







JS散度和Wasserstein散度
JS散度(Jensen-Shannon Divergence)
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。定义如下:
J
S
(
P
1
∣
∣
P
2
)
=
1
2
K
L
(
P
1
∣
∣
P
1
+
P
2
2
)
+
1
2
K
L
(
P
2
∣
∣
P
1
+
P
2
2
)
JS(P_1||P_2)=\frac{1}{2}KL(P_1||\frac{P_1+P_2}{2})+\frac{1}{2}KL(P_2||\frac{P_1+P_2}{2})
JS(P1∣∣P2)=21KL(P1∣∣2P1+P2)+21KL(P2∣∣2P1+P2)
存在两个分布,不存在重叠,KL散度值会变得无意义,而JS散度值是一个常数,会导致梯度消失。
Wasserstein散度/距离(Wasserstein Distance)
Wasserstein距离度量两个概率分布之间的距离,对于两个分布 q 1 q_1 q1, q 2 q_2 q2, P t h − W a s s e r s t e i n P^{th}-Wasserstein Pth−Wasserstein距离定义为:
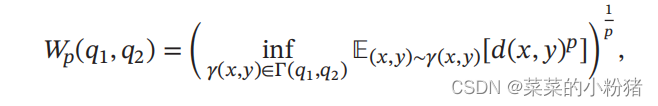
其中Γ(𝑞1, 𝑞2)是边际分布为𝑞1 和𝑞2 的所有可能的联合分布集合,𝑑(𝑥, 𝑦)为𝑥和𝑦的距离,比如ℓ𝑝 距离等。
如果将两个分布看作是两个土堆,联合分布 𝛾(𝑥, 𝑦) 看作是从土堆 𝑞1 的位置𝑥到土堆𝑞2 的位置𝑦的搬运土的数量,并有
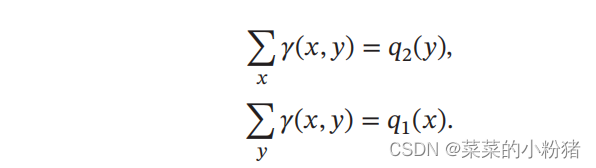
𝑞1 和𝑞2 为𝛾(𝑥, 𝑦)的两个边际分布。
E
(
x
,
y
)
∼
γ
(
x
,
y
)
[
d
(
x
,
y
)
p
]
E_{(x,y)\sim \gamma(x,y)}[d(x,y)^p]
E(x,y)∼γ(x,y)[d(x,y)p]可以理解为在联合分布𝛾(𝑥, 𝑦)下把形状为𝑞1 的土堆搬运到形状为𝑞2 的土堆所需的工作量,
E
(
x
,
y
)
∼
γ
(
x
,
y
)
[
d
(
x
,
y
)
p
]
=
∑
(
x
,
y
)
γ
(
x
,
y
)
d
(
x
,
y
)
p
E_{(x,y)\sim \gamma(x,y)}[d(x,y)^p]=\sum_{(x,y)}{\gamma(x,y)d(x,y)^p}
E(x,y)∼γ(x,y)[d(x,y)p]=(x,y)∑γ(x,y)d(x,y)p
其中从土堆
q
1
q_1
q1中的点
x
x
x到土堆
q
2
q_2
q2中的
y
y
y的移动土的数量和距离分别为
γ
(
x
,
y
)
\gamma(x,y)
γ(x,y)和
d
(
x
,
y
)
p
d(x,y)^p
d(x,y)p。 因此,Wasserstein 距离可以理解为搬运土堆的最小工作量,也称为推土机距离(Earth-Mover’s Distance,EMD)。
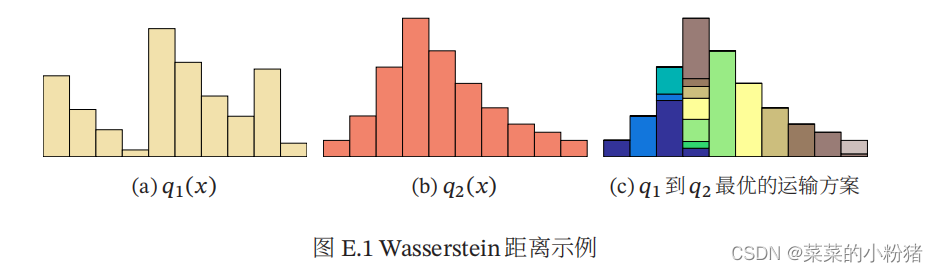
注:图片来自于《神经网络与深度学习》邱锡鹏
Wasserstein距离相比 KL 散度和 JS 散度的优势在于:即使两个分布没有重叠或者重叠非常少,Wasserstein距离仍然能反映两个分布的远近。
import scipy.stats
import numpy as np
u_values, v_values = np.array([1,2,1]), np.array([1,2,1])
u_weights, v_weights=[0,1,2], [3,4,5]
D1=scipy.stats.wasserstein_distance(u_values, v_values, u_weights, v_weights)
# u_values, v_values:在(经验)分布中观察到的值;
# u_weights, v_weights: 每个值的权重。如果未指定,则为每个值分配相同的权重,可选。 u_weights (resp. v_weights) 必须与 u_values (resp. v_values) 具有相同的长度。如果权重总和不为 1,则它仍然必须是正数和有限的,以便权重可以归一化为总和为 1。
# return两个分布之间的计算距离
print(D1)
关注+点赞+收藏
















 3770
3770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









