







系列文章目录
1.Cache相关知识介绍
2.STM32H7的Cache应用
目录
前言
使用M7内核的MCU,为提升性能,此系列文章记录对STM32H7的MPU和Cache的学习。
本文主要写的关于STM32H7上的Cache配置策略及应用
资料链接:Cache相关资料手册资源-CSDN文库
相关资料说明
AN4838这本手册里有对MPU的介绍、MPU的相关寄存器配置、储存器类型的介绍(Memory types)
AN4839这本手册介绍Cache的相关知识,M7内核关于Cache的API函数、stm32h7和f7的默认配置、WB、WT等知识
对于Cache和MPU的配置参考STM32H7编程手册的MPU access permission attributes章节,表格71很完善的介绍了。
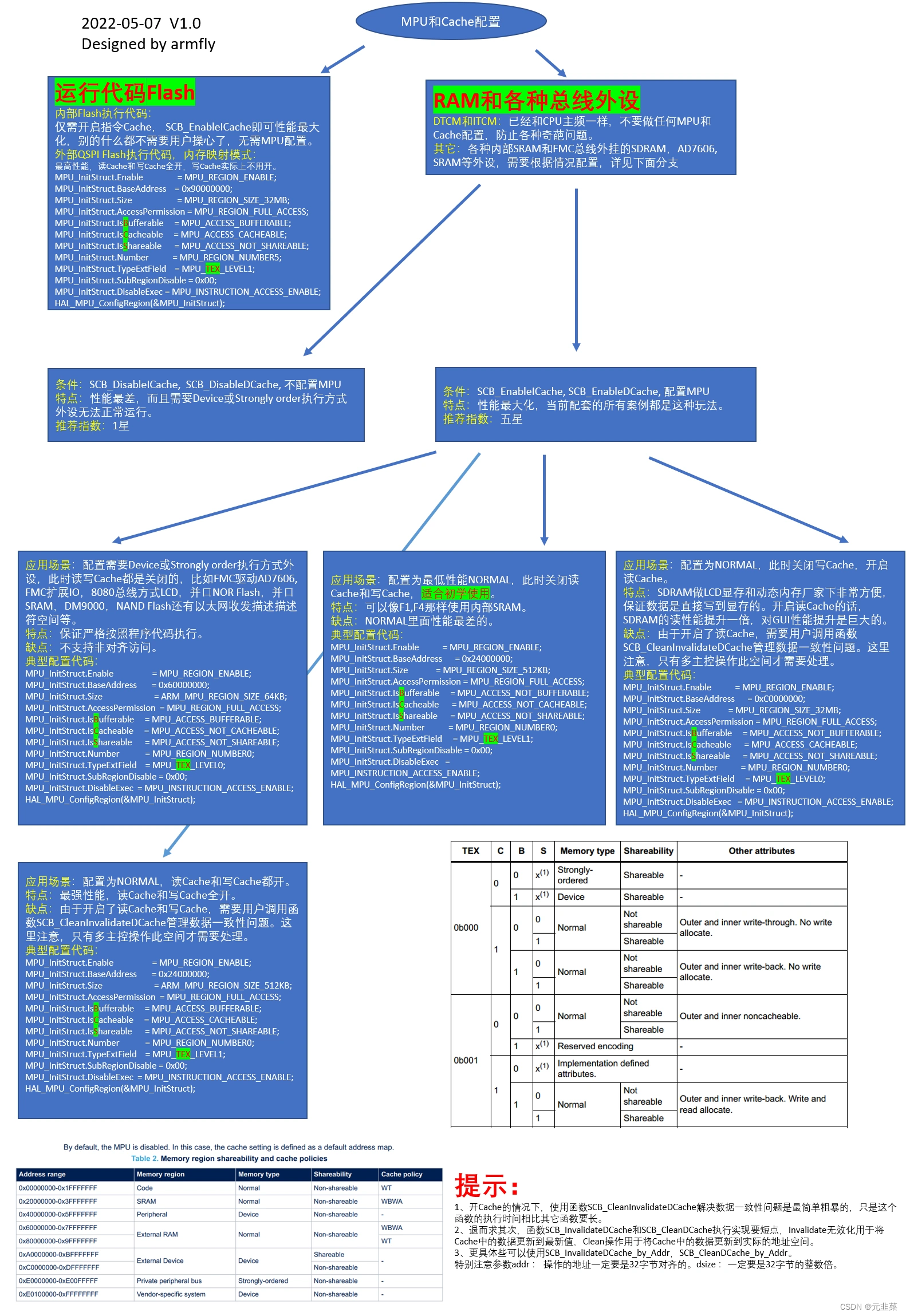
一、Cache支持的配置
1.1 配置总览
Cache的配置是通过MPU来设置的, 在STM32H7的编程手册中找到如下表:

