







简介:无需依赖拼音或五笔输入法,手写输入技术允许用户通过鼠标或触摸屏直接在屏幕上绘制汉字进行文字输入。这种输入方式为不熟悉传统输入法的人群提供了一种直观、易学的替代方案。手写输入技术包含手写识别、笔画顺序理解、字库匹配、用户体验优化、跨平台支持、个性化设置及错误纠正学习等关键技术点。随着技术的进步,未来汉字手写输入将更加智能化,大幅提升用户体验。 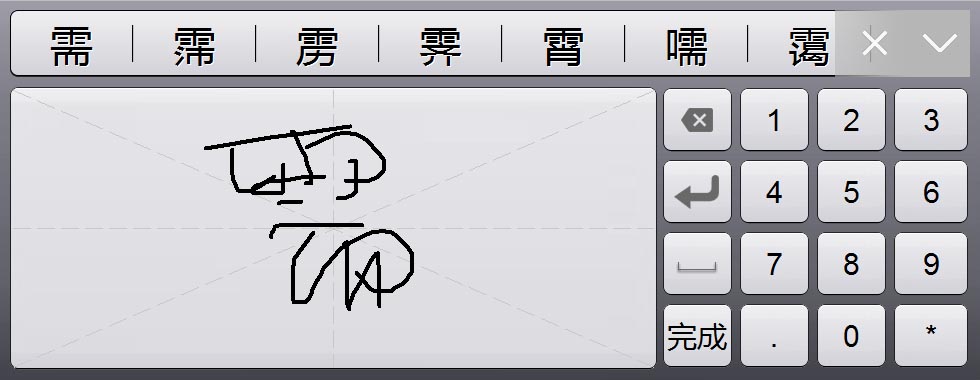
1. 手写识别技术
在现代信息技术中,手写识别技术是一个不断进步且至关重要的领域,它允许人们使用自然的手写方式与数字设备互动。随着人工智能和机器学习的发展,手写识别技术经历了从基本的光学字符识别(OCR)向更智能的笔画与语义分析技术的演变。
1.1 手写识别技术的演变
手写识别技术的发展历程,从最初的手写输入设备,到如今融合深度学习算法的智能识别系统,体现了技术与需求的双重进步。早期的系统依赖于规则和模板匹配,准确性有限;而现在,神经网络和深度学习模型极大地提高了识别率和准确性。
graph LR
A[手写输入设备] -->|规则匹配| B[初步的OCR技术]
B -->|引入深度学习| C[智能手写识别系统]
1.2 手写识别技术的应用
手写识别技术广泛应用于各种场景,包括智能手写笔、移动设备、教育软件和法律行业。它不仅提高了输入效率,还为语言学习、辅助教学和专业文档的创建提供了便利。
graph TD
A[手写识别技术]
A --> B[智能手写笔]
A --> C[移动设备]
A --> D[教育软件]
A --> E[法律文档处理]
为了更好地掌握手写识别技术,我们将在后续章节详细探讨笔画顺序、字库匹配、用户体验设计以及跨平台支持等关键方面。这些元素共同构成了现代手写识别系统的基础。
2. 笔画顺序与识别
2.1 笔画顺序的理论基础
2.1.1 笔画顺序的重要性
笔画顺序在汉字书写中具有至关重要的作用。在手写识别技术中,正确理解笔画顺序能够有效提升识别的准确性。这是因为汉字书写有一套固定的笔顺规则,遵循这些规则书写的汉字更容易被识别算法所理解和解析。正确的笔画顺序有助于区分形似字,例如“未”和“末”,这两字在笔画数量和形态上相似,但笔顺不同,若识别系统能准确识别笔顺,则可以有效区分它们。
2.1.2 识别笔画顺序的技术手段
在手写识别技术中,笔画顺序的识别一般依赖于触控笔或触摸屏上的压力感应技术。这些设备能够捕捉到书写时的压力变化,从而记录笔尖在屏幕上移动的轨迹,包括起始点、笔画方向和转折点等信息。此外,先进的手写识别算法还会利用人工智能,特别是机器学习技术,来分析和学习用户书写习惯,从而更加准确地推测笔画顺序。
2.2 笔画顺序的识别实践
2.2.1 实时笔画捕捉技术
实时笔画捕捉技术是通过高频率的采样和精确定位来实现对笔画顺序的捕捉。现代手写输入设备通常配备有高速的传感器和处理器,能够在毫秒级对用户的笔迹进行采样,确保捕捉到的笔画轨迹连贯且完整。此外,对于笔画的粗细变化、笔压强度等信息的捕捉,也能为识别算法提供额外的数据支持。
示例代码块
import cv2
import numpy as np
# 假设捕捉到的是笔画的轨迹点数组
stroke_points = np.array([[100, 100], [105, 102], [110, 105], ...])
