






SDGAN: A novel spatial deformable generative adversarial network for low-dose CT image reconstruction
SDGAN:一种用于低剂量CT图像重建的新型空间可变形生成对抗性网络
Displays 78 (2023) 102405
背景
- 大多数现有的基于2D的方法都没有充分探索L-Timages的连续2D切片中的片间和片内信息,导致性能下降。
- 一些基于GAN的模型被设计用于学习跨域映射并生成引人注目的目标图像,而映射 高度受限。
- 在以前的许多研究中,缺乏临床应用的定性指标(即经验丰富的医生给出的意见得分)。
贡献
SDGAN由三个模块组成:基于一致性的生成器、双尺度鉴别器和空间可变形融合模块(SDFM)。连续L-CT切片序列首先被馈送到具有双标度鉴别器的基于构象器的生成器中,以生成F-CT图像。然后,这些估计的F-CT图像被馈送到SDFM中,SDFM充分探索层间和层内空间信息,以合成高质量的最终F-CT图像。
- 基于一致性的生成器通过引入来自构象器块的注意力相关潜码来优化从L-CT到F-CT的重建过程,生成初步的F-CT切片。
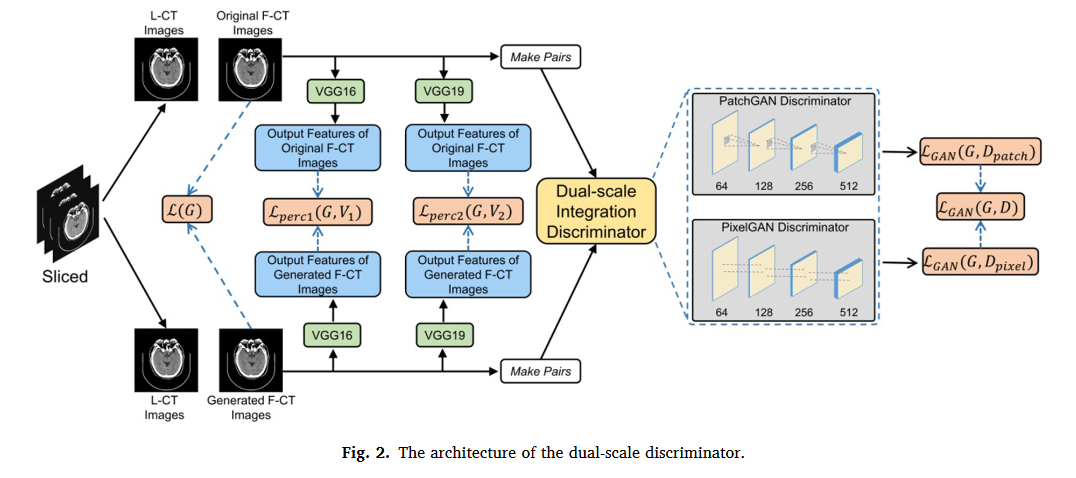
- 双尺度鉴别器集成了不同的预训练网络和感知损失,以区分估计的F-CT切片与补丁和像素视图中的原始F-CT图像之间的详细差异。
- SDFM以一系列估计的F-PET切片作为输入,通过偏移预测网络从不同尺度充分探索片间和片内空间信息,从而生成高质量的F-CT图像。
实验
数据集:私有数据集,38名脑肿瘤患者,PET/CT 系统上采集,排除质量较低的影像。5倍交叉验证

