







看了几个讲这些的博客&视频,自己也有一些小小的技巧,总结一下啦~
一、理解论文代码
对深度学习中50+个经典网络架构代码做了逐行注释(公式/文字/示意图):https://github.com/labmlai/annotated_deep_learning_paper_implementations
对应的可视化网站:https://nn.labml.ai/
1. pycharm调试
在所在行左侧点击即可设置断点(运行至断点前一行暂停)。
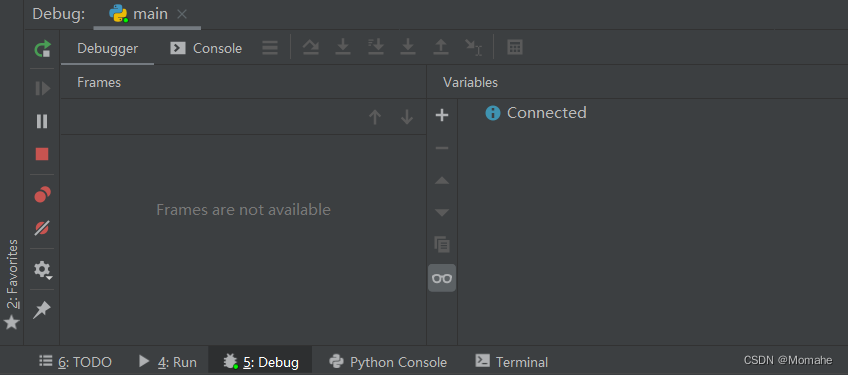
上面一行依次为:
- Step Over(F8):运行完断点所在行(运行接下来的每一步代码)
- Step Into(F7):不管当前调用的函数是在当前脚本中定义,还是在其他包或脚本import进来的,都跳转进该函数。
- Step Into My Code(Alt+Shift+F7):如果要进入的函数是在当前脚本内定义的,那么跳到定义的函数位置;如果不是在当前脚本上定义的(是从其他包或脚本import进来的),那么就不会跳入该函数。
- Step Out(Shift+F8):从内部函数一层一层往外跳
- Run to Cursor(Alt+F9):运行至光标定位的位置。
- Evaluate窗口:最后这个最有用!可以直接搜索当前的变量,查看其具体情况!
下面一行依次为:
- TODO:可以看到整个项目中,带 todo 的注释(用于记一些备忘)
- Python Console:相当于 jupyter/ipython(用于测试)
- Terminal:相当于 anaconda,可用于安装第三方模块(不行则重设镜像,切换到 command prompt)
左侧一列依次为:
2. pycharm阅读
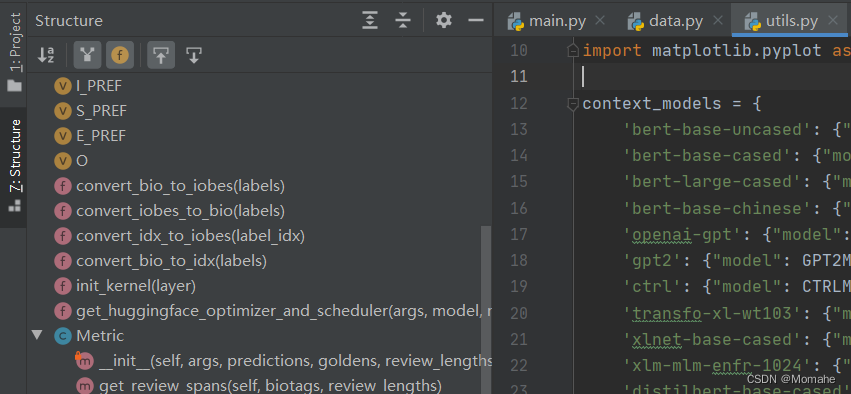
点击左边的Structure按钮,可以查看当前脚本的代码结构(当前脚本文件中有多少个全局变量、函数、类以及类中有多少个成员变量和成员函数等):
黄色v表示全局变量;粉色f表示普通函数;左上角带红色小三角的粉色f表示内嵌函数;
蓝色c表示类,类中粉色m表示成员函数,黄色f表示成员变量。
点击可以跳转到对应的代码。
二、知识总结
1. 目录问题
