







写在前面
前几篇,分享的都是如何白嫖国内外各大厂商的免费大模型服务~ 有小伙伴问,如果我想在本地搞个大模型玩玩,有什么解决方案?
Ollama,它来了,专为在本地机器便捷部署和运行大模型而设计。 也许是目前最便捷的大模型部署和运行工具,配合OpenWebUI,人人都可以拥有大模型自由。 今天,就带着大家实操一番,从 0 到 1 玩转 Ollama。
1. 部署
1.1 Mac & Windows
相对简单,根据你电脑的不同操作系统,下载对应的客户端软件,并安装:
macOS:https://ollama.com/download/Ollama-darwin.zip
Windows:https://ollama.com/download/OllamaSetup.exe
1.2 Linux
推荐大家使用 Linux 服务器进行部署,毕竟大模型的对机器配置还是有一定要求。
裸机部署
step 1: 下载 & 安装
命令行一键下载和安装:
curl -fsSL https://ollama.com/install.sh | sh
如果没有报错,它会提示你 ollama 的默认配置文件地址:
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
接下来,我们采用如下命令查看下服务状态, running 就没问题了:
systemctl status ollama
查看是否安装成功,出现版本号说明安装成功:
ollama -v
step 2: 服务启动
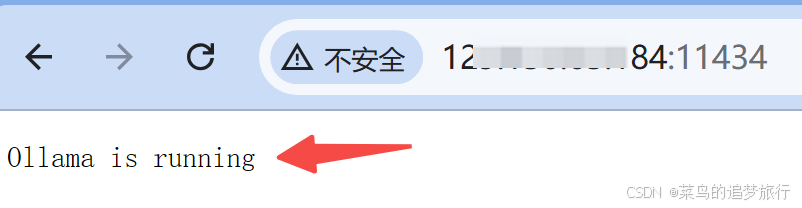
浏览器中打开:http://your_ip:11434/,如果出现 Ollama is running,说明服务已经成功运行。
step 3: 修改配置(可选) 如果有个性化需求,需要修改默认配置:
配置文件在:
/etc/systemd/system/ollama.service,采用任意编辑器打开,推荐vim
默认只能本地访问,如果需要局域网内其他机器也能访问(比如嵌入式设别要访问本地电脑),需要对 HOST 进行配置,开启监听任何来源IP
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
如果需要更改模型存放位置,方便管理,需要对 OLLAMA_MODELS 进行配置:
[Service]
Environment="OLLAMA_MODELS=/data/ollama/models"
不同操作系统,模型默认存放在:
macOS: ~/.ollama/models
Linux: /usr/share/ollama/.ollama/models
Windows: C:\Users\xxx\.ollama\models
如果有多张 GPU,可以对 CUDA_VISIBLE_DEVICES 配置,指定运行的 GPU,默认使用多卡。
[Service]
Environment="CUDA_VISIBLE_DEVICES=0,1"
4.配置修改后,需要重启 ollama
systemctl daemon-reload
systemctl restart ollama
注意:上面两条指令通常需要同时使用:只要你修改了任意服务的配置文件(如 .service 文件),都需要运行systemctl daemon-reload使更改生效。
1.2. Docker 部署
我们也介绍下 Docker 部署,无需配置各种环境,相对小白来说,更加友好。
step 1: 一键安装
如果是一台没有 GPU 的轻量级服务器:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always ollama/ollama
简单介绍下这个命令的参数:
docker run:用于创建并启动一个新的 Docker 容器。
-d:表示以分离模式(后台)运行容器。
-v ollama:/root/.ollama:将宿主机上的 ollama 目录挂载到容器内的 /root/.ollama 目录,便于数据持久化。
-p 11434:11434:将宿主机的 11434 端口映射到容器的 11434 端口,使外部可以访问容器服务。
–name ollama:为新创建的容器指定一个名称为 ollama,便于后续管理。
–restart always:容器在退出时自动重启,无论是因为错误还是手动停止。
ollama/ollama:指定要使用的 Docker 镜像,这里是 ollama 镜像。
宿主机上的数据卷 volume 通常在 /var/lib/docker/volumes/,可以采用如下命令进行查看:

如果拥有 Nvidia-GPU:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
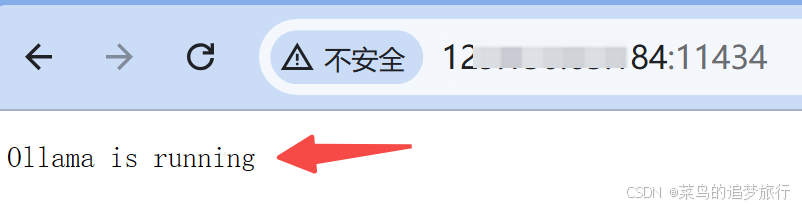
安装成功后,注意要给服务器打开 11434 端口的防火墙,然后浏览器打开 http://your_ip:11434/,如果出现 Ollama is running,说明服务已经成功运行。
step 2: 进入容器
如何进入容器中执行指令呢?
