







一、概述:
GAP定义及产生原理:Gap英文单词的意思就是缝隙的意思,dataguard中出现gap的原理是:源端传递一个archivelog到目标端之后会在目标数据库进行注册,当中间某个archivelog归档到目标端失败或者没有成功注册且后续的archivelog成功归档的话目标端在恢复过程中就会将中间的sequence定义为gap。
注意:gap是mrp在恢复的时候检测的,它只会汇报影响apply日志的gap,当前gap后面是否有gap它无法报告
二、mos文章
11g Steps to perform for Rolling Forward a Physical Standby Database using RMAN IncrementalBackup.(DocID 836986.1); Steps to perform for Rolling forward a standby database using RMAN incremental backup whendatafile is added to primary (Doc ID 1531031.1) How to Roll Forward a Standby Database Using Recover Database From Service (Doc ID2850185.1); 18c Roll Forward Physical Standby Using RMAN Incremental Backup in Single Command(DOcID 2431311.1): How to resolve ORA:00328 in a standby database (Doc ID 864364.1) RMAN-06094 or RMAN-06571 During Recovery or Switch to Copy at Standby Site (Doc ID1339439.1)
三、减少产生gap的可能性:
1).提升网络带宽;
2).启用log_archive_dest_n的compression属性可以压缩到70%的网络占用(需要额外购买license)
3).启用多个进程并发传送同一个archivelog (max_connections)
四、修复GAP
4.1.归档存在且gap较小的情况
解决方法:可以使用手工传递( 也可先备份)归档并手工注册的方式进行修复;
1)在目标端获取GAP的sequence:
SELECT THREAD#, LOW_SEQUENCE#, HIGH_SEQUENCE# FROM V$ARCHIVE_GAP;
2)在源端获取对应sequence的文件名:
SELECT NAME FROM V$ARCHIVED_LOG WHERE THREAD#=1 AND DEST_ID= <dest_id> AND SEQUENCE# BETWEEN <seq_low> AND <seq_high>;
3)确认对应文件在源端是否存在,如果存在则传送到目标端
4)传送到目标端进行注册:
ALTER DATABASE REGISTER LOGFILE ' <full_path_of_archivelog>'; select 'ALTER DATABASE REGISTER LOGFILE '''||name||''';' from v$archived_log where name is not null and APPLIED='NO';
4.2.rman备份归档恢复
4.2.1.备库中查看rman备份是否存在
–---查看这些日志是否存在 list backup of archivelog from sequence 666 until sequence 675; –---如果存在rman备份中,使用rman进行恢复 restore archivelog from sequence 666 until sequence 675;
4.2.2 rman备份归档传送恢复
1)在目标端获取GAP的sequence:
SELECT THREAD#, LOW_SEQUENCE#, HIGH_SEQUENCE# FROM V$ARCHIVE_GAP;
2)在源端确认所需seq对应的归档总大小,对相应的sequence进行备份:
run {
allocate channel ch00 type disk;
backup as compressed backupset archivelog sequence between 50 and 52 thread 1 format '/backup/arc_%d_%T_%s_%p';
release channel ch00;
}
3) 将备份传送到目标端,并停止MRP后进行recover;
SQL> alter database recover managed standby database cancel; RMAN> catalog start with '/backup/arc' noprompt; RMAN> recover database;
4) 应用完成后启用MRP
alter database recover managed standby database disconnect from session;
4.2.3 通过SCN恢复
select THREAD#,SEQUENCE#,FIRST_CHANGE#,NEXT_CHANGE# from v$archived_log where SEQUENCE#=59;