'./'表示运行程序脚本所在目录下;
'…/‘表示运行程序脚本所在目录的上一目录下。
这就意味着相对路径的正确与否取决于你运行程序的’main function’在哪里,而并不取决于你写的’./'命令位于哪个文件。
相对路径的相对,指的是相对于’python.exe main.py’的’main.py’的路径,与’main.py’调用的哪个文件无关。
2. 参数设置
epoch:将所有训练样本训练1次为1个epoch
batch_size:每个batch中训练样本的数量(由于训练样本过多,无法一次性送入计算,需将其分成多个batch , 逐一送入计算训练)
iteration:完成一次epoch需要的batch个数(即 iterations = batch numbers = 样本总数 / batch_size)
3. 评价指标
| 预测正确(T)错误(F) | 预测为正(P) | 预测为负(F) |
|---|---|---|
| 正样本 | TP | FN |
| 负样本 | FP | TN |
Precision = TP/(TP+FP):反映了预测为正的样本中,真正的正样本所占比例;
Recall = TP/(TP+FN) :查全率,反映了真正的正样本中,被正确预测为正的样本所占的比例;
Accuracy = (TP+TN)/(TP+FP+TN+FN) :反映了总样本数中,预测正确的样本所占的比例;
F1-score = 2Recall×Precision/(Recall+Precision):反映了precision和recall的调和平均评估。
Precision高,Recall低:负样本大概率能被正确预测,但是一部分正样本也被预测成了负样本
—> 预测为正的大概率为真正的正样本
—> 侧重看被预测为负的正样本有什么特点,为什么会被预测成负
Recall高,Precision低:正样本大概率能被正确预测,但是一部分负样本也被预测成了正样本
—> 预测为负的大概率为真正的负样本
—> 侧重看被预测为正的负样本有什么特点,为什么会被预测成正
两者都低:可能是训练集和测试集的label弄反了
两者都高:完美!
三、查找论文
查找某领域较具权威的文章:https://ai-paper-collector.vercel.app/
查找某特定文章:https://dblp.uni-trier.de/