# 使用OpenCV将轨迹点绘制出来
for i in range(1, len(stroke_points)):
cv2.line(img, stroke_points[i-1], stroke_points[i], (0, 255, 0), 2)
# 显示图像
cv2.imshow("Stroke Capture", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中,我们使用了OpenCV库来捕捉和显示笔画轨迹。每个点对应用户在屏幕上书写的一个坐标,我们通过绘制连续的线段将这些点连接起来,从而模拟笔画的捕捉过程。
2.2.2 笔画顺序的优化与算法
在手写识别技术中,为了提高笔画顺序的识别率,通常会使用特定的算法来优化处理。这包括但不限于使用动态时间规整(Dynamic Time Warping, DTW)算法来匹配笔画的模式,或者使用隐马尔可夫模型(Hidden Markov Model, HMM)来分析和预测用户的笔顺习惯。
表格展示笔画顺序优化算法的对比
| 算法名称 | 优点 | 缺点 | 应用场景 | |-------|------|------|-------| | DTW | 高度灵活性,能够处理不同速度的笔迹 | 计算量大,效率较低 | 个性化笔迹识别 | | HMM | 能够根据前后笔画预测后续笔画 | 需要大量样本进行训练 | 通用笔迹识别 |
通过上述表格,我们能够清楚地看到不同算法的应用场景和优缺点。在实际应用中,开发者会根据具体需求选择合适的算法。
2.3 笔画顺序的深度学习优化
随着深度学习技术的发展,越来越多的手写识别系统开始采用深度神经网络来优化笔画顺序的识别。卷积神经网络(Convolutional Neural Networks, CNNs)和长短期记忆网络(Long Short-Term Memory, LSTM)在图像识别和序列数据处理方面表现突出,因此也被应用于手写识别领域。
2.3.1 卷积神经网络在笔画识别中的应用
CNNs通过使用卷积层来提取图像中的特征,包括手写笔迹的笔画形状、笔画之间的空间关系等。在笔画顺序识别中,CNNs可以识别出笔画的特征,并结合上下文信息进行识别。
2.3.2 长短期记忆网络在序列数据处理中的作用
LSTM作为一种特殊的循环神经网络(RNN),能够处理和记忆序列数据中的长距离依赖关系。在笔画顺序的识别中,LSTM能够通过前后的笔画信息预测当前笔画的可能路径。
LSTM神经网络的代码示例
from keras.models import Sequential
from keras.layers import LSTM, Dense, Activation
# 假设我们已经有了笔画数据序列
data_sequences = np.array([...]) # 笔画序列数据
# 构建LSTM模型
model = Sequential()
model.add(LSTM(128, input_shape=(timesteps, input_dim), return_sequences=True))
model.add(LSTM(128))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
***pile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(data_sequences, labels, epochs=20, batch_size=32)
在这段代码中,我们使用Keras库构建了一个LSTM模型,并对其进行了训练。这个过程涉及到数据的预处理、模型的构建、编译以及训练。训练完成后,模型能够对笔画序列进行预测,从而辅助识别笔画顺序。
2.4 笔画顺序识别的挑战与未来方向
2.4.1 当前识别技术存在的问题
尽管现有的技术已经能够在很大程度上准确识别笔画顺序,但依然存在一些问题。例如,当用户书写速度过快或者笔画重叠时,系统可能难以准确捕捉笔画顺序。此外,不同的书写风格和习惯也会给识别带来挑战。
2.4.2 未来研究方向与技术突破
