






下载并格式化数据集
下载数据集
口罩检测数据集下载:3wye
原始数据集的结构
JPEGImages文件夹中存放着数据集的所有图片
labels文件夹中存放着许多.txt文件,文件名和图片的文件名一一对应,也就是一张图片对应一个txt文件。
txt文件的内容如下

从左到右依次是class, x_center, y_center, box_width, box_height
x, y, w, h都是归一化后的(0~1)。
Annotations文件夹中是许多.xml文件,也和图片一一对应,.xml中记录了更详细的标注信息,除了边界框的长宽和左上右下角点坐标,还有标注日期等其他信息。
ImageSets/Main文件夹中有train.txt和val.txt
这两个文件中分别逐行列出了训练集和验证集的文件名称(不带后缀名),便于训练时进行索引。
理解符合YOLOv3(仅指此Github模型)要求的数据集结构
符合YOLOv3要求的数据集主要包含5个部分:
①存放图片和每张图片对应的txt文件的文件夹
②写有每张图片路径的索引文件(训练集和验证集各一个)
③为每个class指定名字的.names文件
④写有class总数、训练集索引文件路径、验证集索引文件路径、.names索引文件路径的.data文件
⑤定义网络结构的.cfg文件(因为class总数变了,普通的yolov3是80 classes。所以网络会有稍微不同,只需要在默认cfg文件稍加改动即可)
①存放图片和每张图片对应的txt文件的文件夹
图片放在images文件夹中,txt文件放在labels文件夹中。
这两个文件夹必须是平行关系。
训练集和验证集可以混放在一个文件夹下,即以下两种结构都可以。因为即便训练集和验证集混在一起,根据②中的两个索引文件也能区分开。
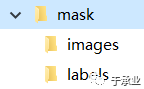
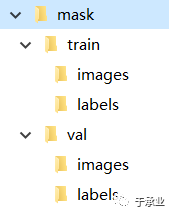
②写有每张图片路径的索引文件
每一行一个地址,注意是填写相对地址,相对train.py的地址。
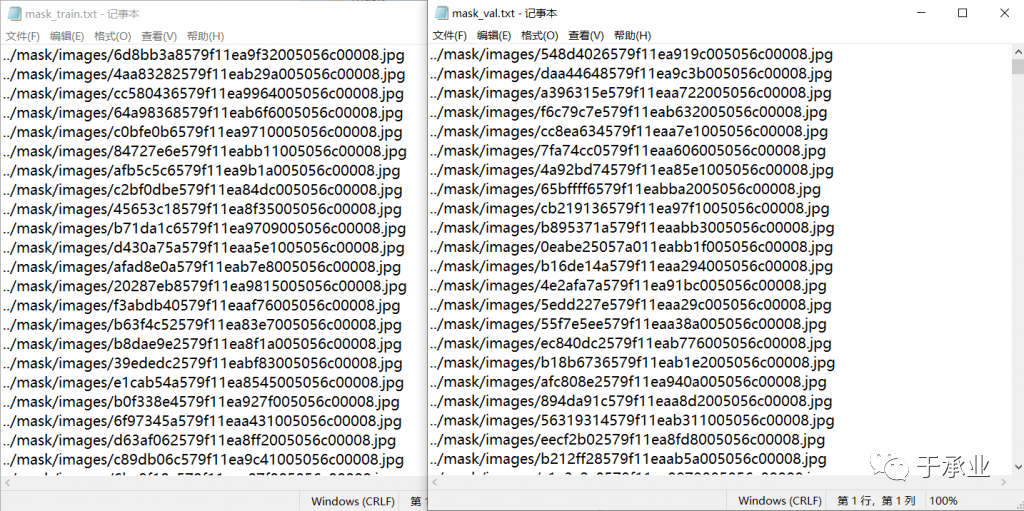
只需要写图片的地址,因为标注文件在与images文件夹平行的labels文件夹中,程序在寻找相应的标注文件时会把xxx/images/xxxx.jpg替换为xxx/labels/xxxx.txt
③为每个class指定名字的.names文件
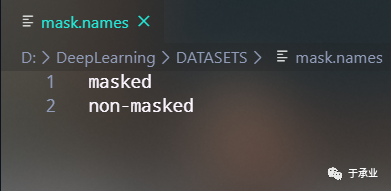
每行对应一个类别,第一行就是class=0时的名字,第二行就是class=1的名字,因为这是二分类(戴与不戴),所以两行就行,也可以只用一个类别即(num_classes=1),区别就是前者在检测时可以同时框出戴口罩和不戴口罩的人,后者只会框出没戴口罩的人。
④写有class总数、训练集索引文件路径、验证集索引文件路径、.names索引文件路径的.data文件
格式如下

