







一、Cache
1、Cache简介
Cache是为提升STM32性能的一个硬件,是一种高级缓存。它在STM32F7系列(以下简称F7)、STM32H7(以下简称H7)系列等高性能芯片中存在,在STM32F1、STM32F4系列中并不存在。它主要是用于提高STM32访问内存的速度,用于将数据提前加载到Cache中,当CPU需要时,再将该数据提供给CPU。这个操作在电脑的CPU中也有对应,如图2.1所示。可以看到电脑的CPU有三级缓存L1、L2、L3。H7、M7系列的芯片属于M7内核,M7内核有一级Cache,可以将其理解为M7内核的芯片有一级缓存,其Cache分为数据缓存D-Cache和指令缓存I-Cache。
为什么H7、M7有Cache,而F1、F4系列的芯片没有Cache呢?因为F7、H7芯片的主频非常高,已经高出SRAM的频率了,也就是说SRAM的传输速度是跟不上芯片了。AXI SRAM、SRAM1、SRAM2的频率一般在240MHz,而H7芯片的频率已经达到了480MHz(Cache的工作频率也是480MHz),这里为了提高CPU对SRAM的访问速度,所以引入了Cache。它可以将CPU常用的数据存储起来,当CPU去计算其他数据的时候,它就可以去替CPU完成对SRAM的读写操作。所以Cache是为了解决CPU获取SRAM数据慢的问题而存在的。
2、Cache的工作原理
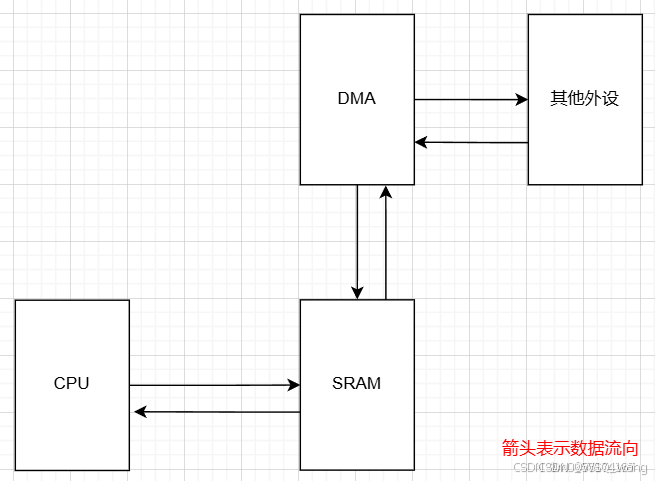
在没有Cache前,单片机对SRAM的操作流程大致是CPU或DMA对SRAM进行读写操作,如图2.1所示。
当单片机中存在Cache后,因为有了Cache作为CPU的一个数据转运与操作,所以Cache应该位于CPU与SRAM之间,作为一种类似于中介的存在。如图2.2所示。
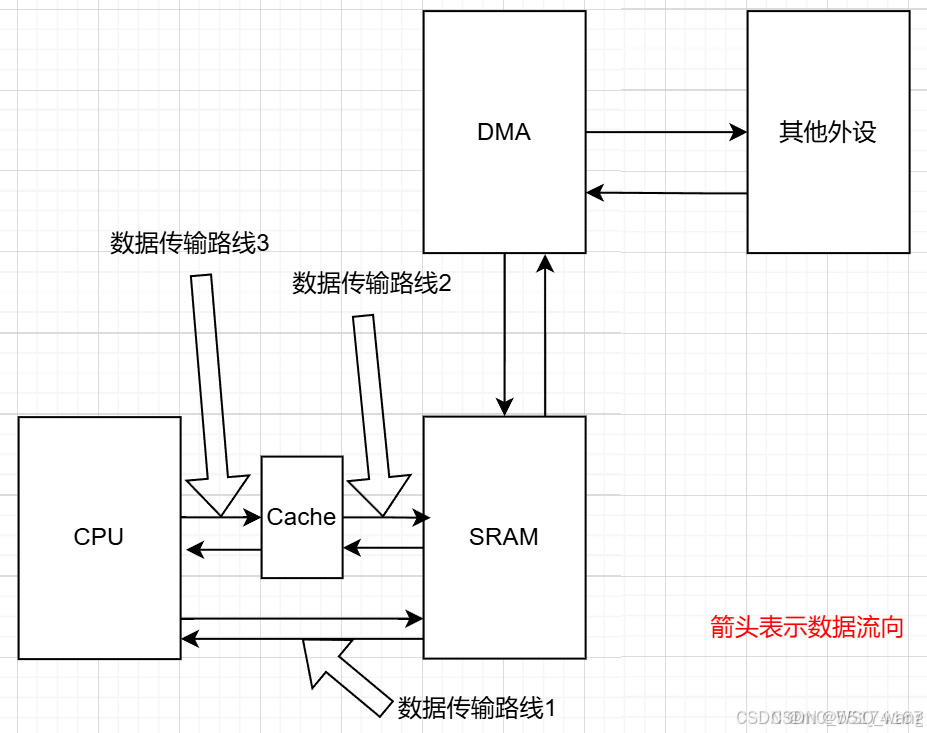
图2.2 单片机使有Cache后的大致数据流向
可以看到,当有了Cache之后,多了两条数据传输路线,即数据传输路线2和3。这两条线路是CPU通过Cache去间接操作SRAM的路线。可为何有了线路2和线路3,为何还保持着线路1呢,这是因为Cache非常小,H7的Cache仅有16K(F7仅有4K),SRAM就非常大了。所以此时就面临着一种情况,即CPU需要的数据,并不在Cache里面,也就是Cache中并没有预加载到CPU需要的数据,需要CPU直接SRAM中获取。这也就引出了四种情况,当CPU读取某数据的时候,Cache中存在或不存在,当CPU写入某数据时,Cache中存在或不存在。用专业的说法就是写命中、写未命中、读命中、读未命中。专业的解释如下:
写操作:CPU要写的SRAM区数据在Cache中已经开了对应的区域,这就叫写命中(Cache hit);
写未命中:CPU要写的SRAM区数据在Cache中没有开辟对应的区域,这就叫写未命中(Cache Miss);
读命中:CPU要读取的SRAM区数据在Cache中已经加载好,叫读命中(Cache hit);
读未命中:CPU要读取的SRAM区数据在Cache中没有加载好,叫读未命中(Cache Miss);
所以为了保证CPU能快速读写想要的数据,那么就需要保证Cache要有足够高的命中率,尽量减少Cache Miss。同样这是一个需要长时间积累经验的过程。
