







伙伴系统算法采用页框作为基本内存区,这适合于对大块内存的请求,但我们如何处理对小内存区的请求呢,比如说几十或几百个字节?显然,如果为了存放很少的字节而给它分配一个整页框,这显然是一种浪费。取而代之的正确方法就是引入一种新的数据結构来描述在同一页框中如何分配小内存区。但这样也引出了一个新的问题,即所谓的内碎片( internal fragmentation)。内碎片的产生主要是由于请求内存的大小与分配给它的大小不匹配而造成的。一种典型的解决方法(早期 Linux版本采用)就是提供按几何分布的内存区大小,换句话说,内存区大小取决于2的幂而不取决于所存放的数据大小。这样,不管请求内存的大小是多少,我们都可保证内碎片小于50%。为此,内核建立了13个按几何分布的空闲内存区链表,它们的大小从32到131072字节。伙伴系统的调用既为了获得存放新内存区所需的额外页框,也为了释放不再包含内存区的页框。用一个动态链表来记录每个页框所包含的空闲内存区。
1.slab分配器
slab分配器把对象分组放进高速缓存。每个高速缓存都是同种类型对象的一种储备。包含高速缓存的主内存区被划分为多个slab,每个slab由一个或多个连续的页框组成,这些页框中既包含已分配的对象,也包含空闲的对象。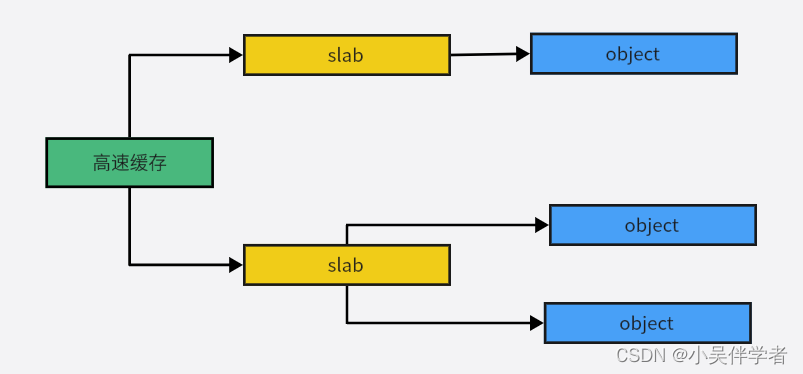
1.1 高速缓存描述符kmem_cache
struct kmem_cache {
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;//从本地高速缓存交换的对象的数量
unsigned int limit; //本地高速缓存中空闲对象的数量
unsigned int shared; //是否存在共享CPU高速缓存
unsigned int size; //对象长度+填充字节
struct reciprocal_value reciprocal_buffer_size; //倒数,加快计算
/* 2) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */ /*高速缓存永久性的标志,当前只CFLGS_OFF_SLAB*/
unsigned int num; /* # of objs per slab */ /*封装在一个单独的slab中的对象数目*/
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;/* 每个 slab 所使用的页框数量 order */
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size;
int align;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
struct memcg_cache_params memcg_params;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial;//部分分配的slab /* partial list first, better asm code */
struct list_head slabs_full;//已经完全分配的 slab
struct list_head slabs_free;//空slab,或者没有对象被分配
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};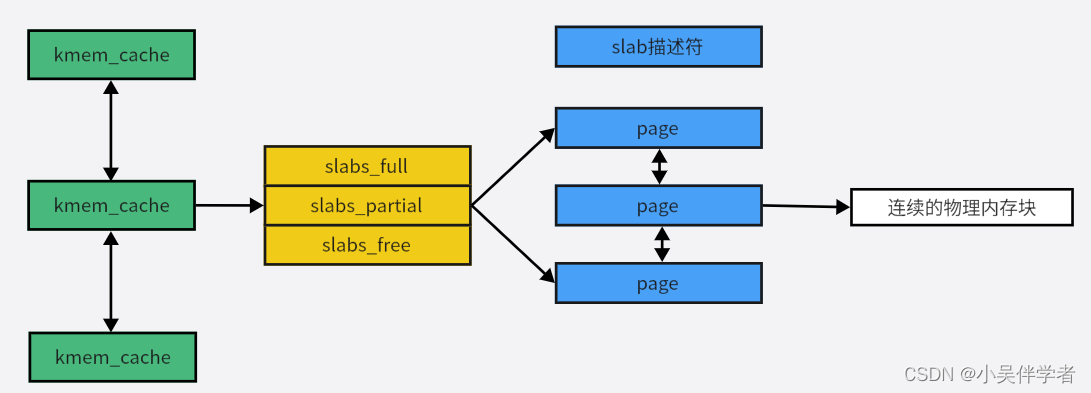
用 struct kmem_cache 结构描述的一段内存就称作一个 slab 缓存池。一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个 slab 。在初始时,所有牛奶都是新的,都存在 slabs_free 链表中。分配内存的时候,就相当于从牛奶箱中拿一瓶牛奶,若把一瓶牛奶喝完,该牛奶就会被加入到 slabs_full 中不能再分配;若只喝了一半就放回到 slabs_partial 中。牛奶可能会喝完(不考虑 slab 内存 free 的情况,因为自己不能生产牛奶(捂脸)),当箱子空的时候,你就需要去超市再买一箱回来。超市就相当于buddy 分配器。实际上操作系统启动创建kmem_cache完成后,这三个链表都为空,只有在申请对象时发现没有可用的 slab 时才会创建一个新的SLAB,并加入到这三个链表中的一个中。也就是说kmem_cache中的SLAB数量是动态变化的,当SLAB数量太多时,kmem_cache会将一些SLAB释放回页框分配器中。
