只是为了检验编译器和链接器有没有问题。”
解释:Jeff 的代码从不出错,他编译代码只是为了确保编译器和链接器没有 bug。
“Jeff Dean 每次只给一条腿穿裤子,但是如果他有很多腿,你会发现他穿裤子的时间复杂度为O(log n)”
解释:Jeff Dean 穿裤子的算法复杂度是对数级的而不是线性级的,这样的话,如果他有很多条腿的话,就会大大节约穿裤子的时间。
“当 Richard Stallman 听说 Jeff Dean 的自传专属 Kindle 平台,他就去买了 Kindle。”
解释:Richard Stallman 是著名的极力反对非自由软件的人,并且从来不购买和使用 Kindle。但是 Jeff Dean 就是这样神奇,Richard 会因为想要阅读 Jeff 的自传而去违背自己的原则。”
“Jeff Dean 是直接写二进制机器代码的,他写源代码,是为了给其他开发人员作参考。”
解释:所有的代码在执行前都要先编译成二进制机器码,Jeff 是直接写二进制机器码的,他写源代码主要是方便其他程序员理解。
“Jeff 来面试谷歌时,被问到等式P=NP 成立的条件,他回答,P=0 或者N=1 时成立。然后在面试官哈哈大笑的时候,他看了一眼谷歌公有证书,就直接在白板上写出了相应的私钥。”
解释:“P与 NP 一直是计算机科学领域的一个悬而未决的问题,但是 Jeff Dean 把它想成了一个代数问题,他直接用大脑根据谷歌的公有证书算出了相应的私有秘钥,这在超级计算机看来,都是不可能的事。
“X86-64 规范有几项非法指令,标志着‘私人使用’,它们其实是为 Jeff Dean 专用。”
解释:私有的非法 CPU 指令是不能被任何人使用的,但是 Jeff Dean 就可以用。
“Jeff Dean 进行人体工程学评估,是为了保护他的键盘。”
解释:通常评估人体工程学是纠正坐姿,保护你的健康的,但是 Jeff 却是为了保护他的键盘。
“所有的指针都是指向 Jeff Dean 的。”
解释:指针是C编程的核心,但是 Jeff Dean 是编程世界的中心。
“在 2000 年末的时候,Jeff Dean 写代码的速度突然增长了 40 倍,原因是他把自己的键盘升级到了 USB 2.0。”
解释:是键盘和计算机之间接口的速度影响了 Jeff Dean 的编码速度。
1、磁盘:
①寻址--毫秒ms级别的。
对于磁盘来说一个完整的IO操作是这样进行的:当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带读写磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻址(Seeking),对应消耗的时间被称为寻址时间(Seek Time);但是找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正上方的之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay);接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后一次IO操作也就完成了。
衡量磁盘的性能最重要的两个参数就是IOPS和吞吐量。
因此只要给定了单次 IO的大小,我们就知道磁盘需要花费多少时间在数据传送上,这个时间就是IO Chunk Size / Max Transfer Rate。
现在我们就可以得出这样的计算单次IO时间的公式。
IO Time = Seek Time + 60 sec/Rotational Speed/2 + IO Chunk Size/Transfer Rate于是我们可以这样计算出IOPS。
IOPS = 1/IO Time = 1/(Seek Time + 60 sec/Rotational Speed/2 + IO Chunk Size/Transfer Rate)IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,I/O请求通常为读或写数据操作请求。随机读写频繁的应用,如OLTP(Online Transaction Processing),IOPS是关键衡量指标。另一个重要指标是数据吞吐量(Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,如VOD(Video On Demand),则更关注吞吐量指标。
简而言之:
1、磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
2、磁盘的吞吐量(指的是硬盘或设备(路由器/交换机)在传输数据的时候数据流的速度即使同一块硬盘在写入不同大小的数据时、表现出来的带宽也是不同的),也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小。
从上面的数据可以看出,当单次IO越小的时候,单次IO所耗费的时间也越少,相应的IOPS也就越大。但是,上面我们的数据都是在一个比较理想的假设下得出来的,这里的理想的情况就是磁盘要花费平均大小的寻址时间和平均的旋转延时,这个假设其实是比较符合我们实际情况中的随机读写,在随机读写中,每次IO操作的寻址时间和旋转延时都不能忽略不计。
写入10000个大小为1KB的文件,比写入一个10MB的文件耗费更多的时间。因为10000个文件需要做好几万次IO,而写入10MB的大文件,因为是连续存放,所以只需要几十个IO。
对于写入10000个小文件,因为每秒需要的IO非常高,如果用具有较高IOPS的磁盘,将提速不少。
写入10MB文件,就算用了较高的IOPS也不会提升速度。因为只需要少量的IO。只有用较大传输带宽的才会体现优势。
②带宽--单位时间内能传输的字节流能有多少,几个G或几M。
1、高传输带宽在传输大块连续数据时具有优势
2、高IOPS在传输小块不连续的数据时具有优势
2、内存:
①寻址--纳秒ns级别的。秒=1000毫秒=1000*1000微妙=1000*1000*1000纳秒。在寻址上,磁盘比内存慢了10万倍。
磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。而内存是晶体管制作的(CPU也是晶体管做的),而晶体管的特性就是我们平时常说的用开关的开和关来表示1,0,通过一些门电路的组合可用来表示数字和实现复杂的逻辑功能,而内存主要是用来临时保存数据,CPU就是处理一些逻辑关系。晶体管由于必须得通电,然后用电流的有无状态来表示信息,充放电后电荷的多少(电势高低)分别对应二进制数据0和1,所以只有通电的时候可以保存数据,电一断内存里的晶体管状态就处未知状态就啥用处也没了,而磁盘断电后磁性物质还存在。
但现在也正出现一些非易失性存储介质,及时掉电也不会失去数据。
存储介质:
| 存储 | 名称 | 描述 |
| disk | 硬盘 | |
