







模型评估是模型落地非常重要的环节,评估指标的好坏反映出特征工程和模型选型的正确与否,本文将简单归纳常见的模型评估指标,持续更新。
- 分类模型
- 混淆矩阵
分类模型的关键是将正负样本分开,评估分类的性能涉及到真实的正负样本和预测的正负样本,两两组合有四种可能性,由此引入混淆矩阵的概念,一个2*2的矩阵,Y-real表示真实的标签,Y-predict表示预测的标签,如下图:
| y | Y-real=0 | Y-real=1 |
|---|---|---|
| Y-predict=0 | ||
| Y-predict=1 |
坐标(0,0)的格子需要填充的数值是预测label为0且真实label为0的样本数量,由此类推其他格子需要填充的值,那格子里的每一个值需要有一个变量名,比如坐标为(0,0)的格子可以用Y-real_Y-predict命名,但是这样太随意又太长了,不够优雅。所以有“先人”对每个格子来了个统一的命名,每个格子变量名由两个字母表示,往往大家都记不住这里面每个格子的变量名,因为是真tm容易“混淆”啊,所以我总结了一套自己记忆的方法,两个关键点:
1)P/N表示预测label,Positive=预测的正样本,Negative=预测的负样本
2)T/F表示预测label是否与真实label一致,True=一致,False=不一致
根据关键点1)绘制混淆矩阵的变量
| Y-real=0 | Y-real=1 | |
|---|---|---|
| Y-predict=0 | N | N |
| Y-predict=1 | P | P |
根据关键点2)绘制混淆矩阵的变量名
| Y-real=0 | Y-real=1 | |
|---|---|---|
| Y-predict=0 | TN | FN |
| Y-predict=1 | FP | TP |
有了混淆矩阵以后,“先人们”就各种组合混淆矩阵,来衡量分类模型的效果。
- 常见评估指标
| 指标名称 | 计算 | 含义 | 描述 |
|---|---|---|---|
| Precision | TP / (TP+FP) | 精确率,分母是全量预测正样本,分子是其中真实正样本的个数 | 描述模型预测出来的正样本的精确程度 |
| Recall | TP / (TP+FN) | 召回率,分母是全量真实正样本,分子是其中预测正样本的个数 | 描述模型从真实正样本中识别出来正样本的能力 |
| F1-score | 2*P*R / (P+R) | Precision和Recall的调和平均 | - |
| Sensitivity(Recall) | TP / (TP+FN) | 敏感性 | 描述模型从真实正样本中识别出来正样本的能力 |
| Specificity(1 - FPR) | TN / (FP+TN) | 特定性 | 描述模型从真实负样本中识别出来负样本的能力 |
| FPR | FP / (FP+TN) | 假阳率,分母是全量真实负样本,分子是对负样本预测错的数量 | 描述模型从真实负样本中没识别出来负样本的程度,越小越好 |
| TPR(Recall/Sensitivity) | TP / (TP+FN) | 真阳率,分子是全量真实正样本,分子是对正样本预测对的数量 | 描述模型从真实正样中识别出来正样本的程度,越大越好 |
| Accuracy | (TP+TN) / (TP+TN+FP+FN) | 准确率 | 描述模型分类正确的占比 |
| AUC | Area Under (ROC) Curve | ROC曲线的面积 | 描述模型的分类能力 |
总结:
1)Recall / Sensitivity / TPR 是一个东西,不同的名字是因为对比角度不同,召回对应精确,敏感性对应特定性,真阳率对假阳率。
2)主要记住核心是Recall,由此衍生出来对应的Precision / Specificity / FPR,其中还有FPR=1-Specificity这样的关系。
3)从条件概率的角度理解Recall和Precision:
Recall = P(Y-predict=1 | Y-real=1)
Precision = P(Y-real=1 | Y-predict=1)
Specificity = P(Y-predict=0 | Y-real=0)
- 各类曲线
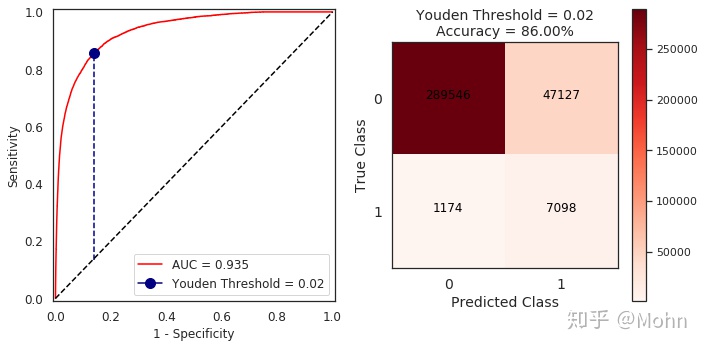
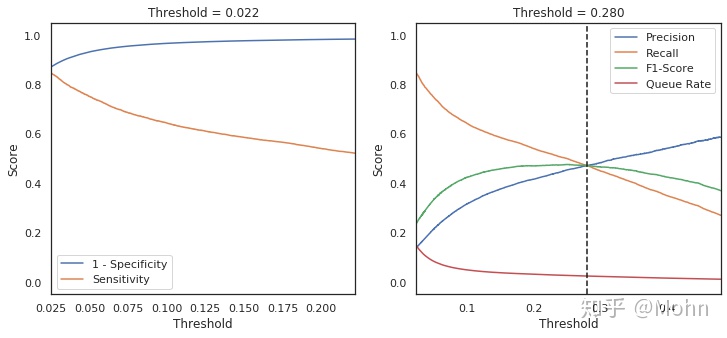
ROC绘制:ROC曲线的横轴是FPR,纵轴是TPR,横轴表示对真实负样本的识别能力,纵轴表示对真实正样本的识别能力,ROC的绘制是根据遍历所有的分类阈值分别计算FPR和TPR,从而绘制出来的连续的曲线。那么问题来了:
1)在同一条ROC曲线上,如何找到该ROC的最佳的分类阈值,使得FPR最小,TPR最大呢?
roc曲线上的每个点包含三个元素(threshold,FPR,TPR),“FPR最小,TPR最大”即找到使得np.abs(TPR-FPR)最大的threshold,
threshold_idx = np.argmax(np.abs(TPR-FPR))
best_threshold = thresholds[threshold_idx]2)那又如何在多个模型中通过绘制的ROC选择使得FPR最小,TPR最大的模型呢?
多个ROC曲线的情况下,可以通过计算AUC衡量分类的效果,AUC即ROC曲线下面积,面积越大,模型的分类效果越好。注意AUC是不受样本不平衡影响的,因为TPR和FPR分别是真实label为分母计算的条件概率,所以不会受影响。
3)如何计算AUC呢?
通常有三种方法,矩形面积近似法,曼-惠特尼法,在曼-惠特尼法上的排序,具体的计算是另一个话题了,这里暂时不展开讲。
推荐链接:
机器学习之类别不平衡问题 (2) -- ROC和PR曲线















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









