






论文FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning,Diffusion 扩散模型用于生成任意风格的复杂字的使用配方。
一种基于扩散的Image-to-Image字体生成方法“FontDiffuser”,它创新性地将字体模仿任务建模为噪声到噪声范式。作者引入了多尺度内容聚合(MCA)模块,它有效地结合了不同尺度的全局和局部内容线索,从而增强了对复杂字的复杂笔画的保留。
- 作者: 杨振华、彭德智.
- 单位: 华南理工大学DLVC实验室、阿里巴巴
论文链接: https://arxiv.org/abs/2312.12142 - 项目链接: https://yeungchenwa.github.io/fontdiffuser-homepage/
- HuggingFace Demo链接: https://huggingface.co/spaces/yeungchenwa/FontDiffuser-Gradio

图1 FontDiffuser的输出结果 (复杂字+风格跨度大

图2 FontDiffuser与InstructPix2Pix的联合使用效果
摘要
字体生成是一项模仿任务,其目的是创建一个字体库,模仿参考图像(风格图像)的风格,同时保留源图像(内容图像)的内容,如下图3所示。虽然现有方法已经取得了令人满意的性能,但它们在处理复杂字符和风格变化较大的字符时仍然很吃力。
为了解决这些问题,我们提出了一种基于扩散的Image-to-Image字体生成方法“FontDiffuser”,它创新性地将字体模仿任务建模为噪声到噪声范式。在我们的方法中,我们引入了多尺度内容聚合(MCA)模块,它有效地结合了不同尺度的全局和局部内容线索,从而增强了对复杂字的复杂笔画的保留。
此外,为了更好地处理具有巨大差异的风格转换,我们提出了风格对比细化(SCR)模块,这是一种新颖的风格表征对比学习策略,它利用风格提取器将风格从图像中分离出来,然后通过精心设计的风格对比损失对扩散模型进行监督。
广泛的实验证明,FontDiffuser 在生成多样化字符和风格方面具有一流的性能。与以前的方法相比,它在复杂字符和大的风格变化方面始终表现出色。
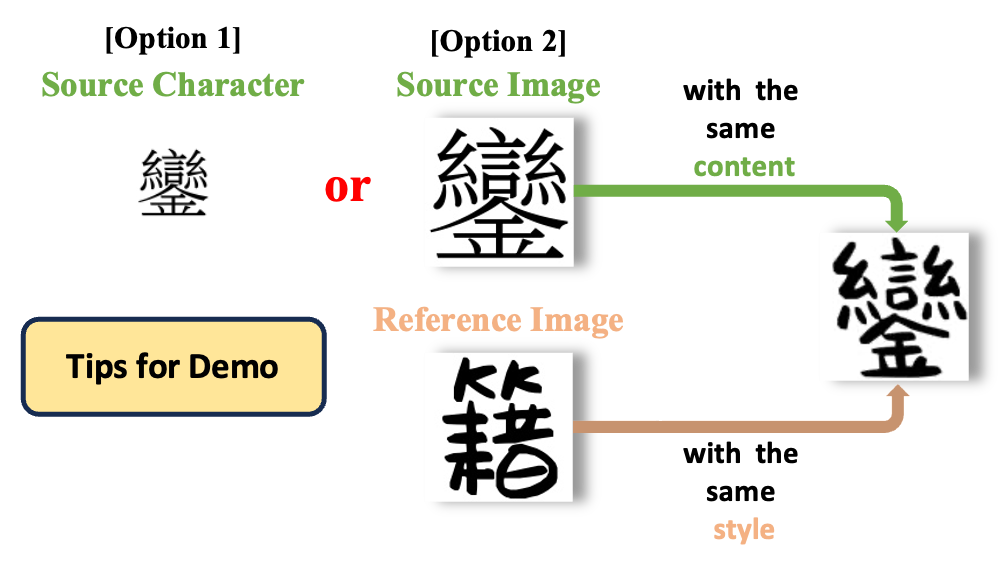
图3 字体生成任务定义
研究动机