| SSD | 固态硬盘 | 采用闪存(FLASH芯片)作为存储介质 采用DRAM作为存储介质 英特尔的XPoint颗粒技 |
| DRAM(主存) | 动态随机存取存储器 | 由于存在DRAM中的数据会在电力切断以后很快消失,因此它属于一种易失性存储器(volatile memory)设备 |
| SRAM(CPU内存) | 静态存储器 | SRAM不需要刷新电路即能保存它内部存储的数据。而DRAM(Dynamic Random Access Memory)每隔一段时间,要刷新充电一次,否则内部的数据即会消失,因此SRAM具有较高的性能,但是SRAM也有它的缺点,即它的集成度较低,功耗较DRAM大,相同容量的DRAM内存可以设计为较小的体积,但是SRAM却需要很大的体积。同样面积的硅片可以做出更大容量的DRAM,因此SRAM显得更贵 |
内存带宽
| 前端总线频率/工作频率 | 最高带宽 | |
| Pentium4 | 400MHz | 3.2GB/s |
| Pentium4 | 533MHz | 4.2GB/s |
| Pentium4 | 800MHz | 6.4GB/s |
| DDR266 | 266MHz | 2.1GB/s |
| 双通道DDR266 | 266MHz | 4.2GB/s |
| DDR333 | 333MHz | 2.7GB/s |
| 双通道DDR333 | 333MHz | 5.4GB/s |
| DDR400 | 400MHz | 3.2GB/s |
| 双通道DDR400 | 400MHz | 6.4GB/s |
3、带宽
生活中我们经常听到宽带或者是带宽之类的东西
宽带:即接入到广域网的线路,可简单理解为电信接的光纤接入。
带宽:接入宽带的理论网速上限,比如常说的100Mbps家庭宽带
为什么我们经常说我们的千兆宽带,但是却很慢呢?因为你用的实际上是有这个光纤的分时多路复用,所有人都在用。
再来聊聊单位问题:
大家都知道计算机存储设备不论内存、硬盘存储数据最终都是通过0和1实现的,这叫1位(1 bit)。而保存一个汉字需要8位(8 bit)也就是1字节(1 Byte)。位/字节都可以缩写成b/B,而大B和小b又喜欢被人混用,通常大B缩写指的是字节,小b缩写指的是位,这样很容易混淆概念。
速度单位(字节每秒 Byte/s)
有了上面的介绍就清晰了。通常下载东西,10MB/s是标准的说法,也就是每秒千万字节。不要用什么Mb/s、mB/s、mb/s这些单位。
带宽单位(位每秒bit/s)
和速度单位不同,带宽也可以说是位宽,100Mbps(100Mb/s)是标准的说法,也就是一千万兆位每秒。注意这里用到了位。所以100Mbps的带宽换算成理论最大速度是12.5MB/s,这里又变回了大B,也就是字节。
那么我们平时的千兆光纤说的是1000Mbps,这里的是指bit位而不是字节(千兆宽带理论上的下载速度是1000Mbps/8=125Mb/S)。
机械硬盘读写速度平均60---80MB每秒
固态硬盘不同品牌型号之间,平均大约在150---300MB每秒
也就是说一般的家庭网络,使用上ssd就达到上网的极限了。
什么时候会造成网络拥堵呢?
如果你使用内存数据库,如果传输数据很大笔网络带宽大很多的话就会堵死你的网络,
举例DDR3 1600HMZ的内存带宽速度就=1600HMZX64/8=12.8GB/S
可以看到内存带宽是非常之高的,基本上可以满足我们对平常对数据的所有要求。
内存带宽=内存等效频率X64/8
I/O Buffer:
磁盘中的磁道和扇区,一扇区512字节byte,如果磁盘容量很大,而扇区很小,势必会增大索引(相当于我给扇区编的号)成本。操作系统无论从磁盘读取多少数据都是以4K为单位。
随着文件变大,速度会越慢,磁盘IO会成为瓶颈。
数据库:
数据库的出现是为了改善磁盘IO的瓶颈。但整体而言,磁盘IO和数据库的IO总量是相等的,因此就有了索引的概念,如果没有索引,仅仅只是建了数据库和表,不会有太大帮助,依旧很慢。
数据库中最小的单位为page页,以4k为单位。
“4K对齐”指的是符合“4K扇区”定义格式化过的硬盘,并且按照“4K扇区”的规则写入数据。因为随着硬盘容量不断扩展,使得之前定义的每个扇区512字节不再是那么的合理,于是将每个扇区512字节改为每个扇区4096个字节,也就是常说的“4K扇区”。随着NTFS成为了标准的硬盘文件系统,其文件系统的默认分配单元大小也是4096字节,为了使簇与扇区相对应,,即使物理硬盘分区与计算机使用的逻辑分区对齐,保证硬盘读写效率,所以有了“4K对齐”概念。
硬盘中文件保存的基本单元是扇区,不管文件大小,都要占用一个扇区的空间。机械硬盘一个扇区是512字节,固态硬盘一个扇区是4K字节。
硬盘上的物理扇区和逻辑扇区
以机械硬盘为例(下同),硬盘上一般有很多盘片组成,每张盘片被划分为一块块的扇面,同时沿着半径方向被划分成了很多磁道,每条磁道与扇面形成的扇形区域就叫作物理扇区。逻辑扇区是由操作系统划分的软件层上的扇区,是为了方便操作系统读写硬盘数据而设置的,其大小与具体地址,都可以通过一定的公式与物理扇区地址对应。扇区是读写信息的最小单位 。
硬盘扇区与操作系统读写操作
以windows系统为例,在格式化硬盘时,我们会看到格式化选项卡中有“分配单元大小”一栏。其意思就是操作系统为这个逻辑分区分配的逻辑扇区空间大小,格式化后操作系统会按照这个单元大小对硬盘进行读写操作。每个分配单元只能存放一个文件。文件按照这个分配单元的大小被分成若干块存储在磁盘上。
传统的硬盘一般以512B为物理扇区大小,其分区偏移尺寸一直是从63扇区(63X512B=31.5KB)开始。大容量的机械硬盘的扇区尺寸提高至4096字节(即4KB),而电脑文件系统(FAT、NTFS等)一直都习惯以512字节的扇区单位来操作硬盘。新标准的"4K扇区"的硬盘在厂商为了保证与操作系统兼容的前提下,也将扇区模拟成512B,因此出现“4K不对齐”的情况发生。如果“4K不对齐”,那么从第63个扇区结束,往后的每一个簇都会跨越两个物理单元,占据前一个单元的一部分和后一个单元的一部分。而“4K对齐”主要是将硬盘的逻辑扇区从第64个扇区开始对齐,即操作系统从第64个扇区开始读写数据,这样就跨过了63扇区的特性,解决了每一个簇跨两个物理单元读写的问题。“4K 对齐”将成为过去
4K对齐是由于硬盘与操作系统各自的扇区单元大小不匹配、不兼容造成的。随着技术的发展和时间的推移,操作系统更新换代,硬盘厂商将不用再对物理扇区进行模拟,从而实现默认的“4K对齐”,手动的“4K对齐”将成为过去 。
“扇区对齐”将替代“4K 对齐”
正如物理扇区大小由512B扩大到4K一样,4K在不久的将来也会成为过去。操作系统支持的逻辑扇区大小已经高达2048K,由于硬盘厂商和操作系统厂商之间技术的差异,追逐与被追逐、兼容与被兼容的状况将一直持续,“4K对齐”将会变成“8K对齐”、“16K对齐”。实际上,其实质就是“扇区对齐”。“扇区对齐”将替代“4K对齐”