在单片机使用Cache后,再读取数据那么就有路线1、路线3两条路可走,如果Cache中直接有需要的数据(读命中),那么直接走路线3即可完成数据读取。如果Cache中没有需要的数据(读未命中),那么就分两种情况了:
①直接走路线1,从SRAM中直接将需要的数据读取出来,不使用Cache,这个方式被称为read through。
②走路线3,等待Cache将数据从SRAM中加载出来,在Cache中开辟对应的数据空间,以后直接从Cache中拿数据就行,这个方式被称为read allocate。
如果单片机需要去写数据,那么分的情况就更多了,写命中和写未命中都分为了两种情况,两条线路,写命中的两种情况如下:
①直接写到SRAM中并同时写到更新Cache里面的数据,也就是STAM和Cache同时更新,也就是同时走了路线1和路线3,这种方式被称为write through。但这种方式很难体现出来Cache。
②数据只写到Cache里面,只在数据被清空(这个操作下面会讲)出Cache时,数据才会被写入到SRAM里面,也就是只走了路线3,等到Cache中的数据被清空,才进行路线2。这种方式被称为write back。
写未命中的两种情况如下:
①等待数据先从SRAM中加载到Cache里面,然后对Cache中的数据进行写入,最后更改到SRAM里面。也就是先走路线2,再走路线3,最后再走路线2。这种方式被称为write allocate。
②直接写入到内存中,不使用Cache,也就是只走路线2,这种方式被称为no write allocate。
这里注意一下,这要待allocate的方式,那么都会在cache中开辟相应的位置给这个数据,也就是一般只需要开辟一次位置,以后就都能从cache中拿数据。
以上说的都是DCache即数据高速缓冲,Cache分为指令Cache和数据Cache,指令Cache一般不用操心各种问题,在使用时一般都直接配置为使能,保存默认配置即可。
3、Cache的工作策略
上面提到了Cache的工作原理,内核根据这些工作原理又将Cache分为了多个工作策略,见图2.3。
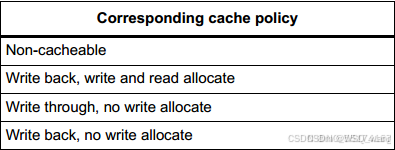
内核支持的工作策略有四种,这里逐个进行分析:
①Non-cacheable:不使用Cache,即不开启Cache,数据走的路线就是图2.2的路线1。
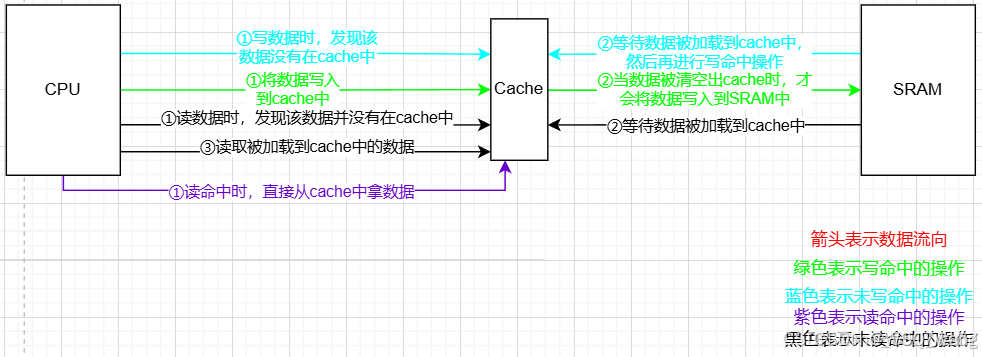
②Wrtie back,write and read allocate:当写命中时,将数据写入到cache里,当数据被清空出cache时,再将数据写入到SRAM中去;当写未命中时,等待要写的数据先加载到cache里,然后对cache中的数据进行写入,最后更改到SRAM里;当读未命中时,等待cache从SRAM中加载出来需要的数据,然后再从cache中拿数据,这个过程如图2.4所示。
③Write through,no write allocate:当写命中时,CPU将数据直接写入到SRAM和cache中;当写未命中时,直接将数据写入到SRAM中;当读数据时,不在cache中开辟空间,过程可见图2.5。
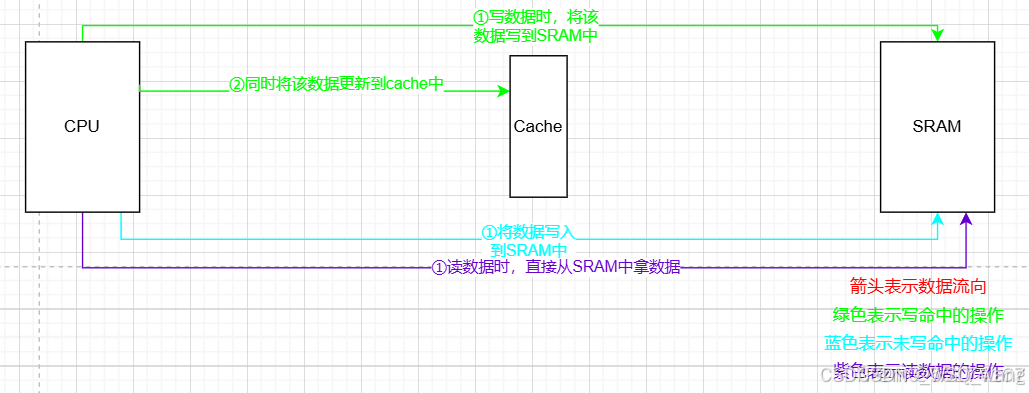
④Write back,no write allocate:当写命中时,当写命中时,将数据写入到cache里,当数据被清空出cache时,再将数据写入到SRAM中去;当写未命中时,直接将数据写入到SRAM中;当读数据时,不在cache中开辟空间,过程可见图2.6。
