










语音合成 | 精选论文汇总(197篇)
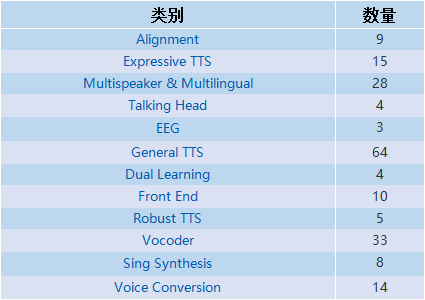
本文为大家整理了语音合成相关论文197篇,共分为12部分,分类如下:
(转至文末链接,免费获取源码链接及PDF版论文)
Journal and conference on speech

Alignment
1.Online and Linear-Time Attention by Enforcing Monotonic Alignments
Code: https://github.com/craffel/mad
2.Forward Attention in Sequence-to-Sequence Acoustic Modeling for Speech Synthesis
3.Monotonic Chunkwise Attention
Code: https://github.com/j-min/MoChA-pytorch
4.Initial Investigation of An Encoder-Decoder End-to-End TTS Framework Using Marginalization of Monotonic Hard Latent Alignments
5.Robust Sequence-to-Sequence Acoustic Modeling with Stepwise Monotonic Attention for Neural TTS
Code: https://gist.github.com/mutiann/38a7638f75c21479582d7391490df37c
6.Attentron:Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding
7.Location-Relative Attention Mechanisms for Robust Long-Form Speech Synthesis
Code: https://github.com/bshall/Tacotron
https://github.com/anandaswarup/TTS
8.Peking Opera Synthesis via Duration Informed Attention Network
9.Understanding Self-Attention of Self-Supervised Audio Transformers
Dual Learning
1.Listening While Speaking:Speech Chain by Deep Learning
2.Machine Speech Chain with One-Shot Speaker Adaptation
3.Almost Unsupervised Text to Speech and Automatic Speech Recognition
Code:https://github.com/RayeRen/unsuper_tts_asr
4.LRSpeech:Extremely Low-Resource Speech Synthesis and Recognition
EEG
1.Advancing Speech Synthesis Using EEG
2.Predicting Different Acoustic Features From EEG and towards Direct Synthesis of Audio Waveform From EEG
3.Speech Synthesis Using EEG
Expressive TTS
1.Hierarchical Generative Modeling for Controllable Speech Synthesis
Code:https://github.com/rarefin/TTS_VAE
https://github.com/lturing/Tools
2.Predicting Expressive Speaking Style From Text in End-to-End Speech Synthesis
3.Style Tokens:Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Code:https://github.com/syang1993/gst-tacotron
4.Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
Demo 地址:https://google.github.io/tacotron/publications/end_to_end_prosody_transfer/
5.Mellotron:Multispeaker Expressive Voice Synthesis by Conditioning On Rhythm, Pitch and Global Style tokens
Code: https://github.com/NVIDIA/mellotron
6.Multi-Reference Neural TTS Stylization with Adversarial Cycle Consistency
Code: https://github.com/entn-at/acc-tacotron2
7.Multi-Reference Tacotron by Intercross Training for Style Disentangling, Transfer and Control in Speech Synthesis
8.Controllable Emotion Transfer for End-to-End Speech Synthesis
9.Controllable Neural Prosody Synthesis
10.Enhancing Speech Intelligibility in Text-to-Speech Synthesis Using Speaking Style Conversion
11.Fine-Grained Emotion Strength Transfer, Control and Prediction for Emotional Speech Synthesis
12.Flowtron:An Autoregressive Flow-Based Generative Network for Text-to-Speech Synthesis
Code: https://github.com/Sebidev/flowtron
13.Fully-Hierarchical Fine-Grained Prosody Modeling for interpretable Speech Synthesis
Demo 地址:https://google.github.io/tacotron/publications/hierarchical_prosody/index.html
14.Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis
15.Whispered and Lombard Neural Speech Synthesis
Front End
1.Automatic Prosody Prediction for Chinese Speech Synthesis Using Blstm-Rnn and Embedding Features
