






工作原因,要探索一下多模态大模型在泛物体检测领域的使用效果,这里从不同角度整理了一些具有代表性的多模态大模型,后期工作会从里面挑选一些进行部署验证。
一 介绍
泛物体检测是开放集任务,相比于 open set,需要知道不在训练集类别中的新预测物体类别。这类模型接入文本作为一个模态输入,输出文本描述物的位置坐标和置信度。
目前实现泛物体检测的方案有两类:
- 通过文本提示(Text Prompt)或自然语言描述引导物体检测,支持开放词汇(Open-Vocabulary)检测。
- 结合大语言模型(LLM)的语义理解能力,实现零样本(Zero-Shot)检测。
第一类泛物体检测以clip系列模型为主,部分有代表性的模型数据如下:
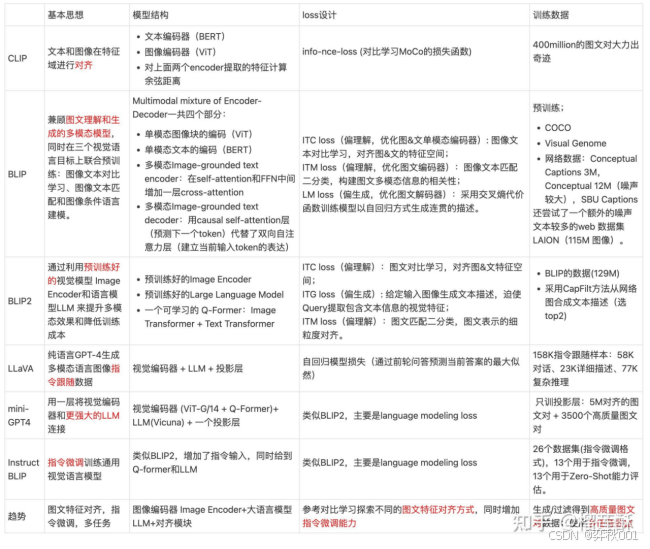
二 CLIP系列多模态模型
2.1 BLIP2
在第一章提供的表格中,目前效果表现较好的是BLIP2:
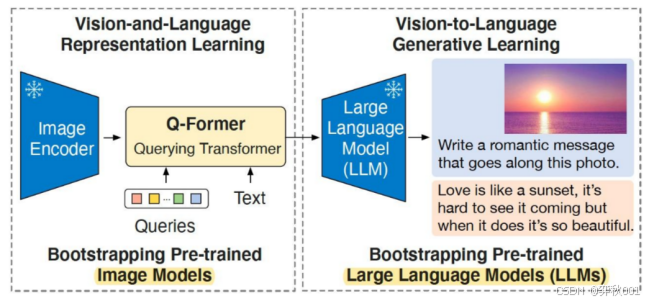
该模型由预训练的Image Encoder,预训练的Large Language Model,和一个可学习的 Q-Former 等模块组成。
Image Encoder:从输入图片中提取视觉特征,尝试了两种网络结构,CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14(去掉了最后一层)。
Large Language Model:大语言模型进行文本生成,尝试了接入decoder-based LLM 和 encoder-decoder-based LLM两种结构。
Q-Former:弥补视觉和语言两种模态的modality gap,可以理解为固定图像编码器和固定LLM之间的信息枢纽,选取最有用的视觉特征给LLM来生成文本。
2.2 LLaVA
第一章表格中LLaVA架构,似乎各项能力都不如BLIP2和InstructBLIP,不过由于结构简单,LLaVA 1.5等后续版本表现效果也好,证明这种也有较高的上限,这也是一款可探索的多模态模型。该架构主要结构如下:
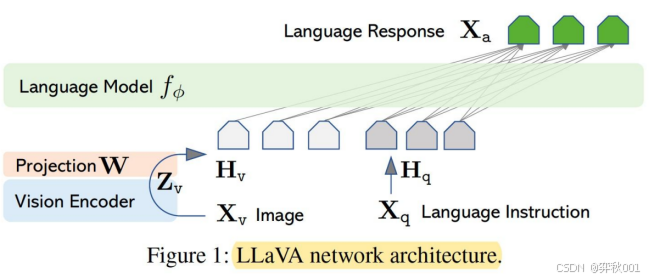
使用视觉编码器CLIP ViT-L/14+语言解码器LLaMA构成多模态大模型,然后使用生成的数据进行指令微调。输入图片X经过与训练好的视觉编码器的到图片特征Z,图片特征Z经过一个映射矩阵W转化为视觉Token H,这样Vison Token H_v与Language Token H_q指令就都在同一个特征空间,拼接后一起输入大模型。
2.3 yolo-world
从检测实时性考虑,由腾讯发布的yolo-world检测速度最快的泛物体检测模型。是基于YOLO框架的多模态扩展,结合CLIP嵌入实现实时开放词汇检测。
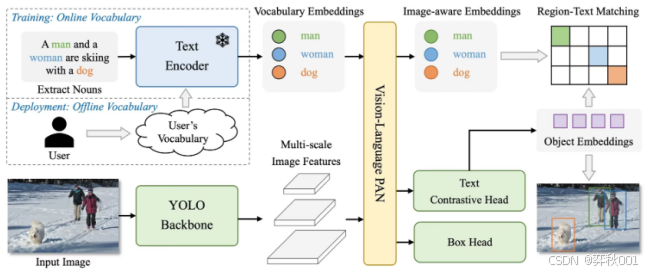
该模型最特点是使用了Re-parameterizable Vision-Language PAN(RepVL-PAN)结构,通过多尺度图像特征建立特征金字塔,通过文本引导CSPLayer和图像池注意,进一步增强图像特征和文本特征之间的交互。
YOLO-World 与传统的开放词汇检测模型相比,具有多项优势:
实时性能:它利用 CNN 的计算速度提供快速、高效的检测。
高效率和低资源需求: YOLO-World 在保持高性能的同时,大幅降低了计算和资源需求。
自定义提示:该模型支持动态提示设置,允许用户指定自定义检测类别,而无需重新培训。
卓越的基准测试:在标准基准测试中,它的速度和效率均优于 MDETR 和 GLIP 等其他开放词汇检测器。
2.4 GroundingDINO
再有表现比较好的是结合DINO(自监督检测)和CLIP的图文对齐能力,支持文本引导的开放词汇检测。代表性模型是GroundingDINO,最新版本已经到GroundingDINO1.6,不过并没有模型,目前可用的仍是GroundingDINO。
