






*python3.8版本安装basemap的方法*
请先根据该参考资料进行安装: http://blog.sciencenet.cn/blog-3429473-1224163.html
注意 如果用anaconda使用的python编译环境,那么在第四步:
将下载好的.whl文件放在python安装目录的Scripts文件夹下:
- 我们应寻找的目录应该是anaconda3/envs/XXX(自己环境的文件夹)/Scripts 文件夹下
- 然后在anaconda3 prompt中自己的envs中安装basemap:
(XXX)C:/用户/DELL/anaconda3/envs/XXX(自己环境的文件夹)/Scripts>> pip install basemap-1.2.1-cp38-cp38-win_amd64.whl - 安装成功,会有以下提示:Successfully installed basemap-1.2.2
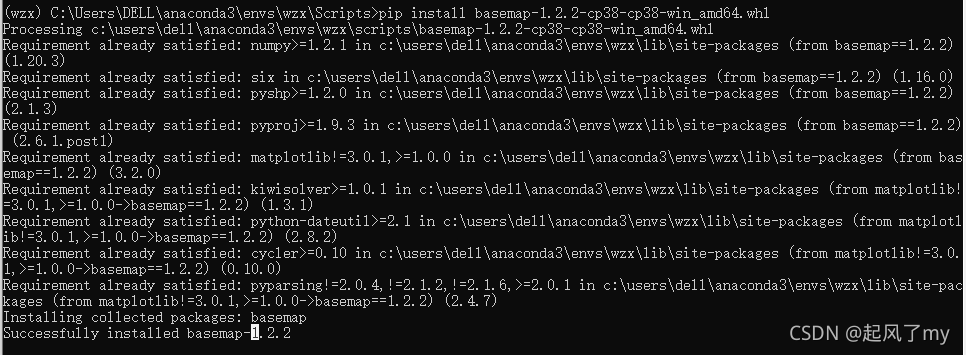
- 最后需要conda list中确认以下basemap库是否安装成功

- 安装完basemap后,可以尝试执行 from mpl_toolkits.basemap import Basemap
发现会报错FIX THE ERROR : cannot import name ‘dedent’ from ‘matplotlib.cbook’
解决方法:
参考资料 https://www.youtube.com/watch?v=MCl6qY7VqRM
是因为anaconda3/envs/XXX(自己环境名称)/lib/site-packages/matplotib/cbook/init.py文件缺少dedent的定义,用notepad打开_init_.py,搜索"dedent"

将以下复制到_dedent_regex={}的下一行,并保存文件退出,发现错误解决。
def dedent(s):
"""
Remove excess indentation from docstring *s*.
Discards any leading blank lines, then removes up to n whitespace
characters from each line, where n is the number of leading
whitespace characters in the first line. It differs from
textwrap.dedent in its deletion of leading blank lines and its use
of the first non-blank line to determine the indentation.
It is also faster in most cases.
"""
# This implementation has a somewhat obtuse use of regular
# expressions. However, this function accounted for almost 30% of
# matplotlib startup time, so it is worthy of optimization at all
# costs.
if not s: # includes case of s is None
return ''
match = _find_dedent_regex.match(s)
if match is None:
return s
# This is the number of spaces to remove from the left-hand side.
nshift = match.end(1) - match.start(1)
if nshift == 0:
return s
# Get a regex that will remove *up to* nshift spaces from the
# beginning of each line. If it isn't in the cache, generate it.
unindent = _dedent_regex.get(nshift, None)
if unindent is None:
unindent = re.compile("\n\r? {0,%d}" % nshift)
_dedent_regex[nshift] = unindent
result = unindent.sub("\n", s).strip()
return result














 9244
9244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