1.2普通和专用高速缓存
高速缓存被分为两种类型:普通和专用。普通高速缓存只由slab分配器用于自己的目的,而专用高速缓存由内核的其余部分使用。
在系统初始化期间调用 kmem_cache_init()和 kmem_cache_ sizes_init()来建立普通高速缓存专用高速缓存是由 kmem_cache_ create()函数创建的。这个函数首先根据参数确定处理新高速缓存的最佳方法(例如,是在slab的内部还是外部包含slab描述符)。然后它从 cache_ cache普通高速缓存中为新的高速缓存分配一个高速缓存描述符,并把这个描述符插入到高速缓存描述符的 cache _chain链表中(当获得了用于保护链表避免被同时访问的 cache_chain_sem信号量后,插入操作完成)。
void __init kmem_cache_init(void)
{
int i;
BUILD_BUG_ON(sizeof(((struct page *)NULL)->lru) <
sizeof(struct rcu_head));
kmem_cache = &kmem_cache_boot;
if (num_possible_nodes() == 1)
use_alien_caches = 0;
// NUM_INIT_LISTS 为 2 * 系统内的节点数量
// 初始化 kmem_cache_node 结构体
for (i = 0; i < NUM_INIT_LISTS; i++)
kmem_cache_node_init(&init_kmem_cache_node[i]);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory if
* not overridden on the command line.
*/
if (!slab_max_order_set && totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_max_order = SLAB_MAX_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the kmem_cache cache: it contains the struct
* kmem_cache structures of all caches, except kmem_cache itself:
* kmem_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_cache_node structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for kmem_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_cache_node for kmem_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
/* 1) create the kmem_cache */
/*
* struct kmem_cache size depends on nr_node_ids & nr_cpu_ids
*/
// 完成第一个kmem cache实例kmem_cache的初始化
// 第一个kmem cache实例用于为创建其他kmem cache实例分配空间
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
// kmem cache实例加入slab_caches链表
list_add(&kmem_cache->list, &slab_caches);
slab_state = PARTIAL;
/*
* Initialize the caches that provide memory for the kmem_cache_node
* structures first. Without this, further allocations will bug.