THREAD# SEQUENCE# FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ------------- ------------
1 59 2083840 2128961
4.3 源端归档不存在,增量恢复
4.3.1 备库首先要知道误删除或者丢失的归档日志是从哪个 SCN 开始的,取最小值。
col DATAFILE_SCN format 9999999999999999999999999999999 col DATAFILE_HEADER_SCN format 9999999999999999999999999 col CURRENT_SCN format 99999999999999999999999999999999 col NEXT_CHANGE# format 99999999999999999999999999999 SELECT (SELECT MIN(D.CHECKPOINT_CHANGE#) FROM V$DATAFILE D) DATAFILE_SCN, (SELECT MIN(D.CHECKPOINT_CHANGE#) CHECKPOINT_CHANGE FROM V$DATAFILE_HEADER D) DATAFILE_HEADER_SCN, (SELECT CURRENT_SCN FROM V$DATABASE) CURRENT_SCN, (SELECT MIN(B.NEXT_CHANGE#) FROM V$ARCHIVED_LOG B WHERE RESETLOGS_CHANGE# = (SELECT D.RESETLOGS_CHANGE# FROM V$DATABASE D)) NEXT_CHANGE# FROM DUAL; sqlplus / as sysdba select to_char(current_scn) from v$database; select min(checkpoint_change#) from vSdatafile_header; --1198077
RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of recover command at 02/05/2020 12:12:28 RMAN-06094: datafile 71 must be restored 查询数据字典 发现这个数据文件为新增的数据文件,standby端还没有此数据文件,所以需要先将此datafile进restore,否则无法recover.查找新增的数据文件sql如下: SQL> select file#,name from v$datafile where creation_change#> =139323967; 解决办法: 找到所有gap之后新增的数据文件,例如71-77号数据文件,先备份进行restore: 原库: RMAN> backup datafile 71,72,73,74,75,76,77 format '/rmanbak/backup/newfile_%U.bak'; 在备库进行还原: RMAN> restore datafile 71,72,73,74,75,76,77; 然后再进行recover即可. RMAN> recover datafile noredo;

4.3.2 主库增量备份
RUN {
ALLOCATE CHANNEL D1 TYPE DISK;
BACKUP AS COMPRESSED BACKUPSET INCREMENTAL FROM SCN 750983 DATABASE FORMAT
'/backup/STANDBY_ADD_%D_%T_%U.BAK' INCLUDE CURRENT CONTROLFILE FOR STANDBY FILESPERSET=5 TAG
'FOR STANDBY ADD';
RELEASE CHANNEL D1;
}
list backupset of controlfile;--找到控制文件的备份集文件名
run(
allocate channel c1 type disk;
allocate channel c2 type disk;
crosscheck archivelog all;
delete expired archivelog all;
backup datafile 6 format '/tmp/bak/ForStandby_%U' tag 'FORSTANDBY'; backup incremental from scn 1198077 database format'/tmp/bak/incre_%U'; backup current controlfile for standby reuse format ''; release channel cl; release channel c2;
4.3.3 传送到目标库恢复
在使用RMAN恢复备库的控制文件之前,需要将原来的控制文件进行手工的冷备并且记录下原来的控制文件中记录的数据文件的名称。
SELECT ''''||NAME||''' ;' FROM V$DATAFILE; --记录备库数据文件原名称及路径 startup force nomount; -----cp +DATA/oranlhr/ controlfile/control01.ctl +DATA/oranlhr/controlfile/control01.ctl_bk restore standby controlfile from '/tmp/bak/standby.ctl';
