










关于langchain的函数、工具、代理系列的博客我之前已经写了五篇,还没有看过的朋友请先看一下,这样便于对后续博客内容的理解:
LangChain的函数,工具和代理(一):OpenAI的函数调用
LangChain的函数,工具和代理(二):LangChain的表达式语言(LCEL)
LangChain的函数,工具和代理(三):LangChain中轻松实现OpenAI函数调用
LangChain的函数,工具和代理(四):使用 OpenAI 函数进行标记(Tagging) & 提取(Extraction)
LangChain的函数,工具和代理(五):Tools & Routing
今天我们来介绍本系列博客中的最后一篇“对话代理(Conversational agent)”, 在上一篇博客“LangChain的函数,工具和代理(五):Tools & Routing”中,我们定义了两个外部函数get_current_temperature和search_wikipedia,其中get_current_temperature的功能是调用外部天气api来获取指定经纬度地区的温度,而search_wikipedia的功能是调用维基百科的api来获取相关的信息,最后我们还创建了一个带有route能力的chain, 这样我们就可以真正实现外部函数的调用功能,比如当我们向这个chain询问某地天气的时候,该chain会返回该地区的实际温度,再比如当我们向这个chain询问某些科普知识的时候,它会查询维基百科并将查询结果返回给用户,当我们向该chain打招呼的时候,它也能回复我们亲切的问候语,也就是说目前已经基本实现了让llm从上下文中自主判断是否需要调用外部函数,如需调用外部函数就通过langchain来实现自动调用外部函数并返回调用结果给到用户。目前看来自动调用外部函数的整体流程已基本打通,但结果其实并不完美,原因是外部函数调用结果都是格式化的,这对用户来说并不友好,今天我们就来解决如何让外部函数的调用结果变的对用户更加友好。我们会涉及到langchain中的agent的一些基本概念:

这里所谓的agent指大型语言模型(LLMs)与代码的一种组合,它具有推理能力和执行力。为了完成任务,agent还必须要有迭代能力(agent loop),比如agent在完成任务时可能会使用一些工具(tool),并观察工具的使用结果,如果结果不满意可以使用别的工具,直到出现满意的结果才停止。
接下来在正式“抠腚”😀之前,先让我们做一些初始化的工作,如设置opai的api_key,这里我们需要说明一下,在我们项目的文件夹里会存放一个 .env的配置文件,我们将api_key放置在该文件中,我们在程序中会使用dotenv包来读取api_key,这样可以避免将api_key直接暴露在程序中:
#pip install -U python-dotenv
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']一、基本函数调用
接下来向让我们回顾一下上一篇博客中我们所定义的两个外部函数get_current_temperature和search_wikipedia:
from langchain.tools import tool
import requests
from pydantic import BaseModel, Field
import datetime
import wikipedia
# Define the input schema
class OpenMeteoInput(BaseModel):
latitude: float = Field(..., description="Latitude of the location to fetch weather data for")
longitude: float = Field(..., description="Longitude of the location to fetch weather data for")
@tool(args_schema=OpenMeteoInput)
def get_current_temperature(latitude: float, longitude: float) -> dict:
"""Fetch current temperature for given coordinates."""
BASE_URL = "https://api.open-meteo.com/v1/forecast"
# Parameters for the request
params = {
'latitude': latitude,
'longitude': longitude,
'hourly': 'temperature_2m',
'forecast_days': 1,
}
# Make the request
response = requests.get(BASE_URL, params=params)
if response.status_code == 200:
results = response.json()
else:
raise Exception(f"API Request failed with status code: {response.status_code}")
current_utc_time = datetime.datetime.utcnow()
time_list = [datetime.datetime.fromisoformat(time_str.replace('Z', '+00:00')) for time_str in results['hourly']['time']]
temperature_list = results['hourly']['temperature_2m']
closest_time_index = min(range(len(time_list)), key=lambda i: abs(time_list[i] - current_utc_time))
current_temperature = temperature_list[closest_time_index]
return f'The current temperature is {current_temperature}°C'
@tool
def search_wikipedia(query: str) -> str:
"""Run Wikipedia search and get page summaries."""
