






论文来源《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》
prompt总步骤
人工定制或学习一个离散的或连续的提词模版
- 应用一个模板,这是一个文本字符串,它有两个槽:一个是输入槽[X],用于输入x,另一个是答案槽[Z],用于中间生成的答案文本z,以后会被映射到y。
- 用输入文本x填充槽[X]。
在答案空间搜索最优填词
接下来,我们寻找最高分的文本zˆ,使LM的得分最大化。在生成任务的情况下,Z可以是整个语言的范围,在分类的情况下,也可以是语言中的一小部分词,比如定义Z={“优秀”、“良好”、“尚可”、“糟糕”、“可怕”}来代表Y={++, +, ~, -, --}中的每个类别。
然后我们定义一个函数fill(x′, z),将潜在的答案z填入提示x′中的位置[Z]。特别是,如果提示被填入一个真实的答案,我们将把它称为answered prompt。最后,我们通过使用预先训练好的LM P(-;θ)计算其对应的已填充提示的概率来搜索潜在的答案集z。
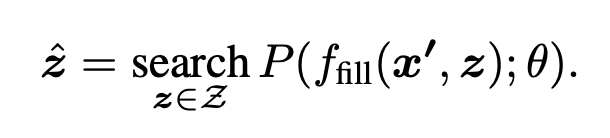
将最优填词映射到下层任务label
将Z映射到Y上,如“优秀”->“+++”

Prompt Engineering
提示工程是创建一个提示函数fprompt(x)的过程,该函数能使下游任务获得最有效的表现。在以前的许多工作中,这涉及到提示模板工程,即由人类工程师或算法为模型预期执行的每项任务寻找最佳模板。如图1的 "提示工程 "部分所示,人们必须首先考虑提示的形状,然后决定是采取人工还是自动的方法来创建所需形状的提示,详见下文。
Prompt Shape
如上所述,主要有两种类型的提示:cloze prompt,即在文本字符串中填空,以及prefix prompt,即延续一个字符串的前缀。选择哪一种,既取决于任务,也取决于用于解决该任务的模型。一般来说,对于有关生成的任务,或正在使用标准的自动回归LM解决的任务,前缀提示往往更有利,因为它们与模型的从左到右的性质相匹配。对于使用屏蔽式LM解决的任务,cloze提示很适合,因为它们与预训练任务的形式非常接近。全文重构模型的用途更广,既可以使用cloze提示,也可以使用前缀提示。最后,对于一些关于多输入的任务,如文本对分类,提示模板必须包含两个输入的空间,[X1]和[X2],或更多。
Manual Template Engineering
也许创建提示的最自然方式是根据人类的介绍手动创建直观的模板。例如,开创性的LAMA数据集提供了手动创建的cloze模板来探测LM的知识。
Automated Template Learning
虽然手工制作模板的策略很直观,而且确实可以在一定程度上解决各种任务,但这种方法也有几个问题。
- 创建和测试这些prompt需要时间和经验,特别是对于一些复杂的任务,如语义解析;
- 即使是有经验的提示设计者也可能无法手动发现最佳提示。
为了解决这些问题,人们提出了一些方法来实现模板设计过程的自动化。比如直接在LM的嵌入空间描述我们的prompt。
- Discrete Prompts
关于发现离散提示(又称硬提示)的工作会自动搜索在离散空间中描述的模板,通常对应于自然语言短语。我们在下文中详细介绍了为此提出的几种方法。
- Prompt Mining MINE方法是一种基于挖掘的方法,在给定一组训练输入x和输出y的情况下,自动寻找模板。该方法在大型文本语料库(如维基百科)中搜索包含x和y的字符串,并找到输入和输出之间的中间词或依赖路径。经常出现的中间词或依赖性路径可以作为模板,如"[X]中间词[Z]"。
- Prompt Paraphrasing 基于转述的方法采用一个现有的种子提示(例如人工构建的或挖掘的),并将其转述为一组其他的候选提示,然后选择一个在目标任务上达到最高训练精度的提示。这种转述可以通过多种方式完成,包括将提示语往返翻译成另一种语言,然后再翻译回来,使用词库中的短语替换,或者使用专门优化的神经提示语改写器来提高使用该提示语的系统的准确性。值得注意的是,在输入x被输入到提示模板后进行转述,允许为每个单独的输入生成不同的转述。
- Gradient-based Search 在实际的标记上应用了基于梯度的搜索,以找到能够使得预训练的LM以生成正确目标预测的短序列。这种搜索是以迭代的方式进行的,通过prompt中的tokens进行踩点。在此方法的基础上,利用下游应用训练样本自动搜索模板标记,可以在提示场景中表现出强大的性能