它是基于Transformer的架构,类似于语言模型,使得处理图像和语言数据更加容易。例如,由于所有的图像和语言分支都是基于Transformer构建的,可以轻松地在整个流程中融合跨模态特征。作为类似DETR的模型,DINO可以进行端到端的优化,而无需使用任何硬编码的模块,比如NMS,这极大简化了整体定位模型的设计。
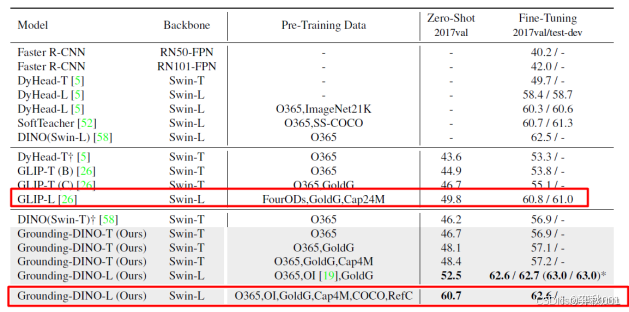
在coco数据集上,zero-shot与fine-tuning的效果比GLIP要好。
三 视觉-语言多模态大模型
3.1 qwen2.5 -vl
使用qwen2.5-vl这样的视觉-语言多模态大模型,将目标检测融入生成式框架,实现多模态交互下的灵活检测。
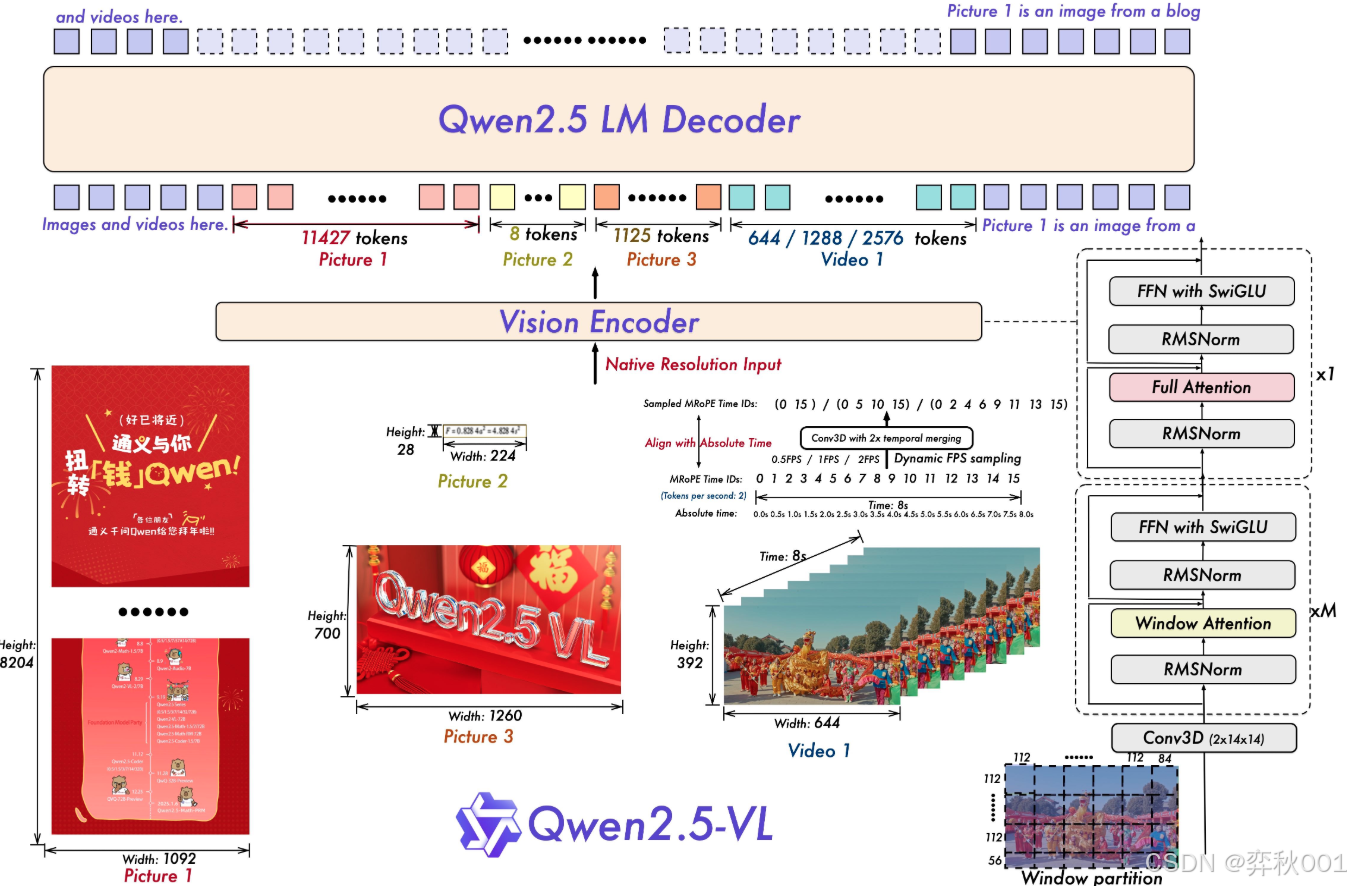
模型原理如下:
LLM:采用 Qwen2.5 LLM 的预训练权重进行初始化,并将 1D RoPE 替换为多模态旋转位置嵌入(MRoPE)。
视觉编码器:重新设计了 Vision Transformer 架构,整合了 2D-RoPE 和窗口注意力机制,以支持原生输入分辨率,并提升计算效率。
Vision-Language Merger:使用基于 MLP 的方法压缩图像特征序列,将空间相邻的四个 patch 特征组合,并通过两层 MLP 投影到与 LLM 文本嵌入对齐的维度。
快速高效的视觉编码器:在大多数层中引入窗口注意力机制,确保计算成本与 patch 数量呈线性关系。采用 2D 旋转位置嵌入(RoPE)来有效捕捉 2D 空间中的空间关系。对于视频数据,将连续两帧分组,减少输入到语言模型的 tokens 数量。使用 RMSNorm 进行归一化,并采用 SwiGLU 作为激活函数,以提高计算效率并增强视觉与语言组件之间的兼容性。
通过文本-图片语义对齐能力,将检测任务转化为序列生成问题:模型输出结构化的文本,包含物体类别和坐标(如“狗在位置[x1,y1,x2,y2]”)。除了qwen-vl,其他比较有代表性模型还有MiniGPT-4,GPT-4V。
3.2 Florence-2
Florence-2是微软发表于2024年6月开源的个基础视觉语言模型,它的定位类似阿里开源的OFA,支持多种类型的任务,包括: 看图说话、目标检测、OCR 等。可以通过调整prompt实现检测任务。
