










目录
1.数据准备
2.将视频切成图片
3.标注工具标图输出xml文件
4.转换文件格式
1)去除未标注的图片
2)xml文件格式转换
3)图片和txt文件汇总成训练文件
4)在darknet/scripts目录下创建以下目录
5.修改配置文件并训练
1)修改data/voc.names
2)修改cgf/voc.data
3)修改cfg/yolov3-voc.cfg
4)yolo模型训练
1.数据准备
用手机录制视频数据或者直接使用收集的带有需检测目标的图片数据集
2.将视频切成图片
若使用手机录制的视频数据,将视频切成图片,下面是切图的脚本,把存放视频的路径及图片存放的路径写入即可:
import cv2
vc = cv2.VideoCapture("./video.mp4")
if vc.isOpened():
rval, frame = vc.read()
else:
rval = False
cnt = 1
f_rate = 0.5
t = round(24*f_rate)
while rval:
cnt += 1
rval, frame = vc.read()
if cnt % t != 0:
continue
if cnt % 100 == 0:
print("processing [%d] -->" % cnt)
cv2.imwrite("./Image/"+str(cnt)+".jpg", frame)将切好的图片放在Image文件夹中
3.标注工具标图输出xml文件
使用LabelImg作为标图工具,下载路径:https://github.com/tzutalin/labelImg,Ubuntu下LabelImg环境安装根据python版本不一样如下:

根据主页提示安装好相关依赖,若报错,可自行检查并安装依赖,在终端运行:
python3 labelImg.py打开窗口如下:

点击“打开目录”,图片存放的目录:

点击“改变存放目录”,存放标注图片生成的xml文件目录:

点击“创建区块”,标注图片,添加label:

标注完进行保存,每张图片依次进行标注保存即可

如果需要修改,可以在图片的选区位置,点击右键,可以看到创建区块、编辑标签、复制区块、删除选择的区块
注:可在标注前进行标签添加,添加位置如下,在标注时添加也可:
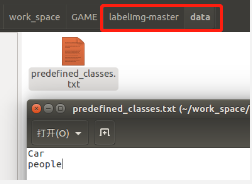
4.转换文件格式
1)去除未标注的图片
标注好的图片及xml文件如下:

在标注的过程中,有些图片可能不一定有需要检测的目标,因此可能不会进行标注,在所有图片标注完可以用脚本进去除,脚本如下:
import os
imagePath = 'Images' #图片文件夹
labelPath = 'labelxml' #xml文件文件夹
imageFileList = os.listdir(imagePath)
labelFileList = os.listdir(labelPath)
for fileName in imageFileList:
fileWName = fileName[:-3]
fileWName += "xml"
if fileWName not in labelFileList:
os.remove(imagePath + "/" + fileName)
for fileName in labelFileList:
fileWName = fileName[:-3]
fileWName += "jpg"
if fileWName not in imageFileList:
os.remove(labelPath + "/" + fileName)此时,文件夹剩下的都是可以数据
2)xml文件格式转换
由于yolo训练要求以txt文件形式进行,因此需要转换文件格式,xml文件格式如下:
<annotation>
<folder>Images</folder>
<filename>07-08-1.avi_(13400).png</filename>
<path>/home/Images/car.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1280</width>
<height>720</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>People</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>780</xmin>
<ymin>242</ymin>
<xmax>890</xmax>
<ymax>360</ymax>
</bndbox>
</object>
</annotation>将标注的xml文件和对应的jpg图片放在一起,把xml文件转换成txt文件,运行如下脚本xml2txt.py:
import os
import re
import cv2
import sys
# 图片及xml文件存放路径
src0 = '/home/work_space/GAME/YOLO/all/'
# 格式转换后存放图片及txt文件的路径
dst0 = '/home/work_space/YOLO/0703/'
# label类名文件
voc_name0 = '/home/work_space/GAME/labelImg-master/data/predefined_classes.txt'
if __name__ == '__main__':
if len(sys.argv) < 4:
print('yolo-voc program need 5 argv')
else:
p = int(sys.argv[1])
src = sys.argv[2]+'/'
dst = sys.argv[3]+'/'
if len(sys.argv) > 4:
voc_name = sys.argv[4]
voc_flag = True
else:
voc_name = ''
voc_flag = False
listd = os.listdir(src)
txt = re.compile(r'.*(xml)')
listdir = []
for i in listd:
if re.findall(txt, i):
listdir.append(i)
cc = r'<xmin>(.*)</xmin>'
xxmin = re.compile(r'<xmin>(.*)</xmin>')
yymin = re.compile(r'<ymin>(.*)</ymin>')
xxmax = re.compile(r'<xmax>(.*)</xmax>')
yymax = re.compile(r'<ymax>(.*)</ymax>')
wwidth = re.compile(r'<width>(.*)</width>')
hheight = re.compile(r'<height>(.*)</height>')
nname = re.compile(r'<name>(.*)</name>')
if voc_flag == True:
f = open(voc_name)
listname = f.read()
f.close()
p = 0
for i in listdir:
i_file = open(src+i, 'r')
i_content = i_file.read()
i_file.close()
print(i)
#print(i_content)
name = (re.findall(nname, i_content)[0])
if voc_flag == True:
index = listname.index(name)
else:
index = 0
txtname0 = dst + str(p).zfill(4) + '.txt'
f = open(txtname0, 'w')
width = int(re.findall(wwidth, i_content)[0])
height = int(re.findall(hheight, i_content)[0])
for j in range(re.findall(xxmin, i_content).__len__()):
xmin = int(re.findall(xxmin, i_content)[j])
ymin = int(re.findall(yymin, i_content)[j])
xmax = int(re.findall(xxmax, i_content)[j])
ymax = int(re.findall(yymax, i_content)[j])
if j != 0:
f.write('\n')
f.write(str(index)+' '+'%0.4f' % ((float(xmin)+float(xmax))/float(width)/2)+' '
+ '%0.4f' % ((float(ymin) + float(ymax))/float(height)/2)+' '+'%0.4f'
% (float(xmax-xmin)/float(width))+' '+'%0.4f' % (float(ymax-ymin)/float(height)))
f.close()
imgsource = src+i
imgname0 = imgsource.replace('xml', 'jpg')
img = cv2.imread(imgname0)
if img is None:
imgname0 = imgname0.replace('jpg','JPG')
img = cv2.imread(imgname0)
if img is None:
imgname0 = imgname0.replace('JPG', 'png')
img = cv2.imread(imgname0)
imgdst = dst+str(p).zfill(4)+'.jpg'
cv2.imwrite(imgdst, img)
p += 1
执行命令如下:
python3 xml2txt.py 0 /home/GAME/work_space/YOLO/0703/all /home/GAME/work_space/YOLO/0703/txtdata /home/YOLO/darknet/data/voa.names参数解释:
python3 xml2txt.py :表示使用python3运行xml2txt.py文件
0 :表示文件重命名的开始序列,本次图片处理从0000.jpg开始
/home/GAME/work_space/YOLO/0703/all :表示所有图片和xml文件所在的路径
/home/GAME/work_space/YOLO/0703/txtdata : 表示整理后图片和txt文件存放的路径
/home/YOLO/darknet/data/voa.names : darknet下标注目标的类名
注:后面不加/
文件结果如下:

3)所有图片和txt文件汇总成一个txt文件,为后面训练文件作准备,运行如下脚本alltxt.py:
import os
import re
import sys
src = '/home/YOLO/darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main/'
path = '/home/YOLO/darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main/'
if __name__ == '__main__':
if len(sys.argv) < 2:
print('piclist2txt program need 1 argv')
else:
src = sys.argv[1]+'/'
if len(sys.argv) > 2:
path = sys.argv[2]+'/'
else:
path = src
filedir = os.listdir(src)
imgfile = re.compile(r'.*(jpg|jpeg|JPEG)')
listdir = []
for i in filedir:
if re.match(imgfile, i):
listdir.append(i)
f=open(src+'train.txt', 'w')
for i in listdir:
print(path+i)
f.write(path+i+'\n')
f.close()执行命令如下:
python3 alltxt.py /home/work_space/YOLO/0703/txtdata python3 alltxt.py :表示使用python3运行alltxt.py文件
/home/work_space/YOLO/0703/txtdata :表示所有整理后图片和txt文件存放的路径
注:后面不加/
结果如下:
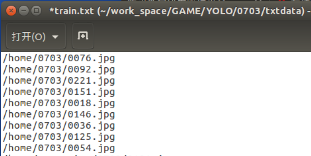
4)在darknet/scripts目录下创建目录
├─ VOCdevkit
└─ VOC2007
├─ ImageSets
├─ Layout
├─ Main
├─ train.txt注:train.txt文件是以上所有图片和txt文件汇总的txt文件,用以训练
5.修改配置文件并训练
自行下载darknet
1)修改data/voc.names,voc.names文件内容如下:
Car
People2)修改cgf/voc.data,voc.data文件内容如下:
classes= 1
train = /home/YOLO/darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main/train.txt
valid = /home/YOLO/darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main/train.txt
names = data/voc.names
backup = backup3)修改cfg/yolov3-voc.cfg,修改yolo标签中的classes, 和此yolo标签上的convolutional的filters数值,共有3组,yolov3-voc.cfg文件内容如下:
[convolutional]
size=1
stride=1
pad=1
filters=21 #修改filters=3*(classes+1+4),如本次训练classes为2
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=2 #修改class的个数,如本次训练,类别为2
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=14)下载预训练权重文件并训练
wget https://pjreddie.com/media/files/darknet53.conv.74
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74注:建议使用GPU训练模型,节约时间成本















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









