







 本文是一篇CUDA安装与调试的实战教程,作者在win10系统下使用Visual Studio 2013和NVIDIA GeForce GTX 1050Ti显卡进行配置。主要内容包括CUDA环境配置、CUDA包下载、CUDA示例和CUDA调试经验分享,特别是关于CUDA调试器Nsight的版本选择与安装问题。
本文是一篇CUDA安装与调试的实战教程,作者在win10系统下使用Visual Studio 2013和NVIDIA GeForce GTX 1050Ti显卡进行配置。主要内容包括CUDA环境配置、CUDA包下载、CUDA示例和CUDA调试经验分享,特别是关于CUDA调试器Nsight的版本选择与安装问题。
写这篇文章主要是针对CUDA调试经验分享,网上可供参考的资料太少了,最后靠自学CUDA官网help文档成功进入global函数断点,感兴趣的继续看下去吧!
本人的电脑配置:本机win10+vs2013+NVIDIA GeForce GTX 1050Ti
1、CUDA加速环境配置,主要包括4项:
1)电脑配有NVIDA显卡
2)安装NVIDA驱动
3)安装VS开发环境(一个C语言编译器)
4)CUDA开发包
简单的说,想要用CUDA加速电脑需要有支持CUDA加速的图形处理器;并且安装NVIDA驱动,版本可能受限于GPU显卡的型号,后面我想CUDA调试的时候发现显卡决定了的cuda调试器版本,也决定了cuda版本,具体关系请慢慢看下去。
2、分享一下资料
1)CUDA包(英文全称:CUDA Toolkit)官网下载:CUDA Toolkit Archive | NVIDIA Developer
2)本人参考教程并成功安装链接:https://blog.csdn.net/qq_21792169/article/details/105842776
3)CUDA教学视频:https://www.iqiyi.com/v_19rrnosmz8.html
4)如何查看cuda是否安装成功:https://jingyan.baidu.com/article/bea41d43d5741fb4c51be6f7.html
5)CUDA调试器(英文全称:Nsight Visual Studio Edition;针对WIN系统,安装后会集成到VS里面)下载:https://developer.nvidia.com/nsight-visual-studio-edition-archive
3、CUDA示例
求一张图像的均值。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cuda.h>
#include <device_functions.h>
#include <iostream>
using namespace std;
const int THREADS = 1024;