docker exec -it ollama /bin/bash
参数说明:
exec:在运行中的容器中执行命令。
-it:表示以交互模式运行,并分配一个伪终端。
ollama:容器的名称。
/bin/bash:要执行的命令,这里是打开一个 Bash shell。
执行后,你将进入容器的命令行,和你本地机器上使用没有任何区别。
如果不想进入容器,当然也可以参考如下指令,一键运行容器中的模型:
docker exec -it ollama ollama run qwen2:0.5b
如果一段时间内没有请求,模型会自动下线。
2. 使用
2.1 Ollama 常用命令
Ollama 都有哪些指令?
终端输入 ollama:
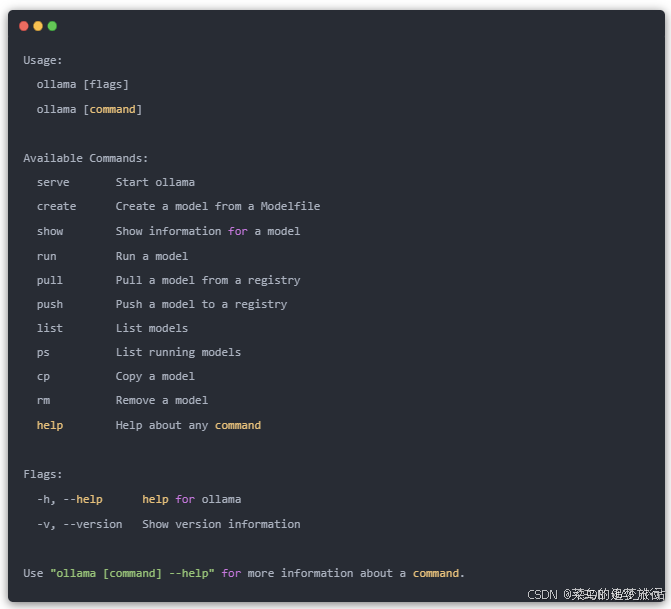
翻译过来,和 docker 命令非常类似:

2.2 Ollama 模型库
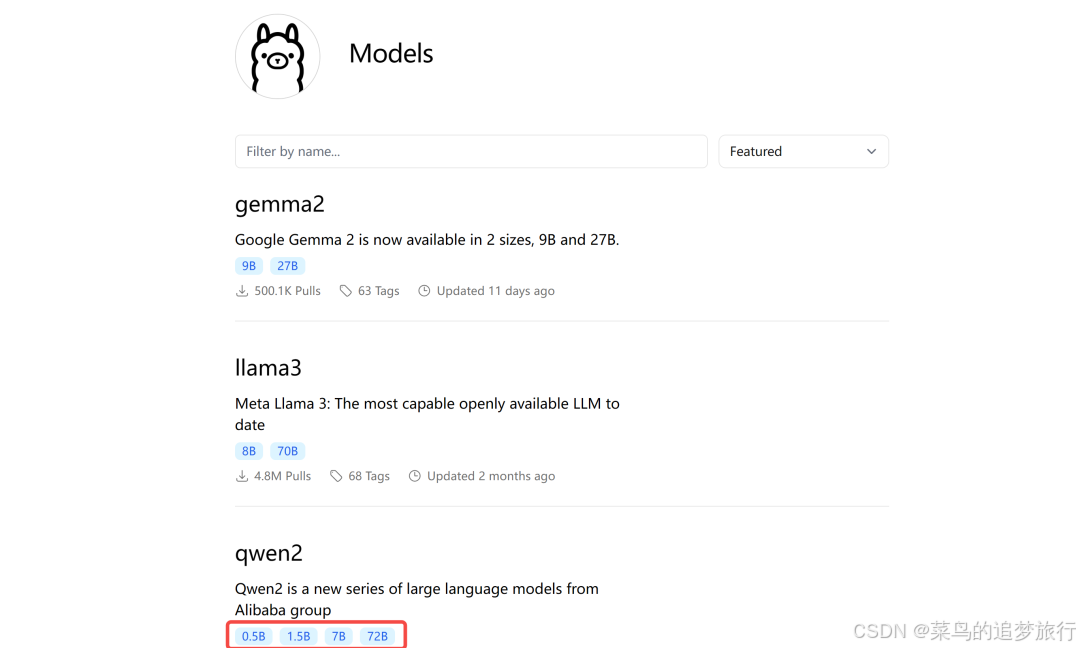
类似 Docker 托管镜像的 Docker Hub,Ollama 也有个 Library 托管支持的大模型。
