







简介:EfficientNet-Lite1是谷歌提出的EfficientNet系列的一个变种,特别针对移动设备和嵌入式系统进行了优化。本文详细解读了该模型的设计理念、结构特点,以及其在移动设备上的实际应用和优势。EfficientNet-Lite1采用了复合缩放策略和移动卷积设计,支持SE模块,并对分辨率进行了优化,使其在资源有限的设备上具有高性能和低功耗的特点。 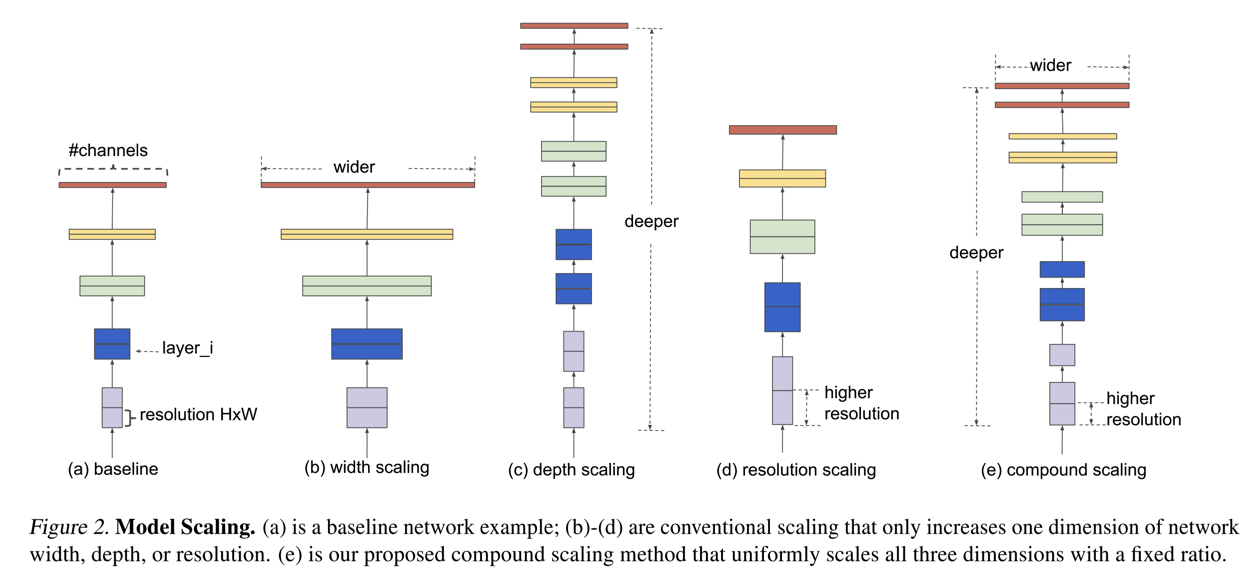
1. EfficientNet模型的发展背景与Lite系列概述
随着深度学习技术的快速发展,神经网络架构的优化成为了提升模型性能和效率的关键。EfficientNet作为其中的佼佼者,因其实现了在高精度和高效计算之间的出色平衡而备受瞩目。EfficientNet模型家族的Lite系列,针对移动和边缘计算设备进行了进一步的优化,从而在保持模型准确性的同时,大幅提升了推理速度和减少了计算资源的需求。
1.1 EfficientNet模型的发展背景
最初提出的EfficientNet模型,通过一种复合缩放方法,系统地对深度、宽度和分辨率进行均匀的缩放,从而在各个维度上实现优化,最终在图像识别、对象检测等任务中取得了显著的性能提升。这一模型在保持计算资源不变的情况下,相较于其他基线模型,展现出优异的准确率和效率。
1.2 Lite系列的推出
随着移动设备性能的提升和边缘计算需求的增长,需要更轻量级且高效的模型来满足在资源受限设备上的实际应用。Lite系列应运而生,专为移动和边缘设备进行了优化,它在保持EfficientNet核心优势的基础上,进一步简化了网络结构,降低了模型复杂度,使得模型能在仅数MB大小的情况下,快速准确地进行推理。
1.3 Lite系列的发展意义
Lite系列的推出不仅仅是在原有模型基础上的简化,而是对神经网络架构的一个全新思考。它强调了在移动设备上运行深度学习模型的特殊需求,包括快速响应时间、低延迟、高准确率以及最小化的能耗。因此,Lite系列不仅推动了移动设备上AI应用的发展,还为深度学习模型在边缘设备上的部署提供了新的可能性。
2. EfficientNet-Lite1设计理念与关键特性
在深入探讨EfficientNet-Lite1模型的细节之前,我们首先需要了解它的设计理念和关键特性。EfficientNet-Lite1模型作为EfficientNet系列的一个轻量级变体,其设计理念旨在在保持高效性能的同时优化模型以适应移动设备的计算和存储限制。为了达到这一目标,模型引入了多项创新,包括复合缩放策略、移动卷积结构和SE(Squeeze-and-Excitation)模块。
2.1 复合缩放策略的应用
2.1.1 缩放策略的理论基础
在现代深度学习模型中,调整模型的复杂度通常涉及到修改网络的宽度(宽度代表模型中层的宽度,即卷积核的数量)、深度(深度代表网络中层数的数量)以及输入图像的分辨率。复合缩放策略(Compound Scaling)则是一种系统性的方法,它将这些维度综合考虑,以获得最优的性能和效率。
传统的缩放方法通常只关注单一维度,这可能导致在其他维度上出现性能瓶颈。例如,增加模型的宽度和深度可能会提高模型的容量和准确性,但同时也会增加计算复杂度和内存占用,从而影响模型在资源受限设备上的部署。EfficientNet-Lite1通过复合缩放策略试图打破这一限制。
2.1.2 复合缩放在模型中的具体实现
EfficientNet-Lite1使用一种由网络宽度、深度和分辨率构成的复合缩放系数来平衡这三个维度。缩放系数由神经架构搜索(NAS)自动确定,以实现最优的性能。该策略确保模型在所有维度上都能协同增长,从而达到既高效又均衡的状态。
复合缩放的关键步骤如下: 1. 确定一个基准模型和一个初始的缩放系数。 2. 使用NAS进行搜索,以找到针对给定计算资源限制的最优缩放系数。 3. 根据找到的缩放系数,按比例调整网络的宽度、深度和分辨率。
# 示例代码展示如何使用复合缩放策略
def compound_scaling(base_model, width_mult, depth_mult, resolution_mult):
"""
根据复合缩放策略调整EfficientNet模型参数
:param base_model: 基准模型
:param width_mult: 网络宽度缩放系数
:param depth_mult: 网络深度缩放系数
:param resolution_mult: 分辨率缩放系数
:return: 调整后的模型
"""
# 以下是伪代码
new_width = base_model.width * width_mult