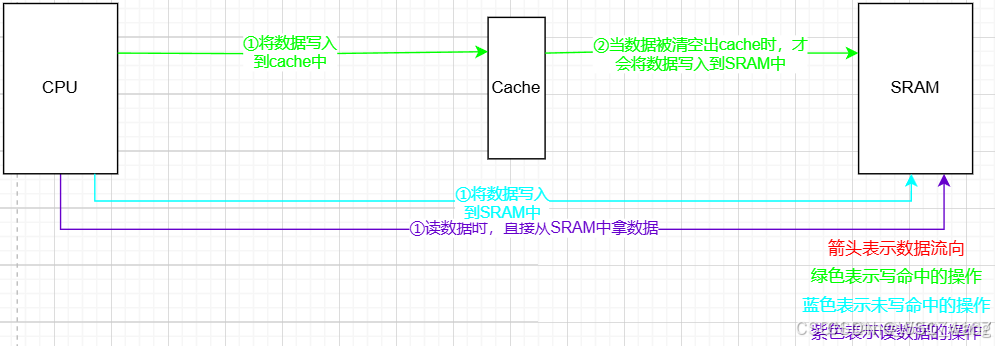
综合这四种工作策略可知,工作策略1应该是读写中最快的,因为在写数据未命中时,CPU是等待cache将SRAM中的数据进行加载,只不过这一次加载,以后都会省略掉该数据的加载时间,之后每次写数据,只要cache空间足够,那理论上每次写数据都会命中;在读数据时,也是只需要等待第一次读数据的时间,之后每次只要对cache操作即可,比直接操作SRAM快了一倍多(cache的频率是480MHz,SRAM的工作频率是200MHz)。这也是最常用的cache工作策略。
4、数据一致性问题
根据上面分析cache可以发现,cache存在一个问题,例如在图2.2中分析,如果cache在1秒的时候从SRAM里面拿到一个DMA转运的数据,然后DMA在1.002秒的时候又存了一个新的数据在SRAM中,但cache并没有立即缓存,CPU在1.0023秒的时候在cache中寻找了这个数据,发现有缓存,那么就直接从cache中进行了加载并处理。这个流程可以看出CPU处理的是1秒的时候的数据,而不是最新的1.002秒时的数据,那么就造成了处理的数据与存储的数据不一致的问题。这就是使用cache时避免不了的"数据一致性"问题。
这一问题能够通过软件去解决优化,也能通过一些硬件来进行解决,后面会根据新硬件、新操作的引入,来逐步讨论解决这个问题的方法。
5、cache的基本操作
cache作为一个高速缓存,它同样也提供了四种基本操作,即通过软件对cache进行使能,禁止,清空,或者无效化。这四种操作的解释如下:
①使能,禁止:这个就是对cache很经常的一个操作,开启还是关闭cache,使能的时候就是开启,禁止的时候就是关闭;
②清空:将cache中已缓存的数据进行清空,也可以理解为将cache中的数据进行了释放,并将被清空的数据更新到SRAM中去;
③无效化:将cache中的数据进行无效化处理,也就是丢弃掉这个数据,然后从SRAM中再进行加载新的数据。
经过清空和无效化的处理,那么就可以去通过软件去解决数据一致性的问题,比如,我在处理某个DMA转运的数据前,对cache进行一次无效化处理,也就是重新从SRAM中加载新的数据,这也就极大的缓解了数据一致化问题。由于这个操作中间也是有cache参与,所以这个数据肯定还是有延时的,但确实已经能很大的缓解这一问题了,但还会存在脏读。这也是解决数据一致性问题最常用的方法了。
三、MPU
1、MPU简介
MPU的全称是Memory protection unit,直译过来就是内存保护单元,它是单片机内核的一个硬件,不属于单片机外设(硬件IIC、看门狗、GPIO什么的都是单片机外设),所以在参考手册中并没有写这个硬件,需要查看"H7编程手册"才会找到这个硬件,虽然F1、F4系列的芯片上也存在这个硬件,但是基本用不上,但到了H7系列,这个硬件就要实实在在用上了,因为要去设置cache了,STM家族支持

这个MPU有什么作用呢,是用来干什么的,在文件"an4838-managing-memory-protection-unit-in-stm32-mcus-stmicroelectronics.pdf"中,可以看到图3.2,对MPU的作用进行了一个小小的总结。

