







 本文探讨了数据降维的必要性,如减少计算量、处理多重共线性等问题,并介绍了特征选择和维度转换两种降维方法。接着,详细讲解了常见的降维技术,包括缺失值比率、低方差过滤器、高相关过滤器、随机森林、因子分析和主成分分析(PCA),并通过实际案例展示了如何在Python中应用这些技术进行数据降维。
本文探讨了数据降维的必要性,如减少计算量、处理多重共线性等问题,并介绍了特征选择和维度转换两种降维方法。接着,详细讲解了常见的降维技术,包括缺失值比率、低方差过滤器、高相关过滤器、随机森林、因子分析和主成分分析(PCA),并通过实际案例展示了如何在Python中应用这些技术进行数据降维。
1.数据为何要降维
- 降低模型的计算量,减少模型运行时间,减少数据存储空间;
- 降低噪音变量信息对于模型结果的影响;
- 它通过删除冗余的特征来处理多重共线性问题。例如,你有两个变量 - “在跑步机上花费的时间”和“燃烧的卡路里”。这些变量是高度相关的,因为你在跑步机上花费的时间越多,你燃烧的卡路里就越多。因此,存储两个变量都没有意义,只有其中一个可以满足需求;
- 较简单的模型在小数据集有更强的鲁棒性;
- 当数据能用较少的特征进行解释,我们可以更好的解释数据,使得我们可以提取知识;
- 便于通过可视化方式展示归约后的维度信息。
因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理。
数据降维有两种方式:特征选择,维度转换
特征选择
特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值。
特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据处理和建模需求,又能保留维度原本的业务含义,以便于业务理解和应用。对于业务分析性的应用而言,模型的可理解性和可用性很多时候要有限于模型本身的准确率、效率等技术指标。例如,决策树得到的特征规则,可以作为选择用户样本的基础条件,而这些特征规则便是基于输入的维度产生。
维度转换
这个是按照一定数学变换方法,把给定的一组相关变量(维度)通过数学模型将高纬度空间的数据点映射到低纬度空间中,然后利用映射后变量的特征来表示原有变量的总体特征。这种方式是一种产生新维度的过程,转换后的维度并非原来特征,而是之前特征的转化后的表达式,新的特征丢失了原有数据的业务含义。 通过数据维度变换的降维方法是非常重要的降维方法,这种降维方法分为线性降维和非线性降维两种,其中常用的代表算法包括独立成分分析(ICA),主成分分析(PCA),因子分析(Factor Analysis,FA),线性判别分析(LDA),局部线性嵌入(LLE),核主成分分析(Kernel PCA)等。
2.常用的降维技术
2.1缺失值比率 (Missing Values Ratio)
假设你有一个数据集。你的第一步是什么?在构建模型之前,你应该会希望先探索数据。在研究数据时,你会发现数据集中存在一些缺失值。怎么办?你将尝试找出这些缺失值的原因,然后将输入它们或完全删除具有缺失值的变量(使用适当的方法)。
如果我们有太多的缺失值(比如说超过50%)怎么办?我们应该输入这些缺失值还是直接删除变量?我宁愿放弃变量,因为它没有太多的信息。然而,这不是一成不变的。我们可以设置一个阈值,如果任何变量中缺失值的百分比大于该阈值,我们将删除该变量。
我们将使用一个实践问题:Big Mart Sales III中的数据集。其中,Item_Outlet_Sales折扣店销量为因变量。
我们将检查每个变量中缺失值的百分比。我们可以使用.isnull().sum()来计算它。
检查每个变量中缺失值的百分比
train.isnull().sum()/len(train)*100
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
train=pd.read_csv("Train_UWu5bXk.csv")
print(train.isnull().sum()/len(train)*100)

正如你在上表中所看到的,并没有太多的缺失值(实际上只有2个变量具有缺失值)。我们可以使用适当的方法来输入变量,或者我们可以设置阈值,比如20%,并删除具有超过20%缺失值的变量。让我们看看如何在Python中完成此操作:
保存变量中缺失的值
a = train.isnull().sum()/len(train)*100
将列名保存在变量中
variables = train.columns
variable = [ ]
for i in range(0,12):
if a[i]<=20: #将阈值设置为20%
variable.append(variables[i])
print(variable)
因此,要使用的变量存储在“variables”中,它只包含哪些缺失值小于20%的特征。
2.2低方差过滤器(Low Variance Filter)