classes=
train=
valid=
names=这里的路径也是相对train.py而言的。
⑤定义网络结构的.cfg文件
可以复制yolov3/cfg/yolov3-spp.cfg,在其副本上进行修改。
将classes=80的三处修改为classes=2
将filters=255的三处修改为filters=21 ([5 + 2] * 3)
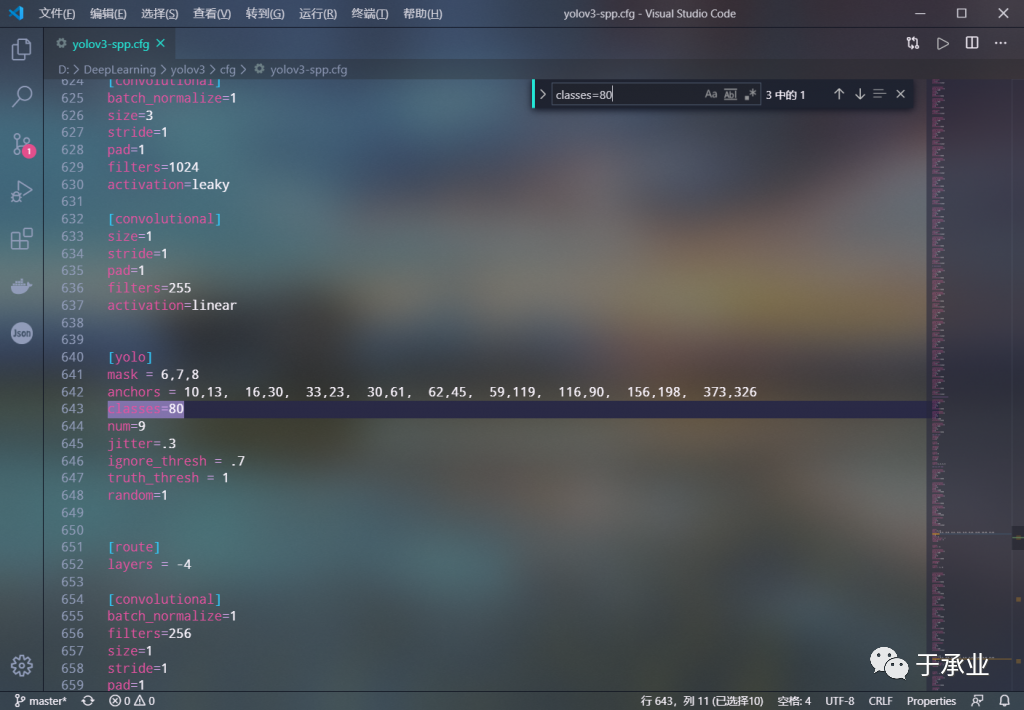

