







1 理论部分
- Seq2Seq模型
- Attention + Seq2Seq
- Transformer
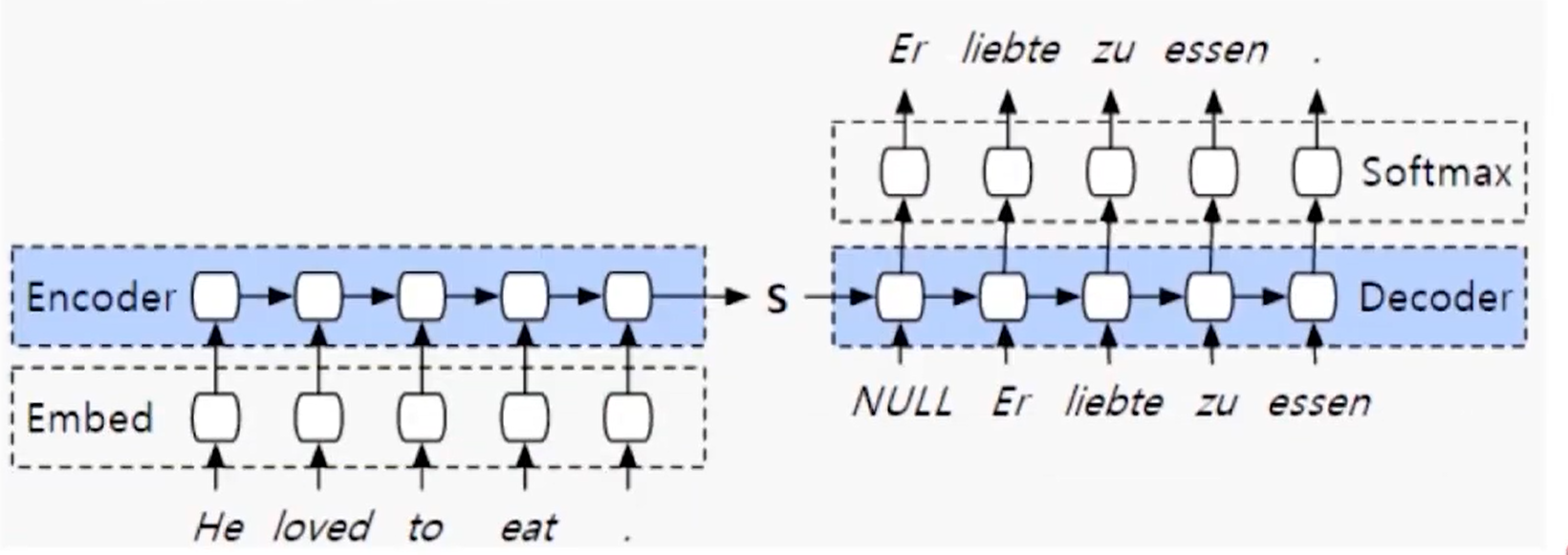
2 Seq2Seq (15-16年比较流行)
- 如下图所示,Encoder和Decoder部分,都可以使用一种循环神经网络,可以是
RNN 、 LSTM、GRU、CIFG等等。
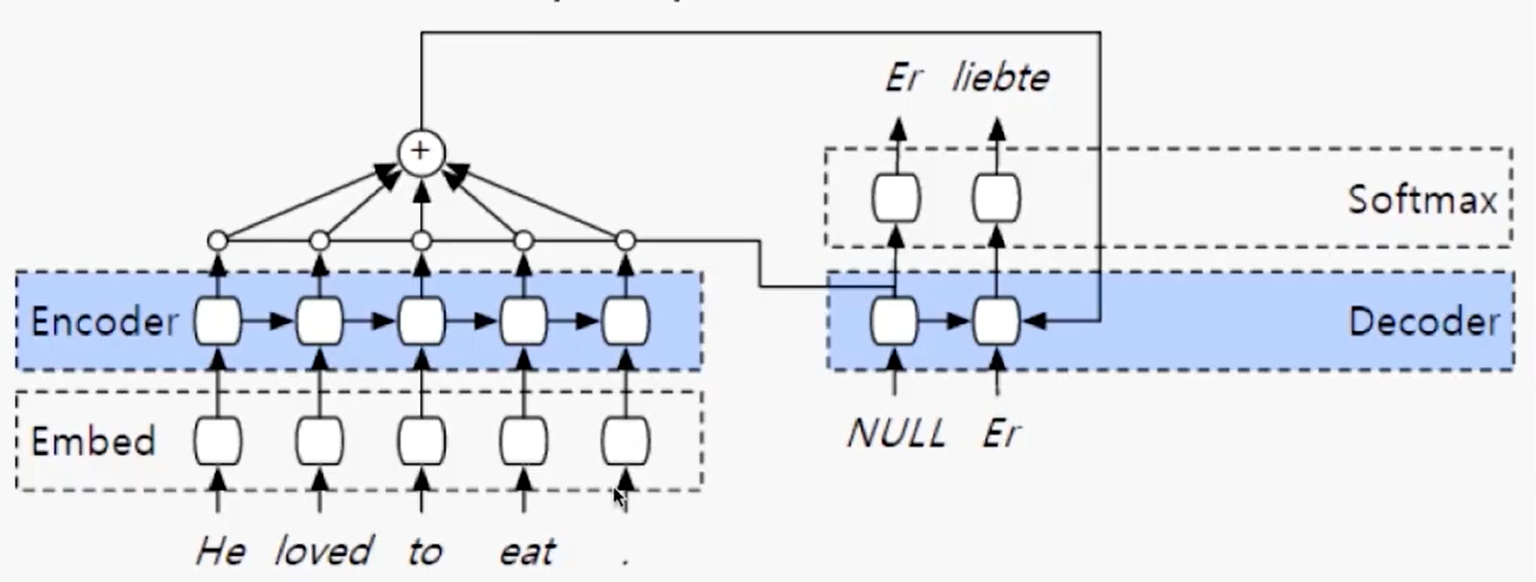
2 基于attention的Seq2Seq
- 改进:每一个
encoder的输出,都会进入到下面的计算中。 attention可以看做是一个 向量来理解,代表的是权重,每一个encoder输出的权重
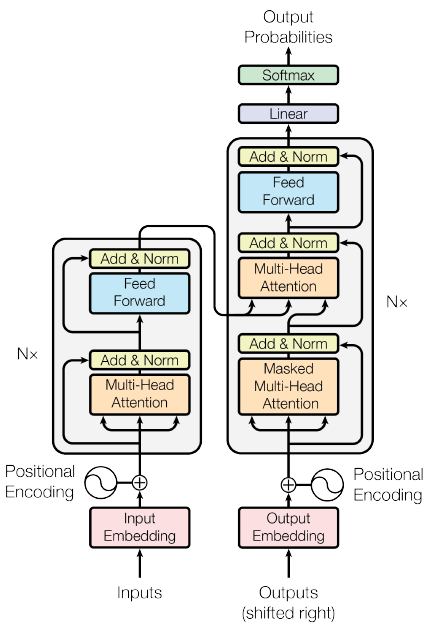
3 Transformer
- 这里就直接抛弃了传统神经网络,也就是说,和上面两种方式的区别就是,在
Transformer中,是不需要RNN、 LSTM等等这些神经网络的。 Transformer是直接使用N 个encoder和N个decoder来实现特征提取和解码的,不需要神经网络,每个编码器和解码器中依靠的是注意力机制和全连接层(全连接层是防止注意力机制对特提取的不够)
















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









