






在股市中,经常会遇到趋势的预判。所谓趋势,即相对而言的规律化的模式识别形态。形象来讲,就是个股的一段时间内的曲线分布状况。
那么,问题来了。
我们虽然可以在少量的图像中分辨出差异不是很大的趋势之间的相似度。如果,在进行量化交易的时候,进行程序化的批量匹配过程中,该如何分辨出相似度最高的曲线标的呢?这就需要程序化算法进行匹配。
对于曲线而言,无非就是一系列的坐标点的连线。在对相邻坐标点的倾斜角进行递归计算,就可以合计出曲线的倾斜角分布积,就代表了曲线的形态。那么,又如何进行批量的匹配呢?需要进行倾斜角分布积的归一化,常规的线性函数在对于无量纲的区间进行归一处理的无奈。该如何处理呢?其实可以转换思路,对每一组倾斜角进行差额计算,由于 180° < 相邻坐标点倾斜角区间 > 0°,那么进行了倾斜角分布积差以后,就转入了常规的线性函数的归一化处理范围。
package com.mms.tools; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * 趋势线拟合度算法 * ww */ public class Trend { /* 任意两点间直线的倾斜角算法 */ public static void main(String[] args) throws Exception { //基准坐标系 List> ls = new ArrayList>(); Map m = new HashMap(); String strs = ""; m = new HashMap(); m.put("x", 1.0);m.put("y", 1.0); ls.add(m); m = new HashMap(); m.put("x", 2.0);m.put("y", 2.0); ls.add(m); m = new HashMap(); m.put("x", 3.0);m.put("y", 3.0); ls.add(m); m = new HashMap(); m.put("x", 4.0);m.put("y", 4.0); ls.add(m); m = new HashMap(); m.put("x", 5.0);m.put("y", 5.0); ls.add(m); m = new HashMap(); m.put("x", 6.0);m.put("y", 6.0); ls.add(m); m = new HashMap(); m.put("x", 7.0);m.put("y", 7.0); ls.add(m); m = new HashMap(); m.put("x", 8.0);m.put("y", 8.0); ls.add(m); m = new HashMap(); m.put("x", 9.0);m.put("y", 9.0); ls.add(m); m = new HashMap(); m.put("x", 10.0);m.put("y", 9.0); ls.add(m); //坐标系斜率归一化 List lvs = getLvs(ls); if(lvs != null && lvs.size() >0){ //匹配坐标系 List> lss = new ArrayList>(); for(int i=0;i<10;i++){ m = new HashMap(); m.put("x", (double)(i+1));m.put("y",(double)GetIntMathNumber(1,9)); lss.add(m); } double guis = getGuis(lss,lvs); //System.out.println("两条坐标系曲线拟合(值越小越拟合): "+guis); } } /* * 根据坐标系计算出相邻坐标的斜率集 */ public static List getLvs(List> ls){ List lvs = new ArrayList(); //排序 if(ls != null && ls.size() >0){ //System.out.println("基准坐标系,斜率集核算"); for(int i=0;i0 && i> ls,List lvs){ double guis = 0; //排序 if(ls != null && ls.size() >0){ //System.out.println("匹配坐标系,斜率集核算匹配"); for(int i=0;i0 && i
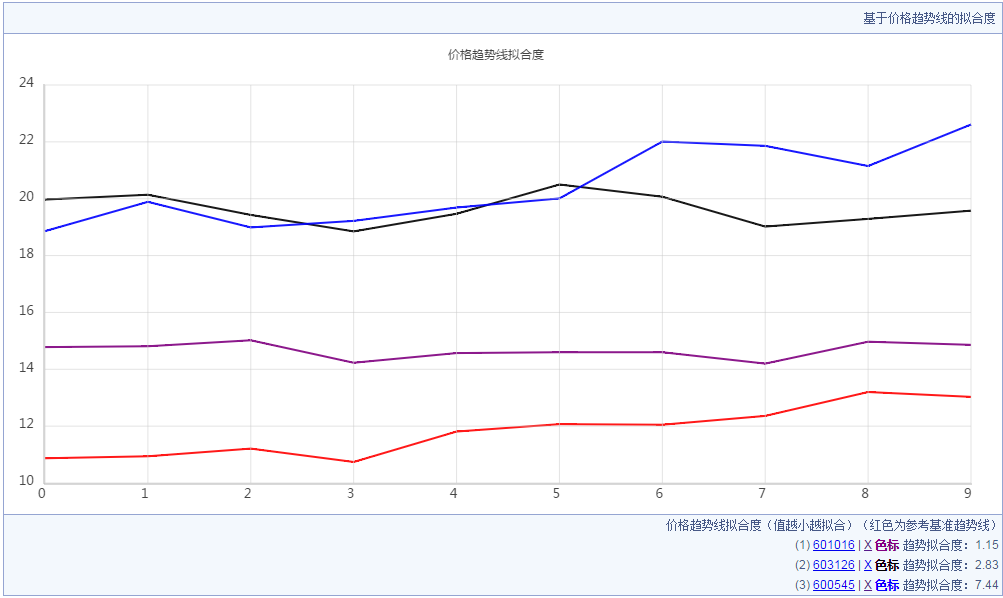
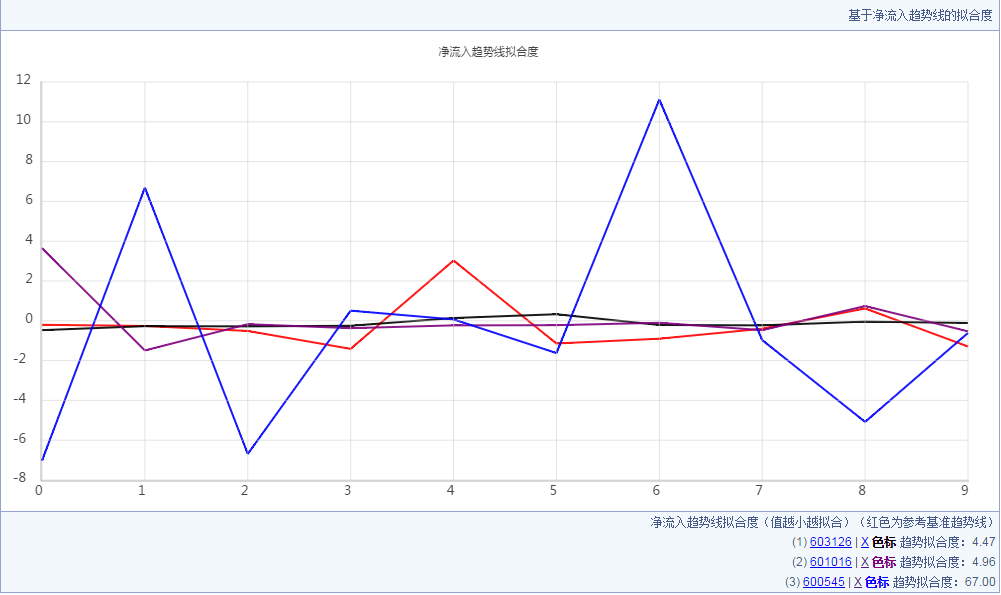
此处给出java的算法代码,如下是进行了图形化结果。














 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









