







可控语音合成的分层生成建模
本文提出了一种神经端到端文本到语音(TTS)模型,该模型可以控制生成的语音中潜在的属性,这些属性很少在训练数据中注释,例如说话风格,重音,背景噪声和记录条件。该模型被公式化为具有两级分层潜变量的条件生成模型。**第一级是分类变量,它表示属性组(例如干净/嘈杂)并提供可解释性。以第一级为条件的第二级是多变量高斯变量,其表征特定属性配置(例如,噪声水平,说话速率)并且能够对这些属性进行解缠结的细粒度控制。**这相当于使用高斯混合模型(GMM)进行潜在分布。广泛的评估证明了其控制上述属性的能力。特别是,无论目标说话者的训练数据的质量如何,它都能够始终如一地合成高质量的清洁语音。
一、简介
我们扩展了Tacotron2以建模两个单独的潜在空间:一个用于标记(即与说话者身份有关),另一个用于未标记的属性。使用高斯混合先验,在可变自动编码框架中对每个隐式变量进行建模。产生的潜在空间(1)学习解缠结的属性表示,其中每个维度控制不同的生成因子;(2)发现一组可解释的聚类,每个可聚类对应于训练数据中的代表性模式(例如,一个聚类用于清洁语音和另一个嘈杂的语音);(3)根据先验知识提供系统的抽样机制。
主要贡献为:
- 提出了一种有原则的概率分层生成模型, 改进了采样稳定性和解缠结的属性控制, 以及可解释性和合成语音质量;
- 模型通过使用两个混合分布以无纠缠的方式分别对监督的说话者属性和潜在属性进行建模,从而显式地考虑了潜在编码。这使得直接根据从不同参考话语推断出的说话人和潜在编码来调节模型输出变得容易。
- 本文是第一个在真实发现的数据上训练高质量可控文本转语音系统的系统,该数据包含录音条件,说话者身份以及韵律和风格的显着变化。利用解缠结的说话人和潜在属性编码,所提出的模型能够从以前未知的说话人说出的嘈杂语音中推断出说话人属性表示,并使用它来合成接近该说话人声音的高质量清晰语音。
二、模型
类似Tacotron的TTS系统采用文本序列 Y t Y_t Yt和可选的观察类别标签(例如发言者身份) y 0 y_0 y0作为输入,并使用自回归解码器预测的序列声学特征 X X X帧接一帧。训练这样的系统以最小化均方误差重建损失可以看作是拟合概率模型 p ( X ∣ Y t , y o ) = ∏ n p ( x n ∣ x 1 , x 2 , . . . , x n − 1 , Y t , y o ) p(X | Y t,y o)= ∏_n p(x_n |x_1,x_2,...,x{_n-1},Y_t,y_o) p(X∣Yt,yo)=∏np(xn∣x1,x2,...,xn−1,Yt,yo)使生成训练数据的可能性最大化,其中每个帧 x n x_n xn的条件分布建模为固定方差各向同性高斯模型,其由解码器在步骤n预测平均值。这样的模型有效地整合了其他未标记的潜在属性(如韵律),并产生具有较高方差的条件分布。结果是,该模型将不透明地产生具有不可预测的潜在属性的语音。启用控制在这些属性中,我们采用带有分层潜变量的图形模型,该模型可以捕获这样的属性。下面我们将解释该表述如何导致可解释性和解缠结,支持采样,并提出有效的推理和训练方法。
2.1 具有分层隐式变量的可控生成模型
| 符号表 |
|---|
| Y t Y_t Yt : 输入文本序列 |
| y 0 y_0 y0 : 分类标签,例如说话人ID |
| X : 预测的声学特征序列 |
| y l y_l yl: 隐式变量,K向分类离散变量 |
| z l z_l zl : 隐式变量,D维连续变量 |
| y ∗ y_* y∗ : 离散变量 |
| z ∗ z_* z∗ : 连续变量 |

为了生成以文本
Y
t
Y t
Yt和观察到的属性
y
0
y_0
y0为条件的语音
X
X
X,首先从其先验
p
(
y
l
)
p(y_l)
p(yl)采样得到
y
l
y_l
yl,然后从条件分布