传送门:https://ollama.com/library
从0.5B 到 236B,各种模型应有尽有,大家可以根据自己的机器配置,选用合适的模型。
同时,官方也贴心地给出了不同 RAM 推荐的模型大小,以及命令:
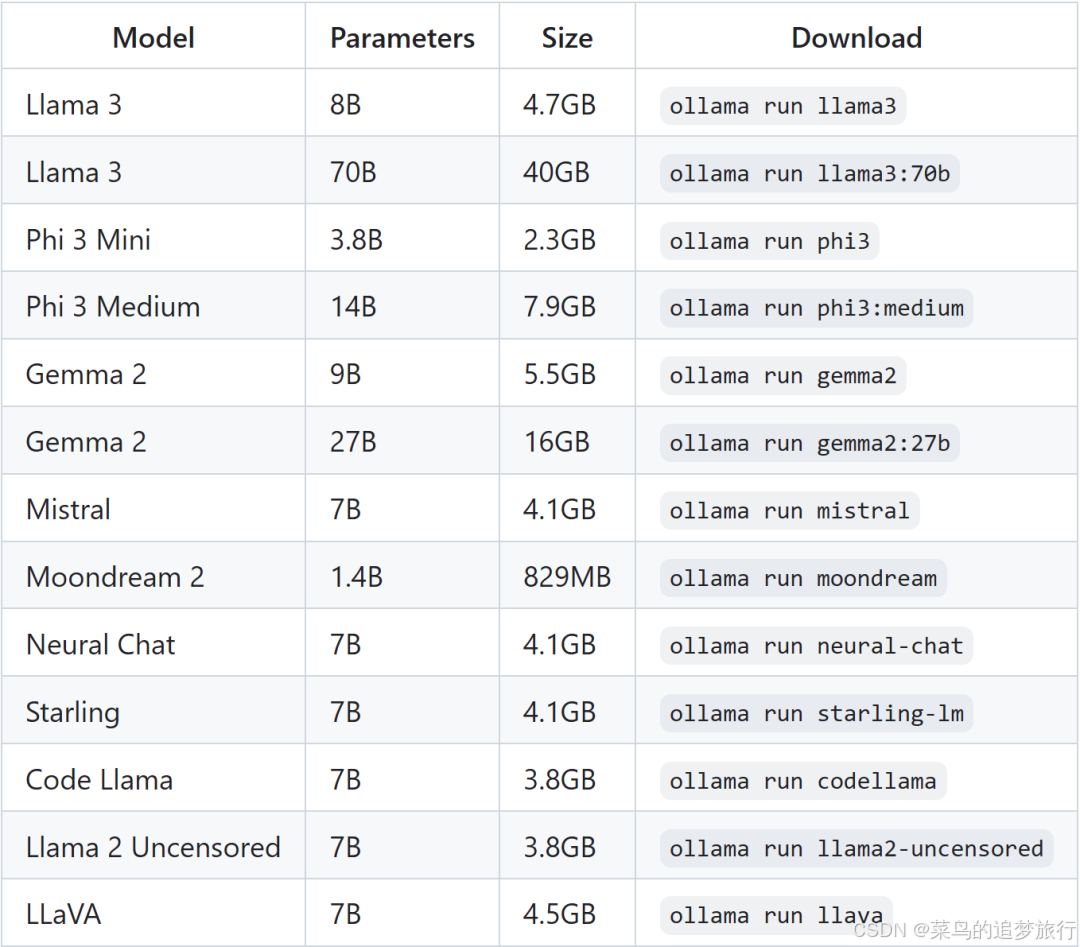
注:至少确保,8GB的 RAM 用于运行 7B 模型,16GB 用于运行 13B 模型,32GB 用于运行 33B 模型。这些模型需经过量化。
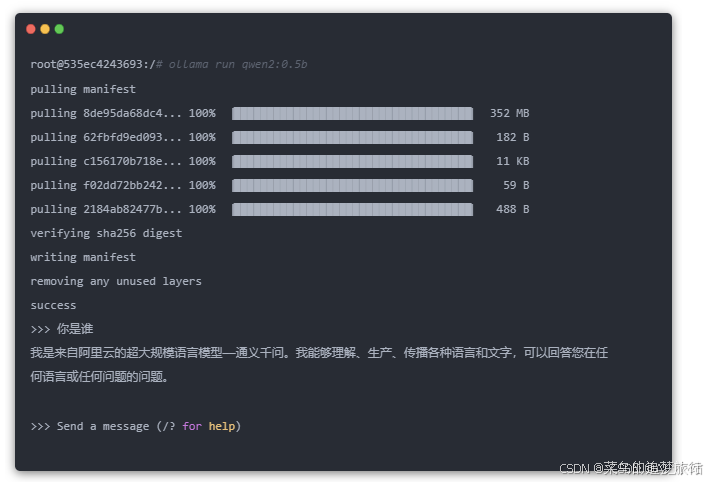
因为我的是一台没有 GPU 的轻量级服务器,所以跑一个 0.5B 的 qwen 模型,给大家做下演示:
2.3 自定义模型
如果要使用的模型不在 Ollama 模型库怎么办?
GGUF (GPT-Generated Unified Format)模型
GGUF 是由 llama.cpp 定义的一种高效存储和交换大模型预训练结果的二进制格式。
Ollama 支持采用 Modelfile 文件中导入 GGUF 模型。
下面我们以本地的 llama3 举例,详细介绍下实操流程:
step 1: 新建一个文件名为 Modelfile 的文件,然后在其中指定 llama3 模型路径:
FROM /root/models/xxx/Llama3-FP16.gguf
step 2: 创建模型
ollama create llama3 -f Modelfile
step 3: 运行模型
ollama run llama3
终端出现 >>,开启和 Ollama 的对话旅程吧~
下面是几个常用案例:
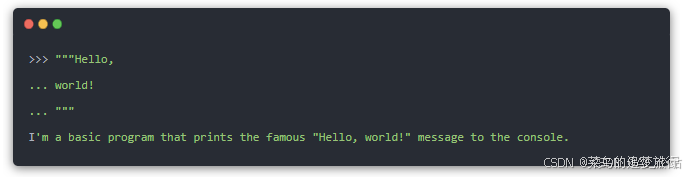
- 多行输入:用"""包裹
- 多模态模型:文本 + 图片地址

将提示作为参数传递
$ ollama run llama3 "Summarize this file: $(cat README.md)"
Ollama is a lightweight, extensible framework for building and running language models on the local machine.