new_depth = base_model.depth * depth_mult
new_resolution = base_model.resolution * resolution_mult
scaled_model = ModelAdjuster.scale_model(base_model, new_width, new_depth, new_resolution)
return scaled_model
# 使用示例
model = compound_scaling(base_model=EfficientNetB0(), width_mult=1.2, depth_mult=1.1, resolution_mult=1.1)
通过上述代码,我们可以看到复合缩放策略是如何应用于调整模型参数的。在实践中,这一过程完全由NAS算法自动完成,以优化模型性能。
2.2 移动卷积结构特点
2.2.1 移动卷积结构的提出与演进
移动卷积结构(Mobile Inverted Residual Bottleneck)是EfficientNet-Lite1中为移动设备优化而设计的一种特殊卷积结构。它通过引入反向残差连接(Inverted Residuals)和分组卷积(Grouped Convolutions)来减少计算量,同时维持了深层网络的性能。
移动卷积的提出基于以下观察: - 反向残差连接能够有效地传递梯度,即使在网络非常深的时候。 - 分组卷积可以将输入和输出特征图分成更小的组,减少了计算量,同时保持足够的特征表达能力。
2.2.2 移动卷积在Lite1中的应用分析
在EfficientNet-Lite1中,移动卷积结构通过一系列的堆叠来构建高效的神经网络层。它允许模型在维持较低计算量的同时,通过分组卷积来利用通道之间的并行性。这一点对于移动设备来说至关重要,因为它们的计算资源有限且对功耗敏感。
# 伪代码展示移动卷积结构在EfficientNet-Lite1中的应用
def inverted_res_bottleneck(input_tensor, filters, expand_ratio, stride):
"""
移动卷积结构的实现
:param input_tensor: 输入张量
:param filters: 输出通道数
:param expand_ratio: 扩展比率
:param stride: 步长
:return: 输出张量
"""
# 以下是伪代码
expanded_tensor = Conv2D(filters=expand_ratio * input_tensor.shape[-1], kernel_size=1)(input_tensor)
expanded_tensor = BatchNormalization()(expanded_tensor)
expanded_tensor = ReLU6()(expanded_tensor)
output_tensor = Conv2D(filters=filters, kernel_size=3, strides=stride, padding='same')(expanded_tensor)
output_tensor = BatchNormalization()(output_tensor)
# 如果输入和输出尺寸相同,则添加残差连接
if stride == 1 and input_tensor.shape[-1] == filters:
output_tensor = Add()([input_tensor, output_tensor])
return output_tensor
2.3 SE模块在模型中的作用
2.3.1 SE模块的原理与重要性
SE模块,即Squeeze-and-Excitation模块,是一种使网络能够自适应地调整通道间的重要性和权重的结构。SE模块通过添加一个通道注意力机制,允许模型更集中地利用重要的特征,同时抑制不那么重要的特征。
SE模块的设计灵感来源于观察到深度卷积神经网络中的许多特征通道包含冗余信息。通过引入SE模块,网络能够在训练过程中学习到如何更有效地利用有限的通道资源。
2.3.2 SE模块优化Lite1性能的机制
在EfficientNet-Lite1中,SE模块被集成到每个移动卷积块中,为模型提供了额外的性能提升。SE模块的主要工作机制如下: 1. Squeeze:将特征图的空间维度压缩成一个单一的数值表示,这通常通过全局平均池化(Global Average Pooling)来实现。 2. Excitation:使用两个全连接层对这些单一数值进行处理,第一个层降低通道维度,第二个层则恢复通道维度,形成一个通道权重向量。 3. Scale:使用得到的通道权重向量来调整原始特征图的每个通道。