注意不要只搜索filters,要搜索filters=255,因为我们只需要修改Darknet那三个分支最后一个卷积层的filter数量,其它层的filter数量不要变,否则加载预训练权重会出错。
可以给新的cfg文件改名为yolov3-spp-2cls.cfg,以后遇到classes=2的数据集直接拿出来用。
而且cfg文件夹中已经自带yolov3-spp-1cls.cfg,yolov3-spp-3cls.cfg等。
将各个部分放在对应位置上
将mask文件夹(包含images文件夹和labels文件夹)放在你②中索引文件写的路径上。
将索引文件mask_train.txt、mask_val.txt以及命名文件mask.names放在你④中写的路径上。
将mask.data放在data文件夹中(其实可以随便放,启动训练的时候会指定路径,不过尽量统一一些)
yolov3-spp-2cls.cfg放在cfg文件夹中(这个不能随便放)
开始训练
cd yolov3python train.py --data data/mask.data --cfg yolov3-spp-2cls.cfg --batch-size 12默认使用预训练权重yolov3-spp-ultralytics.pt进行训练。
每个EPOCH会自动把权重保存在weights/last.pt
并且会把mAP最高的一次EPOCH保存在weights/best.pt
如果训练中断,可以使用以下命令加载last.pt继续训练
python3 train.py --resume或者使用以下命令使用best.pt继续训练
python train.py --data data/mask.data --cfg yolov3-spp-2cls.cfg --batch-size 12 --weights weights/best.pt可视化
官方提供了两种方式,一种是tensorboard,另一种是官方自己写的。
1.tensorboard可视化
在yolov3目录下开启tensorboard可视化(需要先安装tensorboard)
pip install tensorboard #如果没安装tensorboardcd yolov3tensorboard --logdir=runs浏览器访问localhost:6006查看

2.utils.plot_results()
在yolov3目录下新建一个jupyter notebook,执行以下代码。
from utils import utilsutils.plot_results()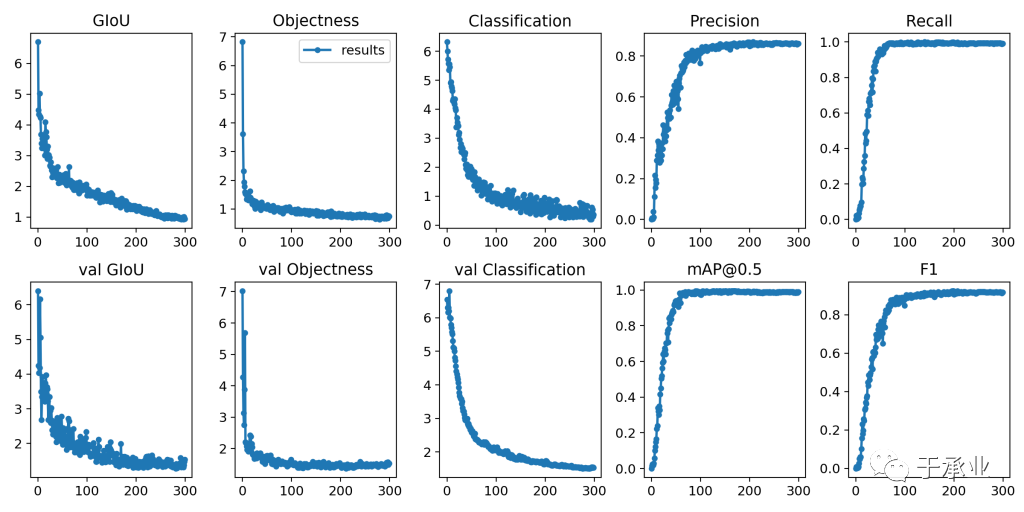
GIoU、Objectness、Classification分别代表坐标损失、score损失、分类损失
Precision、Recall、F1、mAP@0.5分别代表准确率、召回率、F1-score、平均精度损失(iou-threshold=0.5)
推理
训练好以后,可以使用训练好的模型进行推理。
python detect.py --names data/mask.names --cfg yolov3-spp-2cls.cfg --weights weights/best.pt --source ...Image:
--source file.jpgVideo:
--source file.mp4Directory:
--source dir/Webcam:
--source 0RTSP stream:
--source rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daaHTTP stream:
--source http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8
效果演示
















 3816
3816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