未来的笔画顺序识别技术研究可能会集中在以下几个方向:提高算法的鲁棒性、优化用户交互体验、结合多模态输入数据以获得更丰富信息等。通过深度学习技术的不断发展和算法的优化,未来手写识别技术有望达到更高的准确率和更好的用户体验。
笔画顺序识别作为手写识别技术的关键环节,不仅影响了识别的准确性,也对整个系统的用户体验起到了决定性作用。通过不断的技术创新和优化,相信我们能够在这一领域取得更大的突破。
3. 字库与匹配
随着人工智能技术的发展,手写识别技术已经变得越来越精准。然而,无论技术多么先进,手写识别的核心依旧依赖于字库的完备性和匹配算法的高效性。本章深入探讨现代字库的发展与特点,以及字符匹配在提高识别准确性中的作用和挑战。
3.1 现代字库的发展与特点
3.1.1 汉字字库的基本构成
汉字字库是一个庞大的体系,它不仅包含数以万计的汉字字符,还包括了它们的变形、变体以及与之相关的字形、字音、字义等信息。字库的基本构成通常包括以下几个部分:
- 基本字形:涵盖了标准字形、印刷体字形和手写体字形。
- 字形数据:描述了字形的点阵信息、矢量信息和轮廓信息。
- 字符编码:将每个字形与其对应的编码关联起来。
- 字音字义:记录每个字的读音和含义。
- 风格特征:包含了笔画粗细、字体风格(如宋体、黑体等)和书写风格(如行书、草书等)。
字库的构建涉及到复杂的图形学和计算机视觉技术,需要大量的人工校验和机器学习优化以确保高质量的字形数据和准确的字符信息。
3.1.2 字库与手写识别的关联
在手写识别技术中,字库是一个不可或缺的组成部分。手写识别系统依赖于字库提供的大量样本来训练其识别模型。字库中的每个字符样本都是系统学习的一个数据点,越多的数据点意味着越高的识别准确率。
字库的规模和质量直接影响到手写识别的性能。例如,一个包含多种书写字体和风格的字库能够让系统更好地处理各种实际书写场景下的手写输入。同时,字库中字符编码的一致性对于编码解析和字符匹配也至关重要。
3.2 字符匹配与识别准确性
3.2.1 字符识别的准确性挑战
字符识别的准确性一直是手写识别技术研究的重点。由于个体书写差异、笔画的连贯性、书写的随意性等因素,使得准确识别每个字符变得十分困难。尤其在中文手写输入中,同音字、相似字的混淆问题尤为突出。
例如,在识别过程中可能会将“清”和“青”这样的同音字混淆,或者将“十”和“千”这样的形状相似字混淆。这样的错误会大大降低用户在使用手写输入时的体验。
3.2.2 错误匹配的排除策略
为了解决字符识别中的准确性挑战,研究者们开发了多种排除策略以减少错误匹配的发生:
- 上下文分析:通过分析字词的上下文关系来推断可能的正确字符。
- 统计语言模型:利用大量文本数据统计字词出现的频率,提升匹配的准确性。
- 机器学习算法:应用诸如深度学习等技术,通过不断学习减少错误识别。
- 用户反馈机制:利用用户的纠错信息来优化识别模型。
这些策略的实施需要在字库和算法上进行深度集成和优化。在实际应用中,通过机器学习的持续训练和用户反馈的不断输入,可以逐步提升手写识别系统的性能。
在本小节中,我们引入一个简单的代码块来演示如何使用Python进行字符匹配的基本操作。尽管实际的手写识别系统要复杂得多,但以下示例可以展示字符匹配的基本逻辑。
import difflib
# 假设我们有一个字库的字形数据
font_data = {'清': 'qing', '青': 'qing', '十': 'shi', '千': 'qian'}
# 用户输入的手写字符序列
user_input = 'qing'
# 查找字库中与用户输入相似度最高的字
def match_character(input_char, font_data):
matches = difflib.get_close_matches(input_char, font_data.keys())
if matches:
return matches[0]
return None
# 执行匹配操作
matched_char = match_character(user_input, font_data)