关系型数据库建表,必须先给出schema,数据类型(字节宽度),存数据时倾向于行级存储。先给出字节宽度的好处时,保留了位置,在插入或更新数据时直接进行覆写而不用进行数据移动。
索引也是数据,和表数据一样都存储在硬盘中。在内存中创建一棵B+树用于将索引的区间和偏移存储起来,索引和数据存在磁盘,因为内存有限,存不下这么多的数据,利用索引提高遍历查找的速度,减少磁盘IO和寻址的过程,但数据还是从磁盘获取。
内存数据库
内存虽然掉电会失去,但是如果仅仅作为查询临时存储一些小东西,可以大大减少磁盘io和增大并发量。所以内存数据库诸如redis出现了。
二、硬件层的并发

MESI Cache一致性协议
原文链接:https://www.cnblogs.com/z00377750/p/9180644.html#1140240684
概念
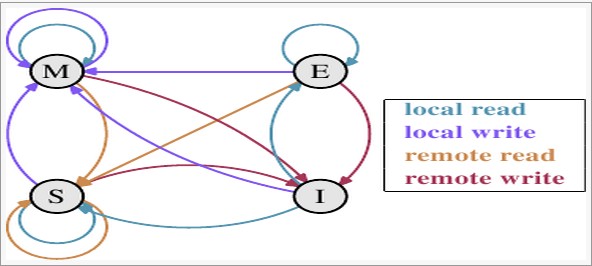
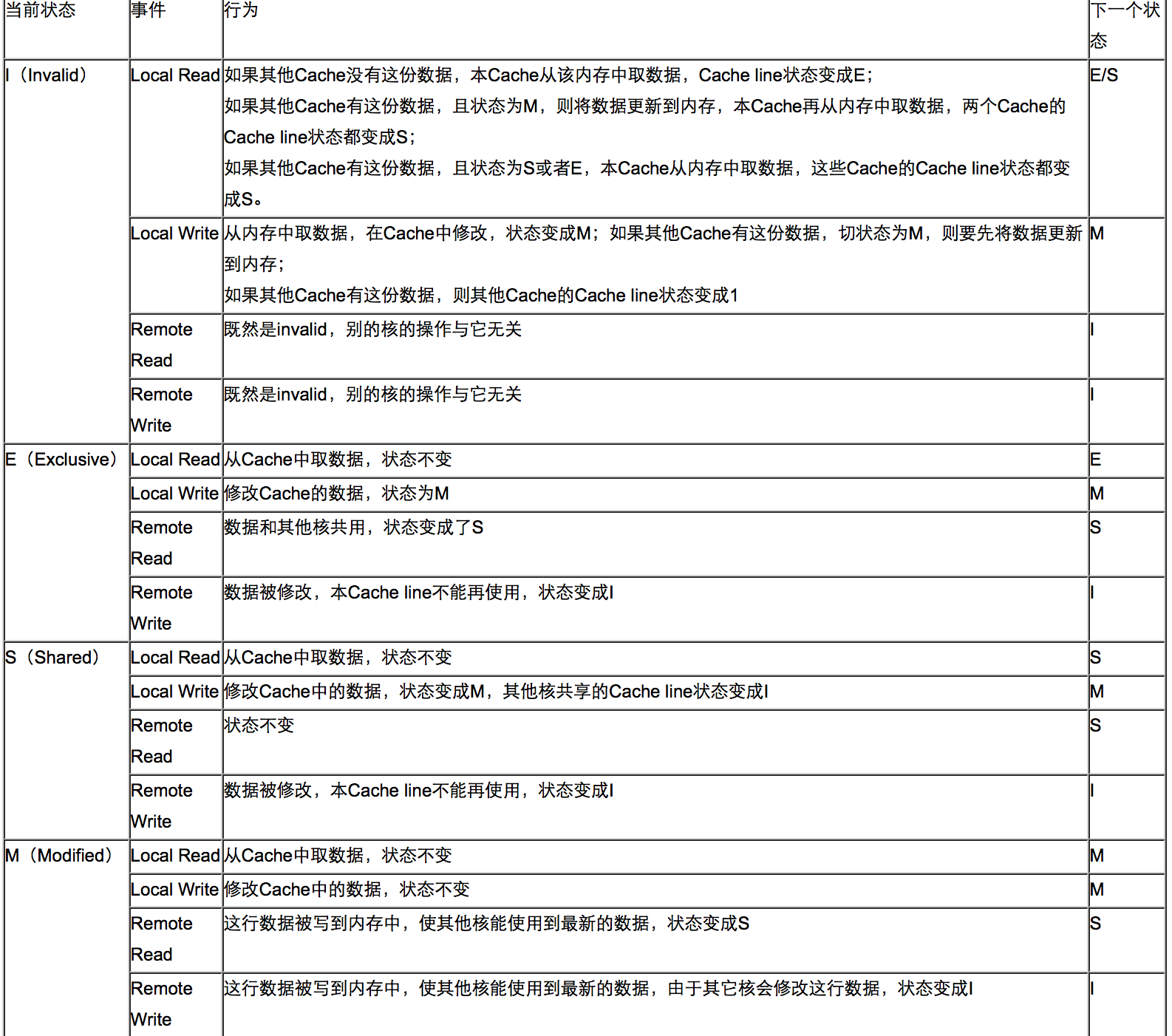
MESI(Modified Exclusive Shared Or Invalid)(也称为伊利诺斯协议,是因为该协议由伊利诺斯州立大学提出)是一种广泛使用的支持写回策略的缓存一致性协议。MESI协议中的状态
CPU中每个缓存行(caceh line)使用4种状态进行标记(使用额外的两位(bit)表示):M: 被修改(Modified)
该缓存行只被缓存在该
CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。当被写回主存之后,该缓存行的状态会变成独享(
exclusive)状态。E: 独享的(Exclusive)
该缓存行只被缓存在该
CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。同样地,当
CPU修改该缓存行中内容时,该状态可以变成Modified状态。S: 共享的(Shared)
该状态意味着该缓存行可能被多个
CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。I: 无效的(Invalid)
该缓存是无效的(可能有其它
CPU修改了该缓存行)。MESI状态转换图
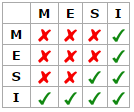
状态之间的相互转换关系也可以使用下表进行表示。
操作
在一个典型系统中,可能会有几个缓存(在多核系统中,每个核心都会有自己的缓存)共享主存总线,每个相应的
CPU会发出读写请求,而缓存的目的是为了减少CPU读写共享主存的次数。一个缓存除在
Invalid状态外都可以满足cpu的读请求,一个Invalid的缓存行必须从主存中读取(变成S或者E状态)来满足该CPU的读请求。一个写请求只有在该缓存行是M或者E状态时才能被执行,如果缓存行处于
S状态,必须先将其它缓存中该缓存行变成Invalid状态(也既是不允许不同CPU同时修改同一缓存行,即使修改该缓存行中不同位置的数据也不允许)。该操作经常作用广播的方式来完成,例如:RequestFor Ownership(RFO)。缓存可以随时将一个非M状态的缓存行作废,或者变成
Invalid状态,而一个M状态的缓存行必须先被写回主存。一个处于
M状态的缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S状态之前被延迟执行。一个处于S状态的缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(
Invalid)。一个处于E状态的缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成
S状态。对于
M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的。而S状态可能是非一致的,如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为
E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。从上面的意义看来E状态是一种投机性的优化:如果一个
CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成Invalid状态,而修改E状态的缓存不需要使用总线事务。
总线锁会锁住总线,使得其他CPU甚至不能访问内存中其他的地址,因而效率较低
缓存锁实现之一
有些无法被缓存的数据或者跨越多个缓存行的数据依然必须使用总线锁
现代CPU的数据一致性实现 = 缓存锁(MESI ...) + 总线锁
cache line
读取缓存以cache line为基本单位,目前64bytes
位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
public class T01_CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}使用缓存行的对齐能够提高效率
public class T02_CacheLinePadding {
private static class Padding {
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}乱序问题
乱序执行的证明
public class Disorder {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (;;) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();
other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
}
}
}
}
//运行结果:第4084次 (0,0)合并写
读指令的同时可以同时执行不影响的其他指令
而写的同时可以进行合并写WCBuffer
这样CPU的执行就是乱序的
必须使用Memory Barrier来做好指令排序
volatile的底层就是这么实现的(windows是lock指令)
lock:主内存,标识变量为线程独占
unlock:主内存,解锁线程独占变量
read:主内存,读取内容到工作内存
load:工作内存,read后的值放入线程本地变量副本
use:工作内存,传值给执行引擎
assign:工作内存,执行引擎结果赋值给线程本地变量
store:工作内存,存值到主内存给write备用
write:主内存,写变量值CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。
原文链接:https://www.cnblogs.com/liushaodong/p/4777308.html