*/
kmalloc_caches[INDEX_NODE] = create_kmalloc_cache("kmalloc-node",
kmalloc_size(INDEX_NODE), ARCH_KMALLOC_FLAGS);
slab_state = PARTIAL_NODE;
setup_kmalloc_cache_index_table();
slab_early_init = 0;
/* 5) Replace the bootstrap kmem_cache_node */
{
int nid;
for_each_online_node(nid) {
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
init_list(kmalloc_caches[INDEX_NODE],
&init_kmem_cache_node[SIZE_NODE + nid], nid);
}
}
create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}1.3 slab分配器与分区页框分配器的接口
当slab分配器创建新的sab时,它依靠分区页框分配器来获得一组连续的空困页框。为了达到此目的,它调用 kmem_getpages()函数,在UMA系统上该函数本质上等价于如下代码片段:
static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags,
int nodeid)
{
struct page *page;
int nr_pages;
flags |= cachep->allocflags;
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
flags |= __GFP_RECLAIMABLE;
if (memcg_charge_slab(cachep, flags, cachep->gfporder))
return NULL;
page = __alloc_pages_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);
if (!page) {
memcg_uncharge_slab(cachep, cachep->gfporder);
slab_out_of_memory(cachep, flags, nodeid);
return NULL;
}
/* Record if ALLOC_NO_WATERMARKS was set when allocating the slab */
if (page_is_pfmemalloc(page))
pfmemalloc_active = true;
nr_pages = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
add_zone_page_state(page_zone(page),
NR_SLAB_RECLAIMABLE, nr_pages);
else
add_zone_page_state(page_zone(page),
NR_SLAB_UNRECLAIMABLE, nr_pages);
__SetPageSlab(page);
if (page_is_pfmemalloc(page))
SetPageSlabPfmemalloc(page);
if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {
kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);
if (cachep->ctor)
kmemcheck_mark_uninitialized_pages(page, nr_pages);
else
kmemcheck_mark_unallocated_pages(page, nr_pages);
}
return page;
}可以通过调用kmem_freepages()函数来释放分配给slab的页框:
static void kmem_freepages(struct kmem_cache *cachep, struct page *page)
{
const unsigned long nr_freed = (1 << cachep->gfporder);
kmemcheck_free_shadow(page, cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
sub_zone_page_state(page_zone(page),
NR_SLAB_RECLAIMABLE, nr_freed);
else
sub_zone_page_state(page_zone(page),
NR_SLAB_UNRECLAIMABLE, nr_freed);
BUG_ON(!PageSlab(page));
__ClearPageSlabPfmemalloc(page);
__ClearPageSlab(page);
page_mapcount_reset(page);
page->mapping = NULL;
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += nr_freed;
__free_pages(page, cachep->gfporder);
memcg_uncharge_slab(cachep, cachep->gfporder);
}1.4 给高速缓存分配slab
一个新创建的高速缓存没有包含任何slab,因此也没有空闲的对象,只有满足以下两个条件,才给高速缓存分配slab:
(1)已经发出一个分配新对象的请求;
(2)高速缓存不包含任何空闲对象;
当这些情况发生时,slab分配器通过调用 cache_grow()函数给高速缓存分配一个新的slab。而这个函数调用 kmem_getpages()从分区页框分配器获得一组页框来存放一个单独的slab,然后又调用alloc_slabmgmt()获得一个新的slab描述符。如果高速缓存描述符的CFLGS_ OFF_SLAB标志置位,则从髙速缓存描述符的 slabp_cache字段指向的普通高速缓存中分配这个新的slab描述符;否则,从slab的第一个页框中分配这个slab描述符。
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, struct page *page)
{
void *freelist;
size_t offset;
gfp_t local_flags;
struct kmem_cache_node *n;
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
if (unlikely(flags & GFP_SLAB_BUG_MASK)) {
pr_emerg("gfp: %u\n", flags & GFP_SLAB_BUG_MASK);
BUG();
}
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
/* Take the node list lock to change the colour_next on this node */
check_irq_off();
n = get_node(cachep, nodeid);
spin_lock(&n->list_lock);
/* Get colour for the slab, and cal the next value. */
offset = n->colour_next;
n->colour_next++;
if (n->colour_next >= cachep->colour)
n->colour_next = 0;
spin_unlock(&n->list_lock);
offset *= cachep->colour_off;
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
if (!page) //获取一组页框
page = kmem_getpages(cachep, local_flags, nodeid);
if (!page)
goto failed;
/* Get slab management. */ //获取一个slab
freelist = alloc_slabmgmt(cachep, page, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
if (!freelist)
goto opps1;
slab_map_pages(cachep, page, freelist);
cache_init_objs(cachep, page);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&n->list_lock);
/* Make slab active. */
list_add_tail(&page->lru, &(n->slabs_free));
STATS_INC_GROWN(cachep);
n->free_objects += cachep->num;
spin_unlock(&n->list_lock);
return 1;
opps1:
kmem_freepages(cachep, page);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
static void *alloc_slabmgmt(struct kmem_cache *cachep,
struct page *page, int colour_off,
gfp_t local_flags, int nodeid)
{
void *freelist;
void *addr = page_address(page);
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
freelist = kmem_cache_alloc_node(cachep->freelist_cache,
local_flags, nodeid);
if (!freelist)
return NULL;
} else {
freelist = addr + colour_off;
colour_off += cachep->freelist_size;
}
page->active = 0;
page->s_mem = addr + colour_off;
return freelist;
}
#define OFF_SLAB(x) ((x)->flags & CFLGS_OFF_SLAB)从高速缓存中释放slab,需要满足两个条件:
(1)slab高速缓存中有太多的空闲对象;
(2)被周期性的定时器函数确定是否有完全未使用的slab能被释放。
调用slab_destroy()函数撤销一个slab,并释放相应的页框到分区页框分配器:
static void slab_destroy(struct kmem_cache *cachep, struct page *page)
{
void *freelist;
freelist = page->freelist;
slab_destroy_debugcheck(cachep, page);
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
struct rcu_head *head;
/*
* RCU free overloads the RCU head over the LRU.