2.Improving Prosodic Boundaries Prediction for Mandarin Speech Synthesis by Using Enhanced Embedding Feature and Model Fusion Approach
3.Mandarin Prosody Prediction Based On Attention Mechanism and Multimodel Ensemble
4.A Mandarin Prosodic Boundary Prediction Model Based On Multi Task Learning
5.Pre-Trained Text Representations for Improving Front-End Text Processing in Mandarin Text-to-Speech Synthesis
6.Token-Level Ensemble Distillation for Grapheme-to-Phoneme Conversion
Code:https://github.com/sigmeta/g2p-kd
7.A Hybrid Text Normalization System Using Multi-Head Self-Attention for Mandarin
8.A Mask-Based Model for Mandarin Chinese Polyphone Disambiguation
9.A Unified Sequence-to-Sequence Front-End Model for Mandarin Text-to-Speech Synthesis
10.Unified Mandarin TTS Front-End Based On Distilled Bert Model
General TTS
1.Statical Parameteric Speech Synthesis Using Deep Neural Networks
2.TTS Synthesis with Bidirectional Lstm Based Recurrent Neural Networks
3.A Study of Speaker Adaptation for Dnn-Based Speech Synthesis
4.Acoustic Modeling in Statistical Parametric Speech Synthesis–From Hmm to Lstm-Rnn
5.Effective Approaches to Attention-Based Neural Machine Translation
Code:https://github.com/lingyongyan/Neural-Machine-Translation
6.The Htk Book
7.Fast, Compact, and High Quality Lstm-Rnn Based Statistical Parametric Speech Synthesizers for Mobile Devices
8.Merlin:An Open Source Neural Network Speech Synthesis System
Code: https://github.com/speechdnn/merlin
9.Attention Is All You Need
Code:https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://github.com/Lsdefine/attention-is-all-you-need-keras
https://github.com/soskek/attention_is_all_you_need
10.Char2wav:End-to-End Speech Synthesis
Code:https://github.com/sotelo/parrot
Demo:http://www.josesotelo.com/speechsynthesis/
11.Deep Voice2:Multi-Speaker Neural Text-to-Speech
12.Deep Voice:Real-Time Neural Text-to-Speech
Code:https://github.com/israelg99/deepvoice
13.Tacotron:towards End-to-End Speech Synthesis
Demo:https://google.github.io/tacotron/publications/tacotron/index.html
14.Voiceloop:Voice Fitting and Synthesis Via A Phonological Loop
15.Clarinet:Parallel Wave Generation in End-to-End Text-to-Speech
Demo:https://clarinet-demo.github.io/
16.Deep Voice 3:Scaling Text-to-Speech with Convolutional Sequence Learning
Code: https://github.com/r9y9/deepvoice3_pytorch
17.A 2019 Guide to Speech Synthesis with Deep Learning
18.Deep Text-to-Speech System with Seq2seq Model
19.Durian:Duration informed Attention Network for Multimodal Synthesis
Code:https://github.com/entn-at/DurIAN-1
20.Exploiting Syntactic Features in A Parsed Tree to Improve End-to-End TTS
21.Fastspeech:Fast,Robust and Controllable Text to Speech
Code:https://github.com/Deepest-Project/FastSpeech
22.Forward-Backward Decoding for Regularizing End-to-End TTS
23.Libritts:A Corpus Derived From Librispeech for Text-to-Speech
24.Maximizing Mutual information for Tacotron
Code: https://github.com/makman09/tacotron2
25.Neural Speech Synthesis with Transformer Network
Code:https://github.com/lfchener/Transformer-TTS
26.Non-Autoregressive Neural Text-to-Speech
Code: https://github.com/ksw0306/WaveVAE
27.Parallel Neural Text-to-Speech
Demo:https://github.com/parallel-neural-tts-demo/parallel-neural-tts-demo.github.io
Code: https://github.com/ksw0306/WaveVAE
28.Self-Attention Based Prosodic Boundary Prediction for Chinese Speech Synthesis
