







疫情期间,过着朝十一晚十一的生活,so,打开PyCharm,编写了此爬虫。
首先,编写该爬虫的初衷是勤(you)奋(qiong)好(you)学(lan),话说宅家期间老婆一直让我下三生三世枕上书这部剧,而这部剧每周四又在腾讯视频VIP持续更新。因为没有VIP账号,就找了一个爬虫相对友好并支持VIP视频下载的网站,这样就实现软件自动查询解析并下载视频。
爬虫思路,进入这个视频网站的首页,在首页中查询对应视频的名称,之后自动进入这个视频对应的一级子页面,解析子页面里对应整部电视剧的网页地址二级子页面,再自动进入页面解析每集的下载地址并保存成列表,最后就通过requests.get下载对应的文件。
通过该爬虫get的技能:
1、使用CHROME的无痕模式,破解网站对爬虫访问的限制(之前一直不知道无痕模式是干嘛的);(该视频网站对老用户有访问限制,只能以新用户的request header来进入才不会被封)
2、加深了开发者工具下network功能的解析能力,并对HTML内容、标签、正则表达式等基础知识进行了又一次的强化;加深认识了request库的get和post功能的基础原理;
未来爬虫改善的空间:
1、目前的下载只是用了单线程,未来考虑多线程及调用下载软件(如IDM)等,加快下载的速度及链接的可靠性;
2、用户界面可以优化得友好一些:运行过程中其实程序在执行,但可能因为网速的关系会比较慢,未来还可以在中间增加用户提示信息;
3、解决部分BUG;
4、打包成可执行exe文件,并可设置文件保存目录等信息;
5、使用request.urlretrieve功能下载,一直会报远程连接错误,以后需研究下原因。
使用说明:
1.程序开始运行

2.解析的一级子网页页面地址

3.爬取二级子网页中每集视频的网址

4.选择需要下载的集数,直接打数字就行
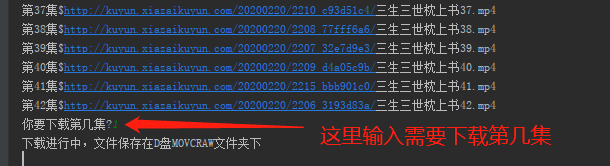
5.下载完成后的视频保存在D盘MOVCRAW文件夹下

代码编程环境:
1.PyCharm 2019.1.3 x64
2.Python 3.7.6 64位
3.需要预先在D盘新建一个MOVCRAW文件夹,保存爬取的视频。
因本人纯Python爱好者,毫无编程经验,代码很乱,各位CSDN网友轻拍。
import requests
from bs4 import BeautifulSoup
import re
#from urllib import request
#from urllib.parse import quote
import time
import sys
def getHTMLText(url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '__cfduid=d1d1427e02a712d32a07dfbaf86dd47a21581431228; PHPSESSID=6q3sji6vo4chsq5f72guu8qcf7; __51cke__=; __tins__19534235=%7B%22sid%22%3A%201581859108786%2C%20%22vd%22%3A%206%2C%20%22expires%22%3A%201581861615220%7D; __51laig__=6',
'Host': 'www.kuyunzyw.tv',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









