






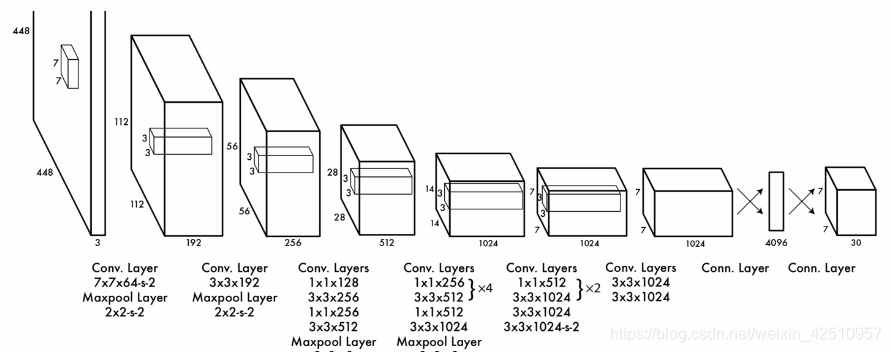
YOLO-V1 结构
同时预测多个Box位置和类别
更加彻底的端到端的目标检测和识别
速度更快
口实现回归功能的CNN并不需要复杂的设计过程
口直接选用整图训练模型,更好的区分目标和背景区域
YOLO(You Only Look Once)它的核心思想就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置及其所属的类别。YOLO最左边是一个InceptionV1网络,共20层。但作者对InceptionV1进行了改造,他没有使用inception模块,而是一用一个1×1的卷积并联InceptionV1提取出的特征图再经过4个卷积层和2个全连接层,最后生成7x7×30的输出。
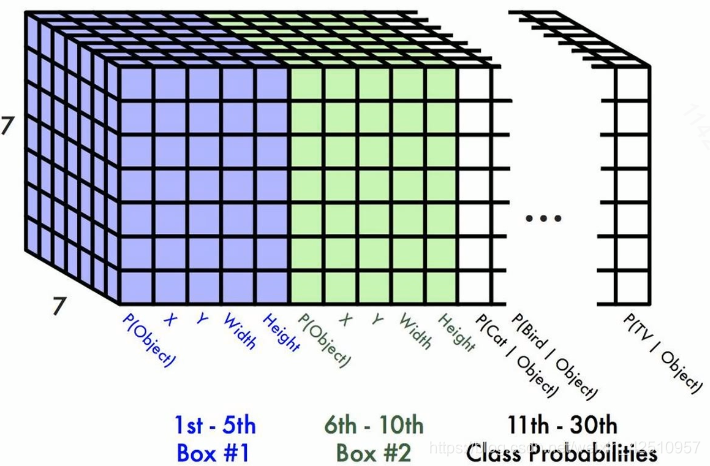
YOLO将一幅448×448的原图分割成了7×7=49个网格,每个网格要预测两个bounding box的坐标(x,y,w,h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及物体属于20类别中每一类的概率(YOLO的训练数据为voc2012,它是一个20分类的数据集)。
所以一个网格对应一个(4x2+2+20)=30维的向量。
最后生成7x7×30的输出
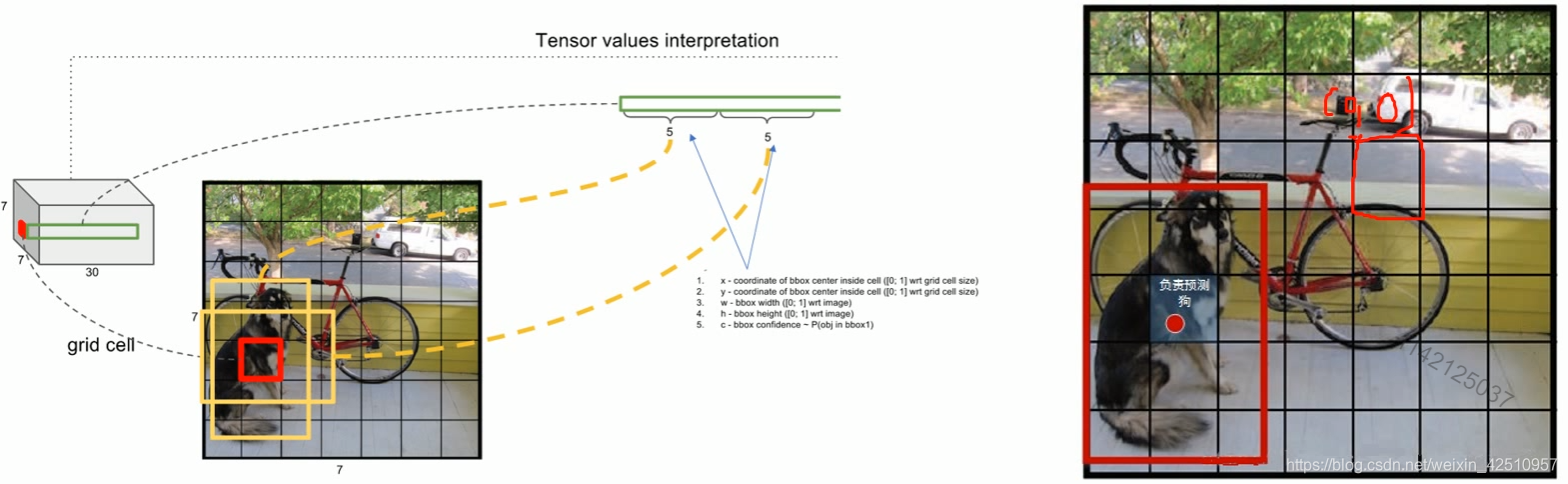
7x7网格内的每个grid(红色框),对应两个大小形状不同的bounding box(黄色框)。每个box的位置坐标为(x,y,w,h),x和y表示box中心点与该格子边界的相对值,w和h表示预测box的宽度和高度相对于整幅图像的宽度和高度的比例。(x,y,w,h)会限制在[0,1]之间。与训练数据集上标定的物体真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个grid负责检查中心点落在该格子的物体。
这个置信度只是为了表达box内有无物体的概率(类似于Faster R-CNN中RPN层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类。
confidence置信度
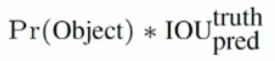
其中前一项表示有无人工标记的物体落入了网格内,如果有则为1,否则为0。第二项代表bounding box和真实标记的box之间的IOU。值越大则box越接近真实位置。
confidence是针对bounding box的,每个网格有两个bounding box,所以每个网络会有两个confidence与之对应。
1.一张图片会被分成7*7=49个格子区域,每一个格子得到两个bounding boxes
2.每个网格预测的class信息和bounding boxes预测的confidence信息相乘,得到了每个Bounding box预测具体物体的概率和位置重叠的概率PrlOU
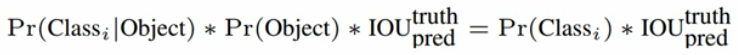
