







摘要
《Federated Learning of a Mixture of Global and Local Models》这篇论文的目的是在Local和Global之间寻找一个trade off,对全局模型和局部模型进行混合,并提出适用于这一想法的几种新的梯度下降算法,如L2GD,该算法还能改进通信复杂度。
本文的两项动机
1、全局模型在客户端的实用性问题。
2、传统的LGD在理论上,并不能改善通信复杂度。
目标函数
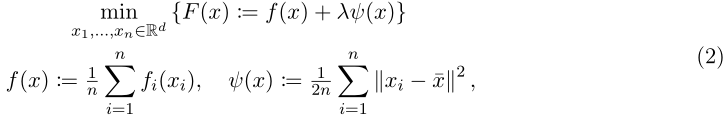
其中f(x)是全局平均损失值,λ≥0是惩罚项参数,
x
1
x_1
x1…
x
n
x_n
xn∈
R
d
R^d
Rd是本地模型,x:=(
x
1
x_1
x1…
x
n
x_n
xn)∈
R
n
d
R^{nd}
Rnd是混合模型,x_hat是所有本地模型的平均值。
文章中假设
f
i
f_i
fi:
R
d
R^d
Rd→R是L-smooth和μ-strongly convex,因此(2)有唯一解,表示为:
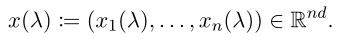
Local model(λ=0):
x
i
x_i
xi(0)是设备i仅基于本地数据训练得到的本地模型。
Mixed model(λ∈(0,∞)):当λ增大时,惩罚项λψ(x)也将增大,此时需要保持通信(及时更新全局模型),防止各个性化模型存在过大差异。
Global model(λ=∞):当λ→无穷时,优化目标将由(2)变成优化f,这样就会使每个本地模型变成单纯的全局模型,x(∞) := (
x
1
x_1
x1(∞),…,
x
n
x_n
xn(∞))。即FedAvg:
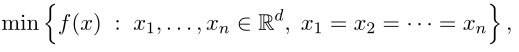
最优解的特征
定理一:
随着λ的增长,最优局部模型
x
i
x_i
xi(λ)越来越相似。the loss f(x(λ)) increases with λ, but never exceeds the optimal global loss f(x(∞)) of the standard FL formulation (1)

定理二:
设备i的最优个性化模型是通过"所有设备上的最优个性化模型的平均"减去设备i上的损失函数的梯度来获得的。所有设备都达到最优个性化模型时,所有本地梯度的总和为0,这在λ = ∞时显然是正确的,当λ > 0时就不那么明显。
L2GD: Loopless Local GD
L2GD其实就是通过概率(0<p<1)选择进行让目标函数导数中的▽f(x)还是▽ψ(x)来计算梯度G(x),定义F在x∈
R
n
d
R^{nd}
Rnd的随机梯度G(x)如(7)所示。本地模型更新:
x
k
+
1
x^{k+1}
xk+1 =
x
k
x^{k}
xk - aG(
x
k
x^{k}
xk),其中步长a是受限的,目的是使aλ/np≤1/2。将▽f或▽ψ的公式代入(7)便可以得到L2GD的完整表达形式,如Algorithm 1所示。
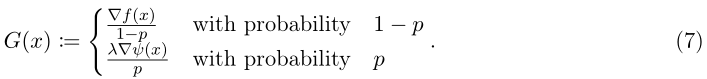

总的来说,当算法采取的local GD步骤越多,个性化模型越接近纯局部模型;采取的average步骤越多,个性化模型越接近它们的平均值。执行local GD与average的相对次数由参数p控制:local GD的预期次数为1/p,连续average的预期次数为1/(1-p)。
定义Device→Master和后续的Master→Device称为一轮通信。L2GD的第k次迭代中通信的预期轮次为p(1-p)k。
主要贡献
一、能够混合全局模型和局部模型的新目标函数。
通过加入一个系数为λ的惩罚项ψ(λ>0),使各个性化模型之间不会存在过分差异。
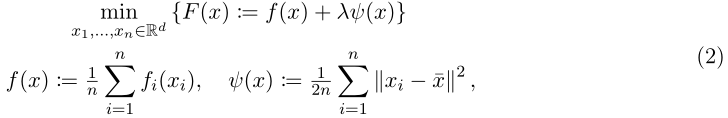
二、文章证明的的关于目标函数(2)的几个结论
1、当λ设置为零时,每个设备只根据自己的本地数据训练模型,这样子效果通常比较一般。
2、证明了最优局部模型以O(1/λ)的速率收敛至
m
i
n
1
/
n
Σ
i
=
1
n
f
i
(
x
)
min\ 1/n Σ_{i=1}^nf_i(x)
min 1/nΣi=1nfi(x)
3、证明了所有局部模型
f
i
(
x
)
f_i(x)
fi(x)的loss的和不会高于全局模型
1
/
n
Σ
i
=
1
n
f
i
(
x
)
1/n Σ_{i=1}^nf_i(x)
1/nΣi=1nfi(x)的loss。
三、用于求解目标函数(2)的梯度下降算法:Loopless Local Gradient Descent (L2GD)
L2GD与Local Gradient Descent(LGD)在本质上其实差不多,主要区别在于它们在实际应用中的通信复杂度。
该算法通过概率控制是执行设备训练还是服务器聚合,并且给设备训练更高的概率,这样就能进行多次本地训练从而改善通信复杂度,当然,本地训练的迭代次数也不是固定的,而是随机的。GD更新分为两次,一次是在设备训练时,一次是在服务器聚合后;
通信次数:当λ→0时,每个设备几乎仅基于本地数据训练局部模型,通信轮数趋于0。当λ→∞时,目标函数收敛于最优全局模型,此时达到通信轮数的上限O((L/μ)log(1/ε))
四、局部目标函数用于解决什么问题?
局部更新的作用并不是单纯的降低通信复杂度。他们的作用是引导函数找到一种全局模型和纯局部模型的混合。
我们越希望函数偏向于纯粹的局部模型(即惩罚参数λ越小),L2GD所采取的局部步骤就越多,并且L2GD的总通信复杂度就越好。
实验
文章比较了三种不同的方法:L2SGD+,带有局部下采样的L2GD(附录中的L2SGD),只为ψ构造局部子采样和控制变量的L2GD(附录中的L2SGD2)。
对于同构数据,文章对数据进行随机打乱。对于异构数据,文章首先根据标签对数据进行排序,然后根据当前顺序构建本地数据。

实验结果展示了减少方差的重要性–它确保了L2SGD+的快速全局收敛。
L2SGD+线性收敛到全局最优解,而L2SGD和L2SGD2都收敛到某个邻域。
每种方法都适用于同构或异构数据,这说明数据异质性不会影响所提出方法的收敛速度。
讨论
如前文所述,L2GD的本地更新为的不单是降低通信复杂度,其主要目的是引导方法找到一种全局模型和纯本地模式的混合。
其优化目标为
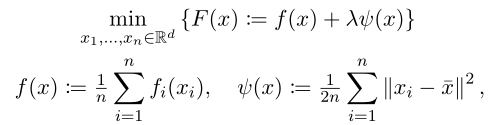
对比FedProx:

两个优化目标看起来差不多,都是在FedAvg的基础上加入了一个正则化项。区别在于L2GD的目标函数是从客户端的角度出发(训练个性化模型),FedProx的目标函数是从服务器的角度出发(训练统一的全局模型)。这也是为什么FedProx的正则参数为0时算法等于FedAvg,而L2GD的正则参数为无穷时算法等于FedAvg。
















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