MPU有三个作用,其作用一是可以这样理解,在我们使用RTOS操作系统时,各个任务与各个任务之间有数据隔离什么的,一般都是靠MPU去进行完成的;其作用二是可以将某一区域定义为不可执行的,这样可以防止代码注入攻击。我对这一条的理解就是将某一区域设置为不可执行,也就是只读的,这样黑客注入到该地方的代码就无法运行,也就防止了注入攻击,感觉要配合着项目完成后的map文件再去进行配置;其作用三就是与cache关系非常相关的,能够通过对MPU的配置,来实现各种cache的配置效果。
MPU的目的就是让存储资源能够被内核高效且可靠的进行访问。
2、MPU工作原理
前面简介提到MPU的目的就是让存储资源能够被内核高效且可靠的进行访问,这也是MPU被设计出来的目的。也就是说MPU设计的初衷就是作为MCU数据的管理员,它能够管理每一块数据的访问、管理权限,针对不同的数据赋予不同的管理权限,即系统的数据能读、不能改、能执行,用户的数据能读、能改、不能执行,等等这种类似的要求。所以MPU的工作原理其实就是核对访问数据的请求是否有权限去获取数据,是以什么样的方式、渠道去获取数据等等。
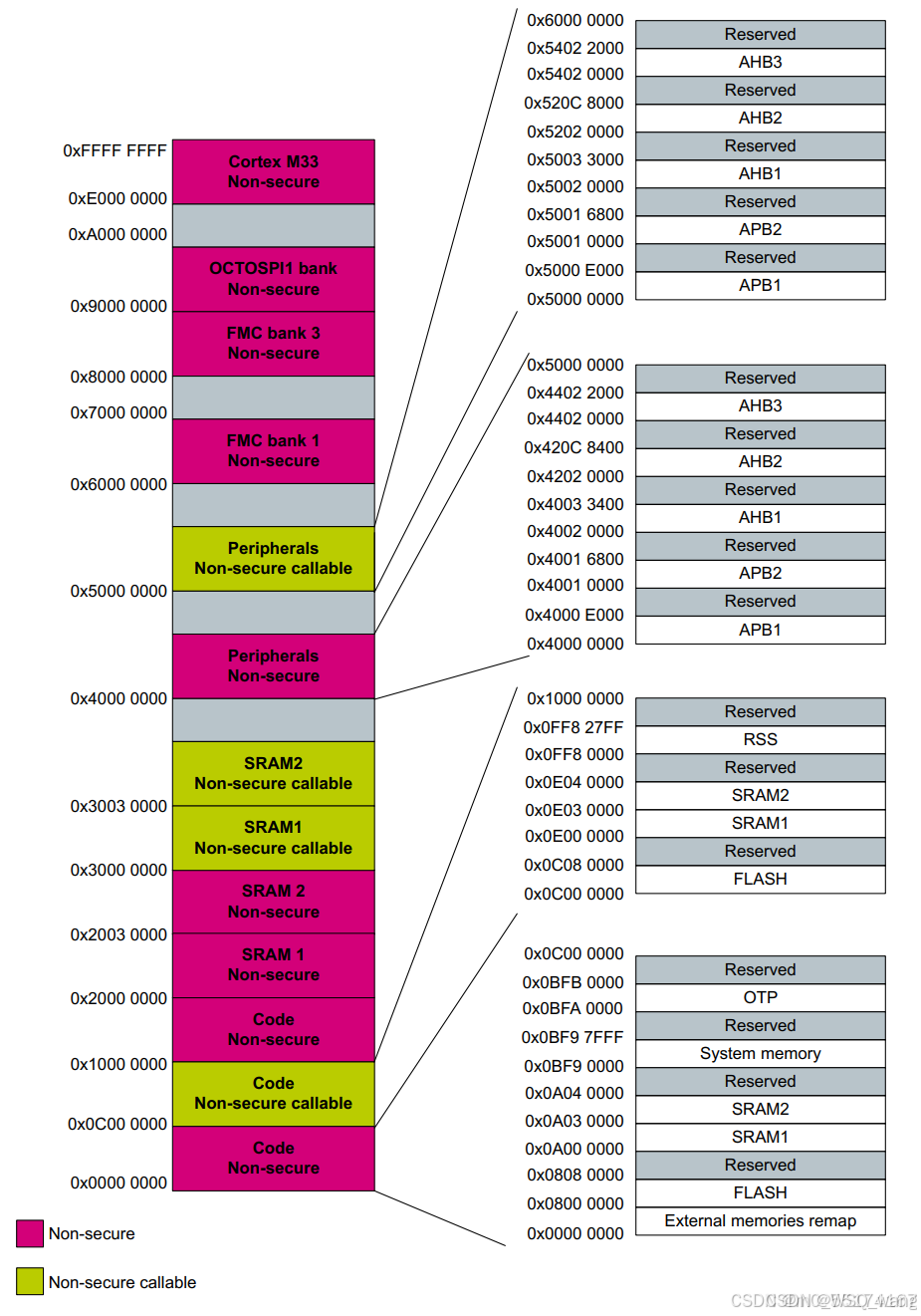
既然要管理数据那就肯定要知道内核地址映射,H7的内核地址映射如图3.4。
3、MPU配置内存区域的访问属性
MPU能配置三种内存类型,即Normal memory(普通内存),Device memory(设备内存),Strongly ordered memory(强有序内存)。其性能按照这个顺序一次降低,这三个名词的解释如下:
Normal memory:直译为普通内存,CPU以最高效的方式加载和存储数据,它对内存区的加载和存储不一定按照代码的顺序执行。经常在配置ROM、FLASH、SRAM时使用该属性。
Device memory:直译未设备内存/外设内存,加载和存储按照严格次序进行,确保寄存器按照正确顺序设置。经常在配置外设时使用该属性。
Strongly ordered memory:直译未强有序内存,程序完全按照代码顺序执行,CPU会等待当前加载存储执行完毕后才执行下一条指令,导致性能下降。
三种属性对应的访问路径情况如图
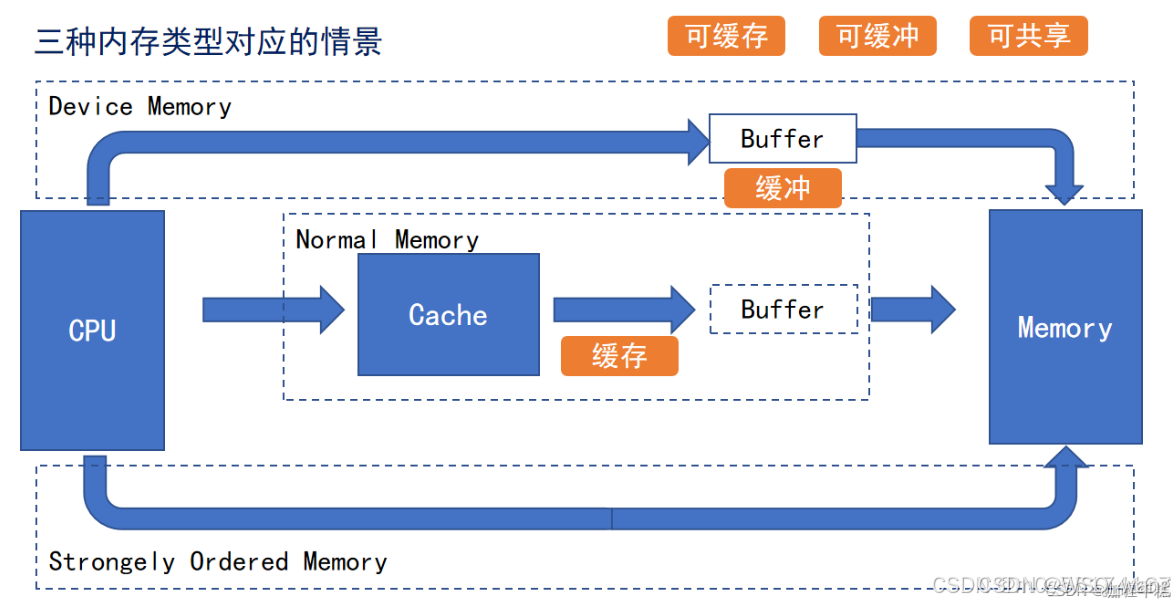
图中的Memory可以当作SRAM去理解。图中可以看到只有Normal Memory模式才使用到了Cache,其余的两种模式并没有使用到。图中可缓冲指的就是开启了Buffer,可缓存就是开启了Cache,可共享的意思笔者也没弄明白,硬汉和正点原子都说是在H7芯片中开启共享基本上等同于关闭Cache,但都没有详细讲,希望有了解的读者能解惑,但原子哥说开启共享后能解决数据一致性的问题,这点我没有验证过,我也不能肯定。
这三种属性可能解释的太笼统了,达不到完全理解的目的,我建议是先记住,然后了解他们的性能强弱就足够了。再深入的我也没去了解和学习过了,如果想再深入了解,我觉得应该去找内核类的资料去看,像该文章上传的文件中可能就有对这些的详细介绍。
通过可共享、可缓冲、可缓存和Cache的策略配置能够决定Cache、MPU和内存之间的工作方式,如图3.7所示。
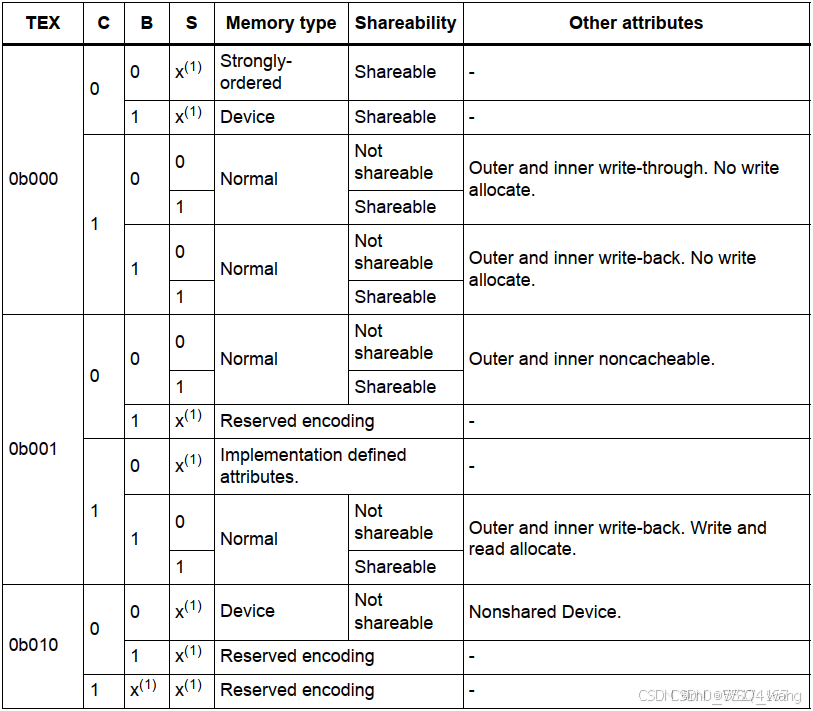