//typedef int DT;
typedef unsigned short DT;
__global__ void matSum(DT *dataIn, double *dataOutAverage, int nPixels)
{
__shared__ double sharedSum[THREADS]; //
int threadIndex = threadIdx.x;
int nPixelsPerThread = nPixels / blockDim.x;
double nSum = 0;
for (int i = threadIndex * nPixelsPerThread; i < (threadIndex + 1) * nPixelsPerThread && i < nPixels; ++i)
{
nSum += dataIn[i];
}
sharedSum[threadIndex] = nSum;
__syncthreads();
if (0 == threadIndex)
{
double fSum = 0;
for (int i = 0; i < THREADS; ++i)
{
fSum += sharedSum[i];
}
*dataOutAverage = fSum / nPixels;
}
}
int main()
{
FILE *fpsrc = NULL;
int Width = 3072;
int Height = 3072;
//fopen read image
DT *image = new DT[Width * Height];
//if ((fpsrc = fopen("E:\\SmileDoc\\MATLAB\\GL\\test.raw", "rb")) == NULL)
if ((fpsrc = fopen("D:\\VG2020-SHARE\\imagecases\\103\\total-3072x3072-chest-ap-NoGrid85KV1.6mAs.raw", "rb")) == NULL)
{
printf("Can not open the raw image.");
system("pause");
return 0;
}
fread(image, sizeof(DT), Width* Height, fpsrc);
fclose(fpsrc);
double average = 0;
DT *d_src = NULL;
double *d_average = NULL;
cudaMalloc((DT**)&d_src, Width*Height*sizeof(DT));
cudaMalloc((double**)&d_average, sizeof(double));