图4 其他方法在复杂字和风格跨度大上的生成效果
存在的问题
现有的字体生成方法虽然取得了令人满意的性能,但在处理复杂字和风格变化较大的字符(尤其是中文字符)时,仍会出现严重的笔画缺失、伪影、模糊、结构布局错误和风格不一致等问题,如上图4所示。
原因分析
- 大多数方法都采用基于 GAN 的框架,由于其对抗训练的性质,可能会出现训练不稳定的问题。
- 这些方法大多只通过单一尺度的高维特征来感知内容信息,而忽略了对保留源内容(尤其是复杂字符)的细粒度细节。
- 许多方法利用先验知识来帮助字体生成,例如字符的笔画或部件组成;然而,对于复杂的字符来说,获取这些细粒度信息的成本很高;
- 在过去的方法中,目标风格通常由一个简单的分类器或判别器来进行特征表示学习,这种分类器或判别器很难学习到合适的风格,在一定程度上阻碍了在风格变化较大时的风格转换。
采用策略
- 我们提出了一种基于扩散的图像到图像(Image-to-Image)的字体生成方法,名字叫FontDiffuser,它将字体生成学习建模为加噪到去噪的范式,能够生成未见过的字符和风格。
- (1) 我们引入了多尺度内容聚合(MCA)模块,它利用了不同尺度的全局和局部内容特征。
- (2) 我们引入了一种新颖的风格表征对比学习策略,通过利用风格对比细化(SCR)模块来增强生成器模仿风格的能力。
FontDiffuser模型框架
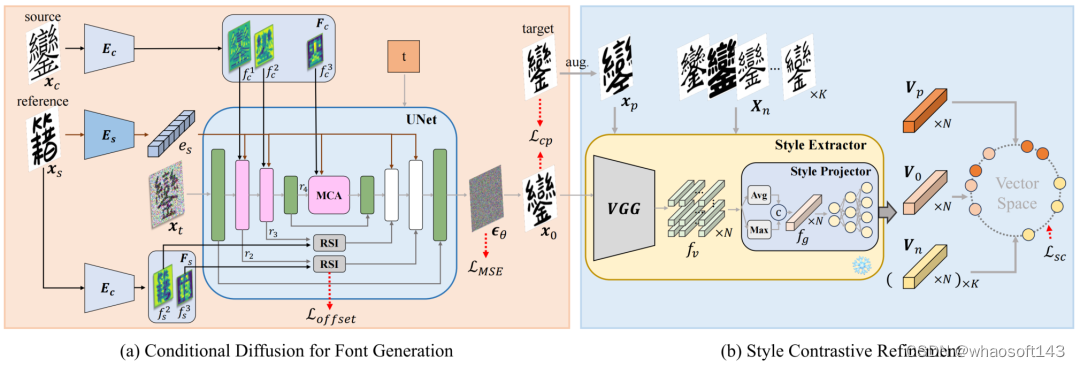
图5 FontDiffuser的模型框架图
FontDiffuser的模型框架如图5所示,其中包括字体生成条件扩散模型和风格细化对比模块两部分。在条件扩散字体生成模型部分,我们的目标是,在给定一张源图片(内容图片)和一张参考图片(风格图片),该模型的输出结果能够既与源图片的字符内容相同,也能与参考图片的风格保持一致;在风格细化对比学习模块,起主要目标是在训练的过程中,能够将一组图片的风格分离出来并完成辨别,最后通过风格对比损失函数来为条件扩散模型提供监督信息。
条件扩散字体生成模型