# 伪代码展示SE模块在EfficientNet-Lite1中的实现
def se_module(input_tensor, ratio):
"""
SE模块的实现
:param input_tensor: 输入张量
:param ratio: 压缩比率,用于计算中间通道数
:return: 调整后的输出张量
"""
# 以下是伪代码
channel_axis = -1
# Squeeze
squeezed_tensor = GlobalAveragePooling2D()(input_tensor)
squeezed_tensor = Reshape((1, 1, squeezed_tensor.shape[-1]))(squeezed_tensor)
# Excitation
excitation_tensor = Dense(input_tensor.shape[channel_axis] // ratio, activation='relu')(squeezed_tensor)
excitation_tensor = Dense(input_tensor.shape[channel_axis], activation='sigmoid')(excitation_tensor)
# Scale
scaled_tensor = Multiply()([input_tensor, excitation_tensor])
return scaled_tensor
通过引入SE模块,EfficientNet-Lite1不仅增强了模型对于不同特征通道的敏感性,还提高了模型对于重要特征的利用率,从而实现了在移动设备上的高效运行和优化性能。
3. EfficientNet-Lite1优化技术分析
随着移动设备计算能力的不断增强,AI模型在移动端的部署和应用变得越来越重要。EfficientNet-Lite1通过一系列优化技术在保持高性能的同时实现了对移动设备的友好部署。本章将深入探讨EfficientNet-Lite1优化技术的细节,从分辨率优化到移动设备部署优势,每一个技术点都会被详细剖析,展示其对模型性能和实用性的提升。
3.1 优化分辨率的优势
3.1.1 分辨率优化对性能的影响
分辨率在图像识别任务中是一个重要的参数,它直接影响到模型的输入大小,进而影响计算资源的消耗和模型的准确性。在EfficientNet-Lite1中,优化分辨率是一个重要的策略,旨在减少模型的计算量,同时保持模型性能不降低或降低较少。当输入图像的分辨率较低时,模型可以更快地处理图像,从而加快推理速度;但过低的分辨率可能会损害模型识别的准确性,特别是在复杂场景下。因此,分辨率优化需要找到一个平衡点,以确保推理速度和准确性之间的最佳权衡。
3.1.2 分辨率优化在Lite1中的实现与效果
为了在分辨率优化方面取得成果,EfficientNet-Lite1使用了多尺度的分辨率增强技术。它首先在多个尺度上对输入图像进行下采样,然后在模型的多个阶段使用不同尺度的特征图。这允许模型捕获不同尺度的上下文信息,同时减少了在较高分辨率下进行处理的计算负担。
在模型中实现分辨率优化的过程可以通过修改网络的第一层来实现,例如将传统的224x224输入调整为更小的160x160。如下代码展示了如何修改输入层的参数以适应新的分辨率:
from efficientnet import EfficientNet
# 创建EfficientNet-Lite1模型实例,输入分辨率改为160x160
model = EfficientNet(width_coefficient=1.0, depth_coefficient=1.0, dropout_rate=0.2,
image_size=160, include_top=True, weights=None, input_tensor=None,
classes=1000)
在上文代码中, image_size 参数被设置为160,意味着模型的输入分辨率被设定为160x160。调整输入分辨率的代码逻辑很直接:改变模型的图像尺寸参数,然后将该参数应用于整个网络。这里的参数 width_coefficient 和 depth_coefficient 保持默认值,意味着模型的宽度和深度未进行改变,仅调整输入分辨率。
3.2 移动设备部署优势
3.2.1 移动设备部署的重要性