通过比较方法和我们的建议对真实和生成的F-PET图像之间的伪色差图进行比较。从小到大的绝对差异用从蓝色到红色的颜色来表示。

从消融实验上看,CG的作用比较大
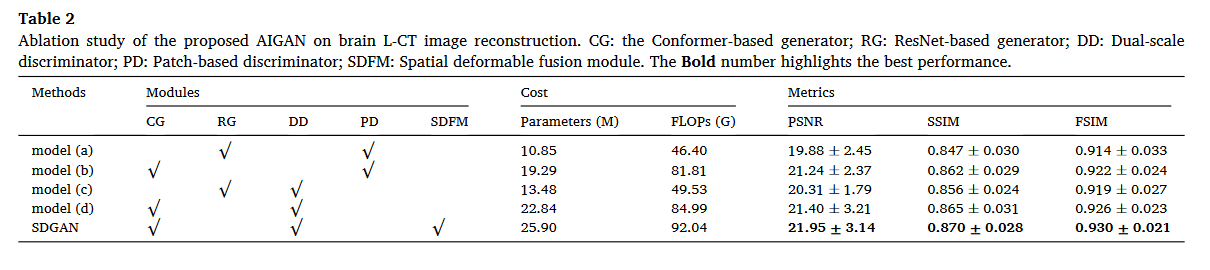
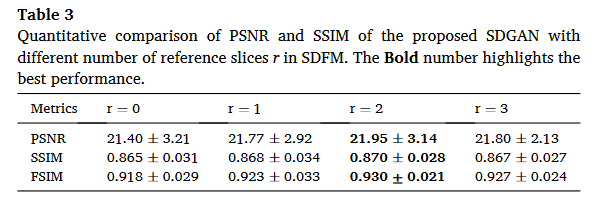
方法
首先将包含相应目标切片和几个相邻参考切片的连续低剂量CT(L-CT)切片序列x馈送到基于构象器的生成器中。所提出的生成器利用依赖于注意力的潜在代码,并探索每个切片中所有像素之间的局部和全局关系,以生成初始F-CT切片(xe)。然后,我们合成了低全剂量切片对(即xey),并将其输入到双尺度鉴别器中,该鉴别器从块视图和像素视图中提取几何信息,以提高xe的质量。最后,SDFM将连续的初始合成F-CT切片序列xe作为输入,以充分利用相邻参考切片的附加空间信息来增强目标切片的质量
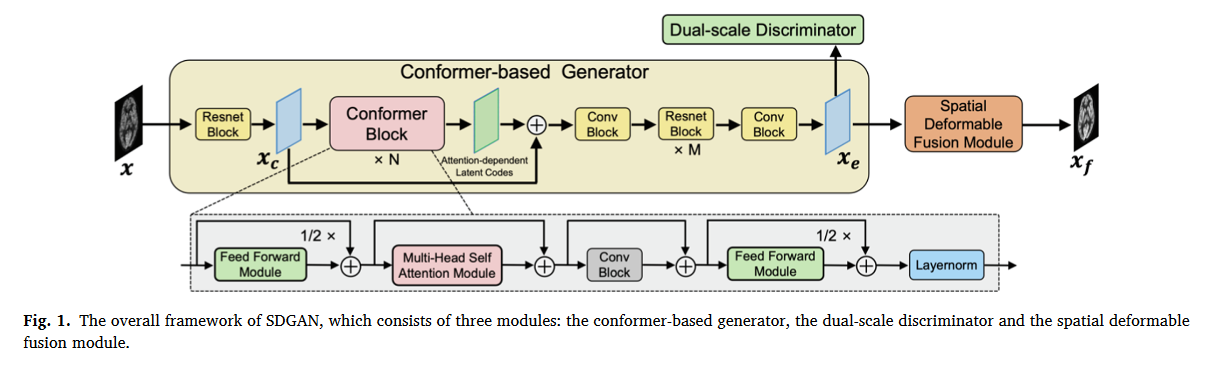
The conformer-based generator
参考文献19的Conformer Block
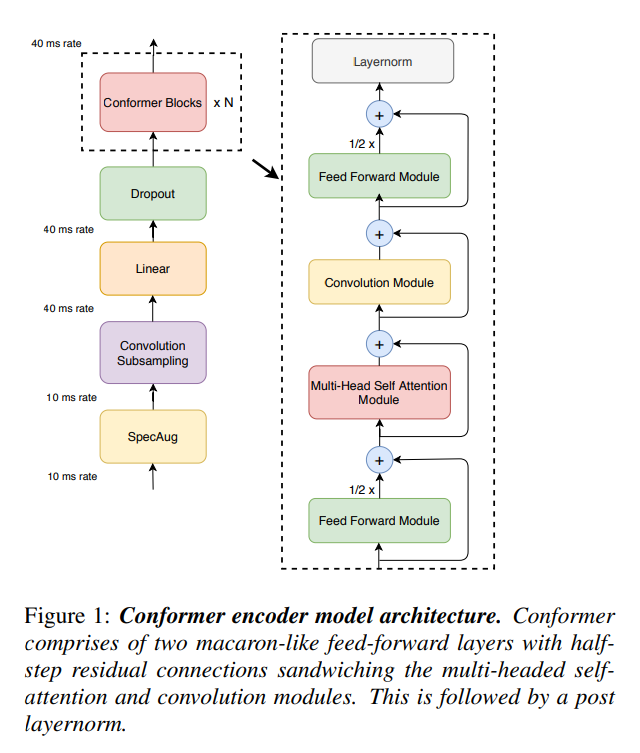
*参考文献19,研究如何以参数高效的方式结合卷积神经网络和Transformer来建模音频序列的局部和全局依赖关系,实现了两者的优势结合 *
conformer是transformer和CNNs的更好组合。受[19]中构象器的巨大成功的启发,我们还为生成器配备了几个构象器,它探索了每个切片的所有像素之间的局部和全局关系,从而产生了与注意力相关的潜在代码,并生成了具有不同细节的图像。上图黄块,CNN+Transformer
The dual-scale discriminator
它包含一个基于补丁的鉴别器Dpa和一个基于像素的鉴别剂Dpi。与单一的Dpa或Dpi只集中在一个视图的图像上不同,该机制允许Ddual在斑块和像素尺度上判断合成的F-CT图像,可以从不同的视图中提取结构信息