- 多尺度内容聚合(MCA)模块
生成复杂的字符一直是一项极具挑战性的任务,现有的许多方法仅依赖于单一尺度的内容特征,而忽略了复杂的细节,如笔画和部首。如图 6 所示,大尺度特征保留了大量细节信息,而小尺度特征则缺乏这些信息。
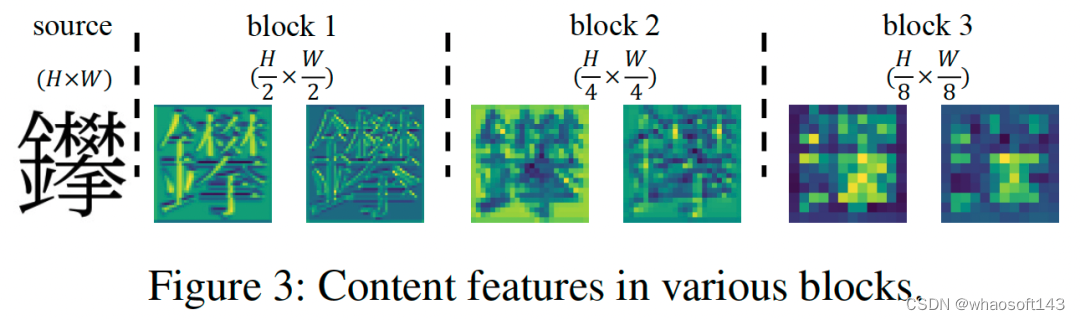
图6 在内容编码器中不同尺度的特征图
因此,我们设计了多尺度内容聚合(MCA)模块,将不同尺度的全局和局部内容特征注入到扩散模型的 UNet 中,如下图7所示。其中包括了一个通道注意力机制来提高自适应通道选择能力和一个Cross-Attention来引入风格特征。
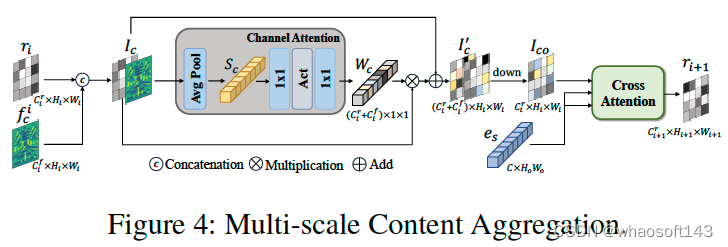
图7 多尺度内容聚合(MCA)模块
- Reference-Structure Interaction (RSI)交互模块
源图像(内容图像)和目标图像之间存在结构差异(如字体大小),为了解决这个问题,我们提出了Reference-Structure(RSI)交互模块,它采用可变形卷积网络DCN对UNet 的skip-connection部分进行结构变形。具体过程可以使用以下公式表
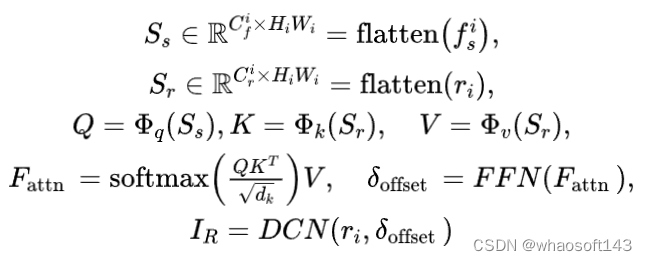
风格细化对比学习模块
不管源图像(内容图像)和参考图像(风格图像)之间的风格差异,字体生成的目的之一是达到预期的风格模仿效果。其中的一种可行的解决方案是找到合适的风格特征表示,并进一步为我们的生成器提供监督信息。因此,我们提出了风格细化对比学习(SCR)模块,这是一个字体风格表示学习模块,它能从一组样本图像中分离出风格,并结合风格对比损失来监督我们的条件扩散模型,能够较好地与扩散模型进行较好的结合,确保生成的风格在全局和局部层面上与目标保持一致,具体的做法如上图5(b)所示,用公式表示如下:
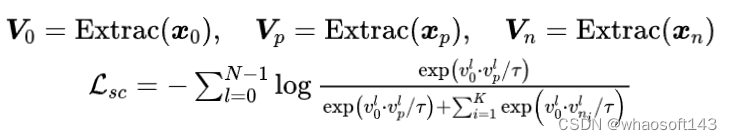
训练损失函数
我们的训练采用了一个从粗到细的两阶段策略,具体包括:
- Phase 1
我们主要使用标准的 MSE 扩散损耗来优化 FontDiffuser,而不使用 SCR 模块。这确保我们的生成器具备字体重构的基本能力:
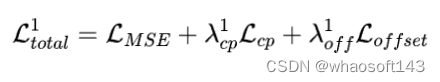
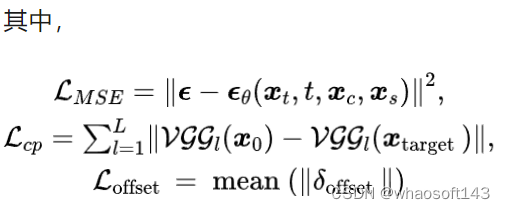