在移动设备上部署AI模型为实时应用带来了巨大的潜力。移动设备部署具有低延迟、私密性和便携性的优点,为用户提供了随时随地使用AI功能的可能性。例如,拍照翻译、场景识别、实时语音翻译等应用都依赖于高效的移动设备部署。因此,高效的模型部署对于AI在移动设备上的普及至关重要。
3.2.2 Lite1模型的移动部署优化策略
EfficientNet-Lite1在设计时考虑到了移动设备的特殊需求。为了优化移动设备上的模型部署,Lite1采用了轻量级的网络结构设计和优化算法。这包括使用深度可分离卷积来减少参数数量,以及使用高效的激活函数和归一化技术来提升计算效率。
下面是一个展示如何使用深度可分离卷积进行优化的代码示例:
from keras.layers import DepthwiseConv2D, Conv2D, Dense
# 构建深度可分离卷积层
depthwise_conv = DepthwiseConv2D(kernel_size=(3, 3), padding='same', depth_multiplier=1)(input_layer)
pointwise_conv = Conv2D(filters=256, kernel_size=(1, 1), padding='same')(depthwise_conv)
# 连接一个全连接层
dense_layer = Dense(1024, activation='relu')(pointwise_conv)
# 分析深度可分离卷积的参数数量
total_params = model.count_params()
print(f"Total number of parameters in the model: {total_params}")
在这段代码中, DepthwiseConv2D 层首先对输入执行深度可分离卷积,其卷积核数量由 depth_multiplier 参数决定。然后通过 Conv2D 执行点卷积,将深度特征转换为高维特征。最后,通过全连接层进一步处理特征。深度可分离卷积通过减少卷积核的数量,从而大幅度减少了模型的参数数量,这使得模型更适合在计算资源受限的移动设备上部署。
此外,EfficientNet-Lite1还利用了一系列模型压缩技术,例如权重剪枝和量化,这些技术有助于进一步降低模型的存储和计算需求,从而在移动设备上实现更快的推理速度和更小的内存占用。
表格与流程图展示
| 模型优化技术 | 描述 | | ------------ | ---- | | 分辨率优化 | 改变输入图像分辨率以减少计算量,优化模型性能 | | 深度可分离卷积 | 使用深度可分离卷积替代传统卷积来减少参数数量 | | 权重剪枝 | 移除模型中权重较小的连接以简化模型 | | 量化 | 将模型参数从浮点数转换为较低精度的数值表示 | | 模型压缩 | 综合使用多种技术减少模型大小和计算需求 |
为了展示EfficientNet-Lite1模型的优化流程,我们可以使用以下的Mermaid流程图来描述优化过程的关键步骤:
flowchart LR
A[开始] --> B[分辨率优化]
B --> C[深度可分离卷积]
C --> D[权重剪枝]
D --> E[量化]
E --> F[模型压缩]
F --> G[最终优化模型]
G --> H[部署到移动设备]
H --> I[结束]
在上述流程图中,展示了从优化开始到最终部署到移动设备的一系列步骤。优化过程从分辨率优化开始,依次经过深度可分离卷积、权重剪枝、量化、模型压缩等关键步骤,最终得到一个优化后的模型,然后可以将其部署到移动设备中使用。
总结
在本章节中,我们详细探讨了EfficientNet-Lite1中应用的优化技术,包括分辨率优化和移动设备部署优势。这些优化技术不仅提升了模型在移动设备上的性能,而且还保持了高效准确的推理能力。从分辨率优化到深度可分离卷积的使用,每一个技术点都围绕着实现高效能模型的核心目标。通过代码逻辑的逐行解读和参数说明,我们可以更深入地了解这些技术如何在实际中被应用和实施。在接下来的章节中,我们将继续深入分析EfficientNet-Lite1模型在实际应用中的优势和挑战。
4. EfficientNet-Lite1在实际应用中的优势
随着移动计算设备的普及和性能的不断提升,模型的效率和在设备上的实际运行效果成为了决定其应用范围的关键因素。本章节深入探讨EfficientNet-Lite1在实际应用中的优势,分析其如何通过优化设计满足低功耗计算和快速推理等移动设备的重要需求。
4.1 低功耗计算能力
4.1.1 低功耗对移动设备的意义