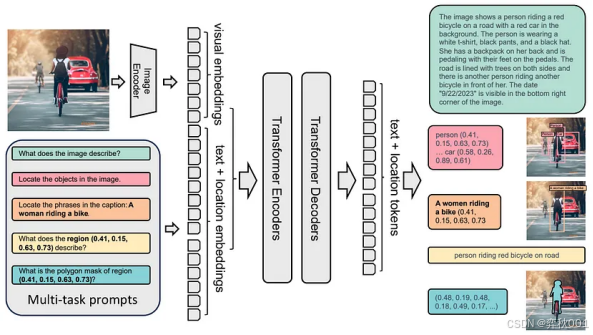
Florence-2 使用标准编码器-解码器转换器架构构建。以下是该过程的工作原理:
① 输入图像由 DaViT 视觉编码器嵌入。
② 文本提示使用 BART嵌入,利用扩展的标记器和字嵌入层。
③ 视觉和文本嵌入都是连接的。
④ 这些串联嵌入由基于转换器的多模态编码器-解码器处理以生成响应。
3.3 Align-DS-V
2025年2月6号由北京大学联合香港科技大学发布了多模态版DeepSeek-R1——Align-DS-V是目前最新的多模态大模型,使用模态框架Align-Anything,将原本专注于纯文本模态的Deepseek R1系列模型拓展至图文模态。

在多个维度的评测数据上好的与gpt-4o相匹配的性能:
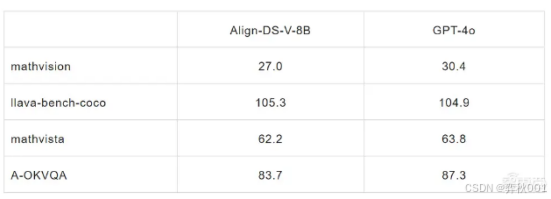
Align-DS-V并非专为目标检测开发,但可以通过修改prompt实现检测任务。
四 总结
本文从多模态clip系列模型和多模态语言大模型两个方向入手,各挑选一些有代表性的开源模型,简要描述工作原理与适配成泛物体检测的使用方法。目前多模态相关的开源模型有几十种, 不可能全部测试一遍。在此,可以挑选一些公认的效果较好的模型构建demo:
1.clip系列的多模态方案有GLIPV2,GroundingDINO可选。
2.从检测实时性考虑有yolo-world。
3.从任务全面性分析可选择Florence-2。
4.从对中文的支持度上可选qwen2.5-vl, 这是2025年1月28号发布的模型,效果也有极大提升。
5.Align-DS-V, Janus-Pro-7B是最新发布的模型,以deepseek-R1为语言模型基座,是目前热门的大模型,也是一个泛物体检测领域值得探索的方案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