p
(
z
l
∣
y
l
)
p(z_l | y_l)
p(zl∣yl)中采样得到隐式属性表示$z_l
。
最
后
,
从
。最后,从
。最后,从p(X | Y_t,y_o,z_l)$得出一系列语音帧,由合成器神经网络参数化。联合概率可以写成:
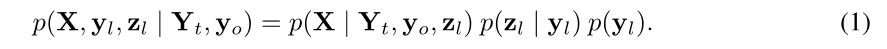
其中,假设 p ( y l ) = K − 1 p(y_l) = K^{-1} p(yl)=K−1为非信息性的先验, p ( z l ∣ y l ) = N ( μ y l , diag ( σ Y l ) ) p\left(\mathbf{z}_{l} | \mathbf{y}_{l}\right)=\mathcal{N}\left(\boldsymbol{\mu}_{\mathbf{y}_{l}}, \operatorname{diag}\left(\boldsymbol{\sigma}_{\mathbf{Y}_{l}}\right)\right) p(zl∣yl)=N(μyl,diag(σYl))为对角协方差高斯,,具有可学习的均值和方差。因此, z l z_l zl的边缘先验变为具有对角线的协方差和相等的混合权重GMM。我们希望这个GMM潜在模型可以更好地捕获位置属性的复杂性。此外,在存在未知属性的集群的情况下,所提出的模型可以通过学习将不同集群的实例分配到混合不同的成分来实现可解释性。每个混合成分的协方差矩阵被约束为对角线以鼓励每个维度捕获统计上不相关的因素。
2.2 变分推论和训练
条件输出分布 p ( X ∣ Y t , y o , z l ) p\left(\mathbf{X} | \mathbf{Y}_{t}, \mathbf{y}_{o}, \mathbf{z}_{l}\right) p(X∣Yt,yo,zl)由一个神经网络参数化。在VAE框架中,变分分布 q ( y l ∣ X ) q ( z l ∣ X ) q(y_l | X)q(z_l | X) q(yl∣X)q(zl∣X)用于得到近似后验 p ( y l , z l , ∣ X , Y t , y 0 ) p(y_l, z_l, | X, Y_t, y_0) p(yl,zl,∣X,Yt,y0),这里假设后验未知属性独立于文本和观察到的属性。 z l z_l zl, q ( z l ∣ X ) q(z_l | X) q(zl∣X)的近似后验建模为对角线协方差矩阵的高斯分布,均值和方差由神经网络学习到。 p ( y l ∣ X ) p(y_l | X) p(yl∣X)近似值由 q ( z l ∣ X ) q(z_l |X) q(zl∣X)得到:
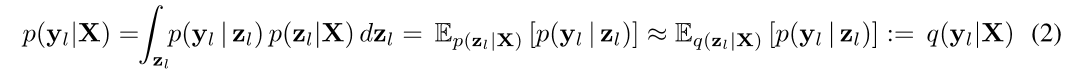
其中,它使用了高斯混合后验的闭式解
p
(
y
l
∣
z
l
)
p(y_l | z_l)
p(yl∣zl)。与VAE类似,通过最大化其证据下界(ELBO)对模型进行训练,如下所示:
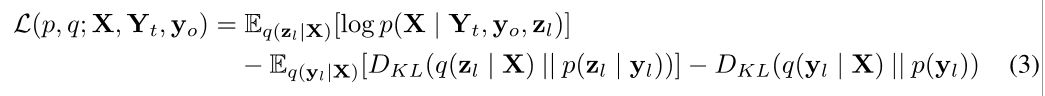
其中,
q
(
z
l
∣
X
)
q(z_l | X)
q(zl∣X)经由蒙特卡罗抽样估计,由于重新参数化, 所有组件是可微的。详见附录A。
2.3 显示分类标签的连续属性空间
分类观察到的标签(例如说话者身份)通常可以看作是来自连续属性空间,例如可以建模说话者的特征F 0范围和声道形状。给定观察到的标签,这些属性可能仍然会有一些变化。我们有兴趣学习这种连续的属性空间,以建模类内变异和从一个看不见的类的实例中推断出表示以进行单次学习。