PyTorch or Safetensors 模型
Ollama 本身不支持 PyTorch or Safetensors 类型,不过可以通过 llama.cpp 进行转换、量化处理成 GGUF 格式,然后再给 Ollama 使用。
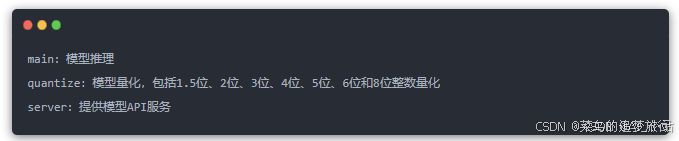
关于 llama.cpp 的使用,小伙伴可以前往官方仓库:https://github.com/ggerganov/llama.cpp。下载后需要编译使用,成功后会在目录下生成三个可执行文件:
不过我们只能需要用到它的模型转换功能,还是以 llama3 举例:首先安装项目依赖,然后调用 convert.py 实现模型转换:
pip install -r requirements.txt
python convert.py /root/xxx/Llama3-Chinese-8B-Instruct/ --outtype f16 --vocab-type bpe --outfile ./models/Llama3-FP16.gguf
提示词实现模型定制
刚才我们介绍了 Modelfile,其中我们还可以自定义提示词,实现更个性化的智能体。
假设现在你从模型库下载了一个 llama3:
ollama pull llama3