来看图3.7,TEX表示cache的策略,C、B、S分别表示可缓存、可缓冲、可共享,通过四种状态的配置可以决定采用哪种内存类型,是采用Normal、Device还是Strongly ordered,这就是对应第四列Memory type,一定要记住他们的性能是逐次降低的。第五列是否可以共享,这个属性笔者也不是很懂,但是可以看到,它总是与第四列相关。最后一列可参考cache的工作策略那一节去分析,其中只有一个write-back前面没有提到,直译过来就是回写操作,就是指我们在写入数据的时候如果未命中,那么直接将数据写入到了SRAM中,再由cache去将这个数据从SRAM中更新到cache中,这就是回写操作。
从第四列可以看到,有很多个Normal模式,这些模式中也有性能强弱之分,首先肯定是打开可共享、关闭缓冲、关闭缓存的性能最弱,也就是第五列的第五行的Normal性能最弱,最强的一定是开启缓存、开启缓冲、关闭共享的性能最强,也就是第五列的第八行的Normal性能最强。但是具体项目什么需求,还是需要结合需求去分析,如果追求数据一致性,那么肯定是开启可共享要好很多。
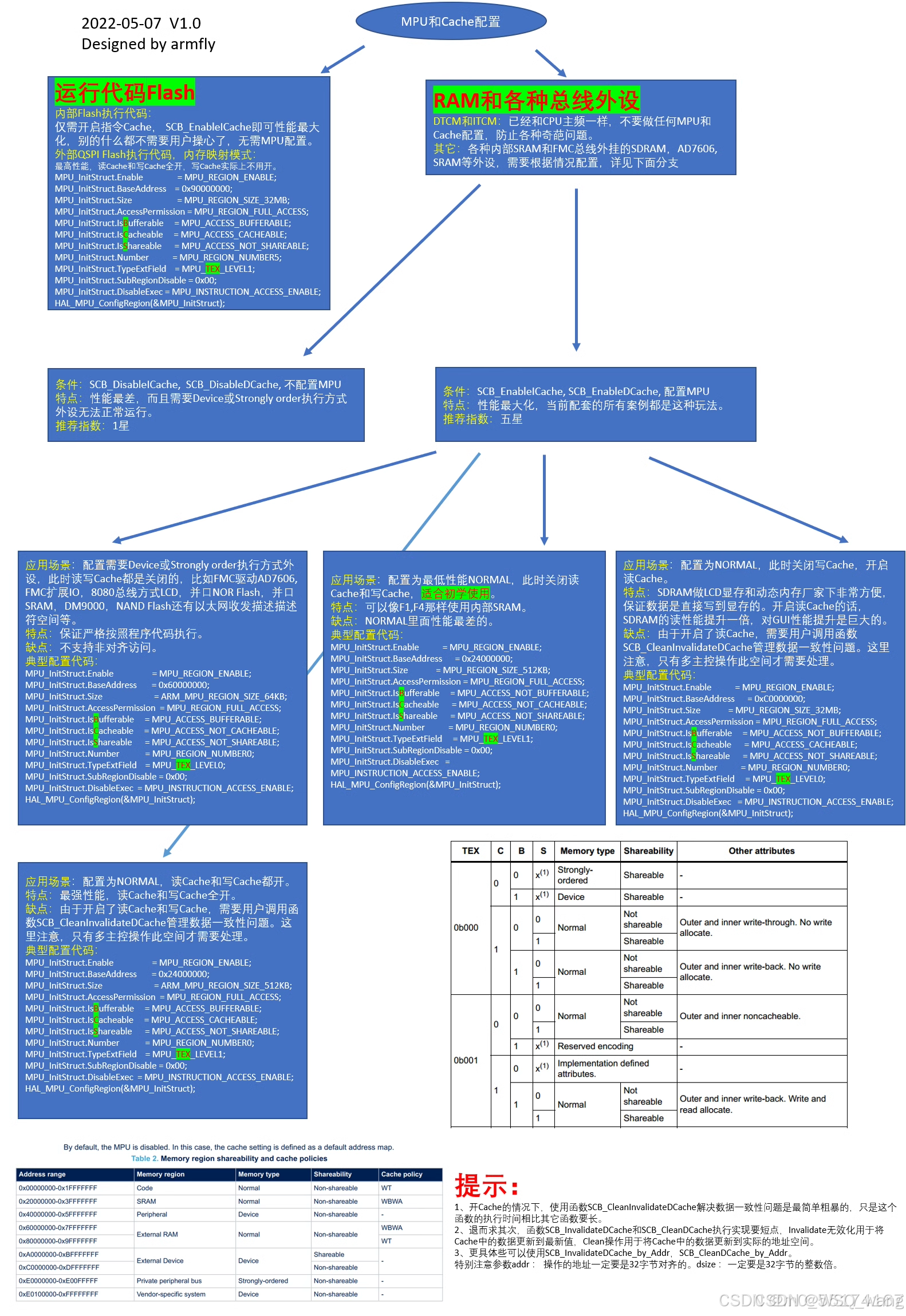
四、通过CubeMX来配置MPU和Cache
1、CubeMX配置MPU的属性简介
打开CubeMX后,进行图4.1的操作便能进行MPU的相关配置:
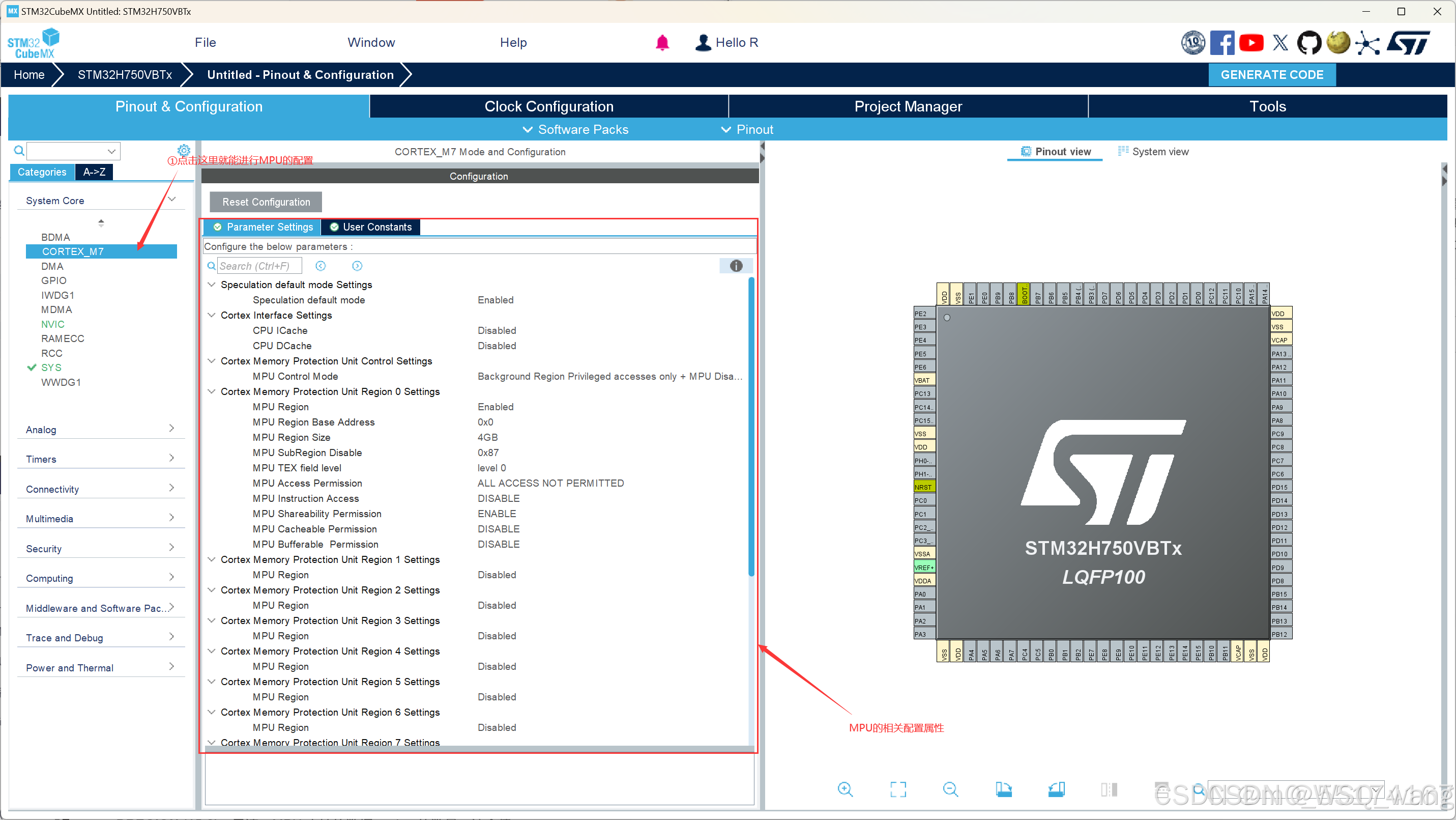
接下来的思路是按照这个CubeMX中的各个配置依次往下进行解释。
2、Speculation default mode(推测默认模式)
第一个属性是Speculation default mode Settings,直译过来就是投机违约,是不是看到这个直译名称头大,作者也是,这是个什么玩意,翻译过来如此抽象,我后续查询到它还可以被称为"推测默认模式"。该属性可以解释为,该模式允许CPU在执行指令时进行一种优化,即Speculation。它是一种执行机制,它允许处理器在不知道某些操作的结果时开始执行后续操作。这可以提高指令执行的效率,因为处理器可以在等待操作结果的同时继续执行其他任务。但使用不当会导致单片机运行出错。也就是说它允许ICache提前去加载指令数据,但这个指令数据是猜着加载的,例如有个判断条件if…else…,CPU运行到这里之前是不知道要执行if里面的还是执行else里面的语句,所以它会进行推测(这个过程我也不了解),最终按照自己的推测结果去进行加载。
它会预测就说明有可能会预测失败,也就会带来系统的不稳定性,但确实会增强单片机的运行效率。它对运行速率的影响,我测试了我的屏幕,发现打开与关闭,帧数上下差不了1帧。
3、Cortex Interface Settings(接口设置)
这个里面的设置其实就是用来配置是否使能ICache和DCache,那咱们使用MPU就是为了使用Cache,所以必然会让ICache、DCache使能。
4、Cortex Memorty Protection Unit Control Setting(内存保护单元控制设置)
该设置有如图4.2,有五项设置。

其实这个本质上是在设置MPU_CTRL寄存器,在文件"STM32H7编程手册.pdf"中可以找到该寄存器的介绍,如图4.3所示。
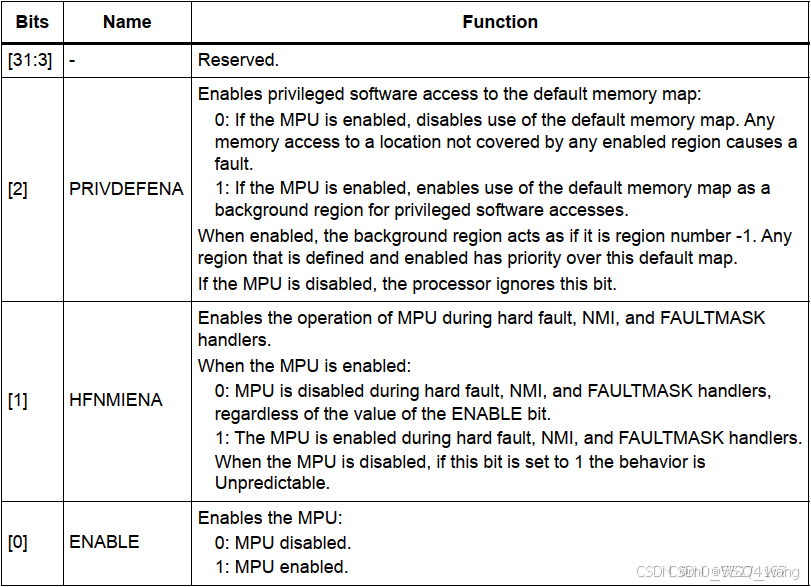
可以看到该寄存器能设置的其实只有三位,ENABLE位不必多说,就是是否开启MPU,0就是关闭,1就是开启。