The spatial deformable fusion module
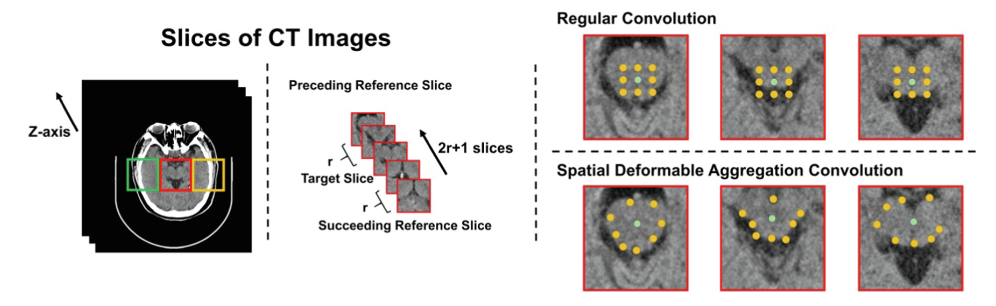
(SDFM)能够充分利用来自生成的F-CT切片序列的附加片间和片内结构信息。与现有方法[23,1]中成对估计(PE)方式的计算成本较高相比,所提出的SDFM通过联合估计(JE)方式提取空间补偿信息,由于相邻切片的所有结构信息都可以在一次前向通过中获得,因此计算成本低得多。具体而言,所提出的SDFM可以分为两个子模块:联合偏移估计(JOE)和空间可变形聚合(SDA)。我们在JOE中采用了一个修改的U-Net来进行可变形偏移,它包含了额外的信息结构内容和语义细节。然后,通过SDA中的可变形卷积层[24,25],将所有可变形偏移场Δ进一步自适应地融合到目标切片中。
现有的许多L-CT重建方法使用的规则卷积由于其感受野有限,无法正确处理大脑结构的细微空间信息。因此,基于常规卷积的融合无法捕获相邻切片中的相关内容。因此,它会引入噪声内容,不可避免地导致无效融合,损害F-CT的图像质量。与常规卷积不同,可变形卷积可以使卷积窗口适应每个切片的结构,并捕捉语义上的细微差异SDFM在融合期间利用位置特定采样来补偿空间信息。我们的SDFM引入了更高的灵活性和鲁棒性,因为内容可以在相邻的卷积窗口中独立采样

损失函数
λ设置为0.5。方程中的α和β。(9)分别设置为10和10。参考切片的数量r也被设置为2

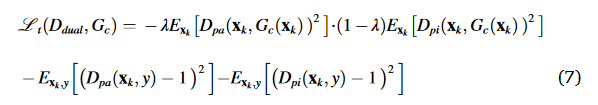

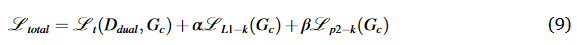
Thinking
生成器是CNN+Transformer,从消融实验看,加入参考文献19提供的Conformer Block有很大提升,双判别器从不同视图提供结构特征,可变形卷积利用切片间和切片内特征(2.5D思想),中间还加入了VGG16、19编码器提取特征进行判别。good idea!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