cudaMemcpy(d_src, image, Width*Height*sizeof(DT), cudaMemcpyHostToDevice);
matSum << <1, THREADS >> >(d_src, d_average, Width * Height);
cudaMemcpy(&average, d_average, sizeof(double), cudaMemcpyDeviceToHost);
cudaFree(d_src);
cudaFree(d_average);
cout << endl << "The average is :" << average << endl;
return 0;
}4、CUDA调试
关于CUDA调试经验,我上网搜了很多资料,可供参考的太少了,下面是关于我自己的经验分享。
首先,你要查一下自己电脑的显卡型号,它所支持的调试器版本,比如我的显卡是NVIDIA GeForce GTX 1050Ti ,支持CUDA调试器Nsight Visual Studio Edition 5.5 或者5.6版本,保险起见选择了5.5版本;
这个Nsight Visual Studio Edition调试器 没有办法单独下载,你下载的CUDA Toolkit在安装时会自动绑定一个CUDA调试器版本,由于没有经验,我先安装了CUDA10.0版本,后面调试怎么都不能进到global函数断点中,vs界面上有Nsight菜单,最底下有个help,在help文档中找到了版本支持的相关信息,提示我的显卡型号支持Nsight 5.5/5.6,单独下载Nsight5.5下载不了,只能卸载CUDA包重新安装CUDA9.1版本,这个信息是在调试器5.5版那个下载页面有说明;特别注意:重新安装CUDA9.1自动会安装Nsight5.5,然后重新配置PATH环境,VS里面配置include/lib等,新建个工程后,成功进入global函数断点:
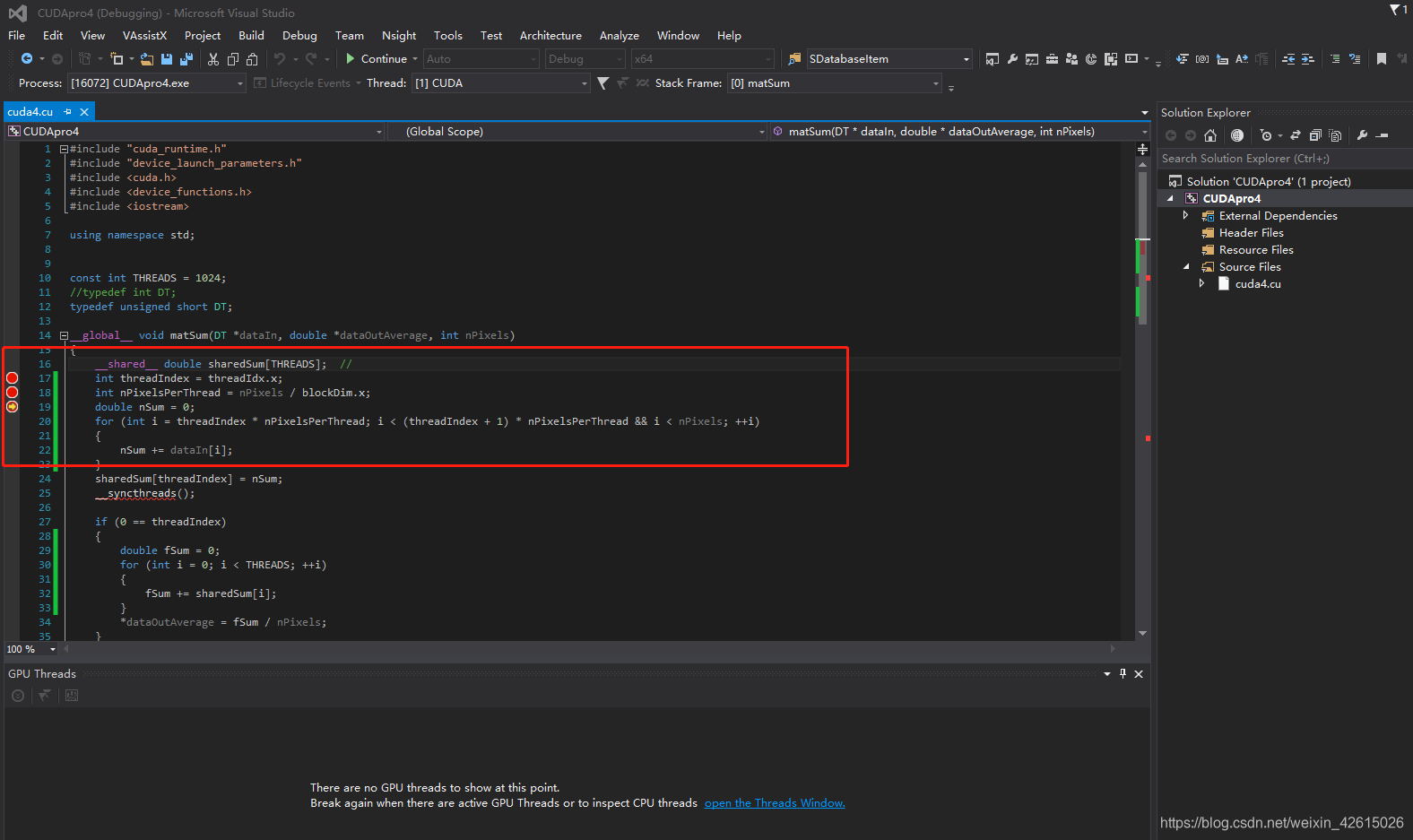
我说的比较粗犷,如果想知道详细流程欢迎加我微信讨论,微信号:zm5547;废话不多索了,工作工作,哈哈哈哈哈
2024年11月13号更新内容:
针对cuda version都有一个对应的最低driver version, 具体参考文章:
例如:
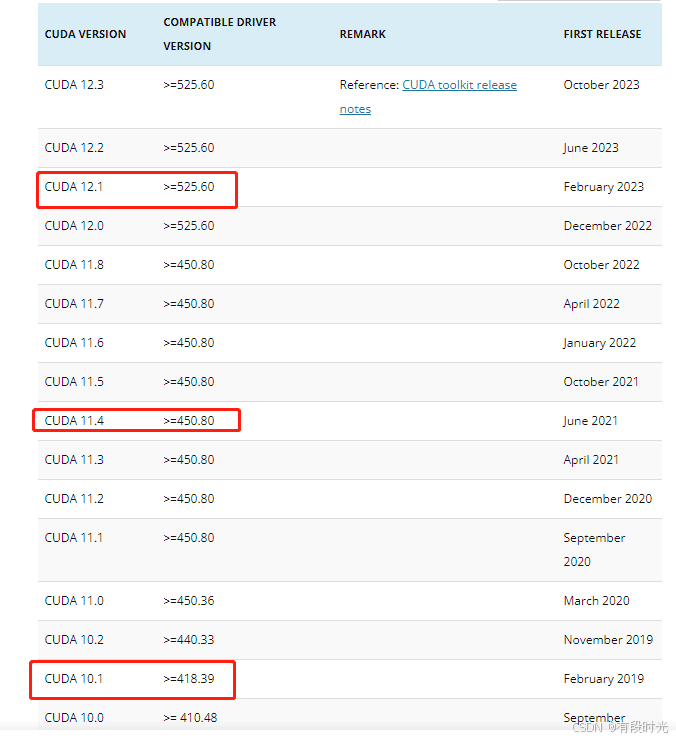
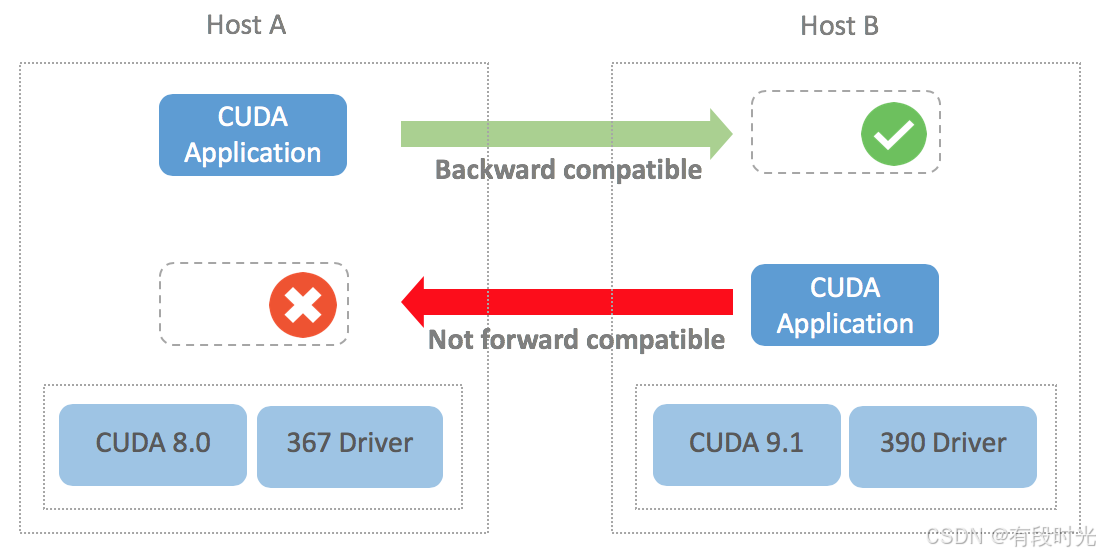
尽可能用低版本的cuda包来编译算法库或者可执行程序,这样目标运行设备的cuda version高于该版本即可运行算法库或者可执行程序。因为它是向下兼容的 。



















 3687
3687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