4.3.4 在备库执行 RECOVER 操作:
ALTER DATABASE MOUNT; CATALOG START WITH '/ARCHIVE/'; list incarnation of database; reset database to incarnation 1; --应该和主库保持一致 RECOVER DATABASE NOREDO; 清空standby redo log select 'ALTER DATABASE CLEAR LOGFILE GROUP '|| GROUP# ||';' from v$logfile where type='STANDBY' group by group#;
4.3.5 备库开始应用redo
alter database recover managed standby database disconnect from session;
4.3.6 使用如下的 SQL 来查询恢复的进度
SELECT A.USERNAME,
( SELECT UPPER(NB.OSUSER)
FROM V$SESSION NB
WHERE NB.SID = A.SID) OSUSER,
( SELECT NB.SID || ', ' || NB.SERIAL# || ', ' || PR.SPID
FROM V$PROCESS PR, V$SESSION NB
WHERE NB.PADDR = PR.ADDR
AND NB.SID = A.SID
AND NB.SERIAL# = A.SERIAL#) SESSION_INFO, A.TARGET, A.OPNAME, TO_CHAR(A.START_TIME, 'YYYY-MM-DD HH24:MI:SS') START_TIME, ROUND(A.SOFAR * 100 / A.TOTALWORK, 2) || '%' AS PROGRESS, (A.TIME_REMAINING) TIME_REMAINING, (A.SOFAR || '
:' || A.TOTALWORK) SOFAR_TOTALWORK, (A.ELAPSED_SECONDS) ELAPSED_SECONDS, MESSAGE MESSAGE,
( SELECT NB.EVENT
FROM V$SESSION_WAIT NB
WHERE NB.SID = A.SID) WAIT_EVENT,
( SELECT NB.STATUS
FROM V$SESSION NB
WHERE NB.SID = A.SID) STATUS
FROM V$SESSION_LONGOPS A
WHERE A.TIME_REMAINING <> 0ORDER BY STATUS, A.TIME_REMAINING DESC, A.SQL_ID, A.SID;



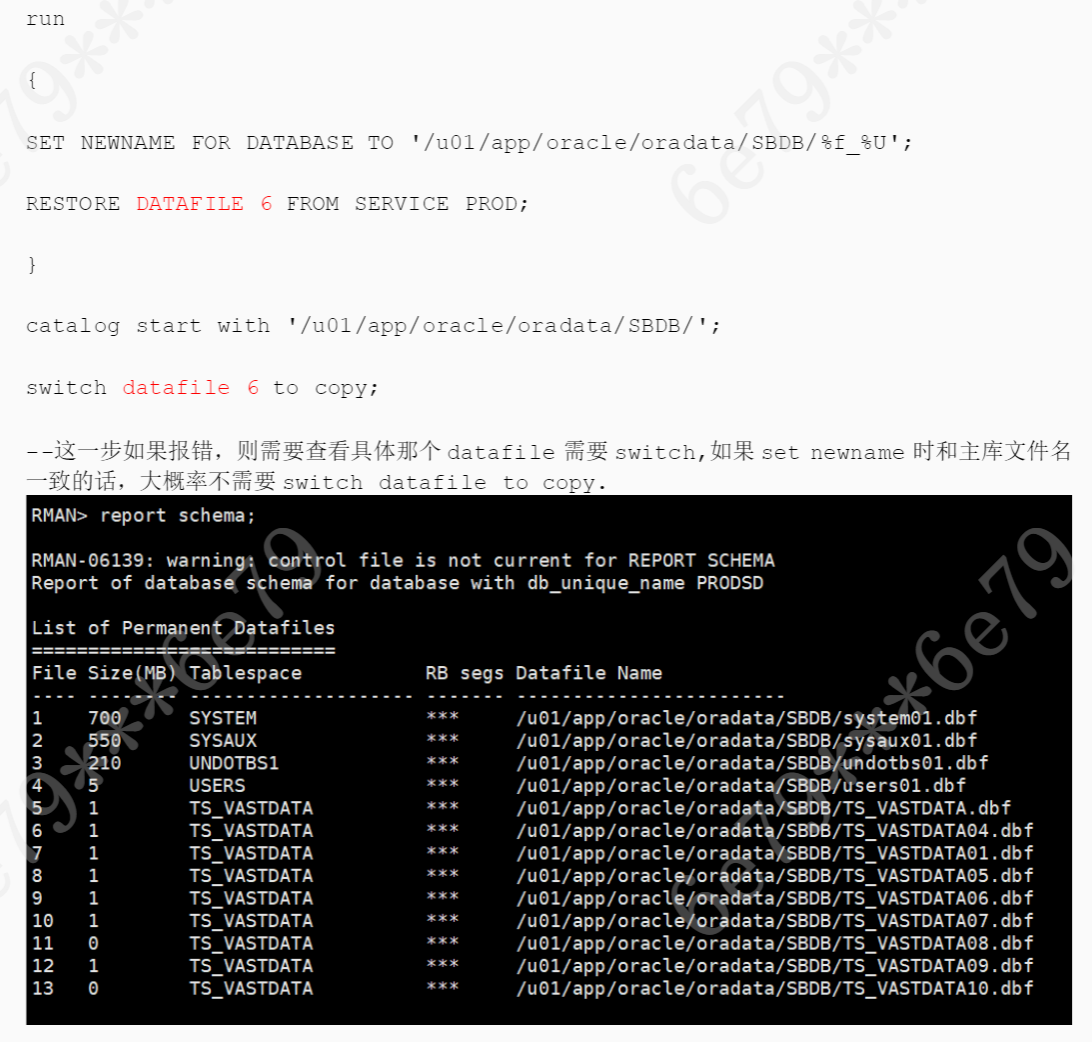
清除孤立的文件
list datafilecopy all; delete datafilecopy all;
清除online redo log and standby redo log;
begin
for log_cur in ( select group# group_no from v$log )
loop
execute immediate 'alter database clear logfile group '||log_cur.group_no;
end loop;
end;
/
begin
for log_cur in ( select group# group_no from v$standby_log )
loop
execute immediate 'alter database clear logfile group '||log_cur.group_no;
end loop;
end;
/
对于已经完成归档的redo group,即状态为inactive的redo group:
执行: alter database clear logfile group
因为这种情况下,redo 已经完成归档,所以恢复时不会造成数据的丢失。
当redo 为active时,即表示正在归档,这个时候,只能执行:
alter database clear unarchived logfile group
这个时候,如果进行恢复,是会有数据丢失的。 一般除非redo 损坏才会用到这个命令。具体的情况还是需要具体对待。 如果的Data Guard 环境,执行了alter database clear unarchived logfile group,那么DG 就需要重新搭建了。恢复主备GAP
主库:
alter system set log_archive_dest_state_2=ENABLE;
备库:
recover database from service prod noredo section size 600M using compressed backupset;
主库:
alter system archive log current;
备库:
recover automatic standby database until consistent;
alter database open read only;备库开启mrp



















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