* slab_page has been overloeaded over the LRU,
* however it is not used from now on so that
* we can use it safely.
*/
head = (void *)&page->rcu_head;
call_rcu(head, kmem_rcu_free);
} else {
kmem_freepages(cachep, page);
}
/*
* From now on, we don't use freelist
* although actual page can be freed in rcu context
*/
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->freelist_cache, freelist);
}
static void slab_destroy_debugcheck(struct kmem_cache *cachep,
struct page *page)
{
int i;
for (i = 0; i < cachep->num; i++) {
void *objp = index_to_obj(cachep, page, i);
if (cachep->flags & SLAB_POISON) {
#ifdef CONFIG_DEBUG_PAGEALLOC
if (cachep->size % PAGE_SIZE == 0 &&
OFF_SLAB(cachep))
kernel_map_pages(virt_to_page(objp),
cachep->size / PAGE_SIZE, 1);
else
check_poison_obj(cachep, objp);
#else
check_poison_obj(cachep, objp);
#endif
}
if (cachep->flags & SLAB_RED_ZONE) {
if (*dbg_redzone1(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "start of a freed object "
"was overwritten");
if (*dbg_redzone2(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "end of a freed object "
"was overwritten");
}
}
}对象描述符:
struct page与对象的关系:
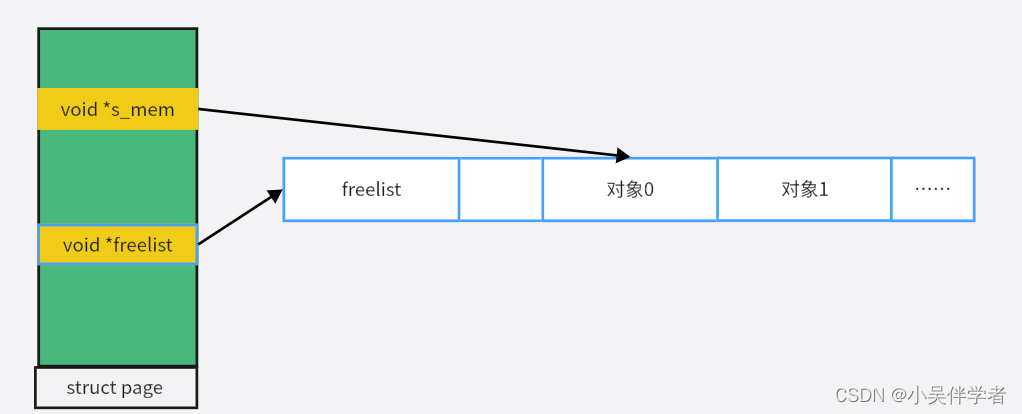
2. slab缓存建立过程
/* internal cache of cache description objs */
static struct kmem_cache kmem_cache_boot = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};//第一个kmem_cache示例void __init kmem_cache_init(void)
{
int i;
BUILD_BUG_ON(sizeof(((struct page *)NULL)->lru) <
sizeof(struct rcu_head));
kmem_cache = &kmem_cache_boot;
if (num_possible_nodes() == 1)
use_alien_caches = 0;
// NUM_INIT_LISTS 为 2 * 系统内的节点数量
// 初始化 kmem_cache_node 结构体
for (i = 0; i < NUM_INIT_LISTS; i++)
kmem_cache_node_init(&init_kmem_cache_node[i]);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory if
* not overridden on the command line.
*/
if (!slab_max_order_set && totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_max_order = SLAB_MAX_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the kmem_cache cache: it contains the struct
* kmem_cache structures of all caches, except kmem_cache itself:
* kmem_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_cache_node structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for kmem_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_cache_node for kmem_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
/* 1) create the kmem_cache */
/*
* struct kmem_cache size depends on nr_node_ids & nr_cpu_ids
*/
// 完成第一个kmem cache实例kmem_cache的初始化
// 第一个kmem cache实例用于为创建其他kmem cache实例分配空间
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
// kmem cache实例加入slab_caches链表
list_add(&kmem_cache->list, &slab_caches);
slab_state = PARTIAL;
/*
* Initialize the caches that provide memory for the kmem_cache_node
* structures first. Without this, further allocations will bug.