29.Tacotron-Based Acoustic Model Using Phoneme for Practical Neural Text-to-Speech Systems
30.Tutorial On End-to-End Text-to-Speech Synthesis
31.Controllable Neural Prosody Synthesis
32.Deep Mos Predictor for Synthetic Speech Using Cluster-Based Modeling
33.Deep Representation Learning in Speech Processing Challenges Recent Advances and Future Trends
34.Devicetts:Asmall-Footprint,Fast,Stable Network for On-Device Text-to-Speech
35.End-to-End Adversarial Text-to-Speech
Code: https://github.com/yanggeng1995/EATS
36.Fast and Lightweight On-Device TTS with Tacotron2 and Lpcnet
37.Fastspeech 2 Fast and High Quality End to End Text to Speech
Code: https://github.com/ming024/FastSpeech2
https://github.com/rishikksh20/FastSpeech2
https://github.com/ga642381/FastSpeech2
https://github.com/dathudeptrai/FastSpeech2
38.Feathertts:Robust and Efficient Attention Based Neural TTS
39.Flowtron:an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
Code: https://github.com/NVIDIA/flowtron
Demo: https://nv-adlr.github.io/Flowtron
40.From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint
Code: https://github.com/caizexin/tf_multispeakerTTS_fc
41.Glow-TTS:A Generative Flow for Text-to-Speech Via Monotonic Search
Code: https://github.com/ntzzc/glow-tts
42.Graphspeech:Syntax-Aware Graph Attention Network for Neural Speech Synthesis
Code: https://github.com/ttslr/GraphSpeech
43.Hierarchical Prosody Modeling for Non-Autoregressive Speech Synthesis
44.incremental Text to Speech for Neural Sequence-to-Sequence Models Using Reinforcement Learning
45.interactive Text-to-Speech Via Semi-Supervised Style Transfer Learning
46.JDI-T:Jointly trained Duration Informed Transformer for Text-To-Speech without Explicit Alignment
47.Location Relative Attention Mechanisms for Robust Long Form Speech Synthesis
Code: https://github.com/anandaswarup/TTS
48.Non-Attentive Tacotron:Robust and Controllable Neural TTS Synthesis including Unsupervised Duration Modeling
Demo: https://google.github.io/tacotron/publications/nat/index.html
49.Parallel Tacotron:Non-Autoregressive and Controllable TTS
Demo: https://google.github.io/tacotron/publications/parallel_tacotron/index.html
50.Pretraining Strategies, Waveform Model Choice, and Acoustic Configurations for Multi-Speaker End-to-End Speech Synthesis
51.Prosody Learning Mechanism for Speech Synthesis System without Text Length Limit
52.Recognition-Synthesis Based Non-Parallel Voice Conversion with Adversarial Learning
53.Speaking Speed Control of End-to-End Speech Synthesis Using Sentence-Level Conditioning
54.Speech Synthesis and Control Using Differentiable DSP
55.Speedyspeech- Efficient Neural Speech Synthesis
Code: https://github.com/janvainer/speedyspeech
56.Squeezewave:Extremely Lightweight Vocoders for On Device Speech Synthesis
Code:https://github.com/tianrengao/squeezewave
57.TTS-by-TTS:TTS-Driven Data Augmentation for Fast and High-Quality Speech Synthesis
58.Unsupervised Learning for Sequence-to-Sequence Text-to-Speech for Low-Resource Languages
59.Adaspeech:Adaptive Text to Speech for Custom Voice
Code: https://github.com/rishikksh20/AdaSpeech
60.Bidirectional Variational inference for Non-Autoregressive Text-to-Speech
61.Building Multilingual TTS Using Cross-Lingual Voice Conversion
62.Lightspeech:Lightweight and Fast Text to Speech with Neural Architecture Search