现代cpu的合并写技术对程序的影响
对于现代cpu而言,性能瓶颈则是对于内存的访问。cpu的速度往往都比主存的高至少两个数量级。因此cpu都引入了L1_cache与L2_cache,更加高端的cpu还加入了L3_cache.很显然,这个技术引起了下一个问题:
如果一个cpu在执行的时候需要访问的内存都不在cache中,cpu必须要通过内存总线到主存中取,那么在数据返回到cpu这段时间内(这段时间大致为cpu执行成百上千条指令的时间,至少两个数据量级)干什么呢? 答案是cpu会继续执行其他的符合条件的指令。比如cpu有一个指令序列 指令1 指令2 指令3 …, 在指令1时需要访问主存,在数据返回前cpu会继续后续的和指令1在逻辑关系上没有依赖的”独立指令”,cpu一般是依赖指令间的内存引用关系来判断的指令间的”独立关系”,具体细节可参见各cpu的文档。这也是导致cpu乱序执行指令的根源之一。
以上方案是cpu对于读取数据延迟所做的性能补救的办法。对于写数据则会显得更加复杂一点:
当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区。这一技术称为合并写入技术。在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区,该缓冲区大小和一个cache line大小,一般都是64字节。这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响。
当后续的写操作需要修改相同的缓存行时,这些缓冲区变得非常有趣。在将后续的写操作提交到L2缓存之前,可以进行缓冲区写合并。 这些64字节的缓冲区维护了一个64位的字段,每更新一个字节就会设置对应的位,来表示将缓冲区交换到外部缓存时哪些数据是有效的。当然,如果程序读取已被写入到该缓冲区的某些数据,那么在读取缓存数据之前会先去读取本缓冲区的。
经过上述步骤后,缓冲区的数据还是会在某个延时的时刻更新到外部的缓存(L2_cache).如果我们能在缓冲区传输到缓存之前将其尽可能填满,这样的效果就会提高各级传输总线的效率,以提高程序性能。#include <unistd.h> #include <stdio.h> #include <sys/time.h> #include <stdlib.h> #include <limits.h> static const int iterations = INT_MAX; static const int items = 1<<24; static int mask; static int arrayA[1<<24]; static int arrayB[1<<24]; static int arrayC[1<<24]; static int arrayD[1<<24]; static int arrayE[1<<24]; static int arrayF[1<<24]; static int arrayG[1<<24]; static int arrayH[1<<24]; double run_one_case_for_8() { double start_time; double end_time; struct timeval start; struct timeval end; int i = iterations; gettimeofday(&start, NULL); while(--i != 0) { int slot = i & mask; int value = i; arrayA[slot] = value; arrayB[slot] = value; arrayC[slot] = value; arrayD[slot] = value; arrayE[slot] = value; arrayF[slot] = value; arrayG[slot] = value; arrayH[slot] = value; } gettimeofday(&end, NULL); start_time = (double)start.tv_sec + (double)start.tv_usec/1000000.0; end_time = (double)end.tv_sec + (double)end.tv_usec/1000000.0; return end_time - start_time; } double run_two_case_for_4() { double start_time; double end_time; struct timeval start; struct timeval end; int i = iterations; gettimeofday(&start, NULL); while(--i != 0) { int slot = i & mask; int value = i; arrayA[slot] = value; arrayB[slot] = value; arrayC[slot] = value; arrayD[slot] = value; } i = iterations; while(--i != 0) { int slot = i & mask; int value = i; arrayG[slot] = value; arrayE[slot] = value; arrayF[slot] = value; arrayH[slot] = value; } gettimeofday(&end, NULL); start_time = (double)start.tv_sec + (double)start.tv_usec/1000000.0; end_time = (double)end.tv_sec + (double)end.tv_usec/1000000.0; return end_time - start_time; } int main() { mask = items -1; int i; printf("test begin---->\n"); for(i=0;i<3;i++) { printf(" %d, run_one_case_for_8: %lf\n", i, run_one_case_for_8()); printf(" %d, run_two_case_for_4: %lf\n", i, run_two_case_for_4()); } printf("test end"); return 0; }相信很多人会认为run_two_case_for_4 的运行时间肯定要比run_one_case_for_8的长,因为至少前者多了一遍循环的i++操作。但是事实却不是这样:下面是运行的截图:
测试环境: fedora 20 64bits, 4G DDR3内存,CPU:Inter® Core™ i7-3610QM cpu @2.30GHZ.