为此,在到观察到的分类标签$y_0 和 语 音 和语音 和语音X 之 间 , 引 入 一 个 连 续 的 潜 在 变 量 之间,引入一个连续的潜在变量 之间,引入一个连续的潜在变量z_0 , 命 名 为 观 察 到 的 属 性 表 示 形 式 , 如 图 1 的 右 侧 所 示 。 每 个 观 察 到 的 类 别 ( 例 如 每 个 说 话 者 ) 在 这 个 连 续 空 间 中 形 成 一 个 混 合 成 分 , 条 件 分 布 是 对 角 协 方 差 高 斯 ,命名为观察到的属性表示形式,如图1的右侧所示。每个观察到的类别(例如每个说话者)在这个连续空间中形成一个混合成分,条件分布是对角协方差高斯 ,命名为观察到的属性表示形式,如图1的右侧所示。每个观察到的类别(例如每个说话者)在这个连续空间中形成一个混合成分,条件分布是对角协方差高斯p\left(\mathbf{z}{0} | \mathbf{y}{0}\right)=\mathcal{N}\left(\boldsymbol{\mu}{\mathbf{y}{0}}, \operatorname{diag}\left(\boldsymbol{\sigma}{\mathbf{Y}{0}}\right)\right) 。 在 条 件 。在条件 。在条件Y_t , , ,z_l 和 和 和p(Z_0 | y_0) 得 到 的 采 样 得到的采样 得到的采样z_0 下 生 成 可 观 测 类 别 下生成可观测类别 下生成可观测类别y_0 的 语 音 。 如 前 所 述 , 由 神 经 网 络 得 到 的 变 分 分 布 的语音。如前所述,由神经网络得到的变分分布 的语音。如前所述,由神经网络得到的变分分布q(z_0 | X)$,用于近似真实后验,其中ELBO变为:
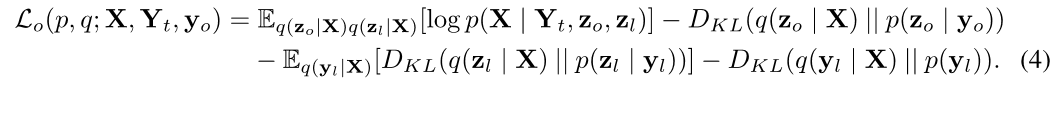
为了鼓励$z_0
使
潜
在
属
性
与
观
测
属
性
分
离
,
使潜在属性与观测属性分离,
使潜在属性与观测属性分离,p(Z_0 | y_0)
的
方
差
初
始
化
为
小
于
的方差初始化为小于
的方差初始化为小于p(Z_l | y_l)$的值。目的是使这个空间应该捕捉与观察到的标签高度相关的属性的变化,因此对于每个混合成分,所有维度的条件分布变化应相对较小。实验性结果证明了有效性。在极端情况下在方差固定且接近零的情况下,此公式收敛到使用查找表。
2.4 神经网络结构

我们使用神经网络(在图2中称为合成器,观察到的编码器和潜在编码器)将三个分布参数化: p ( X ∣ Y t , z o , z l ) ( or p ( X ∣ Y t , z o , z l ) ) , q ( z o ∣ X ) , and q ( z l ∣ X ) p\left(\mathbf{X} | \mathbf{Y}_{t}, \mathbf{z}_{o}, \mathbf{z}_{l}\right)\left(\text { or } p\left(\mathbf{X} | \mathbf{Y}_{t}, \mathbf{z}_{o}, \mathbf{z}_{l}\right)\right), q\left(\mathbf{z}_{o} | \mathbf{X}\right), \text { and } q\left(\mathbf{z}_{l} | \mathbf{X}\right) p(X∣Yt,zo,zl)( or p(X∣Yt,zo,zl)),q(zo∣X), and q(zl∣X)。该合成器基于Tacotron2架构,由文本编码器和自回归语音解码器组成。前者将$Y_t 映 射 到 文 本 编 码 映射到文本编码 映射到文本编码Z_t , 后 者 在 每 个 步 骤 n 预 测 ,后者在每个步骤n 预测 ,后者在每个步骤n预测p\left(\mathbf{x}{n} | \mathbf{x}{1}, \ldots, \mathbf{x}{n-1}, \mathbf{Z}{t}, \mathbf{y}{o}, \mathbf{z}{l}\right) 的 平 均 值 。 