与缺失值比率进行数据降维方法相似,该方法假设数据列变化非常小的列包含的信息量少。因此,所有的数据列方差小的列被移除。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。
假设我们的数据集中的一个变量,其中所有观察值都是相同的,例如1。如果我们要使用此变量,你认为它可以改进我们将要建立的模型么?答案当然是否定的,因为这个变量的方差为零。
因此,我们需要计算给出的每个变量的方差。然后删除与我们的数据集中其他变量相比方差比较小的变量。如上所述,这样做的原因是方差较小的变量不会影响目标变量。
让我们首先使用已知ItemWeight观察值的中值来填充temWeight列中的缺失值。对于OutletSize列,我们将使用已知OutletSize值的模式来填充缺失值:
train[‘Item_Weight’].fillna(train[‘Item_Weight’].median(), inplace=True)
train[‘Outlet_Size’].fillna(train[‘Outlet_Size’].mode()[0], inplace=True)
让我们检查一下是否所有的缺失值都已经被填满了:
train.isnull().sum()/len(train)*100
#使用已知OutletSize值的模式来填充缺失值
train['Item_Weight'].fillna(train['Item_Weight'].median(), inplace=True)
train['Outlet_Size'].fillna(train['Outlet_Size'].mode()[0], inplace=True)
#检查一下是否所有的缺失值都已经被填满了:
print(train.isnull().sum()/len(train)*100)
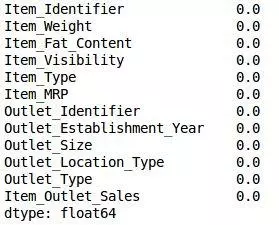
嘿瞧!我们都已经准备好了。现在让我们计算所有数值变量的方差。
train.var()
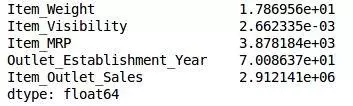
如上面的输出所示,与其他变量相比,Item_Visibility的方差非常小。我们可以安全地删除此列。这就是我们应用低方差过滤器的方法。让我们在Python中实现这个:
#Item_Visibility的方差非常小,删除此列:
numeric = train[['Item_Weight', 'Item_Visibility', 'Item_MRP', 'Outlet_Establishment_Year']]
var = numeric.var()
numeric = numeric.columns
variable = [ ]
for i in range(0,len(var)):
if var[i]>=10: #将阈值设置为10%
variable.append(numeric[i])
print(variable)
上面的代码为我们提供了方差大于10的变量列表。
['Item_Weight', 'Item_MRP', 'Outlet_Establishment_Year']
2.3高相关过滤器 (High Correlation Filter)
高相关滤波认为当两列数据变化趋势相似时,它们包含的信息也相似。这样,使用相似列中的一列就可以满足机器学习模型。对于数值列之间的相似性通过计算相关系数来表示,对于数据类型为类别型的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。
两个变量之间的高度相关意味着它们具有相似的趋势,并且可能携带类似的信息。这可以大大降低某些模型的性能(例如线性回归和逻辑回归模型)。我们可以计算出本质上是数值的独立数值变量之间的相关性。如果相关系数超过某个阈值,我们可以删除其中一个变量(丢弃一个变量是非常主观的,并且应该始终记住该变量)。
作为一般准则,我们应该保留那些与目标变量显示出良好或高相关性的变量。
让我们在Python中执行相关计算。我们将首先删除因变量(ItemOutletSales)并将剩余的变量保存在新的DataFrame(df)中。
df=train.drop(‘Item_Outlet_Sales’, 1)
df.corr()
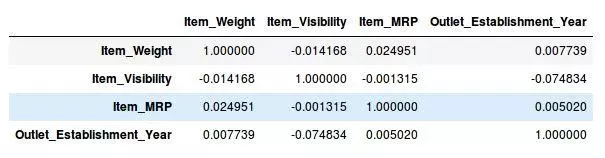
太棒了,我们的数据集中没有任何具有高相关性的变量。通常,如果一对变量之间的相关性大于0.5-0.6,我们真的应该认真的考虑丢弃其中的一个变量。
2.4 随机森林 (Random Forests)
组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成层次非常浅的树,每颗树只训练一小部分属性。如果一个属性经常成为最佳分裂属性,那么它很有可能是需要保留的信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