结果是令人吃惊的,他们的性能差距居然达到了1倍,太神奇了。
原理:上面提到的合并写存入缓冲区离cpu很近,容量为64字节,很小了,估计很贵。数量也是有限的,我这款cpu它的个数为4。个数时依赖cpu模型的,intel的cpu在同一时刻只能拿到4个。
因此,run_one_case_for_8函数中连续写入8个不同位置的内存,那么当4个数据写满了合并写缓冲时,cpu就要等待合并写缓冲区更新到L2cache中,因此cpu就被强制暂停了。然而在run_two_case_for_4函数中是每次写入4个不同位置的内存,可以很好的利用合并写缓冲区,因合并写缓冲区满到引起的cpu暂停的次数会大大减少,当然如果每次写入的内存位置数目小于4,也是一样的。虽然多了一次循环的i++操作(实际上你可能会问,i++也是会写入内存的啊,其实i这个变量保存在了寄存器上), 但是它们之间的性能差距依然非常大。
从上面的例子可以看出,这些cpu底层特性对程序员并不是透明的。程序的稍微改变会带来显著的性能提升。对于存储密集型的程序,更应当考虑到此到特性。

写操作也可以进行合并
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}如何保证特定情况下不乱序
硬件内存屏障 X86
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile的实现细节
1. 字节码层面
ACC_VOLATILE
2. JVM层面
volatile内存区的读写 都加屏障
StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
3. OS和硬件层面hsdis - HotSpot Dis Assembler
windows lock 指令实现 | MESI实现
原文链接:https://www.cnblogs.com/xrq730/p/7048693.html
前言
我们知道volatile关键字的作用是保证变量在多线程之间的可见性,它是java.util.concurrent包的核心,没有volatile就没有这么多的并发类给我们使用。
本文详细解读一下volatile关键字如何保证变量在多线程之间的可见性,在此之前,有必要讲解一下CPU缓存的相关知识,掌握这部分知识一定会让我们更好地理解volatile的原理,从而更好、更正确地地使用volatile关键字。
CPU缓存
CPU缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快得多,举个例子:
- 一次主内存的访问通常在几十到几百个时钟周期
- 一次L1高速缓存的读写只需要1~2个时钟周期
- 一次L2高速缓存的读写也只需要数十个时钟周期
这种访问速度的显著差异,导致CPU可能会花费很长时间等待数据到来或把数据写入内存。
基于此,现在CPU大多数情况下读写都不会直接访问内存(CPU都没有连接到内存的管脚),取而代之的是CPU缓存,CPU缓存是位于CPU与内存之间的临时存储器,它的容量比内存小得多但是交换速度却比内存快得多。而缓存中的数据是内存中的一小部分数据,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先从缓存中读取,从而加快读取速度。
按照读取顺序与CPU结合的紧密程度,CPU缓存可分为:
- 一级缓存:简称L1 Cache,位于CPU内核的旁边,是与CPU结合最为紧密的CPU缓存
- 二级缓存:简称L2 Cache,分内部和外部两种芯片,内部芯片二级缓存运行速度与主频相同,外部芯片二级缓存运行速度则只有主频的一半
- 三级缓存:简称L3 Cache,部分高端CPU才有
每一级缓存中所存储的数据全部都是下一级缓存中的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也相对递增。
当CPU要读取一个数据时,首先从一级缓存中查找,如果没有再从二级缓存中查找,如果还是没有再从三级缓存中或内存中查找。一般来说每级缓存的命中率大概都有80%左右,也就是说全部数据量的80%都可以在一级缓存中找到,只剩下20%的总数据量才需要从二级缓存、三级缓存或内存中读取。
使用CPU缓存带来的问题
用一张图表示一下CPU-->CPU缓存-->主内存数据读取之间的关系:
当系统运行时,CPU执行计算的过程如下:
- 程序以及数据被加载到主内存
- 指令和数据被加载到CPU缓存
- CPU执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
如果服务器是单核CPU,那么这些步骤不会有任何的问题,但是如果服务器是多核CPU,那么问题来了,以Intel Core i7处理器的高速缓存概念模型为例(图片摘自《深入理解计算机系统》):
试想下面一种情况:
- 核0读取了一个字节,根据局部性原理,它相邻的字节同样被被读入核0的缓存
- 核3做了上面同样的工作,这样核0与核3的缓存拥有同样的数据
- 核0修改了那个字节,被修改后,那个字节被写回核0的缓存,但是该信息并没有写回主存
- 核3访问该字节,由于核0并未将数据写回主存,数据不同步
为了解决这个问题,CPU制造商制定了一个规则:当一个CPU修改缓存中的字节时,服务器中其他CPU会被通知,它们的缓存将视为无效。于是,在上面的情况下,核3发现自己的缓存中数据已无效,核0将立即把自己的数据写回主存,然后核3重新读取该数据。
反汇编Java字节码,查看汇编层面对volatile关键字做了什么
有了上面的理论基础,我们可以研究volatile关键字到底是如何实现的。首先写一段简单的代码:
1 /** 2 * @author 五月的仓颉http://www.cnblogs.com/xrq730/p/7048693.html 3 */ 4 public class LazySingleton { 5 6 private static volatile LazySingleton instance = null; 7 8 public static LazySingleton getInstance() { 9 if (instance == null) { 10 instance = new LazySingleton(); 11 } 12 13 return instance; 14 } 15 16 public static void main(String[] args) { 17 LazySingleton.getInstance(); 18 } 19 20 }首先反编译一下这段代码的.class文件,看一下生成的字节码:
没有任何特别的。要知道,字节码指令,比如上图的getstatic、ifnonnull、new等,最终对应到操作系统的层面,都是转换为一条一条指令去执行,我们使用的PC机、应用服务器的CPU架构通常都是IA-32架构的,这种架构采用的指令集是CISC(复杂指令集),而汇编语言则是这种指令集的助记符。
因此,既然在字节码层面我们看不出什么端倪,那下面就看看将代码转换为汇编指令能看出什么端倪。Windows上要看到以上代码对应的汇编码不难(吐槽一句,说说不难,为了这个问题我找遍了各种资料,差点就准备安装虚拟机,在Linux系统上搞了),访问hsdis工具路径可直接下载hsdis工具,下载完毕之后解压,将hsdis-amd64.dll与hsdis-amd64.lib两个文件放在%JAVA_HOME%\jre\bin\server路径下即可,如下图:
然后跑main函数,跑main函数之前,加入如下虚拟机参数:
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*LazySingleton.getInstance运行main函数即可,代码生成的汇编指令为:
1 Java HotSpot(TM) 64-Bit Server VM warning: PrintAssembly is enabled; turning on DebugNonSafepoints to gain additional output 2 CompilerOracle: compileonly *LazySingleton.getInstance 3 Loaded disassembler from D:\JDK\jre\bin\server\hsdis-amd64.dll 4 Decoding compiled method 0x0000000002931150: 5 Code: 6 Argument 0 is unknown.RIP: 0x29312a0 Code size: 0x00000108 7 [Disassembling for mach='amd64'] 8 [Entry Point] 9 [Verified Entry Point] 10 [Constants] 11 # {method} 'getInstance' '()Lorg/xrq/test/design/singleton/LazySingleton;' in 'org/xrq/test/design/singleton/LazySingleton' 12 # [sp+0x20] (sp of caller) 13 0x00000000029312a0: mov dword ptr [rsp+0ffffffffffffa000h],eax 14 0x00000000029312a7: push rbp 15 0x00000000029312a8: sub rsp,10h ;*synchronization entry 16 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@-1 (line 13) 17 0x00000000029312ac: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')} 18 0x00000000029312b6: mov r11d,dword ptr [r10+58h] 19 ;*getstatic instance 20 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@0 (line 13) 21 0x00000000029312ba: test r11d,r11d 22 0x00000000029312bd: je 29312e0h 23 0x00000000029312bf: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')} 24 0x00000000029312c9: mov r11d,dword ptr [r10+58h] 25 0x00000000029312cd: mov rax,r11 26 0x00000000029312d0: shl rax,3h ;*getstatic instance 27 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@16 (line 17) 28 0x00000000029312d4: add rsp,10h 29 0x00000000029312d8: pop rbp 30 0x00000000029312d9: test dword ptr [330000h],eax ; {poll_return} 31 0x00000000029312df: ret 32 0x00000000029312e0: mov rax,qword ptr [r15+60h] 33 0x00000000029312e4: mov r10,rax 34 0x00000000029312e7: add r10,10h 35 0x00000000029312eb: cmp r10,qword ptr [r15+70h] 36 0x00000000029312ef: jnb 293135bh 37 0x00000000029312f1: mov qword ptr [r15+60h],r10 38 0x00000000029312f5: prefetchnta byte ptr [r10+0c0h] 39 0x00000000029312fd: mov r11d,0e07d00b2h ; {oop('org/xrq/test/design/singleton/LazySingleton')} 40 0x0000000002931303: mov r10,qword ptr [r12+r11*8+0b0h] 41 0x000000000293130b: mov qword ptr [rax],r10 42 0x000000000293130e: mov dword ptr [rax+8h],0e07d00b2h 43 ; {oop('org/xrq/test/design/singleton/LazySingleton')} 44 0x0000000002931315: mov dword ptr [rax+0ch],r12d 45 0x0000000002931319: mov rbp,rax ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14) 46 0x000000000293131c: mov rdx,rbp 47 0x000000000293131f: call 2907c60h ; OopMap{rbp=Oop off=132} 48 ;*invokespecial <init> 49 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@10 (line 14) 50 ; {optimized virtual_call} 51 0x0000000002931324: mov r10,rbp 52 0x0000000002931327: shr r10,3h 53 0x000000000293132b: mov r11,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')} 54 0x0000000002931335: mov dword ptr [r11+58h],r10d 55 0x0000000002931339: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')} 56 0x0000000002931343: shr r10,9h 57 0x0000000002931347: mov r11d,20b2000h 58 0x000000000293134d: mov byte ptr [r11+r10],r12l 59 0x0000000002931351: lock add dword ptr [rsp],0h ;*putstatic instance 60 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@13 (line 14) 61 0x0000000002931356: jmp 29312bfh 62 0x000000000293135b: mov rdx,703e80590h ; {oop('org/xrq/test/design/singleton/LazySingleton')} 63 0x0000000002931365: nop 64 0x0000000002931367: call 292fbe0h ; OopMap{off=204} 65 ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14) 66 ; {runtime_call} 67 0x000000000293136c: jmp 2931319h 68 0x000000000293136e: mov rdx,rax 69 0x0000000002931371: jmp 2931376h 70 0x0000000002931373: mov rdx,rax ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14) 71 0x0000000002931376: add rsp,10h 72 