page_titles = wikipedia.search(query)
summaries = []
for page_title in page_titles[: 3]:
try:
wiki_page = wikipedia.page(title=page_title, auto_suggest=False)
summaries.append(f"Page: {page_title}\nSummary: {wiki_page.summary}")
except (
self.wiki_client.exceptions.PageError,
self.wiki_client.exceptions.DisambiguationError,
):
pass
if not summaries:
return "No good Wikipedia Search Result was found"
return "\n\n".join(summaries)这里我们看到,这两个函数都是通过调用外部api来获取我们想要的信息,接下来我们按照上篇博客介绍的方法来创建chain,并向它询问 “上海的天气” 然后让它返回函数调用的参数:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.tools.render import format_tool_to_openai_function
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
#创建工具集合
tools = [get_current_temperature, search_wikipedia]
#生成函数描述变量
functions = [format_tool_to_openai_function(f) for f in tools]
#创建llm,绑定函数描述变量
model = ChatOpenAI(temperature=0).bind(functions=functions)
#根据模板创建prompt
prompt = ChatPromptTemplate.from_messages([
("system", "You are helpful but sassy assistant"),
("user", "{input}"),
])
#创建chain
chain = prompt | model | OpenAIFunctionsAgentOutputParser()
#调用chain
result = chain.invoke({"input": "上海的天气现在怎么样?"})
result
这里我们看到llm返回函数名和调用的参数即上海的经纬度坐标。到目前位置我们已经获得了需要调用的函数名get_current_temperature,及上海的经纬度坐标latitude和longitude。按照上一篇博客介绍的方法,接下来我们还需要手动去调用该函数并获取函数返回值,或者通过创建route函数来自动调用函数并获取返回值。最后将外部函数的返回结果直接再返回给用户,比如:
response = get_current_temperature(result.tool_input)
response
这里我们手动调用了外部函数并得到函数的返回结果:“The current temperature is 16°C”,而我们的问题是:“上海的天气现在怎么样?”,显然这样的结果对用户是不友好的。因此我们需要将这个流程进行优化,我们不能将函数的返回结果直接返回给用户,因为函数的返回结果都是格式化的,格式化的结果对用户不友好。
二、手动优化
手动优化是在上面的基本函数调用的基础上将chain的返回结果和将外部函数的返回结果整合在一起之后,再次调用chain,并将整合的结果喂给llm,这样llm就会给出一个对用户友好的最终回复。下面让我们需要创建一个prompt模板,并在这个模板中加入一个消息占位符变量agent_scratchpad,agent_scratchpad变量时用来存储chain的首次调用结果和外部函数的返回结果:
from langchain.prompts import MessagesPlaceholder
#创建prompt,并在prompt中添加agent_scratchpad变量
prompt = ChatPromptTemplate.from_messages([
("system", "You are helpful but sassy assistant"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
#创建chain
chain = prompt | model | OpenAIFunctionsAgentOutputParser()
#首次调用chain时agent_scratchpad为空列表
result1 = chain.invoke({
"input": "上海现在的天气怎么样?",
"agent_scratchpad": []
})
#首次调用chain的结果
result1
这里我们首次调用chain时返回的结果result1和之前相同,llm只返回了需要调用的函数名和参数,接下来我们需要手动来调用外部函数:
#得到外部函数调用结果
observation = get_current_temperature(result1.tool_input)
observation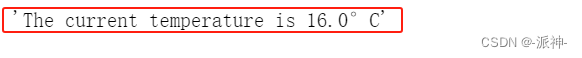
同样,我们还是得到了外部函数的返回结果,不过按照上篇博客的流程拿到外部函数返回结果后将其返回给用户,对话就结束了,不过这里我们还需要外部函数的返回结果做一下处理,我们要让llm对函数返回结果再做一次渲染,我们需要做的就是再次将用户的问题,首次调用llm的返回结果,外部函数的返回结果这三样东西再喂给llm,这样llm就会给出一个对用户友好的最终回复:
from langchain.agents.format_scratchpad import format_to_openai_functions
#将首次llm返回结果和函数执行结果组合起来并转换成函数描述描述变量
functions = format_to_openai_functions([(result1, observation)])
result2 = chain.invoke({
"input": "上海现在的天气怎么样?",
"agent_scratchpad":functions
})
result2
这里需要说明的是我们将llm的首次返回结果result1和函数的返回结果observation组合在一起并将它们转换成了openai的函数描述变量,并在第二次调用chain时将其赋给了prompt模板中的agent_scratchpad变量。这样我们最后就会得到一个对用户友好的最终回复。注意这时llm的返回结果result2的类型是"AgentFinish",它是一个非常重要的返回类型,后面我们自动优化的时候需要用到"AgentFinish"这个类型,接下来我们就可以轻松从result2中提取我们需要的内容了:
result2.return_values['output']
下面我们查看一下format_to_openai_functions方法的结果:
format_to_openai_functions([(result1, observation)])
这里我们看到format_to_openai_functions方法是将llm的首次返回结果和外部函数的返回结果组合在了一起,它们的类型分别是AIMessage和FunctionMessage。
三、自动优化
接下来我们需要将手动优化的流程改造成自动优化,这里我们需要创建一个agent的迭代流程:
def run_agent(user_input):
intermediate_steps = []
while True:
result = chain.invoke({
"input": user_input,
"agent_scratchpad": format_to_openai_functions(intermediate_steps)
})
if isinstance(result, AgentFinish):
return result
tool = {
"search_wikipedia": search_wikipedia,
"get_current_temperature": get_current_temperature,
}[result.tool]
observation = tool.run(result.tool_input)
intermediate_steps.append((result, observation))这里我们定义了一个run_agent的函数,该函数接受用户的输入信息,然后其内部会进行chain的迭代调用,直到chain返回的AgentFinish类型的消息则退出迭代。下面我们来测试一下该函数:
run_agent("上海现在的天气怎么样?")
这里我们看到run_agent返回的是“AgentFinish”消息类型。并且以中文的形式返回了一个比较友好的回复。
run_agent("李世民是谁?")
run_agent("你好")
run_agent("hi!")
这里我们看到,当我们用中文提问的时候,llm也会用中文来回答,当我们用英文提问时,llm会用英文来回答,并且都给出了对用户友好的回复内容,这主要归咎于我们让llm对外部函数的调用结果做了二次渲染。下面再对run_agent函数再做一些改进:
from langchain.schema.runnable import RunnablePassthrough
rp = RunnablePassthrough.assign(
agent_scratchpad= lambda x: format_to_openai_functions(x["intermediate_steps"])
)
#创建agent_chain
agent_chain = rp | chain
def run_agent(user_input):
intermediate_steps = []
while True:
result = agent_chain.invoke({
"input": user_input,
"intermediate_steps": intermediate_steps
})
if isinstance(result, AgentFinish):
return result
tool = {
"search_wikipedia": search_wikipedia,
"get_current_temperature": get_current_temperature,
}[result.tool]
observation = tool.run(result.tool_input)
intermediate_steps.append((result, observation))这里我们在原来chain的基础上创建了一个agent_chain, 这个agent_chain会生成一个agent_scratchpad变量,它对应于prompt模板中的agent_scratchpad变量,并且在run_agent函数中我们不再调用chain变量而是调用agent_chain,同时在run_agent函数中我们将原先的agent_scratchpad变量换成了intermediate_steps,该变量用来存放中间结果如:intermediate_steps.append((result, observation)),经过这样的改造run_agent变得更加的简洁和优雅,可读性更强。下面我们测试一下经过改造的run_agent:
run_agent("北京的天气怎么样?")