HFNAMIENA是指在hard fault,NMI,FAULTMASK handlers中是否是能MPU操作。当MPU使能时:当配置HFNMIENA为0时,MPU在hard fault、NMI和FAULTMASK handlers错误处理过程中禁用;当配置HFNMIENA为1时,MPU在hard fault、NMI和FAULTMASK handlers错误处理过程中使能。当MPU使能失能时,如果HFNMIENA为1,则MPU行为不可预测。
这里的hard fault、NMI和FAULTMASK handlers错误处理可以理解为在这些函数中,这个FAULTMASK根据我查询的资料可知它是一个寄存器,它能够开启、关闭全局中断。其余两个在MX生成的工程中都有对应的错误函数,如图4.4。
PRIVDEFENA可以理解为是否开启内存区域的默认配置,这个默认配置就像一个背景板,如果开启这个背景板(PRIVDEFENA=1),那么去访问我们没有配置的内存区域时,就不会引起错误,如果不开启(PRIVDEFENA=0),那就会引起错误,跳转到对应的错误处理函数中。如果MPU失能,则该位不起作用。
由以上两种标志位,便能组成四种控制模式选项:
Background Region Access Not Allowed + MPU Disable during hard fault , NMI and FAULTMASK handlers (PRIVDEFENA = 0 + HFNMIENA = 0)
Background Region Access Not Allowed + MPU Enable during hard fault , NMI and FAULTMASK handers (PRIVDEFENA = 0 + HFNMIENA = 1)
Background Region Privileged access only + MPU Disable during hard fault , NMI and FAULTMASK handlers (PRIVDEFENA = 1 + HFNMIENA = 0)
Background Region Privileged access only + MPU Enable during hard fault , NMI and FAULTMASK handers (PRIVDEFENA = 1 + HFNMIENA = 1)
一般最常用的是第三种。
5、Cortex Memory Protection Unit Region X Settings(内存保护单元区域X设置)
由于本文章使用的是M7内核的芯片,所以它有16个单元区域可以设置,所以X=16,首先先看这里的配置,如图4.5所示。
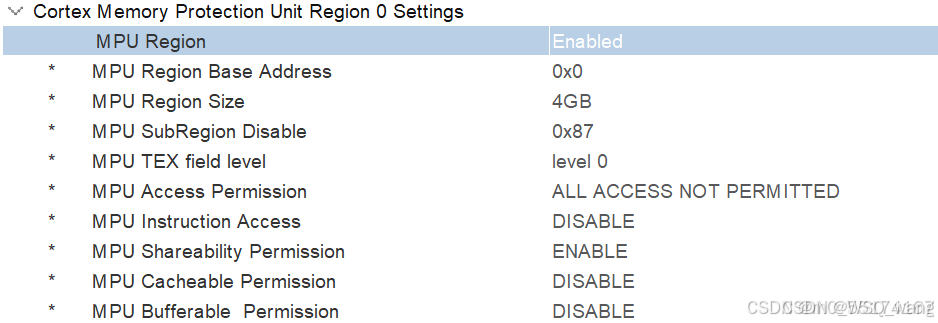
首先第一项,MPU Region,这个一定要是Enable,这没啥可说的。
第二项MPU Region Base Address,这个是在配置保护区域的基地址,这个地址选择可以参考图3.4,例如我这里想要配置SRAM,那么通过图3.4可知,起始地址就是0x20000000,所以该配置就是0x20000000,这个可以根据最终生成的map文件去分析你具体需要的地址。
第三项MPU Region Size,这个配置的是你需要设置多大的区域大小,即你从MPU Region Base Address往后多大区域,像如果配置SRAM,从图3.4可知,SRAM的大小为0x200000000,也就是512KB,所以这里选512KB。