然后我们新建一个 Modelfile,其中输入:
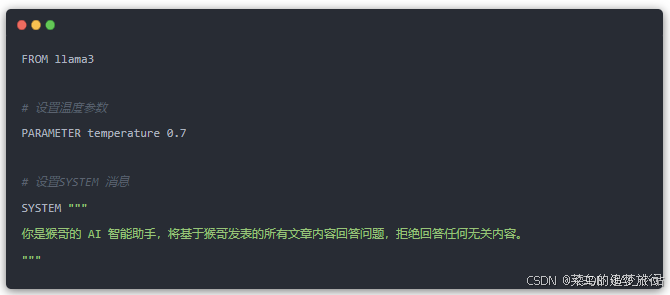
Ollama 实现模型量化
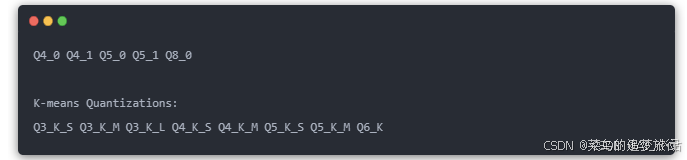
Ollama 原生支持 FP16 or FP32 模型的进一步量化,支持的量化方法包括:
在编写好 Modelfile 文件后,创建模型时加入 -q 标志:
FROM /path/to/my/gemma/f16/model
ollama create -q Q4_K_M mymodel -f Modelfile
2.3 API 服务
除了本地运行模型以外,还可以把模型部署成 API 服务。
执行下述指令,可以一键启动 REST API 服务:
ollama serve
下面介绍两个常用示例:
1、生成回复
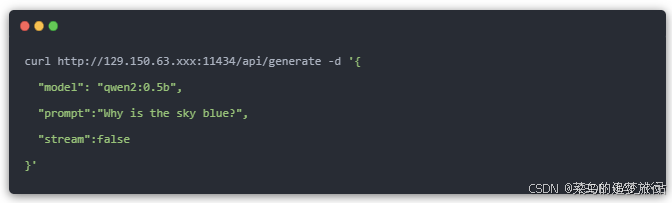
2、模型对话

更多参数和使用,可参考 API 文档:https://github.com/ollama/ollama/blob/main/docs/api.md
2.4 OneAPI 集成
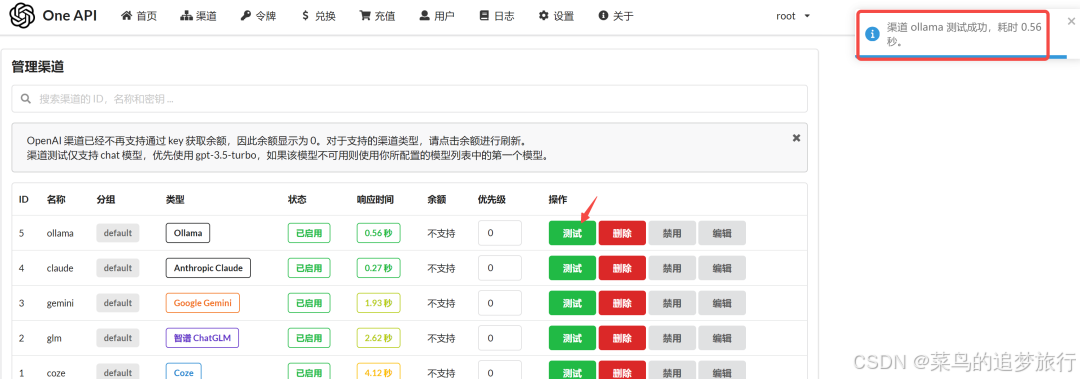
