







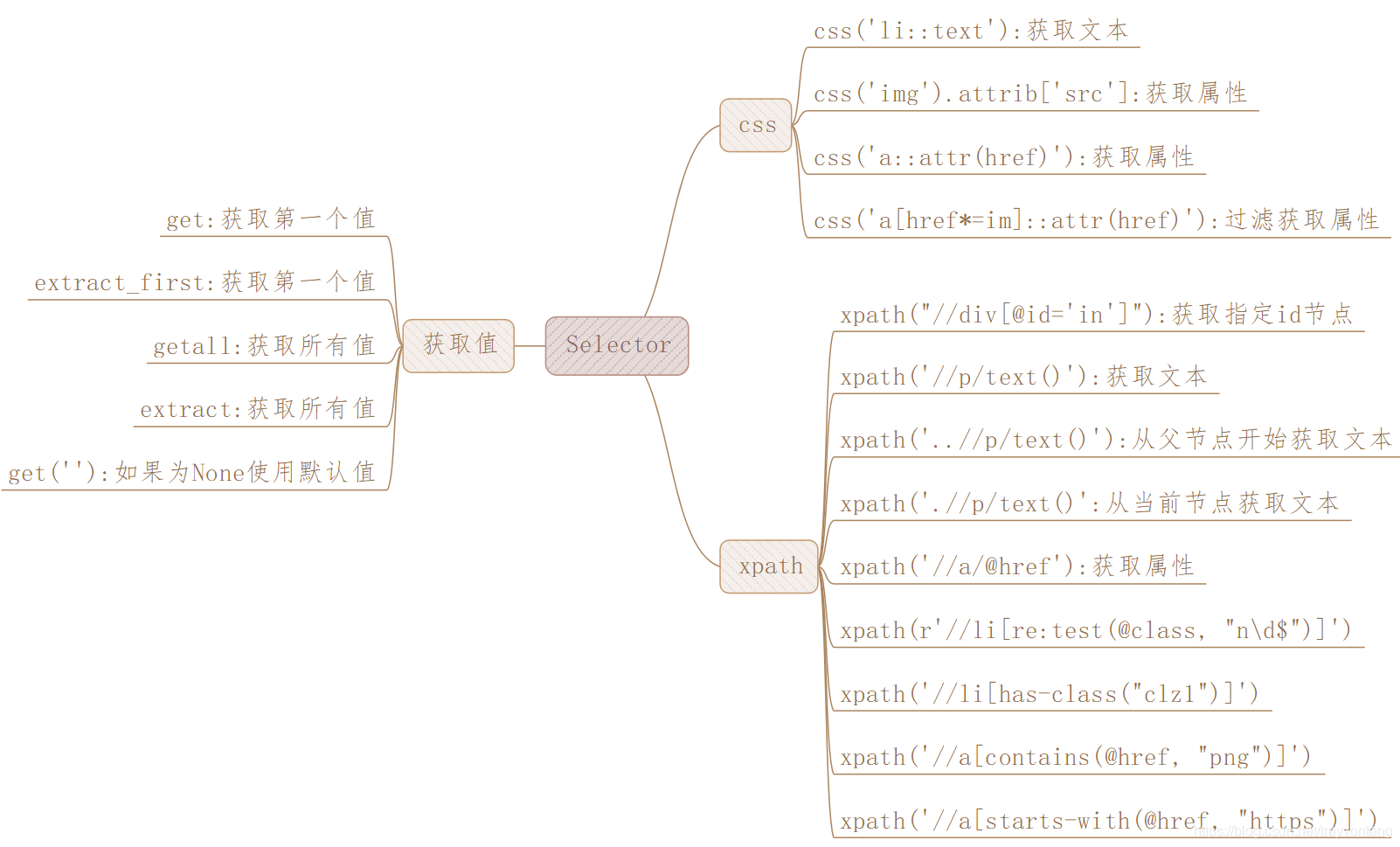
我们先上一波总结,当我们抓取网页的时候,我们最常的任务就是从HTML中将数据提取出来,那我们就不得不学习数据提取库了。
对于爬取信息的解析,我们之前已经介绍过了正则re、Xpath、BeautifulSoup和PyQuery。而Scrapy还给我们提供了自己的数据解析方法,即Selector(选择器)。
Selector选择器是基于lxml来构建的,支持Xpath、CSS选择器以及正则表达式。功能全面。解析的速度与准确率都是极高的。
Selector选择器是一个可以独立使用的模块。直接导入模块就可以实例化使用。我们使用Scrapy shell来模拟请求实现命令行交互模式。
具体的使用方式可以看下面的代码:
from scrapy import Selector
content = "<html><head><title>my html</title><body><h3>Hello World</h3></body></head></html>"
selector = Selector(text=content)
print(selector.xpath('/html/head/title/text()'))
# [<Selector xpath='/html/head/title/text()' data='my html'>]
print(selector.xpath('/html/head/title/text()').extract())
# ['my html']
print(selector.xpath('/html/head/title/text()').extract_first())
# my html
print(selector.css('h3::text').extract_first())
# Hello World
当然Selector也是支持css选择器的使用语法的,接下来,我将使用两种语法来获取同一个数据。
其中的HTML如下所示:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
该网页的链接如下:
https://docs.scrapy.org/en/latest/_static/selectors-sample1.html
因此,我打算在终端通过shell的方式,一种交互模式展现给大家。
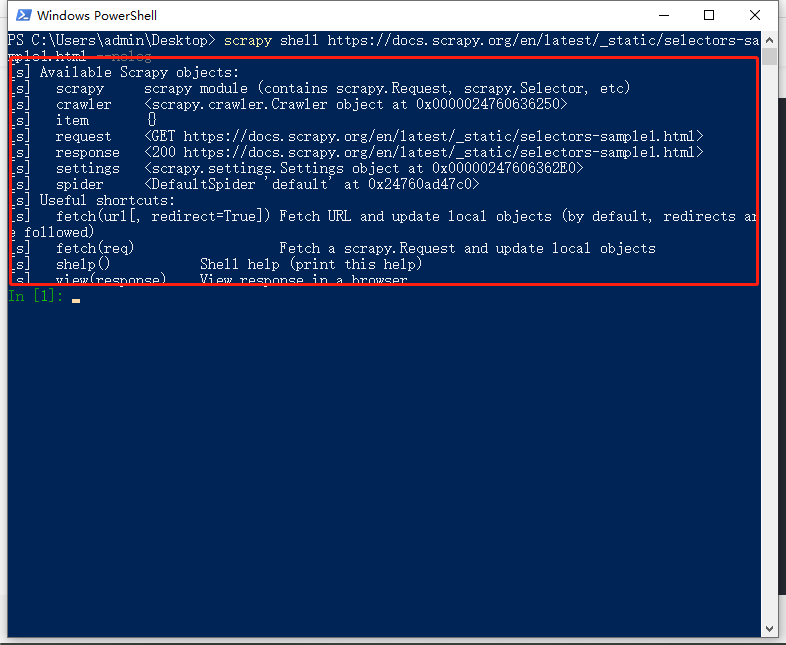
这部分内容就是scrapy向目标网站发起请求,返回的结果。
通过输入response.body,便可以查看到网页的源代码了。