各个Bit的含义:TEX是用来配置Cache策略的
C是开关Cache、B是缓冲用来配合Cache设置,S是开关共享,是用来解决多总线或者多核访问时的同步问题(开启共享等同于关闭Cache)(TEX=010基本上不用,不关注)
TEX配置的Cache策略如下:即这个是配置WB、WT、WA、RA模式

1.2 配置性能对比
MPU设置的存储器类型(memory types):Normal memory > Device memory >Strongly ordered memory
关于三种存储器类型的描述:(AN4838的Memory types章节)

注:M7内核只要开启了Cache,read allocate就是开启的。
配置方法性能最强:Cache策略选择WA、RA、WB模式(即TEX=0b001),开启缓冲区B,关闭共享S。这种相当于读写Cache都开启了,需要注意数据不一致问题。
例:配置AXI SRAM的为性能最强
/* 配置AXI SRAM的MPU属性为Write back, Read allocate,Write allocate */
MPU_InitStruct.Enable = MPU_REGION_ENABLE;
MPU_InitStruct.BaseAddress = 0x24000000;
MPU_InitStruct.Size = MPU_REGION_SIZE_512KB;
MPU_InitStruct.AccessPermission = MPU_REGION_FULL_ACCESS;
MPU_InitStruct.IsBufferable = MPU_ACCESS_BUFFERABLE;
MPU_InitStruct.IsCacheable = MPU_ACCESS_CACHEABLE;
MPU_InitStruct.IsShareable = MPU_ACCESS_NOT_SHAREABLE;
MPU_InitStruct.Number = MPU_REGION_NUMBER0;
MPU_InitStruct.TypeExtField = MPU_TEX_LEVEL1;
MPU_InitStruct.SubRegionDisable = 0x00;
MPU_InitStruct.DisableExec = MPU_INSTRUCTION_ACCESS_ENABLE;
HAL_MPU_ConfigRegion(&MPU_InitStruct);
//其中的MPU_InitStruct.TypeExtField = MPU_TEX_LEVEL1; 对应TEX
// MPU_InitStruct.IsBufferable = MPU_ACCESS_BUFFERABLE;对应B
// MPU_InitStruct.IsCacheable = MPU_ACCESS_CACHEABLE;对应C
// MPU_InitStruct.IsShareable = MPU_ACCESS_NOT_SHAREABLE;对应S性能最弱的:关闭Cache(TEX为000),关闭缓冲区B,开启S共享。这种性能最差,访问的较慢。
例:配置AXI SRAM性能最差
/* 配置AXI SRAM的MPU属性为Write back, Read allocate,Write allocate */
MPU_InitStruct.Enable = MPU_REGION_ENABLE;
MPU_InitStruct.BaseAddress = 0x24000000;
MPU_InitStruct.Size = MPU_REGION_SIZE_512KB;
MPU_InitStruct.AccessPermission = MPU_REGION_FULL_ACCESS;
MPU_InitStruct.IsBufferable = MPU_ACCESS_NOT_BUFFERABLE;
MPU_InitStruct.IsCacheable = MPU_ACCESS_NOT_CACHEABLE;
MPU_InitStruct.IsShareable = MPU_ACCESS_SHAREABLE;
MPU_InitStruct.Number = MPU_REGION_NUMBER0;
MPU_InitStruct.TypeExtField = MPU_TEX_LEVEL0;
MPU_InitStruct.SubRegionDisable = 0x00;
MPU_InitStruct.DisableExec = MPU_INSTRUCTION_ACCESS_ENABLE;
HAL_MPU_ConfigRegion(&MPU_InitStruct);二、四大配置
注:以下配置的方法均是根据编程手册的表格91来
2.1 Non-cacheable
这种配置即关闭了Cache,就是正常的读写操作,无任何优化