3.对于每一个类别,对PrIOU进行排序,去除小于阈值的PrlOU,然后做非极大值抑制(值大的框留下,再把与值大的框重叠比较多的候选框去除)。最后得到预测的结果。
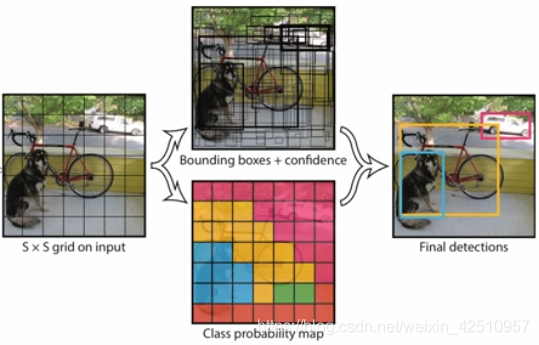
YOLO-V1代价函数
YOLO的loss函数包含三部分:位置误差、confidence误差、分类误差。
左边是4+1+4+1+20 共30个值
每个格子有2个框,所以4+1+4+1代表2个框的x,y,w,h坐标和confidence;20是指20种检测目标的概率。
位置坐标的loss
confidence 的函数
判断第i个网格中第j个bb是否负责这个object,判断标准是:与object的ground truth box的IoU最大的bb负责该object。预测值与ground truth越接近越好
含有object的bbox的confidence预测
不含有object的bbox的confidence预测
相当大的预测框是没有框到object的,所以要分开来处理。同时
λ
n
o
o
b
j
\lambda_noobj
λnoobj的权重要小一些
C
i
C_i
Ci表示网络预测的置信度,
类别预测的函数也是二次代价函数
判断是否有object的中心落在网格i中,网格中包含有object的中心就负责预测该object的类别概率。
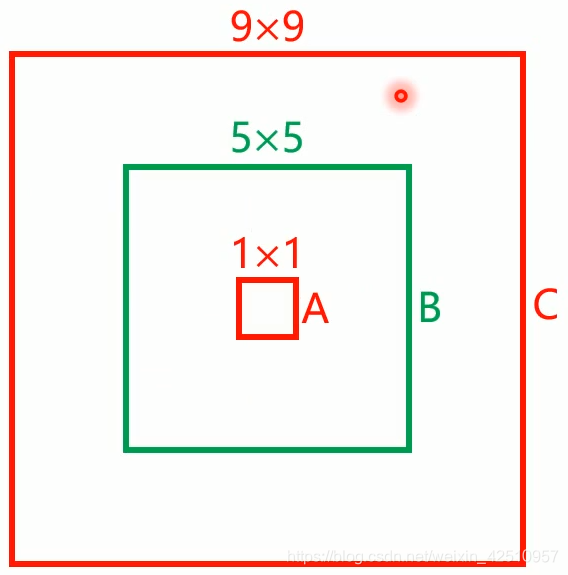
为什么要加根号,可以通过下面的例子来理解
绿色为bounding box,红色为真实标注。如果w和h没有平方根,那么bounding box跟两个真实标注的位置loss是相同的,但是从面积看来B框是A框的25倍,C框是B框的(81/25约等于3.2)倍,B框跟A框的大小偏差更大,不应该得到相同的loss。
如果w和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,更符合我们的实际判断。
不同的任务重要程度不同,所以也应该给予不同的loss weight。
·每个网格两个预测框坐标比较重要(决定了框的准不准),给这些损失前面赋予更大的 loss weight在pascal VOC取值为5。
·对没有object的box的confidence loss,赋予小的 loss weight,在pascal VOC训练中取0.5。
·有object的box的confidence loss 和类别的loss的loss weight正常取1。
YOLO-V1缺点
1.每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。
2.原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。
3.最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
4.对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病,SSD对这个问题有一些些优化。














 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