通 过 将 潜 在 变 量 的平均值。通过将潜在变量 的平均值。通过将潜在变量z_l 和 和 和y_0 或 或 或z_0 连 接 到 解 码 器 , 将 它 们 注 入 解 码 器 在 每 个 步 骤 中 输 入 。 文 本 连接到解码器,将它们注入解码器在每个步骤中输入。文本 连接到解码器,将它们注入解码器在每个步骤中输入。文本Y_t 和 语 音 和语音 和语音X 表 示 为 音 素 序 列 和 序 列 梅 尔 级 滤 波 器 组 系 数 。 为 了 加 快 推 理 速 度 , 我 们 使 用 了 基 于 W a v e R N N 的 神 经 声 码 器 而 不 是 W a v e N e t 预 测 的 梅 尔 谱 图 到 时 域 波 形 。 两 个 后 验 表示为音素序列和序列梅尔级滤波器组系数。为了加快推理速度,我们使用了基于WaveRNN的神经声码器而不是WaveNet预测的梅尔谱图到时域波形。两个后验 表示为音素序列和序列梅尔级滤波器组系数。为了加快推理速度,我们使用了基于WaveRNN的神经声码器而不是WaveNet预测的梅尔谱图到时域波形。两个后验q(z_l|X) 和 和 和q(z_0|X)$均由映射的递归编码器映射一个可变长度的梅尔谱图到两个固定维矢量得到,对应于后验均值和对数方差。完整的体系结构详见附录B。
三、相关研究
(2018)GMVAE-Tacotron模型,引入了模型韵律或噪声的参考嵌入。第一次使用自动编码器从参考语音频谱图中提取韵律嵌入。第二个Global Style Token(GST)模型将参考嵌入约束为加权固定的一组学习向量的组合,而第三种进一步将权重限制为一键式,并基于传统的参数语音合成器(2009)。这些方法的主要关注点是从参考音频示例进行样式转换。他们既不提供系统采样机制,也不能像第4.3.1节中所示解码出表示。
与这些方法类似,(2018)由VAE生成的潜在参考嵌入对VoiceLoop进行了扩展,使用居中固定方差各向同性高斯用于潜在属性的优先级。这提供了从隐式分布中采样的原理机制,但不提供可解释性。相反,GMVAE-Tacotron潜在模型使用混合分布的属性,可以自动发现隐式的属性簇。这种结构使解释潜在的空间变得更加容易。具体来说,我们在部分中显示4.1可以分析混合物参数以了解每种成分对应的含义类似于GST。此外,可以确定潜在空间最独特的尺寸使用组件内部/组件内部的差异率,例如可以识别控制尺寸的背景噪声水平如第4.2.2节所示。
最后,第2.3节中描述的扩展将第二个混合分布添加到为发音人属性建模。这种表述学习混合的说话者和潜在属性表示,可以用来估计训练中以前未知的发音人的声音。(2018)模型它使用发音人嵌入,并训练一个单独的回归模型以根据音频进行预测。这个可以被视为所提议模型的特殊情况,其中 z 0 z_0 z0的方差设置为几乎为零,这样说话者总是会产生固定的表现;同时,后验模型 q ( z 0 ∣ X ) q(z_0 | X) q(z0∣X)对应于其嵌入预测变量,因为它现在旨在预测每个嵌入对象的固定嵌入。
(2016 )探索了在VAE中使用混合分布来处理潜在变量。(2017)用于无条件图像生成和文本主题造型。这些模型对应于在图1所提出的模型子图形 y l − > z l − > X y_l->z_l->X yl−>zl−>X。该方法提供额外的灵活性来对条件生成中的潜在属性和观察到的属性进行建模场景。(2017)在变量级别上类似地学习了解缠结表示(即通过为不同的潜在变量定义不同的先验来解开 z l z_l zl和 z 0 z _ 0 z0)。(2017)还使用了先验的对角协方差矩阵来分解不同的嵌入尺寸。我们的模型通过学习每种混合物成分的不同方差来提供额外的灵活性。
四、实验
欢迎进群交流~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