接下来,我会使用两种数据提取的方式教大家把标题文本提取出来。

既可以通过xpath语法获取到数据,也可以通过css选择器获取到我们想要的数据,是不是觉得很爽!!
下面的内容我就不一一说明了,因为我之前也是有写过关于xpath和css的文章,如果看不懂,建议回看文章。
# 文本一
response.xpath('//title/text()').extract()
response.css('title::text').extract()
response.selector.xpath("//a/text()").extract()
# 文本 包括子节点
response.xpath("//a[1]//text()").extract()
# 文本 包括子节点
response.xpath("string(//a[1])").extract()
# 属性
response.xpath('//img/@src').extract()
response.css('img::attr(src)').extract()
# 混合
response.css('img').xpath('@src').extract()
response.xpath('//img').css('::attr(src)').extract()
本篇文章的内容有点少,主要目的就是带大家了解一下,scrapy中的Selector的使用方法,其实只要前面的基础打得牢固的话,对于本篇内容相信你不到5分钟就可以掌握了。
最后我还是不得不说.......
最后
没有什么事情是可以一蹴而就的,生活如此,学习亦是如此!
因此,哪里会有什么三天速成,七天速成的说法呢?
唯有坚持,方能成功!
啃书君说:
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。在文章末尾点【赞】,让我知道,你们也在为自己的学习拼搏和努力。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