*/
kmalloc_caches[INDEX_NODE] = create_kmalloc_cache("kmalloc-node",
kmalloc_size(INDEX_NODE), ARCH_KMALLOC_FLAGS);
slab_state = PARTIAL_NODE;
setup_kmalloc_cache_index_table();
slab_early_init = 0;
/* 5) Replace the bootstrap kmem_cache_node */
{
int nid;
for_each_online_node(nid) {
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
init_list(kmalloc_caches[INDEX_NODE],
&init_kmem_cache_node[SIZE_NODE + nid], nid);
}
}
create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}slab_cache 作为链接所有 kmem_cache 的链表头,使用宏LIST_HEAD(slab_caches)定义在文件mm/slab_common.c中;在 kmem_cache 初始化后,都将通过 list_add 将其添加到链表中。create_kmalloc_cache()函数首先调用函数kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);从 kmem_cache 中申请一个 slab 用来保存记录 struct kmem_cache_node实例的 kmem_cache。之后再调用create_boot_cache()函数对从 kmem_cacha slab 中申请来的 kmem_cache 进行初始化,并再添加到 slab_caches 链表中。
struct kmem_cache *__init create_kmalloc_cache(const char *name, size_t size,
unsigned long flags)
{
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
if (!s)
panic("Out of memory when creating slab %s\n", name);
create_boot_cache(s, name, size, flags);
list_add(&s->list, &slab_caches);
s->refcount = 1;
return s;
}
专用的 slab 的初始化分布在不同子系统所在的源文件中。以 vm_area_struct 为例,其初始化在__init proc_caches_init(void) 函数(定义在文件kernel/fork.c中)中被调用,代码如下所示。
void __init proc_caches_init(void)
{
sighand_cachep = kmem_cache_create("sighand_cache",
sizeof(struct sighand_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_DESTROY_BY_RCU|
SLAB_NOTRACK, sighand_ctor);
signal_cachep = kmem_cache_create("signal_cache",
sizeof(struct signal_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
files_cachep = kmem_cache_create("files_cache",
sizeof(struct files_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
fs_cachep = kmem_cache_create("fs_cache",
sizeof(struct fs_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
/*
* FIXME! The "sizeof(struct mm_struct)" currently includes the
* whole struct cpumask for the OFFSTACK case. We could change
* this to *only* allocate as much of it as required by the
* maximum number of CPU's we can ever have. The cpumask_allocation
* is at the end of the structure, exactly for that reason.
*/
mm_cachep = kmem_cache_create("mm_struct",
sizeof(struct mm_struct), ARCH_MIN_MMSTRUCT_ALIGN,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
vm_area_cachep = KMEM_CACHE(vm_area_struct, SLAB_PANIC);
mmap_init();
nsproxy_cache_init();
}
slab缓存分配函数调用过程: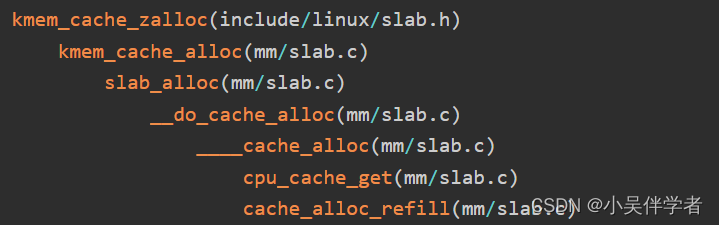
____cache_alloc()函数实现如下,slab 分配器首先会从 array_cache中查找是否存在可用 obj (下面会详细介绍 struct array_cache),若有直接分配,若无则调用 cache_alloc_refill()函数尝试从 3 个 slabs_(free/partial/full)中寻找可用的内存,并将其填充到 array_cache 中,再次进行分配。
struct array_cache {
unsigned int avail; //表示当前可用对象的数量
unsigned int limit; //可拥有的最大对象数
unsigned int batchcount; //要从 slab_list 转移进本地高速缓存对象的数量,或从本地高速缓存中转移出去的 obj 数量
unsigned int touched; //是否在收缩后访问过
void *entry[]; /* 伪数组,保存释放的对象指针
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*
* Entries should not be directly dereferenced as
* entries belonging to slabs marked pfmemalloc will
* have the lower bits set SLAB_OBJ_PFMEMALLOC
*/
};static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
bool force_refill = false;
check_irq_off();
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
ac->touched = 1;
objp = ac_get_obj(cachep, ac, flags, false);
/*
* Allow for the possibility all avail objects are not allowed
* by the current flags
*/
if (objp) {
STATS_INC_ALLOCHIT(cachep);
goto out;
}
force_refill = true;
}
STATS_INC_ALLOCMISS(cachep);
//尝试从 3 个 slabs_(free/partial/full)中寻找可用的内存,并将其填充到 array_cache 中,再次进行分配
objp = cache_alloc_refill(cachep, flags, force_refill);
/*
* the 'ac' may be updated by cache_alloc_refill(),
* and kmemleak_erase() requires its correct value.