移动设备如智能手机、平板电脑和可穿戴设备,通常具有有限的电池容量和计算资源。低功耗计算能力的提升,可以显著延长设备的使用时间,减少充电频率,并允许设备在更长时间内保持高性能运行。此外,低功耗也意味着较低的热量产生,有助于设备保持更好的物理稳定性和用户体验。
4.1.2 Lite1模型的功耗优化技术
EfficientNet-Lite1通过多种技术手段实现了低功耗计算。其中包括深度可分离卷积(Depthwise Separable Convolution)的应用,该技术将标准卷积运算分解为深度卷积和逐点卷积两个部分,大幅减少了模型参数和计算量。还有,模型在设计时减少了层的深度和宽度,同时使用了高效的激活函数,例如Swish函数替代ReLU,这些都有助于减少功耗。
代码示例:
import tensorflow as tf
from tensorflow.keras.layers import DepthwiseConv2D, Conv2D, Dense
def efficientnet-lite1_layer(x):
# 使用深度可分离卷积
x = DepthwiseConv2D(kernel_size=(3, 3), padding='same')(x)
# 接着使用逐点卷积
x = Conv2D(filters=24, kernel_size=(1, 1), padding='same')(x)
# 使用Swish激活函数
x = tf.keras.activations.swish(x)
return x
# 模拟一个简单的模型层
input_shape = (None, None, 3)
x = tf.keras.layers.Input(shape=input_shape)
output = efficientnet-lite1_layer(x)
model = tf.keras.Model(inputs=x, outputs=output)
# 查看模型参数和计算量
model.summary()
分析: 通过使用深度可分离卷积,模型能够减少运算量和模型大小。 DepthwiseConv2D 执行深度卷积运算,而 Conv2D 随后用较少的参数执行逐点卷积。这样的设计使模型能够减少参数量和计算次数,从而优化功耗。
4.2 快速推理和实时数据处理
4.2.1 推理速度在实时应用中的重要性
在实时应用场景下,如视频监控、自动驾驶、互动应用等领域,快速的推理速度是至关重要的。它能够确保系统可以快速响应环境变化,处理大量数据,并做出即时决策。这不仅关乎用户体验的流畅度,更关乎系统的安全性和可靠性。
4.2.2 Lite1模型提升推理速度的方法
EfficientNet-Lite1通过模型压缩和优化的策略,如知识蒸馏和量化技术,进一步提升了推理速度。知识蒸馏是训练一个小型网络(学生网络)来模仿一个大型网络(教师网络)的行为,而量化则是在保持模型准确性的同时,减少模型中权重和激活的表示精度,从而加快计算速度。
mermaid流程图示例:
graph TD
A[Start] --> B[Knowledge Distillation]
B --> C[Train Student Network]
C --> D[Quantization]
D --> E[Optimized Model]
E --> F[Inference on Device]
F --> G[End]
表格展示:
| 技术 | 描述 | 优势 | | --- | --- | --- | | 知识蒸馏 | 训练小型网络模仿大型网络 | 提升推理速度,保持模型准确性 | | 量化 | 减少权重和激活的表示精度 | 加快计算速度,减少存储需求 |
代码示例:
import tensorflow as tf
# 假设我们已经有了一个预训练的大型模型 teacher_model
teacher_model = tf.keras.models.load_model('large_pretrained_model.h5')
# 创建一个较小的模型 student_model 作为蒸馏的目标
student_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=10, activation='softmax')
])
# 使用知识蒸馏的损失函数来训练student_model
distillation_loss = tf.keras.losses.KLDivergence()
def distillation_loss_fn(y_true, y_pred):
return distillation_loss(y_true, y_pred)