if matched_char:
print(f"匹配成功,最相似的字是:{matched_char}")
else:
print("没有找到匹配的字。")
上述代码使用了 difflib 库来找到最相似的字,这是基于字符串相似度的一种简单匹配。在真实场景中,匹配过程会涉及更复杂的算法和大数据量的分析。
通过以上分析,我们看到了字库在手写识别中的重要性,以及字符匹配在提升准确率方面的关键作用。字库与匹配是手写识别技术中的基础组件,它们的不断优化和创新是提高手写识别准确度的关键路径。在下一章中,我们将讨论用户体验设计对于手写识别技术的影响和重要性。
4. 用户体验设计
用户体验设计(UX Design)是确保用户与产品交互时感受愉快、高效并完成目标的关键因素。本章节深入探讨用户体验设计的基本原则,以及如何通过用户界面和交互设计提升用户满意度和产品可用性。
4.1 用户体验设计的基本原则
在用户体验设计中,基本原则是为用户提供愉悦、有效和有价值的体验。这些原则在设计过程中充当指南针,确保产品设计符合用户的期望和需求。
4.1.1 用户需求分析
用户体验设计开始于对用户需求的深入理解。用户需求分析涉及对目标用户群体进行市场调研、访谈、问卷调查、用户测试等方法,以获取他们对产品使用的期望和痛点。理解用户需求不仅包括基本的使用场景,还包括用户的个人偏好、使用环境以及任务目标。
4.1.2 设计原则与目标用户群体
设计原则是指导设计师在产品开发过程中做出决策的规则和框架。对于不同的目标用户群体,设计原则可能需要进行调整。例如,面向儿童的应用需要充满乐趣和互动性,而面向专业人士的应用则需要注重效率和直观性。目标用户群体的特征,如年龄、文化背景、技术熟练度等,都将直接影响到用户体验设计的实施策略。
设计原则示例
- 简洁性:界面元素和操作流程尽可能简化。
- 可访问性:确保产品可以被所有用户使用,包括那些有障碍的人。
- 可靠性:系统稳定,用户可以信赖产品完成任务。
- 一致性:在产品的不同部分和不同场景中保持设计和操作的一致性。
4.2 用户界面与交互设计
用户界面(UI)和交互设计是用户体验设计的核心组成部分,它们直接影响用户对产品的第一印象和操作感受。
4.2.1 界面设计的便捷性与直观性
界面设计的便捷性与直观性意味着用户可以轻易地理解界面布局、元素和操作流程。设计应该遵循人类的直觉,使用通用的符号和图标,以及明确的标签和提示。同时,界面设计应减少用户的认知负担,使用户能够快速学会如何使用产品。
交互设计的流程图示例
以下是一个简化的设计流程图,描述了交互设计的步骤:
flowchart LR
A[用户需求分析] --> B[原型设计]
B --> C[用户测试]
C --> D[反馈分析]
D -->|需要修改| B
D -->|设计确认| E[详细设计]
E --> F[开发]
F --> G[产品发布]
G --> H[市场反馈]
H -->|需要迭代| E
4.2.2 交互设计的流畅性与反馈机制
交互设计的流畅性指的是用户在使用产品时的操作流程应该连贯、无阻碍。设计应该考虑到用户操作的自然流程,并在可能的环节减少步骤。此外,流畅的交互设计还包括及时且合理的反馈机制,以告知用户他们的操作是否成功,系统状态如何,以及接下来该怎么做。
代码块示例
下面是一个简单的HTML和JavaScript代码示例,展示了如何为一个按钮添加点击事件的反馈。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>交互设计反馈示例</title>
<script>
function handleClick() {
alert("操作已执行!");
}
</script>
</head>
<body>
<button onclick="handleClick()">点击我</button>
</body>
</html>
在上面的代码中,当用户点击按钮时, handleClick 函数会被调用,弹出一个提示框告知用户操作已执行。这是一个基本的用户操作反馈机制,实际产品中的反馈机制会更为复杂,并且会根据用户的操作和产品的上下文来提供个性化的反馈。