- Prompt Generation其他作品将提示语的生成视为文本生成任务,并使用标准的自然语言生成模型来执行这一任务。将seq2seq预训练的模型T5引入模板搜索过程。由于T5已经在填补缺失跨度的任务上进行了预训练,他们使用T5来生成模板标记:(1)指定在模板内插入模板标记的位置(2)为T5提供训练样本来解码模板标记。Ben-David等人(2021)提出了一种领域适应算法,训练T5为每个输入生成独特的领域相关特征(DRFs;一组描述领域信息的关键词)。然后,这些DRFs可以与输入连接起来,形成一个模板,并被下游任务进一步使用。
- Prompt Scoring使用LM设计了一个输入(头-关系-尾三要素)的模板。他们首先手工制作了一组模板作为潜在的候选者,并填充输入和答案槽,形成一个填充的提示。然后,他们使用单向LM对这些填充的提示进行打分,选择具有最高LM概率的一个。这将导致为每个单独的输入定制模板。
- Continuous Prompts
因为构建提示的目的是找到一种能让LM有效执行任务的方法,而不是供人使用,所以没有必要将提示限定为人类可理解的自然语言。正因为如此,还有一些研究连续提示(又称软提示)的方法,直接在模型的嵌入空间中进行提示。具体来说,连续提示消除了两个约束。(1) 放宽模板词的嵌入是自然语言(如英语)词的嵌入的限制。(2)取消了模板由预训练的LM的参数决定的限制。相反,模板有自己的参数,可以根据下游任务的训练数据进行调整。我们在下面强调几个有代表性的方法。
- ** Prefix Tuning** 将连续的特定任务向量序列预加到输入中的方法,同时保持LM参数冻结。在数学上,这包括对以下对数似然目标进行优化,给定一个可训练的前缀矩阵Mφ和一个固定的预训练的LM参数为θ。
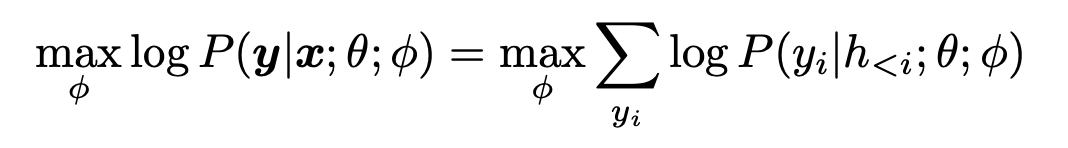
h<i = [h(1); - -; h(n)] 是时间步长i的所有神经网络层的连接。
如果相应的时间步长在前缀内,则直接从Mφ中复制(hi为Mφ[i]),否则就用预训练的LM计算。 - Tuning Initialized with Discrete Prompts还有一些方法是用已经创建的提示语或用离散提示语搜索方法发现的提示语来初始化连续提示语的搜索。例如,首先使用离散搜索方法如AUTOPROMPT搜索出一个初始模版,把这个模版的token作为起点,然后微调以提高任务准确性。这项工作发现,用人工模板初始化可以为搜索过程提供一个更好的起点。每个输入学习一个混合的软模板,其中每个模板的权重和参数是使用训练样本共同学习的。他们使用的初始模板集是手工制作的模板或使用 "提示挖掘 "方法获得的模板。
- ** Hard-Soft Prompt Hybrid**这些方法不使用纯粹的可学习提词模板,而是在硬提词模板中插入一些可微调的嵌入物。Liu等人(2021b)提出了 “P-tuning”,即通过在嵌入输入中插入可训练的变量来学习连续的提示语。为了说明提示标记之间的互动,他们将提示嵌入表示为BiLSTM的输出(Graves等人,2013)。P-tuning还引入了在模板中使用与任务相关的锚定标记(如关系提取中的 “资本”),以进一步改善。这些锚定标记在训练中不被调整。Han等人(2021年)提出了用规则进行提示性调整(PTR),它使用手工制作的子模板,用逻辑规则组成一个完整的模板。为了提高所形成的模板的表示能力,他们还插入了几个虚拟标记,这些虚拟标记的嵌入可以与使用训练样本的预训练LMs参数一起进行调整。PTR中的模板标记同时包含实际标记和虚拟标记。实验结果证明了这种提示设计方法在关系分类任务中的有效性。
answer engineering
Discrete Answer Search
与人工创建的提示语一样,人工创建的答案有可能是让LM达到理想预测性能的次优答案。正因为如此,有一些关于自动答案搜索的工作,尽管比搜索理想提示的工作要少。这些工作在离散的答案空间(本节)和连续的答案空间(下文)都有。
- Answer Paraphrasing
这些方法从初始答案空间Z′开始,然后使用意译来扩展这个答案空间,以扩大其覆盖范围。给出一对答案和输出⟨z′,y⟩,我们定义一个函数,生成一个同义转换的答案集para(z′)。然后,最终输出的概率被定义为这个解析集中所有答案的边际概率P(y|x)=z∈para(z′)P(z|x)。这种解析可以用任何方法进行,但Jiang等人(2020b)特别使用了回译的方法,首先翻译成另一种语言,然后再回译,以生成多个解析的答案列表。 - Prune-then-Search