到目前位置自动的优化的基础工作我们都已完成,接下来我们需要进一步完善agent的使用机制,不能每次都通过调用run_agent函数来实现和用户的互动,因此我们需要创建一个AgentExecutor,其内部已经封装了run_agent函数,使用起来更加方便:
from langchain.agents import AgentExecutor
#创建AgentExecutor,打开调试器verbose=True
agent_executor = AgentExecutor(agent=agent_chain, tools=tools, verbose=True)
#执行agent_executor
agent_executor.invoke({"input": "上海现在的天气怎么样?"})
agent_executor.invoke({"input": "李世民是谁?"})
这里我们打开了agent_executor的调试器开关verbose=True,我们可以在llm的返回结果中看到函数调用的中间结果,以及llm最终的返回结果。接下来我们再测试一下agent_executor的记忆能力:
agent_executor.invoke({"input": "我的名字叫王老六"})
agent_executor.invoke({"input": "我的名字叫什么?"})
我们看到agent_executor不具有记忆的能力,因为不能记住我之前告诉它的名字,所以我们需要给它添加一个记忆力组件:
from langchain.memory import ConversationBufferMemory
#创建带有聊天历史记录变量的prompt模板
prompt = ChatPromptTemplate.from_messages([
("system", "You are helpful but sassy assistant"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
#创建agent_chain
agent_chain = RunnablePassthrough.assign(
agent_scratchpad= lambda x: format_to_openai_functions(x["intermediate_steps"])
) | prompt | model | OpenAIFunctionsAgentOutputParser()
#创建记忆力组件
memory = ConversationBufferMemory(return_messages=True,
memory_key="chat_history")
#添加记忆力组件
agent_executor = AgentExecutor(agent=agent_chain,
tools=tools,
verbose=True,
memory=memory)
#调用chain
agent_executor.invoke({"input": "我的名字叫王老六"})
agent_executor.invoke({"input": "我的名字叫什么?"})
这里我们给prompt 模板中增加了一个消息占位符变量chat_history,并且每次在和用户对话过程中,之前对话的历史记录都会被传送给llm, 所以llm在回答用户问题的时候都会去分析历史聊天记录,并在此基础上给出正确的回复,从而具有了记忆的能力。
agent_executor.invoke({"input": "上海现在的天气怎么样?"})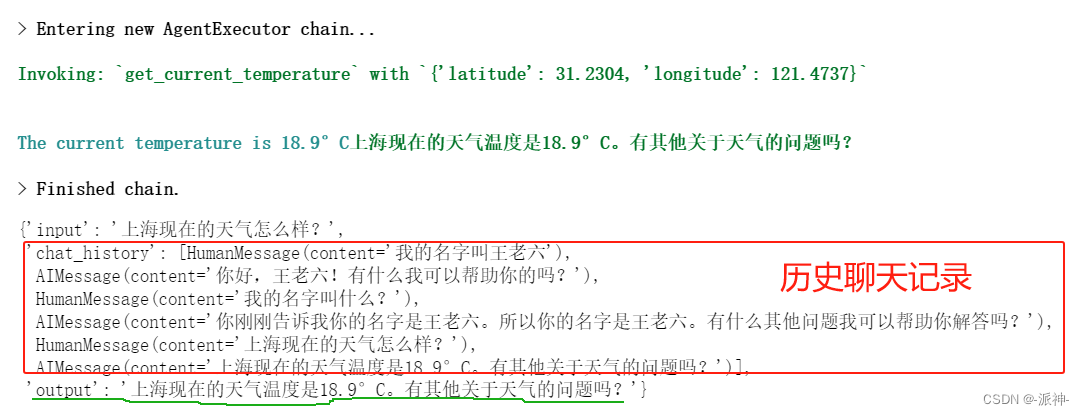
四、创建聊天机器人
下面我们要将上面所有的功能都整合起来创建一个自动化的聊天机器人程序,请注意下面的聊天机器人时在jupyter notebook中实现的:
import panel as pn # GUI
pn.extension()
import panel as pn
import param
@tool
def create_your_own(query: str) -> str:
"""This function can do whatever you would like once you fill it in """
print(type(query))
return query[::-1]