更多可视化结果

图8 困难难度字符
中等难度字符 (medium)

图9 中等难度字符
容易难度字符 (easy)

图10 容易难度字符
跨语言生成 (中文到韩文)

图11 跨语言生成 (中文到韩文)
实验
为了验证生成不同复杂度字符的有效性,我们根据中文字符的笔画数将其分为三个复杂度级别(easy, medium, hard),并在每个级别上分别测试我们的方法。不同复杂度的中文字符样例如下:

图12 三种不同复杂度的中文字符样例
定量结果 (Quantitative Results)
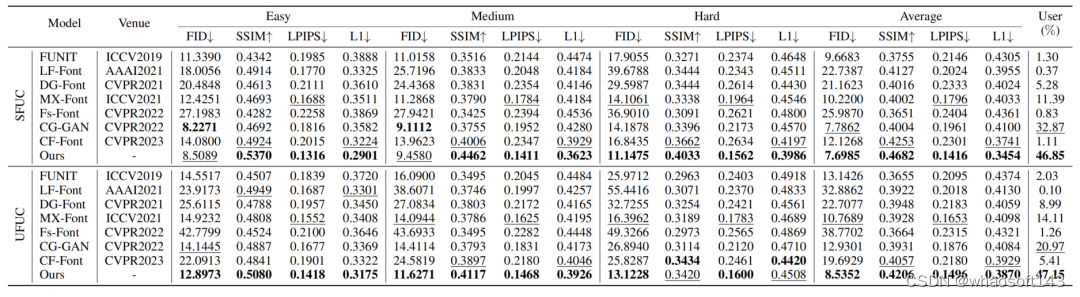
图13 在SFUC和UFUC上的定量结果
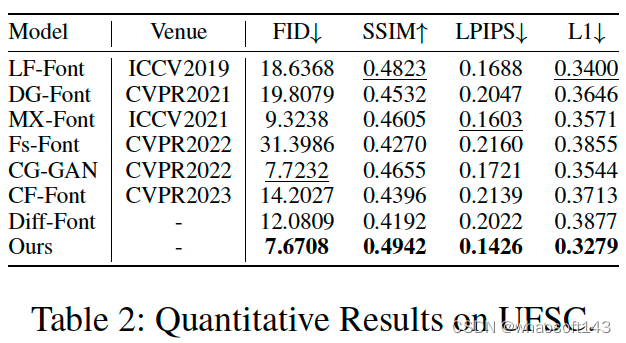
图14 在UFSC上的定量结果
定性结果 (Qualitative Results)
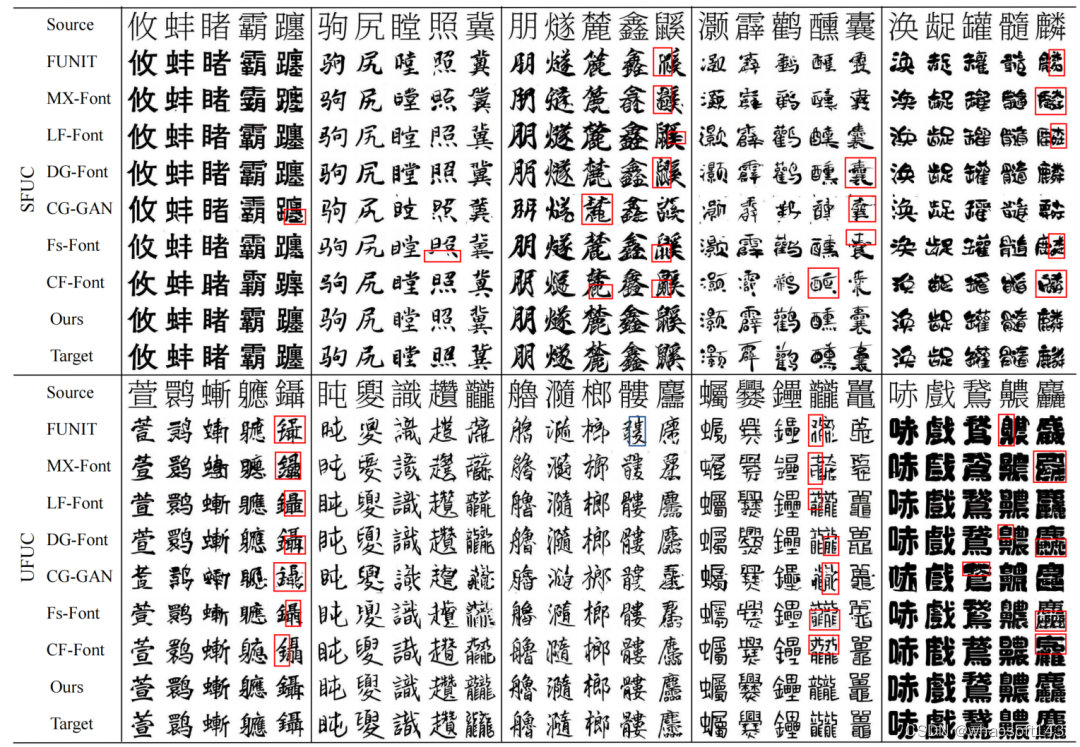
图15 在SFUC和UFUC上的定性结果
跨语言生成 (中文到韩文)
FontDiffuser还能在仅有中文数据集的训练的情况下,用于韩文的生成,结果如下图11所示:

图16 跨语言生成 (中文到韩文)
结论分析
我们的方法在不同的在三个复杂度级别的字符上,FontDiffuser 的表现优于目前的其他方法。此外,FontDiffuser 还证明了它在跨语言字体生成任务(如中文到韩文)中的适用性,凸显了其良好的跨领域能力。
消融实验
- 不同模块的有效性
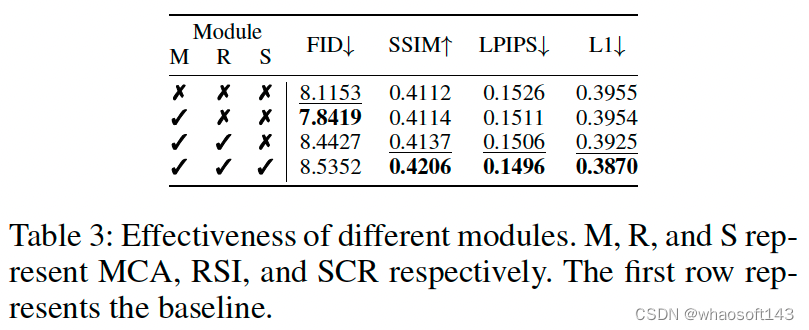
图17 使用不同模块后的性能对比

图18 使用不同模块后的可视化效果对比
- SCR模块中数据增广的有效性
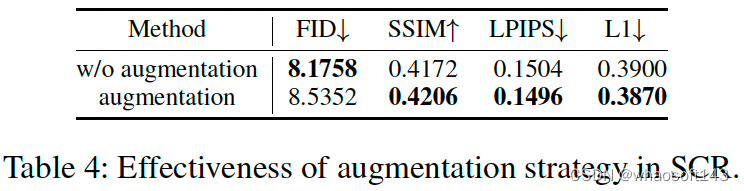
图19 SCR模块中数据增广的有效性
- RSI模块中基于cross-attention和CNN的交互方式的性能对比
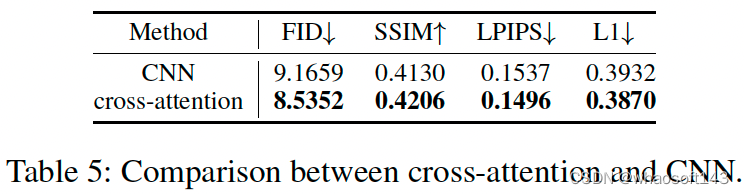
图20 RSI模块中基于cross-attention和CNN的交互方式的性能对比
总结
