







前言:对于一个数据库来说,想学会它的底层原理,就一定要熟悉它的读写过程,因为数据库最常见的操作就是读和写前面我们已经把数据模型和架构各自击破,本篇将通过读写流程将学过的知识串一遍,做到融汇贯通
本篇目标:
1.掌握读写流程的主要过程2.思考读写过程中所涉及原理与细节
01 读数据流程先来看下读取数据的流程: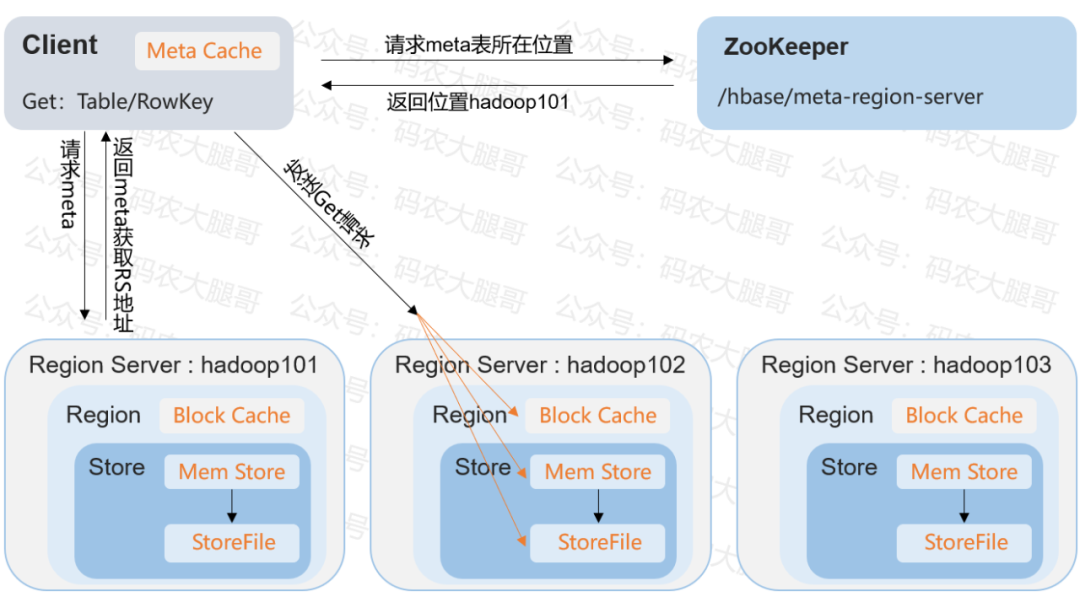 HBase读流程
HBase读流程
01 读数据流程先来看下读取数据的流程:
HBase读流程
我把读流程划分为2大步7小步:
1.获取目标Region位置1)Client访问ZooKeeper,获取元数据表hbase:meta位置信息(哪个Region Server)
2) 访问目标RS,读取hbase:meta表,根据读请求的 table/rowkwy ,查询目标数据位于哪个RS中的哪个region 3) 将 table的region 信息< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1543
1543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