*/
ac = cpu_cache_get(cachep);
out:
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
if (objp)
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags,
bool force_refill)
{
int batchcount;
struct kmem_cache_node *n;
struct array_cache *ac;
int node;
check_irq_off();
node = numa_mem_id();
if (unlikely(force_refill))
goto force_grow;
retry:
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
n = get_node(cachep, node);
BUG_ON(ac->avail > 0 || !n);
spin_lock(&n->list_lock);
/* See if we can refill from the shared array */
if (n->shared && transfer_objects(ac, n->shared, batchcount)) {
n->shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
struct list_head *entry;
struct page *page;
/* Get slab alloc is to come from. */
entry = n->slabs_partial.next;
if (entry == &n->slabs_partial) {
n->free_touched = 1;
entry = n->slabs_free.next;
if (entry == &n->slabs_free)
goto must_grow;
}
page = list_entry(entry, struct page, lru);
check_spinlock_acquired(cachep);
/*
* The slab was either on partial or free list so
* there must be at least one object available for
* allocation.
*/
BUG_ON(page->active >= cachep->num);
while (page->active < cachep->num && batchcount--) {
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
ac_put_obj(cachep, ac, slab_get_obj(cachep, page,
node));
}
/* move slabp to correct slabp list: */
list_del(&page->lru);
if (page->active == cachep->num)
list_add(&page->lru, &n->slabs_full);
else
list_add(&page->lru, &n->slabs_partial);
}
must_grow:
n->free_objects -= ac->avail;
alloc_done:
spin_unlock(&n->list_lock);
if (unlikely(!ac->avail)) {
int x;
force_grow:
//当 slab 中都没有空闲对象时,开始从 buddy 系统中获取内存
x = cache_grow(cachep, gfp_exact_node(flags), node, NULL);
/* cache_grow can reenable interrupts, then ac could change. */
ac = cpu_cache_get(cachep);
node = numa_mem_id();
/* no objects in sight? abort */
if (!x && (ac->avail == 0 || force_refill))
return NULL;
if (!ac->avail) /* objects refilled by interrupt? */
goto retry;
}
ac->touched = 1;
return ac_get_obj(cachep, ac, flags, force_refill);
}可以通过调用kmem_cache_alloc()函数分配slab对象:
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *ret = slab_alloc(cachep, flags, _RET_IP_);
trace_kmem_cache_alloc(_RET_IP_, ret,
cachep->object_size, cachep->size, flags);
return ret;
}调用kmem_cache_free()释放slab对象:
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
unsigned long flags;
cachep = cache_from_obj(cachep, objp);
if (!cachep)
return;
local_irq_save(flags);
debug_check_no_locks_freed(objp, cachep->object_size);
if (!(cachep->flags & SLAB_DEBUG_OBJECTS))
debug_check_no_obj_freed(objp, cachep->object_size);
__cache_free(cachep, objp, _RET_IP_);
local_irq_restore(flags);
trace_kmem_cache_free(_RET_IP_, objp);
}3.kmalloc函数分析
kmalloc() 只是适用于分配通用的 slab。 kmalloc 会调用到 __do_kmalloc()函数,其实现如下:
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
cachep = kmalloc_slab(size, flags); //根据申请的 size 获取到对应的 kmem_cache
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = slab_alloc(cachep, flags, caller);
trace_kmalloc(caller, ret,
size, cachep->size, flags);
return ret;
}
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{
int index;
if (unlikely(size > KMALLOC_MAX_SIZE)) {
WARN_ON_ONCE(!(flags & __GFP_NOWARN));
return NULL;
}
if (size <= 192) {
if (!size)