Code: https://github.com/rishikksh20/LightSpeech
63.TripleM:Apractical Text-to-Speech Synthesis System with Multi-Guidance Attention and Multi-Band Multi-Time Lpcnet
64.Vara-TTS:Non-Autoregressive Text-to-Speech Synthesis Based On Very Deep Vae with Residual Attention
Demo: https://github.com/vara-tts/VARA-TTS
Multispeaker & Multilingual
1.Multi-Speaker Modeling and Speaker Adaptation for Dnn-Based TTS Synthesis
2.Speaker Representations for Speaker Adaptation in Multiple Speakers’ Blstm-Rnn-Based Speech Synthesis
3.Cross Lingual Multi Speaker Texttospeech Synthesis for Voice Cloning without Using Parallel Corpus for Unseen Speakers
4.Cross-Lingual,Multi-Speaker Text-to-Speech Synthesis Using Neural Speaker Embedding
5.Learning to Speak Fluently in Aforeign Language:Multilingual Speech Synthesis and Cross-Language Voice Cloning
6.Master Thesis:Automatic Multispeaker Voice Cloning
7.Training Multi-Speaker Neural Text-to-Speech Systems Using Speaker-Imbalanced Speech Corpora
8.Transfer Learning From Speaker Verification to Multispeaker Text-to-Speech Synthesis
Code:https://github.com/smoke-trees/Voice-synthesis
9.个性化语音合成中说话人特征不同嵌入方式的研究
10.Can Speaker Augmentation Improve Multi-Speaker End-to-End TTS
11.Cross-Lingual Multispeaker Text-to-Speech Under Limited-Data Scenario
Demo:https://caizexin.github.io/mlms-syn-samples/index.html
12.Domain-Adversarial Training of Multi-Speaker TTS
13.Efficient Neural Speech Synthesis for Low Resource Languages Through Multilingual Modeling
14.End-to-End Code-Switching TTS with Cross-Lingual Language Model
15.Focusing On Attention:Prosody Transfer and Adaptative Optimization Strategy for Multi Speaker End to End Speech Synthesis
16.Generating Multilingual Voices Using Speaker Space Translation Based On Bilingual Speaker Data
17.Multi-Speaker Text-to-Speech Synthesis Using Deep Gaussian Processes
18.Multilingual Speech Synthesis
19.One Model, Many Languages:Meta Learning for Multilingual Text to Speech
Code: https://github.com/Tomiinek/Multilingual_Text_to_Speech
20.Phonological Features for 0-Shot Multilingual Speech Synthesis
Code:https://github.com/papercup-open-source/phonological-features
21.Semi-Supervised Learning for Multi-Speaker Text-to-Speech Synthesis Using Discrete Speech Representation
Code: https://github.com/ttaoREtw/semi-tts
22.Speaker Adaptation of A Multilingual Acoustic Model for Cross-Language Synthesis
23.Towards Natural Bilingual and Code-Switched Speech Synthesis Based On Mix of Monolingual Recordings and Cross-Lingual Voice Conversion
Code: https://github.com/espnet/espnet
24.Using Ipa-Based Tacotron for Data Efficient Cross-Lingual Speaker Adaptation and Pronunciation Enhancement
25.Zero-Shot Multi-Speaker Text-to-Speech with State-of-The-Art Neural Speaker Embeddings
26.Adaspeech:Adaptive Text to Speech for Custom Voice
Code: https://github.com/rishikksh20/AdaSpeech
27.Building Multilingual TTS Using Cross-Lingual Voice Conversion
28.Investigating On incorporating Pretrained and Learnable Speaker Representations for Multi-Speaker Multi-Style Text-to-Speech
Robust TTS
1.Disentangling Correlated Speaker and Noise for Speech Synthesis Via Data Augmentation and Adversarial Factorization
Code:https://github.com/meelement/noise_adversarial_tacotron
2.Neural Text-to-Speech Adaptation From Low Quality Public Recordings