注意:在设置Address时一定要是32字节对齐的。在设置Size时,一定要是32字节的整数倍。
第四项MPU SubRegion Disable,用于标志特定子区域是启用还是禁用。前面提到每个区域还可以被分为8个大小相等的子区域去配置,这里可以让某一个子区域禁用,不启用。所以取值范围是0x0到0xff。0表示使能,1表示失能。一般都会配置为0x0,这个主要看需求。
第六项MPU Access Permission,用于配置MPU的区域访问权限,从图4.6可以看到共有六种选项可选。这里的配置参考文件"an4838-managing-memory-protection-unit-in-stm32-mcus-stmicroelectronics.pdf"中MPU_RASR寄存器可知,就是在配置AP位,如图4.7。可以看到这里大部分的配置都是在配置这个寄存器。有时间可以看一下这个寄存器,这个寄存器的配置对于MPU非常重要。


从MPU_RASR寄存器的描述中可知,AP位的配置如图4.8。
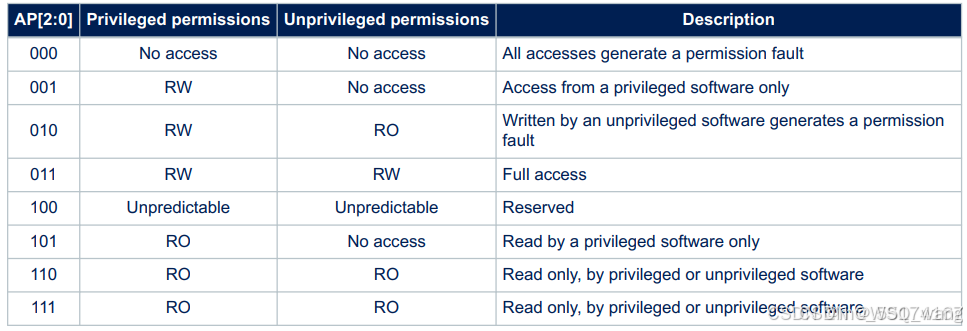
从图4.8可知,一共有6种区域访问权限可以设置,即特权级、用户级都不可读、不可写,对应000;特权级可读、可写,用户级不可读不可写对应001;010、011、101、110、111都同理,100则作为保留位。这些模式中,011是使用最常见的(全访问),即特权级和用户级都能够进行读写。如果采用的是010设置,即特权级可以读写,用户级只读,如果用户级还是要往该区域写入数据,那么就会触发错误异常MemManage。
第七项MPU Instruction Access,这个用于配置该区域中的数据是否可以执行,也就是该区域中的数据是否可以像执行代码一样去运行它们,类似于Linux中,文件会有一个可运行权限,这个就是用于设置这个的。
第五项是MPU TEX field level,用于配置Cache的策略,这个策略可以看第二章第3小节的讲述,这个有三种策略配置,它需要和第八项、第九项、第十项共同去配置。
第八项是MPU Share ability Permission,是否可共享,这个共享的意思笔者也没弄明白,硬汉和正点原子都说是在H7芯片中开启共享基本上等同于关闭Cache,但都没有详细讲,希望有了解的读者能解惑,但原子哥说开启共享后能解决数据一致性的问题,这点我没有验证过,我也不能肯定。我一般会设置为失能。
第九项是MPU Cacheable Permission,是否开启缓存cache。配置MPU就是为了使用cache,所以这里一定是使能的。
第十项是MPU Bufferable Permission,是否开启缓冲。就是Buffer,如第三章第3小节中图所示的Buffer。
这里第五项、第八项、第九项、第十项共同决定了访问内存的配置,这个配置可以参考图3.7和图3.7的图说明。
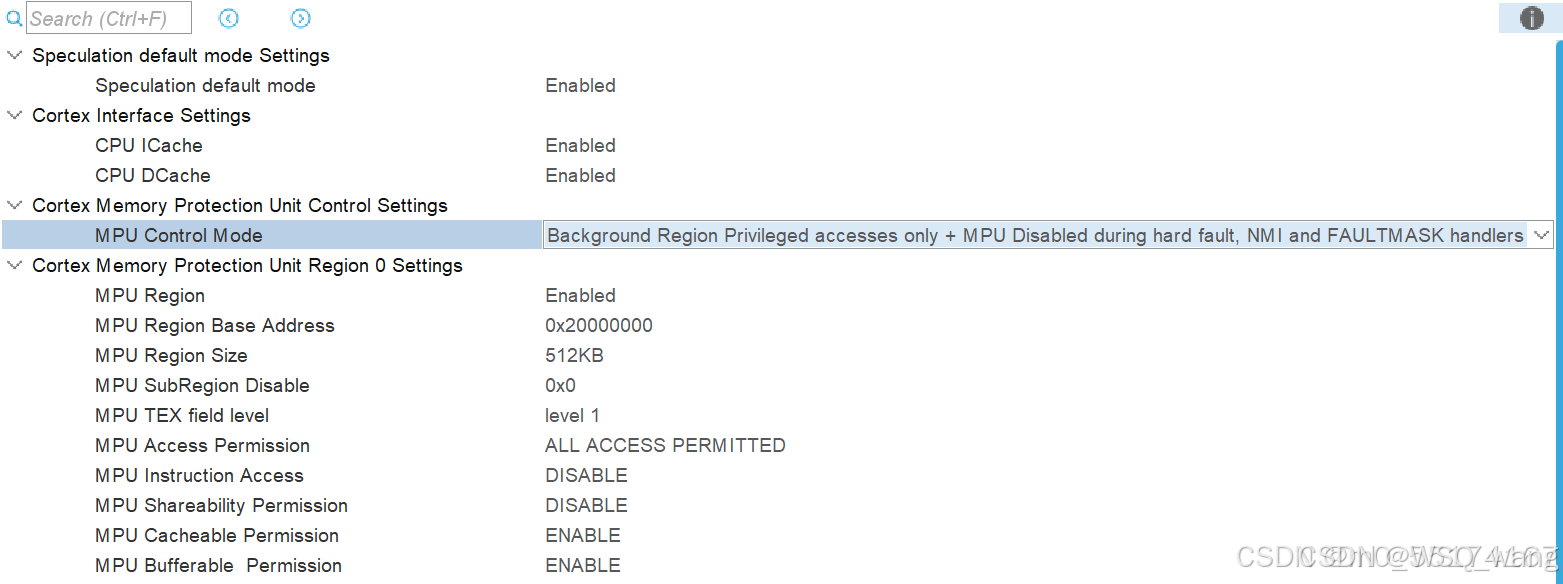
经过这些配置,也就配置好了MPU和cache,这样一定能大大的提高芯片性能。这里再举个例子,例如我要将整个SRAM区域都设置起来,采用最高性能的访问速度,那么我的配置应该如图4.9所示。
五、解决数据一致性的操作
在使用cache时遇到的最多的就是数据一致性问题,前面提到cache的基本操作由无效化和清空,CMSIS软件包也提供了相关函数,如下图所示。