总结下NLP领域常见的期刊:
一类:ACL ICML NEURIPS ICLR
二类:NAACL EMNLP
三类:EACL AAAI IJCAI COLING CONLL
其他:AACL IJCAI SIGIR IJCNLP NLPCC CCL CCMT
四、查找论文代码
如果这论文很老,论文里的算法在该领域有举足轻重的地位,那么网上很可能有工具包。例如机器学习方向中,经典的聚类、分类算法。MATLAB,python等常用语言都有丰富的工具包可供使用,一般有名的算法都会包括在其中。
如果论文非常新,或者论文中的算法在该领域并没有多大的影响,且论文中没有附加代码链接,可尝试以下方法(成功概率降序):
-
使用谷歌或必应搜索该论文的名称 \ 第一作者的姓名+homepage,找到该作者的个人学术主页,在他的主页上看看他是否公开了论文的代码。
-
搜索该论文中算法的名字+code或者是某种语言,如python等,有的科研人员读完这篇论文,会写代码并公布出来。
-
邮件联系第一作者。一些很忙的大牛可能扫一眼就不再过问,但一些博士生还是乐于分享代码的,这样自己的文章也更容易被同行引用。
-
查看该论文被哪些论文引用了,引用者有时需要将自己的算法与引用的算法作比较,所以他们有可能这个算法的代码。
有几个查找代码的网站推荐(附链接和简介):
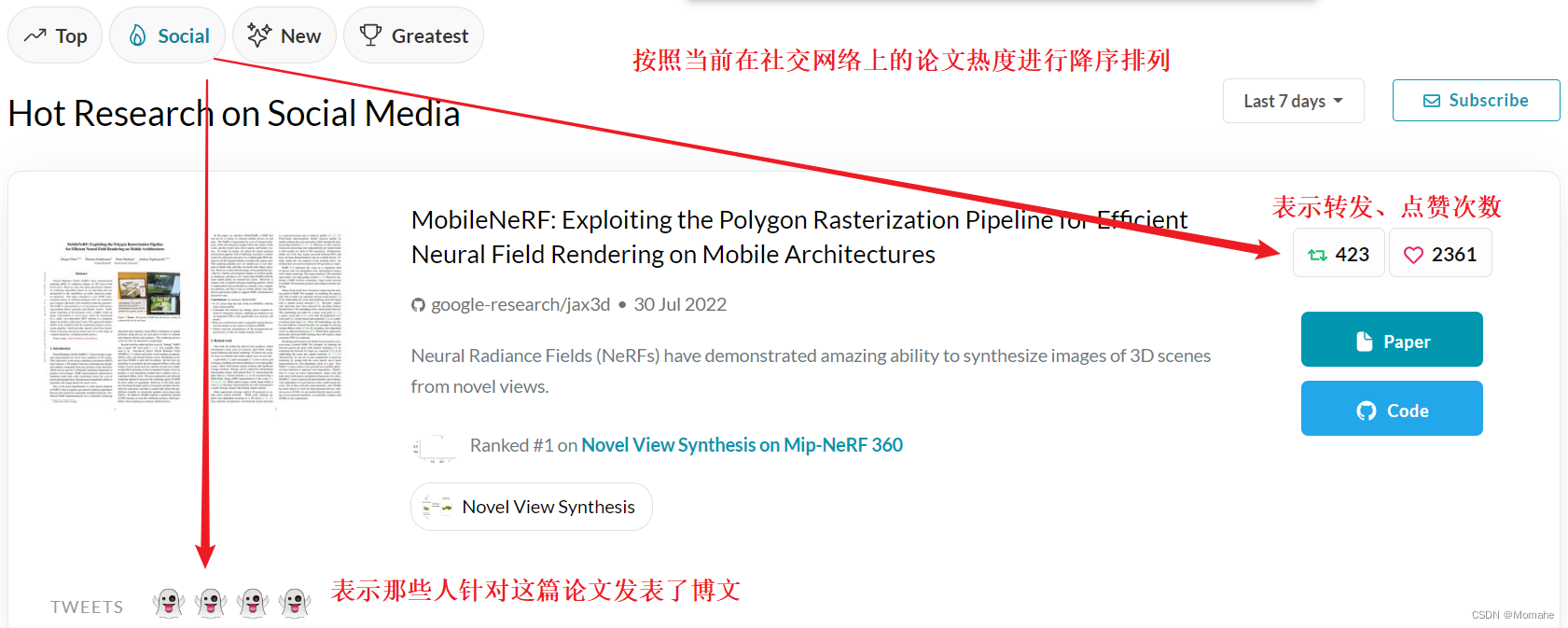
- Papers with Code:https://paperswithcode.com/
网站将ArXiv上的最新机器学习论文与GitHub上的代码相对应,可以按标题关键词查询,也可以按流行程度、GitHub星星数排序。



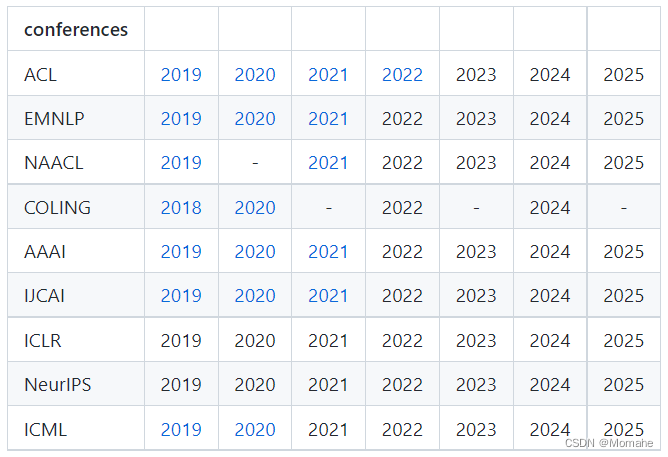
- https://github.com/MLNLP-World/Top-AI-Conferences-Paper-with-Code
按照顶会及其年份进行的分类整理。
五、其他
伯乐 RecBole(推荐系统框架):https://recbole.io/















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