通过以上的例子,可以看出,用户体验设计是一个全面考虑用户需求、界面布局和交互逻辑的综合过程,每一个环节都是为了让产品更加易用、可靠并满足用户的目标。在接下来的章节中,我们将继续探讨如何通过技术手段来跨平台支持产品的广泛使用,以及如何实现个性化设置和错误纠正,进一步提升用户体验。
5. 跨平台支持
跨平台支持已经成为软件开发的一个重要方面,特别是在手写识别技术领域,用户期望他们的应用能够在各种设备和操作系统上无缝运行。本章将探讨跨平台技术面临的挑战与机遇,并提供一些跨平台策略和实践案例。
5.1 跨平台技术的挑战与机遇
随着技术的发展,市场上出现了多样化的操作系统,例如Windows、macOS、Linux、iOS和Android等。每个系统都有其独特的特性和限制,这就对跨平台应用的设计与实现带来了挑战。
5.1.1 不同操作系统间的兼容问题
每个操作系统都有一套自己的编程接口、安全模型和用户界面指南。开发人员必须确保应用在不同平台上运行时的一致性和兼容性。例如,Windows系统广泛使用Win32 API,而Linux系统可能使用GTK+或Qt框架。这意味着同一套代码可能无法直接跨平台运行,需要进行适当的调整和优化。
// 伪代码示例,展示不同平台可能的代码差异
#if WINDOWS
var file = new FileDialog().ShowOpenFileDialog();
#elif LINUX
var file = new Gtk.FileChooserDialog(...);
#endif
在上例中,我们看到即使是简单的文件打开对话框的实现,在不同的操作系统上也需要不同的API调用。跨平台框架能够帮助简化这一过程,通过封装不同平台间的差异,为开发者提供统一的API。
5.1.2 跨平台解决方案的探究
为了解决不同操作系统间的兼容性问题,出现了多种跨平台技术解决方案。这些方案大致可以分为以下几类:
- 原生跨平台框架,如Qt和Electron,它们允许开发者使用单一的代码库,而运行时会为不同平台编译相应的原生应用。
- Web技术,利用HTML、CSS和JavaScript构建Web应用,然后通过WebView或PWA技术在不同平台上运行。
- 虚拟机和容器技术,如Wine,它通过模拟其他操作系统的环境来运行应用。
每种方案都有其优缺点,选择合适的跨平台解决方案需要根据项目需求、开发团队的熟悉度、性能要求和维护成本等多方面因素来决定。
5.2 跨平台策略与实践
选择合适的跨平台策略和实践对于项目的成功至关重要。本节将探讨如何选择合适的跨平台开发框架,以及如何部署和维护跨平台产品。
5.2.1 跨平台开发框架的选择
跨平台开发框架的选择是一个复杂过程,因为每种框架都有其特定的优势和限制。例如,使用Qt框架可以开发出在多个平台上有原生外观和性能的应用,但是它需要开发人员精通C++。而使用Electron可以快速开发出跨平台的桌面应用,因为它基于Web技术,这使得前端开发者可以更容易上手,但可能在性能上有所牺牲。
// Electron 示例代码
const { app, BrowserWindow } = require('electron');
function createWindow() {
const win = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
nodeIntegration: true
}
});
win.loadFile('index.html');
}
app.whenReady().then(createWindow);
Electron的示例代码显示了它如何允许使用Node.js和Web技术来开发桌面应用。这段代码演示了创建一个新窗口,并加载一个HTML文件作为应用的界面。
5.2.2 跨平台产品的部署与维护
部署跨平台产品需要考虑多方面的因素,例如如何打包应用、分发和更新机制等。很多跨平台框架提供了内置的工具来自动化这些流程。