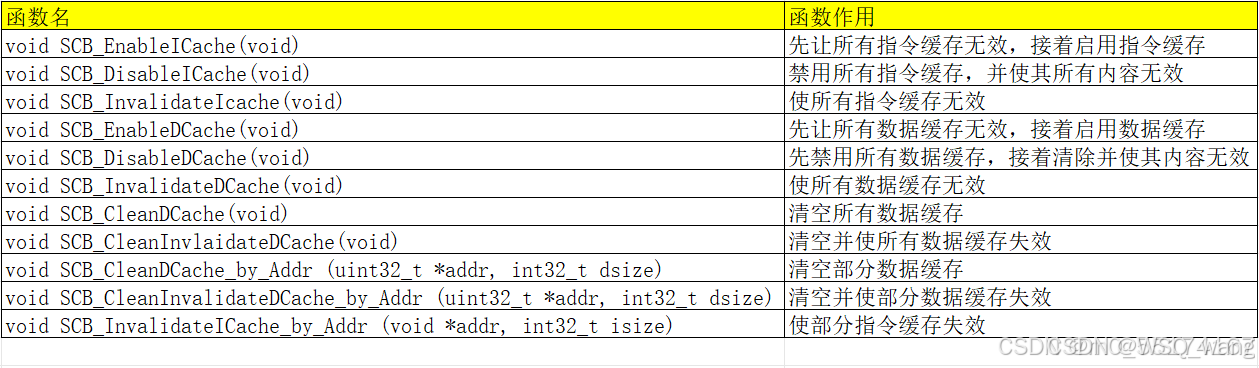
这些函数使用的时候比较简单,可以参考前面写的数据无效化和清空操作,经常需要解决DCache数据一致化问题,ICache一般不用去管,刚开始的时候可以多用"SCB_CleanInvlaidateDCache"函数,只需要在你使用和DMA共享的数据时去调用一下这个函数即可,最后三个函数建议使用娴熟的时候再开始使用。
六、总结
其实设置MPU和cache最需要注意的就是芯片的内存分布,根据芯片的内存分布去划分要配置的区域,最终根据图3.7去选择性的配置读取内存性能即可。硬汉哥也总结了一个非常不错的图片,我就直接放到这里吧,如果理解了MPU和cache,那一定能看懂这个图片。
作者杂感
这篇文章写的时间太长了,断断续续写了大概俩星期,边写边查资料,导致逻辑性不算很强,更像是想到啥就写啥一样,挺不好意思的,但是功力有限,也是我第一次接触内核,很多知识点并不是很清楚,内核的设计也只是接触皮毛,所以我感觉本笔记写的很乱,排版不好,但是已经尽力去讲好MPU和cache了,希望大家发生本笔记的错误时,及时告知我,我好修改,谢谢大家。
一些名词的解释
代码注入攻击
这个名词单纯是我自己的理解,不知道理解正确与否,如有理解问题,请联系我改正,谢谢。
我针对单片机的代码注入攻击进行查找,查询到的讨论很少,但针对电脑的代码注入有很多,我就想,单片机不也是电脑吗,那原理应该都差不多。大致讨论的意思就是让原本用户该的信息作为代码去执行,比如你玩游戏时,让你给自己起一个游戏ID,这条ID数据会被上传到服务器上并被解析,你上传的ID叫做"printf(“Hello World”)“,原本这个ID该被当作字符串去被处理,但通过一些手段让你这条数据被当成了代码执行了起来,这样就达到了代码注入攻击的效果。但现在服务器管理员通过MPU将SRAM的属性设置成了"不可执行”,也就是你上传的数据在硬件层面就给锁死成了字符串,不可能被单片机给当作代码执行,这样MPU就阻止了代码注入攻击。
特权模式与用户模式
这两个模式是取决于CONTROL寄存器来实现切换的。这两个模式就相当于是Linux中的root用户和其他用户的区别,具体解析可看文章:
【实战经验】理解与应用MPU的特权与用户模式 - 资料馆 - 论坛-意法半导体STM32/STM8技术社区
问题(等待大家反应、讨论)
问:我有一个问题不太懂,就是C语言中volatile关键字,在使用这个关键字的时候,是从cache中拿数据还是是从SRAM中拿的数据?如果是从SRAM中拿的数据,那么是不是就能解决数据一致性问题?
答:这个问题是我写文章的时候想到的,写完这篇文章要投入到下一个项目中,所以这个问题我并没有做具体实验,我看了两篇文章的讲解,感觉两篇文章讲的都有道理。文章链接如下:
嵌入式C语言关键字volatile以及cache对数据一致性的影响_arm cache对volatile指令的影响-CSDN博客
浅析c语言的volatile关键字及数据一致性_c语言共享内存如何保证数据一致性呢-CSDN博客
两位作者得出的结论都不一样,这我就蒙圈了,希望各位读者能帮忙解答一下。

















 3334
3334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