0x000000000293137a: pop rbp 73 0x000000000293137b: jmp 2932b20h ; {runtime_call} 74 [Stub Code] 75 0x0000000002931380: mov rbx,0h ; {no_reloc} 76 0x000000000293138a: jmp 293138ah ; {runtime_call} 77 [Exception Handler] 78 0x000000000293138f: jmp 292fca0h ; {runtime_call} 79 [Deopt Handler Code] 80 0x0000000002931394: call 2931399h 81 0x0000000002931399: sub qword ptr [rsp],5h 82 0x000000000293139e: jmp 2909000h ; {runtime_call} 83 0x00000000029313a3: hlt 84 0x00000000029313a4: hlt 85 0x00000000029313a5: hlt 86 0x00000000029313a6: hlt 87 0x00000000029313a7: hlt这么长长的汇编代码,可能大家不知道CPU在哪里做了手脚,没事不难,定位到59、60两行:
0x0000000002931351: lock add dword ptr [rsp],0h ;*putstatic instance ; - org.xrq.test.design.singleton.LazySingleton::getInstance@13 (line 14)之所以定位到这两行是因为这里结尾写明了line 14,line 14即volatile变量instance赋值的地方。后面的add dword ptr [rsp],0h都是正常的汇编语句,意思是将双字节的栈指针寄存器+0,这里的关键就是add前面的lock指令,后面详细分析一下lock指令的作用和为什么加上lock指令后就能保证volatile关键字的内存可见性。
lock指令做了什么
之前有说过IA-32架构,关于CPU架构的问题大家有兴趣的可以自己查询一下,这里查询一下IA-32手册关于lock指令的描述,没有IA-32手册的可以去这个地址下载IA-32手册下载地址,是个中文版本的手册。
我摘抄一下IA-32手册中关于lock指令作用的一些描述(因为lock指令的作用在手册中散落在各处,并不是在某一章或者某一节专门讲):
在修改内存操作时,使用LOCK前缀去调用加锁的读-修改-写操作,这种机制用于多处理器系统中处理器之间进行可靠的通讯,具体描述如下: (1)在Pentium和早期的IA-32处理器中,LOCK前缀会使处理器执行当前指令时产生一个LOCK#信号,这种总是引起显式总线锁定出现 (2)在Pentium4、Inter Xeon和P6系列处理器中,加锁操作是由高速缓存锁或总线锁来处理。如果内存访问有高速缓存且只影响一个单独的高速缓存行,那么操作中就会调用高速缓存锁,而系统总线和系统内存中的实际区域内不会被锁定。同时,这条总线上的其它Pentium4、Intel Xeon或者P6系列处理器就回写所有已修改的数据并使它们的高速缓存失效,以保证系统内存的一致性。如果内存访问没有高速缓存且/或它跨越了高速缓存行的边界,那么这个处理器就会产生LOCK#信号,并在锁定操作期间不会响应总线控制请求32位IA-32处理器支持对系统内存中的某个区域进行加锁的原子操作。这些操作常用来管理共享的数据结构(如信号量、段描述符、系统段或页表),两个或多个处理器可能同时会修改这些数据结构中的同一数据域或标志。处理器使用三个相互依赖的机制来实现加锁的原子操作: 1、保证原子操作 2、总线加锁,使用LOCK#信号和LOCK指令前缀 3、高速缓存相干性协议,确保对高速缓存中的数据结构执行原子操作(高速缓存锁)。这种机制存在于Pentium4、Intel Xeon和P6系列处理器中IA-32处理器提供有一个LOCK#信号,会在某些关键内存操作期间被自动激活,去锁定系统总线。当这个输出信号发出的时候,来自其他处理器或总线代理的控制请求将被阻塞。软件能够通过预先在指令前添加LOCK前缀来指定需要LOCK语义的其它场合。 在Intel386、Intel486、Pentium处理器中,明确地对指令加锁会导致LOCK#信号的产生。由硬件设计人员来保证系统硬件中LOCK#信号的可用性,以控制处理器间的内存访问。 对于Pentinum4、Intel Xeon以及P6系列处理器,如果被访问的内存区域是在处理器内部进行高速缓存的,那么通常不发出LOCK#信号;相反,加锁只应用于处理器的高速缓存。为显式地强制执行LOCK语义,软件可以在下列指令修改内存区域时使用LOCK前缀。当LOCK前缀被置于其它指令之前或者指令没有对内存进行写操作(也就是说目标操作数在寄存器中)时,会产生一个非法操作码异常(#UD)。 【1】位测试和修改指令(BTS、BTR、BTC) 【2】交换指令(XADD、CMPXCHG、CMPXCHG8B) 【3】自动假设有LOCK前缀的XCHG指令 【4】下列单操作数的算数和逻辑指令:INC、DEC、NOT、NEG 【5】下列双操作数的算数和逻辑指令:ADD、ADC、SUB、SBB、AND、OR、XOR 一个加锁的指令会保证对目标操作数所在的内存区域加锁,但是系统可能会将锁定区域解释得稍大一些。 软件应该使用相同的地址和操作数长度来访问信号量(用作处理器之间发送信号的共享内存)。例如,如果一个处理器使用一个字来访问信号量,其它处理器就不应该使用一个字节来访问这个信号量。 总线锁的完整性不收内存区域对齐的影响。加锁语义会一直持续,以满足更新整个操作数所需的总线周期个数。但是,建议加锁访问应该对齐在它们的自然边界上,以提升系统性能: 【1】任何8位访问的边界(加锁或不加锁) 【2】锁定的字访问的16位边界 【3】锁定的双字访问的32位边界 【4】锁定的四字访问的64位边界 对所有其它的内存操作和所有可见的外部事件来说,加锁的操作都是原子的。所有取指令和页表操作能够越过加锁的指令。加锁的指令可用于同步一个处理器写数据而另一个处理器读数据的操作。IA-32架构提供了几种机制用来强化或弱化内存排序模型,以处理特殊的编程情形。这些机制包括: 【1】I/O指令、加锁指令、LOCK前缀以及串行化指令等,强制在处理器上进行较强的排序 【2】SFENCE指令(在Pentium III中引入)和LFENCE指令、MFENCE指令(在Pentium4和Intel Xeon处理器中引入)提供了某些特殊类型内存操作的排序和串行化功能 ...(这里还有两条就不写了) 这些机制可以通过下面的方式使用。 总线上的内存映射设备和其它I/O设备通常对向它们缓冲区写操作的顺序很敏感,I/O指令(IN指令和OUT指令)以下面的方式对这种访问执行强写操作的排序。在执行了一条I/O指令之前,处理器等待之前的所有指令执行完毕以及所有的缓冲区都被都被写入了内存。只有取指令和页表查询能够越过I/O指令,后续指令要等到I/O指令执行完毕才开始执行。反复思考IA-32手册对lock指令作用的这几段描述,可以得出lock指令的几个作用:
- 锁总线,其它CPU对内存的读写请求都会被阻塞,直到锁释放,不过实际后来的处理器都采用锁缓存替代锁总线,因为锁总线的开销比较大,锁总线期间其他CPU没法访问内存
- lock后的写操作会回写已修改的数据,同时让其它CPU相关缓存行失效,从而重新从主存中加载最新的数据
- 不是内存屏障却能完成类似内存屏障的功能,阻止屏障两遍的指令重排序
(1)中写了由于效率问题,实际后来的处理器都采用锁缓存来替代锁总线,这种场景下多缓存的数据一致是通过缓存一致性协议来保证的,我们来看一下什么是缓存一致性协议。
缓存一致性协议
讲缓存一致性之前,先说一下缓存行的概念:
- 缓存是分段(line)的,一个段对应一块存储空间,我们称之为缓存行,它是CPU缓存中可分配的最小存储单元,大小32字节、64字节、128字节不等,这与CPU架构有关,通常来说是64字节。当CPU看到一条读取内存的指令时,它会把内存地址传递给一级数据缓存,一级数据缓存会检查它是否有这个内存地址对应的缓存段,如果没有就把整个缓存段从内存(或更高一级的缓存)中加载进来。注意,这里说的是一次加载整个缓存段,这就是上面提过的局部性原理
