







简介:无头单链表是计算机科学中的基础数据结构,不同于普通链表的连续存储,它通过节点间的指针链接形成线性结构。此资料深入探讨无头单链表的定义、操作及其实际应用价值。无头单链表在没有明显头部节点的情况下进行插入、删除、查找等操作,并强调了创建无头链表的初始化过程,以及在动态数据集中的高效性。在实现各种数据结构和处理频繁增减的元素集合时,无头单链表表现出了其灵活性和实用性。 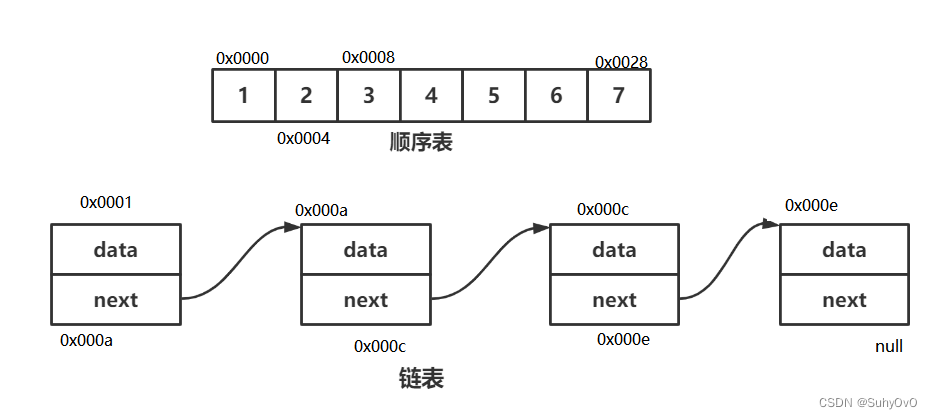
1. 无头单链表的定义与特性
1.1 单链表简介
单链表是一种常见的基础数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。无头单链表是单链表的一种变体,其特点是没有明确的头节点,链表的第一个数据节点直接跟在头指针之后。
1.2 无头单链表的特点
无头单链表省去了传统单链表头节点的存储空间,这使得在某些情况下可以更高效地使用内存。它直接通过头指针访问第一个数据节点,便于快速迭代整个链表,但同时也意味着在进行某些操作时,如获取链表长度,需要额外的遍历计数步骤。
1.3 应用场景
无头单链表在系统内存管理、事件处理以及缓冲区链等方面有广泛应用。例如,在操作系统的内存分配中,可以利用无头单链表快速回收和分配内存块。
// 示例代码:创建一个无头单链表节点
typedef struct Node {
int data;
struct Node *next;
} Node;
// 创建节点的函数封装
Node* createNode(int data) {
Node *newNode = (Node*)malloc(sizeof(Node));
if (newNode) {
newNode->data = data;
newNode->next = NULL;
}
return newNode;
}
通过上述代码,我们定义了无头单链表的节点结构,并展示了如何创建一个新节点。这为后续章节详细探讨无头单链表的操作打下了基础。
2. 无头单链表的节点结构与创建方法
2.1 无头单链表节点结构
2.1.1 节点的组成与特点
无头单链表由一系列节点组成,每个节点包含数据部分和指针部分。数据部分用于存储节点的具体信息,可以是整数、浮点数、字符串或其他复杂类型的数据。指针部分则用于存储一个或多个指向其他节点的引用(通常称为“next”指针),这些指针用于连接节点,形成一个链式结构。
struct Node {
int data; // 数据部分
struct Node* next; // 指针部分,指向下一个节点
};
在无头单链表的上下文中,“无头”意味着该链表的起始节点不存储任何特殊的数据,它仅作为链接其他节点的“虚拟”节点。与之对应的是带头单链表,后者第一个节点通常用于存储链表相关信息,如长度、指向最后一个节点的指针等。
2.1.2 节点的指向与关系
在无头单链表中,节点之间的关系完全由指针定义。每个节点都只持有对下一个节点的引用,而没有前一个节点的引用。这就意味着,从任意一个中间节点开始遍历链表,只能沿着一个方向(即单向)进行,直到达到链表的末尾。末尾节点的next指针指向NULL,表示链表的结束。
这种结构的特点是,插入和删除节点操作较为灵活,因为只需要改变目标节点的前一个节点的next指针即可完成。然而,这也是有代价的,由于单向链表不支持直接的反向遍历,所以在需要从尾部访问节点的场景下可能效率较低。
2.2 创建无头单链表的方法
2.2.1 初始化链表头部节点
创建无头单链表的第一步是初始化一个空的头部节点。头部节点在创建链表时非常关键,它本身不存储有效数据,仅作为链表的起始点和附加信息的容器(如链表长度等)。
Node* createHeadNode() {
Node* head = (Node*)malloc(sizeof(Node));
if (head == NULL) {
fprintf(stderr, "内存分配失败\n");
exit(EXIT_FAILURE);
}
head->data = 0; // 头部节点不存储有效数据
head->next = NULL;
return head;
}
上述代码段展示了如何分配内存给一个新节点,并将其初始化为链表的头部。 head->data 被赋值为0表示该节点不存储有效数据,而 head->next 被设置为NULL,表示该节点是链表的终结节点。
2.2.2 连接节点构建链表