3.Can Speaker Augmentation Improve Multi-Speaker End-to-End TTS
Code:https://github.com/nii-yamagishilab/multi-speaker-tacotron
4.Data Efficient Voice Cloning From Noisy Samples with Domain Adversarial Training
5.Noise Robust TTS for Low Resource Speakers Using Pre-Trained Model and Speech Enhancement
Sing Synthesis
1.Mellotron:Multispeaker Expressive Voice Synthesis by Conditioning On Rhythm, Pitch and Global Style tokens
Code: https://github.com/NVIDIA/mellotron
2.A Comprehensive Survey On Deep Music Generation Multi-Level Representations, Algorithms, Evaluations, and Future Directions
3.ByteSing:A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder Decoder Acoustic Models and Wavernn Vocoders
4.Durian Sc:Duration informed Attention Network Based Singing Voice Conversion System
Code:https://github.com/tencent-ailab/learning_singing_from_speech
5.HiFiSinger:Towards High Fidelity Neural Singing Voice Synthesis
6.Jukebox:A Generative Model for Music
Code: https://github.com/openai/jukebox
7.Speech-to-Singing Conversion Based On Boundary Equilibrium Gan
8.Xiaoicesing:A High-Quality and integrated Singing Voice Synthesis System
Demo:https://github.com/xiaoicesing/xiaoicesing.github.io
Talking Head
1.Talking Face Generation by Adversarially Disentangled Audio-Visual Representation
Code:https://github.com/Hangz-nju-cuhk/Talking-Face-Generation-DAVS
2.Text-Based Editing of Talking-Head Video
Project:http://zollhoefer.com/papers/SG2019_TalkingHead/page.html
3.A Novel Face-Tracking Mouth Controller and Its Application to interacting with Bioacoustic Models
4.Large-Scale Multilingual Audio Visual Dubbing
Vocoder
1.Fast Wavenet Generation Algorithm
Code:https://github.com/tomlepaine/fast-wavenet
2.Wavenet:A Generative Model for Raw Audio
Demo:https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
3.Parallel Wavenet:Fast High-Fidelity Speech Synthesis
4.Efficient Neural Audio Synthesis
Code: https://github.com/ys10/WaveRNN
5.Improving Fftnet Vocoder with Noise Shaping and Subband Approaches
6.Natural TTS Synthesis by Conditioning Wavenet On Mel Spectrogram Predictions
Code: https://github.com/sooftware/tacotron2
7.A Neural Vocoder with Hierarchical Generation of Amplitude and Phase Spectra for Statistical Parametric Speech Synthesis
8.A Real-Time Wideband Neural Vocoder At 1.6 Kbs Using Lpcnet
9.An investigation of Subband Wavenet Vocoder Covering Entire Audible Frequency Range with Limited Acoustic Features
10.High Quality, Lightweight and Adaptable TTS Using Lpcnet
11.Melgan:Generative Adversarial Networks for Conditional Waveform Synthesis
Code: https://github.com/erogol/melgan-neurips
12.Rawnet:Fast End-to-End Neural Vocoder
Code: https://github.com/candlewill/RawNet
13.Waveglow:A Flow-Based Generative Network for Speech Synthesis
Code: https://github.com/yanggeng1995/WaveGlow
https://github.com/npuichigo/waveglow
14.A Cyclical Post-Filtering Approach to Mismatch Refinement of Neural Vocoder for Text-to-Speech Systems
15.Bunched Lpcnet:Vocoder for Low-Cost Neural Text-to-Speech Systems
16.Featherwave:An Efficient High-fidelity Neural Vocoder with Multi-Band Linear Prediction
Demo: https://github.com/wavecoder/FeatherWave
17.Gaussian Lpcnet for Multisample Speech Synthesis
18.Hifi-Gan:Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Code: https://github.com/rishikksh20/HiFi-GAN