对应的MPU配置如下:
TEX = 000 C=0 B=0 S=忽略此位,强制为共享
TEX = 000 C=0 B=1 S=忽略此位,强制为共享
TEX = 001 C=0 B=0 S=0
TEX = 001 C=0 B=0 S=1
2.2 透写、读分配、无写分配(WT、RA)
(1)使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会同时写到Cache里面和SRAM里面;如果没有,就用到配置no write allocate了,意思就是CPU会直接往SRAM里面写数据,而不再需要在Cache里面开辟空间了。(如果是write allocate就会在Cache里面开辟一块空间)
在写Cache命中的情况下,这个方式的优点是Cache和SRAM的数据同步更新了,没有多总线访问造成的数据一致性问题。缺点也明显,Cache在写操作上无法有效发挥性能。(写操作无提升)
(2)使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
(3)对应两种MPU配置如下:
TEX = 000 C=1 B=0 S=1
TEX = 000 C=1 B=0 S=0
2.3 回写、读分配、无写分配(WB、RA)
(1)使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会写到Cache里面,而不会立即更新SRAM;如果没有,就用到配置no write allocate了,意思就是CPU会直接往SRAM里面写数据,而不再需要在Cache里面开辟空间了。
安全隐患,如果Cache命中的情况下,此时仅Cache更新了,而SRAM没有更新,那么DMA直接从SRAM里面读出来的就是错误的。(数据一致性问题)
(2)使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
(3)对应两种MPU配置如下:
TEX = 000 C=1 B=1 S=1
TEX = 000 C=1 B=1 S=0
2.4 回写、读写分配(WB、RA、WA)
(1)使能了此配置的SRAM缓冲区写操作
如果CPU要写的SRAM区数据在Cache中已经开辟了对应的区域,那么会写到Cache里面,而不会立即更新SRAM;如果没有,就用到配置write allocate了,意思就是CPU写到往SRAM里面的数据,会同步在Cache里面开辟一个空间将SRAM中写入的数据加载进来,如果此时立即读此SRAM区,那么就会有很大的速度优势。(这就是与无写分配的不同,有写分配就会同步开辟一块空间)
安全隐患,如果Cache命中的情况下,此时仅Cache更新了,而SRAM没有更新,那么DMA直接从SRAM里面读出来的就是错误的。
(2)使能了此配置的SRAM缓冲区读操作
如果CPU要读取的SRAM区数据在Cache中已经加载好,就可以直接从Cache里面读取。如果没有,就用到配置read allocate了,意思就是在Cache里面开辟区域,将SRAM区数据加载进来,后续的操作,CPU可以直接从Cache里面读取,从而时间加速。
安全隐患,如果Cache命中的情况下,DMA写操作也更新了SRAM区的数据,CPU直接从Cache里面读取的数据就是错误的。
这个配置被誉可以最大程度发挥Cache性能,不过具体应用仍需具体分析。
(3)对应两种MPU配置如下:
TEX = 001 C=1 B=1 S=1
TEX = 001 C=1 B=1 S=0
三、Cache相关API

(1)推荐使用128KB的TCM作为主RAM区,其它的专门用于大缓冲和DMA操作等。
(2)Cache问题主要是CPU和DMA都操作这个缓冲区时容易出现,使用时要注意。
(3)Cache配置的选择,优先考虑的是WB,然后是WT和关闭Cache,其中WB和WT的使用中可以配合ARM提供的如下几个函数解决上面说到的隐患问题。但不是万能的,在不起作用的时候,直接暴力选择函数SCB_CleanInvlaidateDCache解决。关于这个问题,在分别配置以太网MAC的描述符缓冲区,发送缓冲区和接收缓冲区时尤其突出。
在多个主控访问同一块内存前,可简单粗暴调用SCB_CleanInvlaidateDCache函数将Cache中的数据更新到主控制器里面,这样避免数据的不一致性。
通过WT策略,也可避免写的数据的不一致性,但是就无法提升写性能了。
开发过程多注意这个问题,使用SCB_CleanInvlaidateDCache或SCB_InvaildateDcahe尽量避免就可提高性能。
四、总结
下表摘自于安富莱电子论坛

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