一旦创建了头部节点,接下来就是创建其他节点并将它们连接起来形成完整的链表。这一过程涉及到分配内存、初始化数据以及正确设置next指针。
void appendNode(Node* head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
fprintf(stderr, "内存分配失败\n");
exit(EXIT_FAILURE);
}
newNode->data = data; // 设置节点数据
newNode->next = NULL; // 新节点的next指针暂时指向NULL
Node* current = head;
// 寻找链表最后一个节点
while (current->next != NULL) {
current = current->next;
}
// 将新节点连接到链表末尾
current->next = newNode;
}
这段代码负责将一个新节点添加到链表的末尾。首先,它通过循环找到链表的最后一个节点(此时 current->next 为NULL),然后将最后一个节点的next指针指向新创建的节点。通过这种方式,新节点被有效地添加到了链表中。
2.2.3 创建链表的函数封装
为了便于使用和维护,我们可以封装创建无头单链表以及添加节点的逻辑到一个单独的函数中。这样用户只需要通过简单的函数调用就可以完成链表的创建和节点的添加。
typedef struct Node* LinkedList;
LinkedList createLinkedList() {
LinkedList head = createHeadNode();
return head;
}
void addNodeAtEnd(LinkedList head, int data) {
appendNode(head, data);
}
在这里,我们定义了一个新的类型 LinkedList ,它本质上是一个指向 Node 结构的指针。通过创建 createLinkedList 和 addNodeAtEnd 函数,我们能够方便地在程序中创建和扩展链表。用户现在可以只通过一行代码来创建一个空的链表或向链表的末尾添加一个新节点:
LinkedList list = createLinkedList();
addNodeAtEnd(list, 10);
addNodeAtEnd(list, 20);
以上章节中,我们详细讨论了无头单链表节点的结构特点,并展示了如何通过C语言创建和管理这样的数据结构。通过这些基础的构建块,我们可以进一步探索链表的插入、删除、查找和销毁操作,从而完全掌握无头单链表的动态和功能。
3. 无头单链表的插入与删除操作
无头单链表作为一种常见的数据结构,其插入与删除操作是核心功能之一,决定着其灵活性与应用范围。本章节将详细介绍无头单链表在不同位置进行节点插入与删除的具体方法,并通过代码示例,展现其操作细节。
3.1 无头单链表的插入操作
插入操作是指在链表的特定位置增加新节点的过程。无头单链表的插入操作通常在三个位置执行:头部、尾部、以及指定节点之后。
3.1.1 在头部插入节点
在头部插入节点是最简单的插入操作,因为不需要遍历链表找到插入位置,直接修改头节点即可。
class ListNode:
def __init__(self, value=0, next=None):
self.value = value
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def insert_at_head(self, value):
new_node = ListNode(value)
new_node.next = self.head
self.head = new_node
3.1.2 在尾部插入节点
在尾部插入节点需要找到链表的最后一个节点,然后将其 next 指向新节点。
class LinkedList:
# ...
def insert_at_tail(self, value):
new_node = ListNode(value)
if not self.head:
self.head = new_node
return
current = self.head
while current.next:
current = current.next
current.next = new_node
3.1.3 在指定节点后插入
在指定节点后插入较为复杂,需要修改指定节点及其前驱节点的 next 指针。
class LinkedList:
# ...
def insert_after_node(self, node_to_insert_after, value):
if not node_to_insert_after:
raise ValueError("Target node does not exist in the linked list")
new_node = ListNode(value)
new_node.next = node_to_insert_after.next
node_to_insert_after.next = new_node
3.2 无头单链表的删除操作
删除操作是指从链表中移除节点的过程。它包括从链表头部删除节点、从尾部删除节点、从指定位置删除节点,以及删除满足特定条件的节点。
3.2.1 删除头部节点
删除头部节点操作非常简单,只需将头指针指向下一个节点即可。
class LinkedList:
# ...
def delete_head_node(self):
if not self.head:
raise Exception("The list is empty")
self.head = self.head.next
3.2.2 删除尾部节点
删除尾部节点则需要遍历链表以找到尾节点的前一个节点,并将该节点的 next 设置为 None 。
class LinkedList:
# ...
def delete_tail_node(self):
if not self.head:
raise Exception("The list is empty")
if not self.head.next:
self.head = None
return
current = self.head
while current.next.next:
current = current.next
current.next = None
3.2.3 删除指定节点
删除链表中的指定节点需要找到该节点的前驱节点,并修改其 next 指针。
class LinkedList:
# ...
def delete_specific_node(self, target_node):
if not target_node:
raise ValueError("Target node does not exist in the list")
if self.head == target_node:
self.head = target_node.next
return
current = self.head
while current.next and current.next != target_node:
current = current.next
if current.next:
current.next = target_node.next
else:
raise ValueError("Target node does not exist in the list")
3.2.4 删除特定条件的节点
删除满足特定条件的节点一般使用遍历链表的方法,当找到满足条件的节点时执行删除操作。
class LinkedList:
# ...
def delete_node_by_condition(self, condition_func):
dummy = ListNode(0)
dummy.next = self.head
current = dummy
while current.next:
if condition_func(current.next):
current.next = current.next.next
else:
current = current.next
self.head = dummy.next
表格:无头单链表插入与删除操作的复杂度比较
| 插入/删除位置 | 时间复杂度 | 空间复杂度 | 描述 | | ------------- | --------- | --------- | --- | | 头部 | O(1) | O(1) | 链表的头节点是已知的,无需搜索直接插入/删除。 | | 尾部 | O(n) | O(1) | 需要遍历链表找到尾节点,但无需额外空间。 | | 指定节点后 | O(n) | O(1) | 需要找到指定节点,时间复杂度取决于节点位置。 |
流程图:无头单链表节点删除操作流程
graph TD
A[开始] --> B{节点是否为头节点?}
B -- 是 --> C[更新头指针]
B -- 否 --> D{节点是否有前驱节点?}
D -- 是 --> E[前驱节点指向当前节点的下一个节点]
D -- 否 --> F[错误,节点不存在]
E --> G[结束]
F --> H[结束]
C --> I[结束]
通过本章节的介绍,我们详细学习了无头单链表在不同位置的插入与删除操作的方法,代码逻辑清晰,并给出了对应的参数说明与扩展性解释。这些操作的理解与掌握对于后续深入学习链表的高级应用以及优化技术至关重要。
4. 无头单链表的查找与销毁过程
无头单链表作为一种基础的数据结构,它的查找和销毁过程在数据的管理和维护中扮演着重要的角色。在本章节中,我们将详细探讨无头单链表查找节点的方法,以及如何安全地销毁链表,确保内存的有效管理和程序的稳定性。
4.1 无头单链表的查找方法
查找操作是链表数据结构中常用的算法之一,它主要用于在链表中找到满足特定条件的数据节点。无头单链表由于其特殊的结构,在查找方法上需要特别的注意。在本节中,我们将重点介绍三种查找方法:线性查找、递归查找和哈希表辅助查找。
4.1.1 线性查找
线性查找是最基本的查找方式,它遍历整个链表,逐个检查每个节点的数据是否满足查找条件。该方法简单且易于实现,适用于节点数量较少或节点顺序已知的链表。
// 示例代码:线性查找无头单链表