return ZERO_SIZE_PTR;
index = size_index[size_index_elem(size)];//计算出在对应的 index
} else
index = fls(size - 1);
#ifdef CONFIG_ZONE_DMA
if (unlikely((flags & GFP_DMA)))
return kmalloc_dma_caches[index];
#endif
return kmalloc_caches[index];
}首先,对于size 小于 192B的申请,则从 size_index 中查找索引。size_index_elem()函数和 size_index 数组的定义如下,为了方便比对,这里再次给出 kmalloc_info 数组的前 7 个元素。通过分析可以发现,在分配小于 192 的 obj 时,会向上对齐,例如,9~16 字节的 obj 保存到 16 字节的kmem_cache中,65-96字节的 obj 保存到 96字节的 mem_cache中。
static s8 size_index[24] = {
3, /* 8 */
4, /* 16 */
5, /* 24 */
5, /* 32 */
6, /* 40 */
6, /* 48 */
6, /* 56 */
6, /* 64 */
1, /* 72 */
1, /* 80 */
1, /* 88 */
1, /* 96 */
7, /* 104 */
7, /* 112 */
7, /* 120 */
7, /* 128 */
2, /* 136 */
2, /* 144 */
2, /* 152 */
2, /* 160 */
2, /* 168 */
2, /* 176 */
2, /* 184 */
2 /* 192 */
};
static inline int size_index_elem(size_t bytes)
{
return (bytes - 1) / 8;
}
kfree()函数如下,根据一个指针找到待释放的对象由函数virt_to_cache()函数实现:
void kfree(const void *objp)
{
struct kmem_cache *c;
unsigned long flags;
trace_kfree(_RET_IP_, objp);
if (unlikely(ZERO_OR_NULL_PTR(objp)))
return;
local_irq_save(flags);
kfree_debugcheck(objp);
c = virt_to_cache(objp);
debug_check_no_locks_freed(objp, c->object_size);
debug_check_no_obj_freed(objp, c->object_size);
__cache_free(c, (void *)objp, _RET_IP_);
local_irq_restore(flags);
} virt_to_cache()函数定义在mm/slab.h文件中,调用 virt_to_head_page()函数获得该虚拟地址对应的 page 描述符,然后由 page->slab_cache 反向获取到对应的 kmem_cache。
static inline struct kmem_cache *virt_to_cache(const void *obj)
{
struct page *page = virt_to_head_page(obj);
return page->slab_cache;
}继续回到kfree()函数,virt_to_cache()函数获取到了虚拟地址所对应的 kmem_cache,接下来调用__cache_free()函数来释放内存。
4.内存池:mempool_t
不应该将内存池与前面“保留的页框池”的保留页框混淆。实际上这些页框只能用于满足中断处理程序或内部临界区发出的原子内存分配请求。而内存池是动态内存的储备,只能被特定的内核成分(即池的“拥有者”)使用。拥有者通常不使用储备但是,如果动态内存变得极其稀有以至于所有普通内存分配请求都将失败的话,那么作为最后的解决手段,内核成分就能调用特定的内存池函数提取储备得到所需的内存。因此,创建一个内存池就像手头存放一些罐装食物作为储备,当没有新鲜食物时就使用开罐器。
typedef struct mempool_s {
spinlock_t lock; //用来保护对象字段的自旋锁
int min_nr; //内存池中元素的最大个数
int curr_nr; //当前内存池中元素的个数
void **elements; //指向一个数组的指针,该数组由指向保留元素的指针组成
void *pool_data; //池的拥有者可获得的私有数据
mempool_alloc_t *alloc; //分配一个元素的方法
mempool_free_t *free; //释放一个元素的方法
wait_queue_head_t wait; //当内存池为空时使用的等待队列
} mempool_t;内存池的创建函数mempool_create:内存池大小,分配方法,释放发法,分配源。创建完成之后,会从分配源(pool_data)中分配内存池大小(min_nr)个元素来填充内存池。
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data)
{
return mempool_create_node(min_nr,alloc_fn,free_fn, pool_data,
GFP_KERNEL, NUMA_NO_NODE);
}内存池的释放函数mempool_destory:
void mempool_destroy(mempool_t *pool)
{
if (unlikely(!pool))
return;
while (pool->curr_nr) {
void *element = remove_element(pool);
pool->free(element, pool->pool_data);
}
kfree(pool->elements);
kfree(pool);
}内存池分配对象的函数:mempool_alloc。mempool_alloc的作用是从指定的内存池中申请/获取一个对象。函数先从后备源中申请内存,当从后备源无法成功申请到时,才会从内存池中申请内存使用,因此可以发现内核内存池(mempool)其实是一种后备池,在内存紧张的情况下才会真正从池中获取,这样也就能保证在极端情况下申请对象的成功率,但也不一定总是会成功,因为内存池的大小毕竟是有限的,如果内存池中的对象也用完了,那么进程就只能进入睡眠,也就是被加入到pool->wait的等待队列,等待内存池中有可用的对象时被唤醒,重新尝试从池中申请元素。
void * mempool_alloc(mempool_t *pool, gfp_t gfp_mask)
{
void *element;
unsigned long flags;
wait_queue_t wait;
gfp_t gfp_temp;
VM_WARN_ON_ONCE(gfp_mask & __GFP_ZERO);
might_sleep_if(gfp_mask & __GFP_WAIT);
gfp_mask |= __GFP_NOMEMALLOC; /* don't allocate emergency reserves */
gfp_mask |= __GFP_NORETRY; /* don't loop in __alloc_pages */