上面说了,LOCK#会锁总线,实际上这不现实,因为锁总线效率太低了。因此最好能做到:使用多组缓存,但是它们的行为看起来只有一组缓存那样。缓存一致性协议就是为了做到这一点而设计的,就像名称所暗示的那样,这类协议就是要使多组缓存的内容保持一致。
缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于"嗅探(snooping)"协议,它的基本思想是:
所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个CPU缓存可以读写内存)。 CPU缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其它处理器马上知道这块内存在它们的缓存段中已失效。MESI协议是当前最主流的缓存一致性协议,在MESI协议中,每个缓存行有4个状态,可用2个bit表示,它们分别是:
这里的I、S和M状态已经有了对应的概念:失效/未载入、干净以及脏的缓存段。所以这里新的知识点只有E状态,代表独占式访问,这个状态解决了"在我们开始修改某块内存之前,我们需要告诉其它处理器"这一问题:只有当缓存行处于E或者M状态时,处理器才能去写它,也就是说只有在这两种状态下,处理器是独占这个缓存行的。当处理器想写某个缓存行时,如果它没有独占权,它必须先发送一条"我要独占权"的请求给总线,这会通知其它处理器把它们拥有的同一缓存段的拷贝失效(如果有)。只有在获得独占权后,处理器才能开始修改数据----并且此时这个处理器知道,这个缓存行只有一份拷贝,在我自己的缓存里,所以不会有任何冲突。
反之,如果有其它处理器想读取这个缓存行(马上能知道,因为一直在嗅探总线),独占或已修改的缓存行必须先回到"共享"状态。如果是已修改的缓存行,那么还要先把内容回写到内存中。
由lock指令回看volatile变量读写
相信有了上面对于lock的解释,volatile关键字的实现原理应该是一目了然了。首先看一张图:
工作内存Work Memory其实就是对CPU寄存器和高速缓存的抽象,或者说每个线程的工作内存也可以简单理解为CPU寄存器和高速缓存。
那么当写两条线程Thread-A与Threab-B同时操作主存中的一个volatile变量i时,Thread-A写了变量i,那么:
- Thread-A发出LOCK#指令
- 发出的LOCK#指令锁总线(或锁缓存行),同时让Thread-B高速缓存中的缓存行内容失效
- Thread-A向主存回写最新修改的i
Thread-B读取变量i,那么:
- Thread-B发现对应地址的缓存行被锁了,等待锁的释放,缓存一致性协议会保证它读取到最新的值
由此可以看出,volatile关键字的读和普通变量的读取相比基本没差别,差别主要还是在变量的写操作上。
后记
之前对于volatile关键字的作用我个人还有一些会混淆的误区,在深入理解volatile关键字的作用之后,感觉对volatile的理解深了许多。相信看到文章这里的你,只要肯想、肯研究,一定会和我一样有恍然大悟、茅塞顿开的感觉^_^






synchronized实现细节
1. 字节码层面
ACC_SYNCHRONIZED
monitorenter monitorexit
2. JVM层面
C C++ 调用了操作系统提供的同步机制
3. OS和硬件层面
X86 : lock cmpxchg / xxx原文链接:Java使用字节码和汇编语言同步分析volatile,synchronized的底层实现_深度Java的博客-CSDN博客
查看汇编语言汇编码
说要看汇编还是很有必要的,因为有些地方比如加锁其实还是通过汇编实现的,只看字节码不能看出底层实现。其实就是利用使用hsdis与jitwatch查看JIT后的汇编码。
1.首先下载hsids
要查看JIT生成的汇编代码,要先装一个反汇编器:hsdis。从名字来看,即HotSpot disassembler。实际就是一个动态链接库。网络上有已经编绎好的文件,直接下载即可。
https://github.com/jkubrynski/profiling/tree/master/bin
下载这2个文件拷贝到jre1.8.0_144\bin\server下:
通过以下命令可以测试是否安装成功:
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -version
这说明安装完成。2.安装JITWatch
JITWatch是分析展现JIT日志等的图形界面工具。https://github.com/AdoptOpenJDK/jitwatch
下载好,本地解压开,然后在IDEA里导入项目然后编译之!
首先要写一个足够复杂的类,让JIT编绎器认为它需要进行优化,不然产生的日志可能没什么内容。
启动launchUI.bat
左上方有一个sanbox,点击会在当前目录下生成一个sanbox文件夹,里面存放着sanbox这个示例相关的代码,你也可以直接这里写代码。
public class Test {
public volatile long sum = 0;
public int add(int a, int b) {
int temp = a + b;
sum += temp;
return temp;
}
public static void main(String[] args) {
Test test = new Test();
int sum = 0;
for (int i = 0; i < 1000000; i++) {
sum = test.add(sum, 1);
}
System.out.println("Sum:" + sum);
System.out.println("Test.sum:" + test.sum);
}
}
javac Test.java
java -server -XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=E:\work\tmp\Test.log Test
在tmp目录会生成对应文件,然后OpenLog打开,再Config好:点“Start”解析:
点击方法,弹出的页面就可以 源码,字节码,汇编码 同步了:
可以看到实际上底层还是通过lock来实现,关于lock可以参考intel处理器指令。
另外这一片帖子也可以参考《volatile,你了解多少》,作者多少有一点靠蒙的分析,这不科学,不过我觉得还是不如汇编来的彻底。
import static java.lang.Thread.sleep;
public class TestAdd {
private static int count;
public static void main(String[] args) {
for (int i = 0; i < 10000; i++) {
new Thread() {
public void run() {
//System.out.println(">>>:");
synchronized(TestAdd.class){
//System.out.println(">>>>:");
count++;
//System.out.println("<<<<:");
}
}
}.start();
}
try {
sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count:" + count);
}
}CMPXCHG
含义: 比较并交换指令
用法:目的操作数和累加操作数(AH、AL、EAX)进行比较,如果相等(ZF=1),则将源操作数复制到目的操作数中,否则将目的操作数复制到累加器中。
干我们这行,啥时候懈怠,就意味着长进的停止,长进的停止就意味着被淘汰,只能往前冲,直到凤凰涅槃的一天!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