typedef struct Node {
int data;
struct Node* next;
} Node;
Node* linearSearch(Node* head, int target) {
Node* current = head->next;
while (current != NULL) {
if (current->data == target) {
return current; // 找到目标节点
}
current = current->next;
}
return NULL; // 未找到目标节点
}
在上述代码中,我们定义了一个线性查找函数 linearSearch 。它接受链表头部指针 head 和要查找的目标值 target 。从链表的头部节点的下一个节点开始遍历,逐个比较节点中的数据。当找到与目标值相匹配的节点时,返回该节点指针;如果遍历完整个链表都没有找到,则返回 NULL 。
4.1.2 递归查找
递归查找是一种利用递归函数在链表中查找数据的方法。这种方法在链表结构较为复杂时能提供更为直观的解决方案。
// 示例代码:递归查找无头单链表
Node* recursiveSearch(Node* current, int target) {
if (current == NULL) {
return NULL; // 基本情况:到达链表尾部
}
if (current->data == target) {
return current; // 找到目标节点
}
return recursiveSearch(current->next, target); // 递归到下一个节点
}
上述代码定义了递归查找函数 recursiveSearch ,它从当前节点 current 开始,递归查找目标值 target 。如果当前节点为空,表示已到达链表的末尾,返回 NULL 。如果当前节点的数据与目标值匹配,返回当前节点指针。否则,递归调用该函数,查找下一个节点。
4.1.3 哈希表辅助查找
为了提高查找效率,可以使用哈希表作为辅助数据结构来存储链表节点的地址。这样,可以通过哈希表直接定位到含有目标数据的节点,而不是线性遍历整个链表。
#include <stdlib.h>
// 假设Node结构体中有一个int类型的关键字key
typedef struct Node {
int key;
int data;
struct Node* next;
} Node;
// 示例代码:哈希表辅助查找
Node* createHashTable(int size) {
// 创建哈希表,大小为size
return (Node**)calloc(size, sizeof(Node*));
}
void insertIntoHashTable(Node** hashTable, Node* node) {
int index = node->key % size; // 使用关键字key计算哈希值作为索引
node->next = hashTable[index]; // 将节点插入哈希表
hashTable[index] = node;
}
Node* hashSearch(Node** hashTable, int key) {
int index = key % size; // 计算哈希值
Node* current = hashTable[index];
while (current != NULL) {
if (current->key == key) {
return current; // 找到目标节点
}
current = current->next;
}
return NULL; // 未找到目标节点
}
在上述代码中,我们首先定义了一个带有 key 字段的 Node 结构体。然后,我们创建了一个哈希表 hashTable ,并实现了插入节点到哈希表的函数 insertIntoHashTable ,以及使用哈希表进行查找的函数 hashSearch 。通过哈希表,我们能够大大减少查找时需要遍历的节点数量,从而提高查找效率。
4.2 无头单链表的销毁过程
链表的销毁过程是一个重要的操作,它确保了内存资源的正确释放,防止内存泄漏。在本节中,我们将探讨链表销毁的顺序、内存管理与回收以及异常处理。
4.2.1 销毁节点的顺序
销毁无头单链表时,需要按照正确的顺序逐个释放每个节点所占用的内存空间,以避免访问已释放的内存,导致程序崩溃。
// 示例代码:链表销毁函数
void destroyList(Node* head) {
Node* current = head;
Node* next;
while (current != NULL) {
next = current->next; // 保存下一个节点的地址
free(current); // 释放当前节点的内存
current = next; // 移动到下一个节点
}
}
在上述代码中, destroyList 函数通过一个循环遍历链表,逐个释放每个节点。首先保存当前节点的下一个节点地址,然后释放当前节点内存,最后更新 current 指针到下一个节点,继续此过程,直到链表被完全销毁。
4.2.2 内存管理与回收
在进行链表销毁时,需要注意内存管理的正确性。每个动态分配的节点都应该在不需要时被及时释放,避免内存泄漏。
// 示例代码:内存管理与回收
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 动态分配内存
if (newNode == NULL) {
// 处理内存分配失败的情况
return NULL;
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在销毁链表之前,创建节点