在本文中,我们提出了一种基于扩散的图像到图像(Image-to-Image)的字体生成方法,称为FontDiffuser,它在生成复杂字符和处理差异较大的风格转换方面表现出色。
此外,我们还提出了一种新颖的风格特征对比学习策略,该策略提出了一个 SCR 模块,并使用风格对比损失来监督我们的扩散模型。此外,我们还采用了 RSI 模块,利用参考图像的结构特征促进结构变形。
大量实验证明,在三个复杂度级别的字符上,FontDiffuser 的表现优于目前的方法。此外,FontDiffuser 还证明了它在跨语言字体生成任务(如中文到韩文)中的适用性,凸显了其良好的跨领域能力。
demo
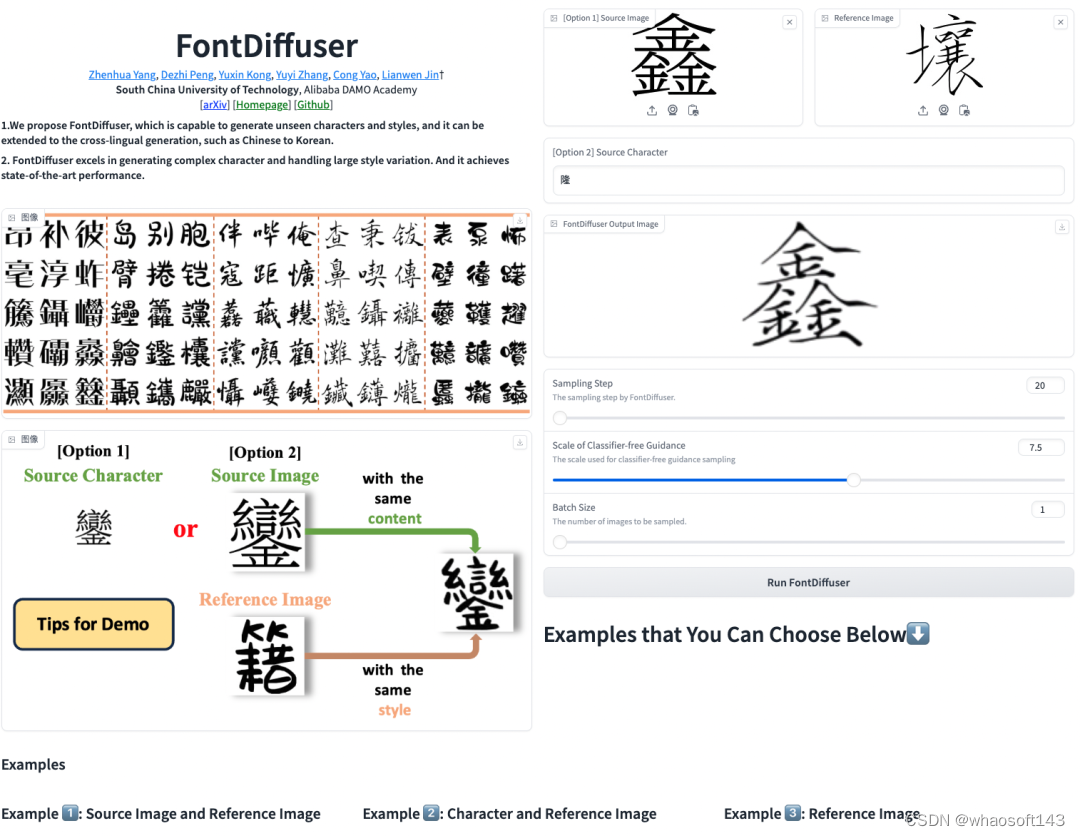
图21 demo演示















 5046
5046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