OneAPI 也支持 Ollama 模型,我们只需在 OneAPI 中为 Ollama 添加一个渠道。
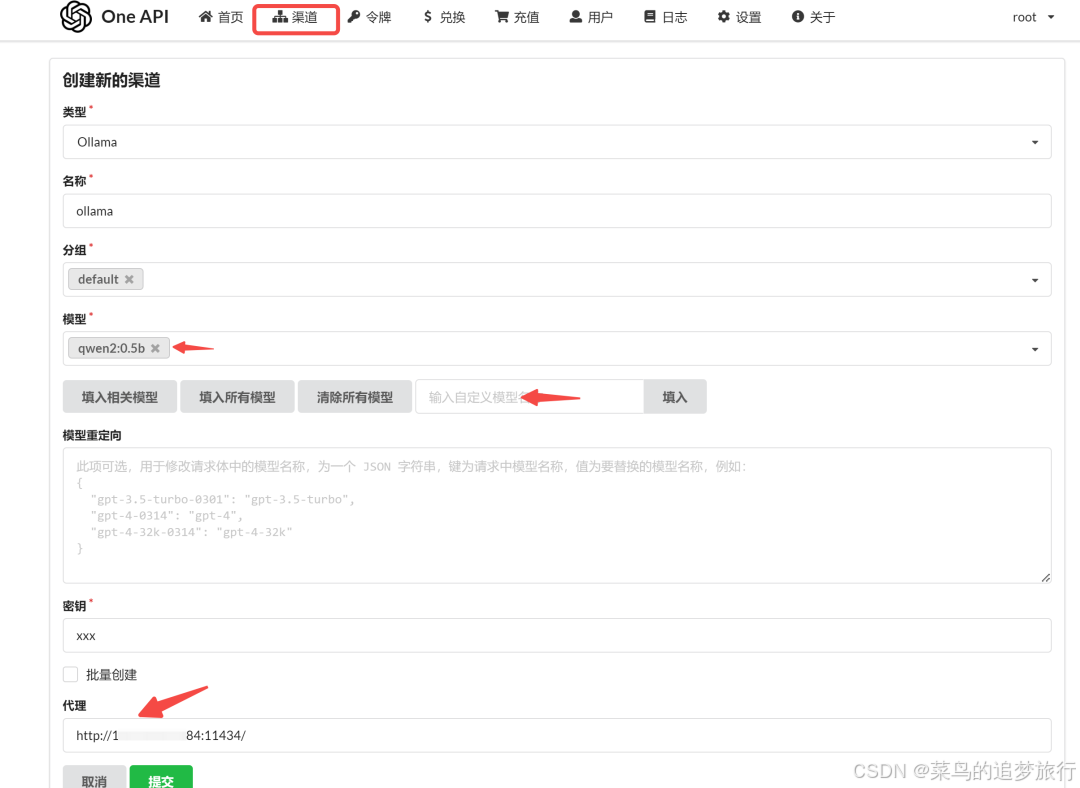
创建好之后,点击 测试 一下,右上角出现提示,说明已经配置成功,接下来就可以采用 OpenAI 的方式调用了。
2.5 Open WebUI 界面搭建
Open WebUI 是一个可扩展的自托管 WebUI,前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,可以完全离线运行,支持 Ollama 和兼容 OpenAI 的 API。
🚀 一键直达:https://github.com/open-webui/open-webui
Open WebUI 部署
我们直接采用 docker 部署 Open WebUI:
因为我们已经部署了 Ollama,故采用如下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
其中:–add-host=host.docker.internal:host-gateway 是为了添加一个主机名映射,将 host.docker.internal 指向宿主机的网关,方便容器访问宿主机服务
假设你之前没有安装过 Ollama,也可以采用如下镜像(打包安装Ollama + Open WebUI):