例如,对于Electron应用,开发者可以使用electron-builder或electron-packager等工具来打包应用,并创建安装包供用户下载。这些工具可以配置应用的签名、图标、构建配置等,使得构建过程更加方便和标准化。
# electron-builder 配置文件示例
name: 'ElectronApp'
author: 'Your Name'
description: 'An example of electron-builder configuration'
win:
target: nsis
icon: 'build/icons/win/icon.ico'
在上例中,一个简单的YAML配置文件定义了Electron应用的名称、作者、描述以及Windows平台的打包目标和图标。这样的配置使得应用构建过程更加清晰和可维护。
跨平台产品的维护也是一个持续的过程。为了保持应用的稳定性和安全性,开发团队需要定期更新应用,修复发现的问题,并适配新版本的操作系统。跨平台框架的自动化工具在这里扮演了关键角色,它们可以帮助自动化测试和更新流程。
# 自动化脚本示例,用于更新应用
import subprocess
import os
def update_app():
# 更新应用源代码
subprocess.run(['git', 'pull'], cwd='path/to/repo')
# 构建新版本应用
subprocess.run(['./build_app.sh'], cwd='path/to/repo')
# 分发新版本应用
subprocess.run(['./distribute_app.sh'], cwd='path/to/repo')
if __name__ == "__main__":
update_app()
在上面的Python脚本中,我们演示了如何自动化更新应用的过程。这个脚本会首先拉取最新代码,然后构建新版本的应用,并执行分发脚本将新版本部署到用户手中。
跨平台技术为开发者提供了前所未有的灵活性,但也带来了新的挑战。本章所涵盖的内容和实践可以帮助开发团队在多样化的技术环境中成功地推出他们的手写识别应用。
6. 个性化设置与错误纠正
6.1 个性化输入的实现方式
6.1.1 用户偏好设置与记忆功能
用户在使用手写输入系统时,往往希望能够根据自己的使用习惯来调整输入偏好,如字体大小、颜色、笔触粗细等。用户偏好设置能够存储用户对这些个性化选项的选择,并在用户下次使用时自动应用这些设置,以增强用户满意度。
为了实现这一点,手写识别系统可以使用本地存储或云同步的方式保存用户的偏好设置。开发者需要提供一个用户界面,让用户能够轻松地调整这些设置,并通过编程代码将用户的设置保存到一个配置文件中。例如,使用JSON格式存储用户的偏好设置,并在应用程序启动时读取这些信息。
{
"userPreferences": {
"fontColor": "#FFFFFF",
"fontSize": "16",
"brushWidth": "3",
"language": "en-US",
"touchSensitivity": "medium"
}
}
此外,系统还需要考虑记忆功能,以适应用户的手写风格和习惯。这就需要手写输入系统具备学习用户笔迹的能力。可以通过收集用户的笔画数据,使用机器学习算法逐步优化手写识别模型,从而提高对用户手写笔迹的识别准确率。
6.1.2 个性化词库的构建与优化
个性化词库是根据用户的使用习惯和输入历史构建的词汇集合。在中文输入法中,用户常输入的词组或短语会被自动添加到个性化词库中,从而加快输入速度。个性化词库的构建需要对用户输入数据进行分析,并根据分析结果动态调整词库内容。
构建个性化词库的过程通常包括以下几个步骤: 1. 收集用户输入数据,包括完整输入和未完成输入。 2. 使用自然语言处理技术进行分词处理。 3. 记录每个词或词组的使用频率。 4. 将高频词汇优先推荐给用户。
代码示例:
# 假设这是一个分词函数
def tokenize(text):
# 使用分词库进行分词操作
# 返回分词结果
pass
# 用户输入历史记录
user_input_history = [
"输入法界面设计应该符合用户习惯",