在这些方法中,首先生成一个由几个可信答案组成的初始修剪过的答案空间Z′,然后一个算法在这个修剪过的空间上进一步搜索,选择最终的答案集。请注意,在下面介绍的一些论文中,他们定义了一个从标签y到单一答案标记z的函数(“good” -> “++”),这通常被称为verbalizer。在搜索步骤中,他们通过最大化标签在训练数据上的可能性,反复计算一个词作为标签y的代表性答案z的适合性。Shin等人(2020)使用[Z]标记的上下文表示作为输入,学习一个逻辑分类器。在搜索步骤中,他们使用第一步中学习的逻辑分类器,选择取得最高概率分数的前k个标记。这些被选中的标记将构成答案。Gao等人(2021)首先根据训练样本确定的[Z]位置上的生成概率,选择前k个词汇,构建一个修剪后的搜索空间Z′。然后,根据训练样本上的零点准确性,只选择Z′内的一个词组,进一步修剪搜索空间。(2)在搜索步骤中,他们用训练数据对固定模板的LM和每个答案映射进行微调,并根据开发集上的准确度选择最佳标签词作为答案。 - Label Decomposition 在进行关系提取时,Chen等人(2021b)自动将每个关系标签分解为其组成词,并将它们作为答案。例如,对于关系per:city of death,分解后的标签词将是{person, city, death}。答案span的概率将被计算为每个标记的概率之和。
Continuous Answer Search
很少有工作探索可以通过梯度下降进行优化的软答案标记的可能性。为每个类标签分配了一个虚拟标记,并通过训练优化了每个标记的嵌入。他们不使用由LM学习的嵌入,而是为每个标签从头学习一个嵌入。
Multi-Prompt Learning
到目前为止,我们讨论的提示工程方法主要集中在为一个输入构建一个单一的提示。然而,大量的研究表明,使用多个提示可以进一步提高提示方法的功效,我们将这些方法称为多提示学习方法。在实践中,有几种方法可以将单提示学习扩展到使用多提示,这些方法的动机各不相同。

Prompt Ensembling
-
概率求平均
在使用多个提示时,结合预测的最直观方法是取不同提示的概率的平均值。首先通过选择在训练集上达到最高准确度的K个提示来过滤他们的提示,然后使用从前K个提示中得到的平均对数概率来计算执行事实探测任务时在[Z]位置出现单个标记的概率。 -
加权平均数
每个提示都与一个权重相关。权重通常是根据prompt性能预先指定的,或者使用训练集进行优化。例如,通过最大化训练数据中目标输出的概率来学习每个prompt的权重。也有使用相同的方法,只是每个提示的权重与软提示参数一起被优化。此外,还有做法通过引入了一个与数据相关的加权策略,在对不同的prompt进行加权时,也会考虑输入出现在该提示中的概率。也有将每个提示的权重与训练前训练集上的准确性成正比。 -
Majority voting
对于分类任务,多数投票也可以用来结合不同提示的结果。 -
知识蒸馏
深度学习模型的集合通常可以提高性能,这种优越的性能可以通过知识提炼提炼成一个单一的模型。为了融入这个想法,为每个手动创建的模板-答案对训练一个单独的模型,并使用它们的集合来注释一个未标记的数据集。然后,最终的模型被训练为从注释的数据集中提炼出知识。 -
文本生成任务的联合prompt方法
关于生成任务(即答案是一串token而不是单一token的任务)的提示语合集的工作相对较少。在这种情况下进行合集的简单方法是使用标准方法,根据答案序列中下一个词的合集概率
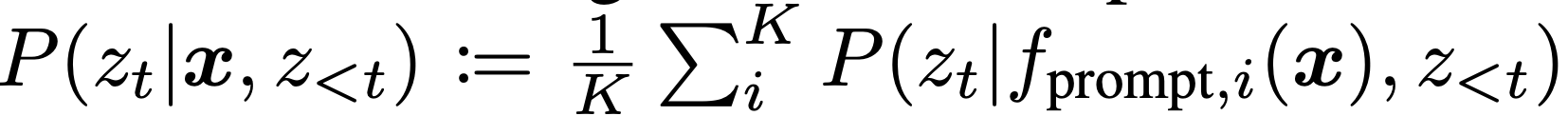
生成输出。相比之下,Schick和Schu ̈̈(2020)为每个提示fprompt,i(x)训练了一个单独的模型,因此将这些微调的LMs一一存储在内存中是不可行的。相反,他们首先使用每个模型解码,然后通过在所有模型中平均其生成概率来为每一代人评分。
提示增强
提示增强,提供了一些额外的回答提示,可以用来示范LM应该如何提供输入x的实际提示的答案。例如,而不是仅仅提供 "中国的首都是[Z]"的提示,可以在提示前加上一些例子,如 “英国的首都是伦敦。日本的首都是东京。中国的首都是[Z]”。另一个执行两个数字相加的例子可以在图4-(b)中找到。这些很少的演示利用了强势语言模型学习重复模式的能力。
虽然提示增强的想法很简单,但有几个方面使其具有挑战性。(1) 样本选择:如何选择最有效的例子?(2)样本排序。如何将选择的例子与提示进行排序。















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