tools = [get_current_temperature, search_wikipedia, create_your_own]
class cbfs(param.Parameterized):
def __init__(self, tools, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.functions = [format_tool_to_openai_function(f) for f in tools]
self.model = ChatOpenAI(temperature=0).bind(functions=self.functions)
self.memory = ConversationBufferMemory(return_messages=True,memory_key="chat_history")
self.prompt = ChatPromptTemplate.from_messages([
("system", "You are helpful but sassy assistant"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
self.chain = RunnablePassthrough.assign(
agent_scratchpad = lambda x: format_to_openai_functions(x["intermediate_steps"])
) | self.prompt | self.model | OpenAIFunctionsAgentOutputParser()
self.qa = AgentExecutor(agent=self.chain, tools=tools, verbose=False, memory=self.memory)
def convchain(self, query):
if not query:
return
inp.value = ''
result = self.qa.invoke({"input": query})
self.answer = result['output']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=450)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=450, styles={'background-color': '#F6F6F6'}))
])
return pn.WidgetBox(*self.panels, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
cb = cbfs(tools)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
conversation = pn.bind(cb.convchain, inp)
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=400),
pn.layout.Divider(),
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# QnA_Bot')),
pn.Tabs(('Conversation', tab1))
)
dashboard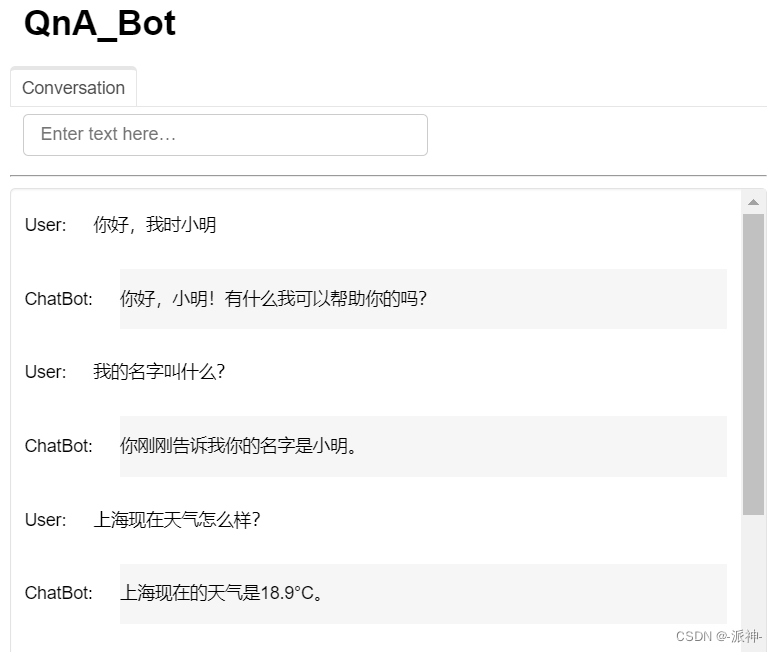

这里我们定义了一个自定义的工具函数create_your_own, 它用来反转用户输入的字符串,从上面的聊天结果中我们可以看到机器人不仅可以通过调用外部函数来回答用户的问题,并且它还知道自己的内部结构(知道自己有几个工具),同时还可以让用户来指定调用其内部的哪个工具函数。
五、总结
今天我们回顾了在langchain中实现基本的函数调用方法,以及在此基础上进行手动优化和自动优化的流程,最后我们将所有的功能整合在一起开发了一个自动化的聊天机器人,它具有记忆能力同时还能根据用户的问题来自主判断是否调用外部函数并给出对用户友好的回复,希望今天的内容对大家学习langchain有所帮助!


















 7893
7893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