19.Improving Lpcnet-Based Text-to-Speech with Linear Prediction-Structured Mixture Density Network
20.Improving Opus Low Bit Rate Quality with Neural Speech Synthesis
21.Investigating The Impact of Lookahead for incremental Neural TTS
22.Multi-Band Melgan:Faster Waveform Generation for High-Quality Text-to-Speech
23.Neural Text-to-Speech with A Modeling-by-Generation Excitation Vocoder
Demo: https://github.com/sewplay/demos
24.Parallel Wavegan:A Fast Waveform Generation Model Based On Generative Adversarial Networks with Multi-Resolution Spectrogram
Code:https://github.com/kan-bayashi/ParallelWaveGAN
25.Quasi-Periodic Parallel Wavegan Vocoder:Anon-Autoregressive Pitchdependent Dilated Convolution Model for Parametric Speech Generation
Demo:https://github.com/bigpon/QuasiPeriodicParallelWaveGAN_demo
26.Speaker Conditional Wavernn:towards Universal Neural Vocoder for Unseen Speaker and Recording Conditions
Code:https://github.com/dipjyoti92/SC-WaveRNN
27.Ultrasound-Based Articulatory-to-Acoustic Mapping with Waveglow Speech Synthesis
Code:https://github.com/BME-SmartLab/UTI-to-STFT
28.Universal Melgan:A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
Code: https://github.com/avi33/universalmelgan
29.Vocgan:A High-Fidelity Real-Time Vocoder with A Hierarchically Nested Adversarial Network
Code: https://github.com/rishikksh20/VocGAN
30.Vocoder-Based Speech Synthesis From Silent Videos
31.Wavegrad:Estimating Gradients for Waveform Generation
Code: https://github.com/ivanvovk/WaveGrad
32.Wg-Wavenet:Real-Timehigh-Fidelity Speech Synthesis without Gpu
Code:https://github.com/BogiHsu/WG-WaveNet
33.Gan Vocoder:Multi-Resolution Discriminator Is All You Need
Voice Conversion
1.An Overview of Voice Conversion Systems
2.Autovc:Zero-Shot Voice Style Transfer with Only Autoencoder Loss
Code: https://github.com/auspicious3000/autovc
3.Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations
Code: https://github.com/jxzhanggg/nonparaSeq2seqVC_code
4.Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion
Code: https://github.com/andi611/ZeroSpeech-TTS-without-T
5.Accent and Speaker Disentanglement in Many-to-Many Voice Conversion
6.An Overview of Voice Conversion and Its Challenges:From Statistical Modeling to Deep Learning
7.Any-to-One Sequence-to-Sequence Voice Conversion Using Self-Supervised Discrete Speech Representations
8.Converting Anyone’S Emotion:towards Speaker-independent Emotional Voice Conversion
Code:https://github.com/KunZhou9646/Speaker-independent-emotional-voice-conversion-based-on-conditional-VAW-GAN-and-CWT
9.Cyclegan-Vc3:Examining and Improving Cyclegan-Vcs for Mel-Spectrogram Conversion
Code: https://github.com/jackaduma/CycleGAN-VC3
10.Gazev:Gan-Based Zero-Shot Voice Conversion Over Non-Parallel Speech Corpus
11.Seen and Unseen Emotional Style Transfer for Voice Conversion with A New Emotional Speech Dataset
Code:https://github.com/HLTSingapore/Emotional-Speech-Data
12.Towards Low-Resource Stargan Voice Conversion Using Weight Adaptive instance Normalization
Code: https://github.com/MingjieChen/LowResourceVC
13.Building Multilingual TTS Using Cross-Lingual Voice Conversion
14.Emocat:Language-Agnostic Emotional Voice Conversion
转至链接:https://www.shenlanxueyuan.com/page/57
源码链接及PDF版论文

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