gfp_mask |= __GFP_NOWARN; /* failures are OK */
gfp_temp = gfp_mask & ~(__GFP_WAIT|__GFP_IO);
repeat_alloc:
element = pool->alloc(gfp_temp, pool->pool_data);//先从后备源中申请内存
if (likely(element != NULL))
return element;
spin_lock_irqsave(&pool->lock, flags);
if (likely(pool->curr_nr)) {
element = remove_element(pool);/*从内存池中提取一个对象*/
spin_unlock_irqrestore(&pool->lock, flags);
/* paired with rmb in mempool_free(), read comment there */
smp_wmb();
/*
* Update the allocation stack trace as this is more useful
* for debugging.
*/
kmemleak_update_trace(element);
return element;
}
/*
* We use gfp mask w/o __GFP_WAIT or IO for the first round. If
* alloc failed with that and @pool was empty, retry immediately.
*/
if (gfp_temp != gfp_mask) {
spin_unlock_irqrestore(&pool->lock, flags);
gfp_temp = gfp_mask;
goto repeat_alloc;
}
/* We must not sleep if !__GFP_WAIT */
if (!(gfp_mask & __GFP_WAIT)) {
spin_unlock_irqrestore(&pool->lock, flags);
return NULL;
}
/* Let's wait for someone else to return an element to @pool */
init_wait(&wait);
prepare_to_wait(&pool->wait, &wait, TASK_UNINTERRUPTIBLE);//加入等待队列
spin_unlock_irqrestore(&pool->lock, flags);
/*
* FIXME: this should be io_schedule(). The timeout is there as a
* workaround for some DM problems in 2.6.18.
*/
io_schedule_timeout(5*HZ);
finish_wait(&pool->wait, &wait);
goto repeat_alloc;
}void mempool_free(void *element, mempool_t *pool)
{
unsigned long flags;
if (unlikely(element == NULL))
return;
/*
* Paired with the wmb in mempool_alloc(). The preceding read is
* for @element and the following @pool->curr_nr. This ensures
* that the visible value of @pool->curr_nr is from after the
* allocation of @element. This is necessary for fringe cases
* where @element was passed to this task without going through
* barriers.
*
* For example, assume @p is %NULL at the beginning and one task
* performs "p = mempool_alloc(...);" while another task is doing
* "while (!p) cpu_relax(); mempool_free(p, ...);". This function
* may end up using curr_nr value which is from before allocation
* of @p without the following rmb.
*/
smp_rmb();
/*
* For correctness, we need a test which is guaranteed to trigger
* if curr_nr + #allocated == min_nr. Testing curr_nr < min_nr
* without locking achieves that and refilling as soon as possible
* is desirable.
*
* Because curr_nr visible here is always a value after the
* allocation of @element, any task which decremented curr_nr below
* min_nr is guaranteed to see curr_nr < min_nr unless curr_nr gets
* incremented to min_nr afterwards. If curr_nr gets incremented
* to min_nr after the allocation of @element, the elements
* allocated after that are subject to the same guarantee.
*
* Waiters happen iff curr_nr is 0 and the above guarantee also
* ensures that there will be frees which return elements to the
* pool waking up the waiters.
*/
if (unlikely(pool->curr_nr < pool->min_nr)) {
spin_lock_irqsave(&pool->lock, flags);
if (likely(pool->curr_nr < pool->min_nr)) { //当前可分配的是否小于内存大小,
add_element(pool, element);
spin_unlock_irqrestore(&pool->lock, flags);
wake_up(&pool->wait);
return;
}
spin_unlock_irqrestore(&pool->lock, flags);
}
pool->free(element, pool->pool_data);
}















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