"用户界面的设计可以提高用户体验",
"界面的设计需要考虑用户的实际需求"
]
# 分词并统计词频
word_frequency = {}
for sentence in user_input_history:
words = tokenize(sentence)
for word in words:
if word in word_frequency:
word_frequency[word] += 1
else:
word_frequency[word] = 1
# 按词频排序
sorted_words = sorted(word_frequency.items(), key=lambda x: x[1], reverse=True)
6.2 错误纠正与智能学习能力
6.2.1 常见输入错误类型与纠正方法
在手写识别过程中,用户可能会犯各种输入错误。这些错误通常可以分为几类,包括笔画错误、形状错误、位置错误以及结构错误。针对不同类型的错误,手写识别系统需要有相应的纠正策略。
- 笔画错误:识别笔画的顺序或者笔画数量错误。
- 形状错误:笔画形状与标准写法不一致,如将“一”写成类似数字“1”的形状。
- 位置错误:笔画书写的位置不正确,如将点写在横的上方而不是下方。
- 结构错误:整个字符的结构与标准写法有差异,如左右结构写成了上下结构。
纠正错误的策略可以包括: - 提供候选词提示,根据相似度排列,让用户选择。 - 使用笔画校正功能,通过笔画分析,给出建议修改点。 - 实施笔画、形状、位置、结构的智能识别与校正算法。
6.2.2 智能学习机制的设计与实现
智能学习机制的设计目标是让系统通过用户的输入数据自我优化,提高识别准确率和效率。系统通过实时收集用户的输入数据,分析用户的书写习惯,对识别模型进行动态调整。
实现智能学习机制的步骤通常包括: 1. 收集用户的手写样本数据。 2. 分析手写样本的笔画、结构和笔顺等特征。 3. 根据分析结果,调整识别模型参数。 4. 定期更新个性化词库和错误纠正策略。
为了实现智能学习,可以采用机器学习中的监督学习方法。例如,可以使用随机森林算法来区分和纠正用户的输入错误。代码示例:
from sklearn.ensemble import RandomForestClassifier
# 假设这是用户手写样本数据
user_samples = [
("用户手写样本数据", "正确输入文本"),
# 更多样本...
]
# 特征提取函数
def extract_features(sample):
# 提取样本的特征
# 返回特征数据
pass
# 训练智能学习模型
model = RandomForestClassifier()
for sample in user_samples:
sample_features = extract_features(sample)
model.fit(sample_features, sample[1]) # 训练数据
# 使用模型进行预测和错误纠正
def predict_and_correct(input_sample):
sample_features = extract_features(input_sample)
predicted_text = model.predict([sample_features])
return predicted_text[0]
在实际应用中,智能学习机制的设计需要兼顾准确性和效率,以便能够快速响应用户输入,并提供及时的反馈。
简介:无需依赖拼音或五笔输入法,手写输入技术允许用户通过鼠标或触摸屏直接在屏幕上绘制汉字进行文字输入。这种输入方式为不熟悉传统输入法的人群提供了一种直观、易学的替代方案。手写输入技术包含手写识别、笔画顺序理解、字库匹配、用户体验优化、跨平台支持、个性化设置及错误纠正学习等关键技术点。随着技术的进步,未来汉字手写输入将更加智能化,大幅提升用户体验。

















 5927
5927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