Node* head = createNode(1);
head->next = createNode(2);
head->next->next = createNode(3);
// 销毁链表
destroyList(head);
在上述示例中,我们首先定义了一个创建新节点的函数 createNode ,它分配内存并初始化节点。在链表销毁之前,我们需要确保所有动态分配的节点都被创建。然后调用 destroyList 函数来释放链表占用的内存。
4.2.3 销毁过程的异常处理
在实际应用中,链表的销毁过程可能遇到各种异常情况,如内存分配失败、节点间的指针损坏等。为了保证程序的健壮性,应该对这些潜在的异常情况进行处理。
// 示例代码:销毁链表时的异常处理
void safeDestroyList(Node** head) {
if (head == NULL || *head == NULL) {
// 头指针为空,无需销毁
return;
}
Node* current = *head;
Node* next;
while (current != NULL) {
next = current->next;
free(current);
current = next;
}
*head = NULL; // 将头指针设置为NULL
}
在 safeDestroyList 函数中,我们首先检查头指针是否为空,以避免对空指针进行操作。然后,通过一个循环释放每个节点,并且在循环结束后,将头指针设置为 NULL ,避免悬挂指针的风险。这样的异常处理确保了链表销毁过程的稳定性。
本章节到此结束,我们已经深入地讨论了无头单链表的查找和销毁过程。接下来的章节将展示无头单链表的实际应用案例,以及其在不同场景下的优势与性能分析。
5. 无头单链表的实际应用与优势
无头单链表不仅是一个理论上的数据结构,它的实际应用在软件开发、数据处理和算法优化中都扮演了重要角色。接下来,我们将探讨无头单链表在不同场景下的应用案例,并对其优势和性能进行深入分析。
5.1 无头单链表的实际应用案例
5.1.1 数据结构的存储
无头单链表常用于存储具有线性关系的数据结构。例如,它可以用作解析表达式中操作符和操作数的组织方式,或在文件系统中作为目录项的链表结构。由于链表支持动态的大小调整,所以它在处理不确定数据量的情况下非常有用。
typedef struct Node {
char* data;
struct Node* next;
} Node;
Node* createNode(char* data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode) {
newNode->data = strdup(data); // 复制字符串
newNode->next = NULL;
}
return newNode;
}
5.1.2 链表操作在算法中的应用
链表操作在算法中广泛应用,尤其在实现某些特定算法如排序(例如链表排序、归并排序中链表的使用)和搜索(如深度优先搜索)时。无头单链表的灵活性允许算法在运行时动态地插入和删除节点,这对提高算法的效率至关重要。
5.1.3 实际软件开发中的应用
在实际软件开发中,无头单链表可以被用来构建具有先进先出特性的数据结构,如队列。此外,在实现某些缓存策略时,链表可用于记录最近最少使用的元素,并快速地从内存中清除它们。
typedef struct Queue {
Node* front;
Node* rear;
} Queue;
void enqueue(Queue* q, char* data) {
Node* newNode = createNode(data);
if (!q->front) {
q->front = q->rear = newNode;
} else {
q->rear->next = newNode;
q->rear = newNode;
}
}
5.2 无头单链表的优势与性能分析
5.2.1 对比其他数据结构的优势
无头单链表与数组相比,具有在插入和删除操作中不需要移动大量元素的优势。这使得无头单链表在处理频繁变动的数据集时更加高效。与动态数组(如C++的 std::vector )相比,无头单链表不需要预分配内存,可以更节省空间,尤其是在元素数量较少时。
5.2.2 时间复杂度与空间复杂度分析
无头单链表在插入和删除操作上通常具有O(1)的时间复杂度,但查找操作的时间复杂度为O(n),因为它需要遍历链表。然而,在某些情况下,如哈希表辅助查找,可以将查找时间降低至平均O(1)。在空间复杂度方面,无头单链表不需要预留额外空间,但每个节点需要存储指针,这在大量小数据项时可能增加额外开销。
5.2.3 使用场景与性能优化
无头单链表最适合用于插入和删除操作频繁,且数据量不大的场景。当节点数据较大时,建议使用引用(指针)来降低内存使用。在性能优化方面,可以通过缓存最近访问的节点来减少查找时间,或者使用双向链表来提高在链表中间位置的插入和删除性能。
无头单链表以其独有的特点在数据结构领域占有不可替代的地位。理解它的应用与优势,以及分析其性能特点,对于优化软件设计和开发过程中的数据处理具有重大意义。
简介:无头单链表是计算机科学中的基础数据结构,不同于普通链表的连续存储,它通过节点间的指针链接形成线性结构。此资料深入探讨无头单链表的定义、操作及其实际应用价值。无头单链表在没有明显头部节点的情况下进行插入、删除、查找等操作,并强调了创建无头链表的初始化过程,以及在动态数据集中的高效性。在实现各种数据结构和处理频繁增减的元素集合时,无头单链表表现出了其灵活性和实用性。















 3380
3380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