# 训练过程省略 ...
# 量化模型
quantize_model = tf.keras.models.load_model('student_model.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(quantize_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
quantized_tflite_model = converter.convert()
分析: 以上示例中,首先利用知识蒸馏将大型教师网络的知识转移到小型学生网络中,之后通过量化将训练好的学生模型转换为适用于移动设备的模型。通过这样的步骤,模型的参数和计算复杂度大幅度降低,能够实现快速的推理。
在本章节中,通过两个方面的深入分析,展示了EfficientNet-Lite1如何满足实际应用中的低功耗计算和快速推理的需求。通过对模型结构和技术手段的优化,EfficientNet-Lite1确保了其在移动设备上的高效运行,同时保持了良好的性能。
5. EfficientNet-Lite1模型的未来展望与挑战
随着深度学习与机器视觉技术的快速发展,EfficientNet-Lite1作为一个专为移动设备优化的轻量级模型,在图像处理与分类任务中显示出了巨大的潜力。然而,技术的发展永无止境,面对未来,EfficientNet-Lite1亦需不断地进步与适应。本章节将探讨EfficientNet-Lite1未来的发展趋势、面临的挑战以及可能的应对策略。
5.1 模型未来发展趋势
5.1.1 当前技术的局限性与改进方向
尽管EfficientNet-Lite1在轻量级模型中取得了令人瞩目的成就,但仍有改进的空间。当前的技术局限性主要体现在模型泛化能力、数据效率以及对新兴硬件的适配上。例如,在处理非标准输入尺寸数据时,模型可能需要进行额外的调整,这会影响推理效率。
改进的方向可以从以下几个方面进行:
- 模型泛化能力 :通过引入更多的正则化技术来防止过拟合,使用自监督学习或半监督学习来增强模型在未标记数据上的泛化能力。
- 数据效率 :优化训练过程,使用更有效的数据增强策略和小批量训练技术来提高样本效率。
- 硬件适应性 :继续与移动芯片制造商合作,针对特定硬件平台优化模型架构,以充分利用其计算资源。
5.1.2 未来可能的创新点和应用领域
未来的EfficientNet-Lite1模型可能会在以下几个方面展现新的创新点:
- 神经架构搜索(NAS) :通过自动化技术寻找最优的模型结构,以实现更高的准确率和效率。
- 多模态学习 :整合图像、文本、音频等多种类型的数据,创建更为全面的模型,以应用于更复杂的任务,如视频理解。
- 强化学习 :引入强化学习机制,使模型能够自我优化,在特定任务中实现更高的性能。
- 边缘计算应用 :随着5G时代的到来,边缘计算将变得更为重要,EfficientNet-Lite1将被用于各类边缘设备,从智能手表到自动驾驶汽车。
5.2 模型面临的挑战与解决策略
5.2.1 模型在不同场景下的适应性问题
EfficientNet-Lite1在不同场景下的适应性依然是一大挑战。比如在户外场景中,光照变化、天气条件等因素会对模型的性能造成影响。
为了解决这些问题,可以采取以下策略:
- 环境自适应 :增加模型对环境变化的适应性,如使用领域适应技术,对数据进行模拟增强,使其覆盖更广泛的变化。
- 多任务学习 :通过同时训练模型执行多个相关任务,增强其在不同场景下的表现。
5.2.2 面对挑战的应对策略和研究方向
在模型的优化与创新过程中,研究者需要面对多种挑战,例如如何保证模型的轻量化的同时不牺牲性能,如何实现模型的快速部署等。
具体应对策略包括:
- 轻量化技术的研究 :开发更高效的神经网络结构,例如使用分组卷积、深度可分离卷积等方法。
- 模型压缩与加速 :研究更先进的模型压缩技术,如权重量化、知识蒸馏等,以进一步减少模型体积并提高运算速度。
- 跨平台部署策略 :制定统一的模型部署标准和工具链,使模型能够轻松部署在不同的硬件平台和操作系统上。
在未来的研究中,EfficientNet-Lite1将继续向着更加高效、智能的方向发展,不断提升其在实际应用中的效能与鲁棒性。
简介:EfficientNet-Lite1是谷歌提出的EfficientNet系列的一个变种,特别针对移动设备和嵌入式系统进行了优化。本文详细解读了该模型的设计理念、结构特点,以及其在移动设备上的实际应用和优势。EfficientNet-Lite1采用了复合缩放策略和移动卷积设计,支持SE模块,并对分辨率进行了优化,使其在资源有限的设备上具有高性能和低功耗的特点。

















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