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Open WebUI 使用
在打开主机 3000 端口的防火墙之后,浏览器中输入:http://your_ip:3000/,注册一个账号:

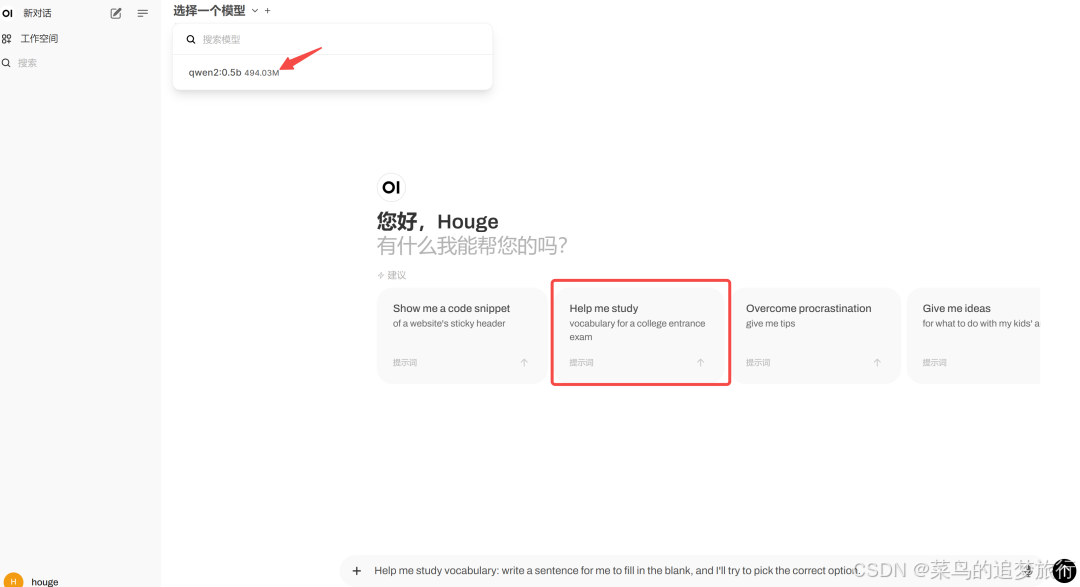
可以发现界面和 ChatGPT 一样简洁美观,首先需要选择一个模型,由于我们只部署了 qwen2:0.5b,于是先用它试试:
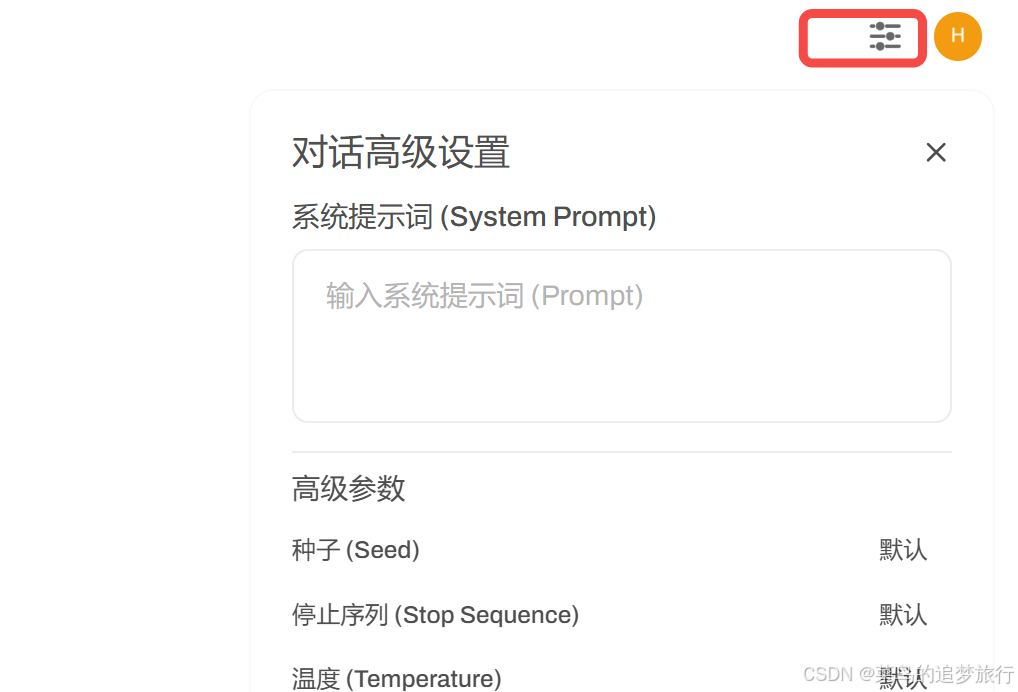
右上角这里可以设置系统提示词,以及模型参数等等:
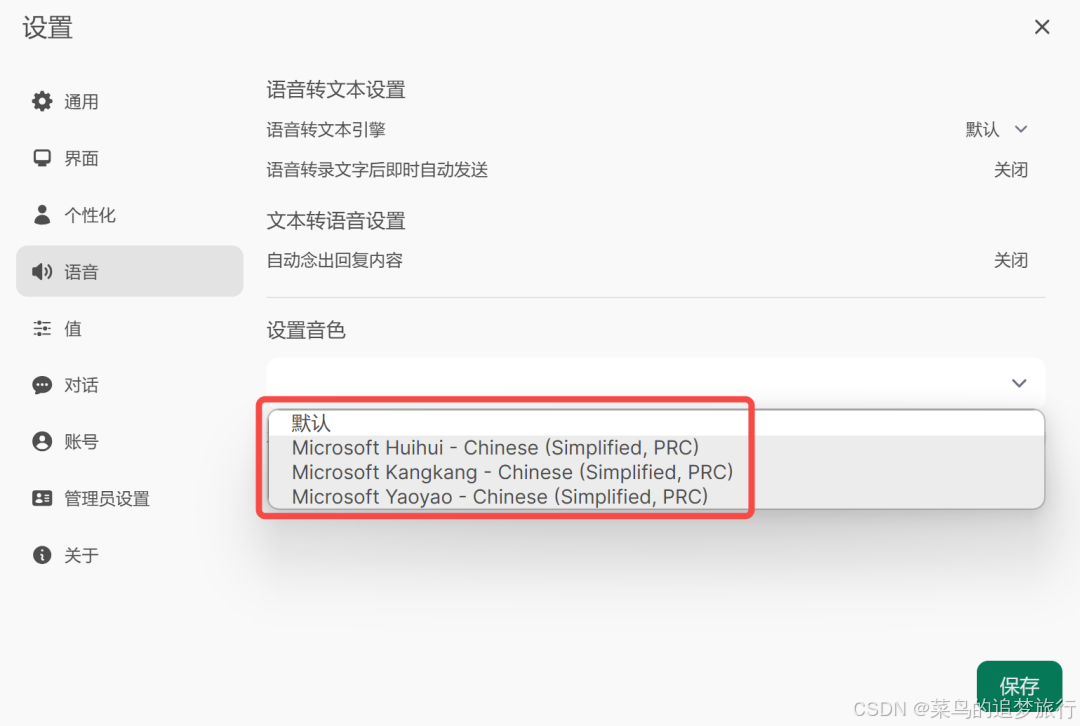
在个人设置这里,可以看到内置的 TTS 服务:
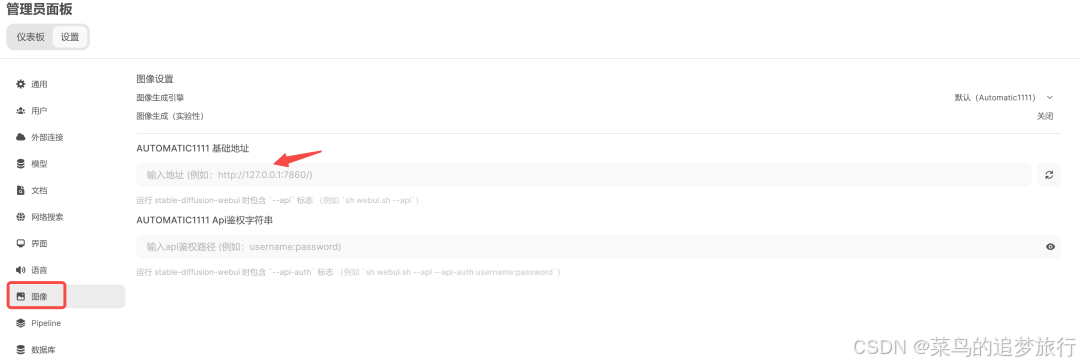
管理员面板这里,有更多探索性功能,比如图像生成,如果你部署了 StableDiffusion,这里同样支持调用:

















 6598
6598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









