







目录
摘要:
演示如何通过Matlab自带的随机森林函数进行特征选择,筛选出大量特征数据中对于回归预测最重要的特征,并对各特征进行重要性排序,充分反应不同特征的重要性。演示如何在种植随机树林时为数据集选择适当的拆分预测变量选择技术。随机森林特征筛选一种特征选择技术,特征选择( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ),或属性选择( Attribute Selection )。是指从已有的M个特征(Feature)中选择N个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。对于一个学习算法来说,好的学习样本是训练模型的关键。
已写好输入输出结构,方便使用者通过替换自己的数据实现不同的功能,注释详细
适合数学建模等直接应用
1.随机森林:
随机森林算法(Random Forest,RF)是一种 新型机器学习算法,是利用多棵决策树对样本进行训练并集成预测的一种分类器,它采用Boot‐ strap重抽样技术从原始样本中随机抽取数据构 造多个样本,然后对每个重抽样样本采用节点的 随机分裂技术构造多棵决策树,最后将多棵决策树组合,并通过投票得出最终预测结果。
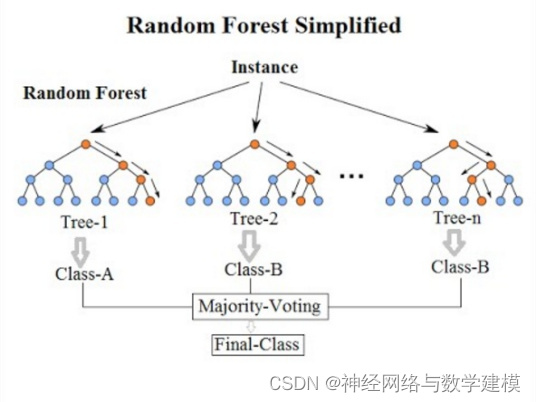
根据下列算法而建造每棵树 :
1.用N来表示训练用例(样本)的个数,M表示特征数目。
2.输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
3.从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
4.对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
5.每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用)。
2.随机森林的特征选取:
随机森林算法利用 OOB 误差计算特征变量相对重要性,并对特征变量进行排序和筛选,这一特点对于大量特征参与分类时非常适用,因为众多特征之间的高相关性会产生高维问题,会显著降低提取的精度。现阶段机器学习模型的特征空间往往庞大且复杂,呈现出高维性、非线性等复杂特点,面对这样的海量高维数据,剔除冗余特征进行特征筛选,已成为当今信息与科学技术面临的重要问题之一。实际上,特征选择正是从输入特征中优选了重要性高、信息量丰富的特征来提高地物信息提取的精度,在遥感应用中有着重要的应用潜力。
在特征重要性的基础上,特征选择的步骤如下:
1.计算每个特征的重要性,并按降序排序
2.确定要剔除的比例,依据特征重要性剔除相应比例的特征,得到一个新的特征集
3.用新的特征集重复上述过程,直到剩下m个特征(m为提前设定的值
4.根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集
3.基于Matlab自带的随机森林函数进行特征选取具体步骤
(1)加载数据
加载Matlab自带的数据集。建立一个随机森林预测模型,该模型根据汽车的气缸数、发动机排量、马力、重量、加速度、车型年份和原产国来预测汽车的燃油经济性。使用Load函数进行数据的加载。
各单词解释:
【Cylinders,Displacement,Horsepower,Weight,Acceleration,Model_Year,Origin】
【气缸数目,排量,马力,重量,加速度,车辆年份,原产地】
(2)首先建立随机森林并使用全部特征进行车辆经济性预测
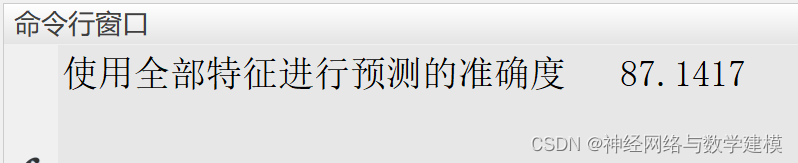
使用templateTree和fitrensemble这两个函数建立随机森林,并先使用全部的特征进行车辆经济性进行预测。输入为【气缸数目,排量,马力,重量,加速度,车辆年份,原产地】,输出为【车辆经济性】,随机森林中的决策树数量设置为100。训练模型并进行预测分析,具体结果如下,使用全部特征进行预测的准确度为87.1417.
(3)使用随机森林进行特征选择
根据第二点所述,利用 OOB 误差计算特征变量相对重要性,并对特征变量进行排序和筛选,编写相关程序进行随机森林特征筛选,具体结果与各个特征变量的重要性情况如下所示:
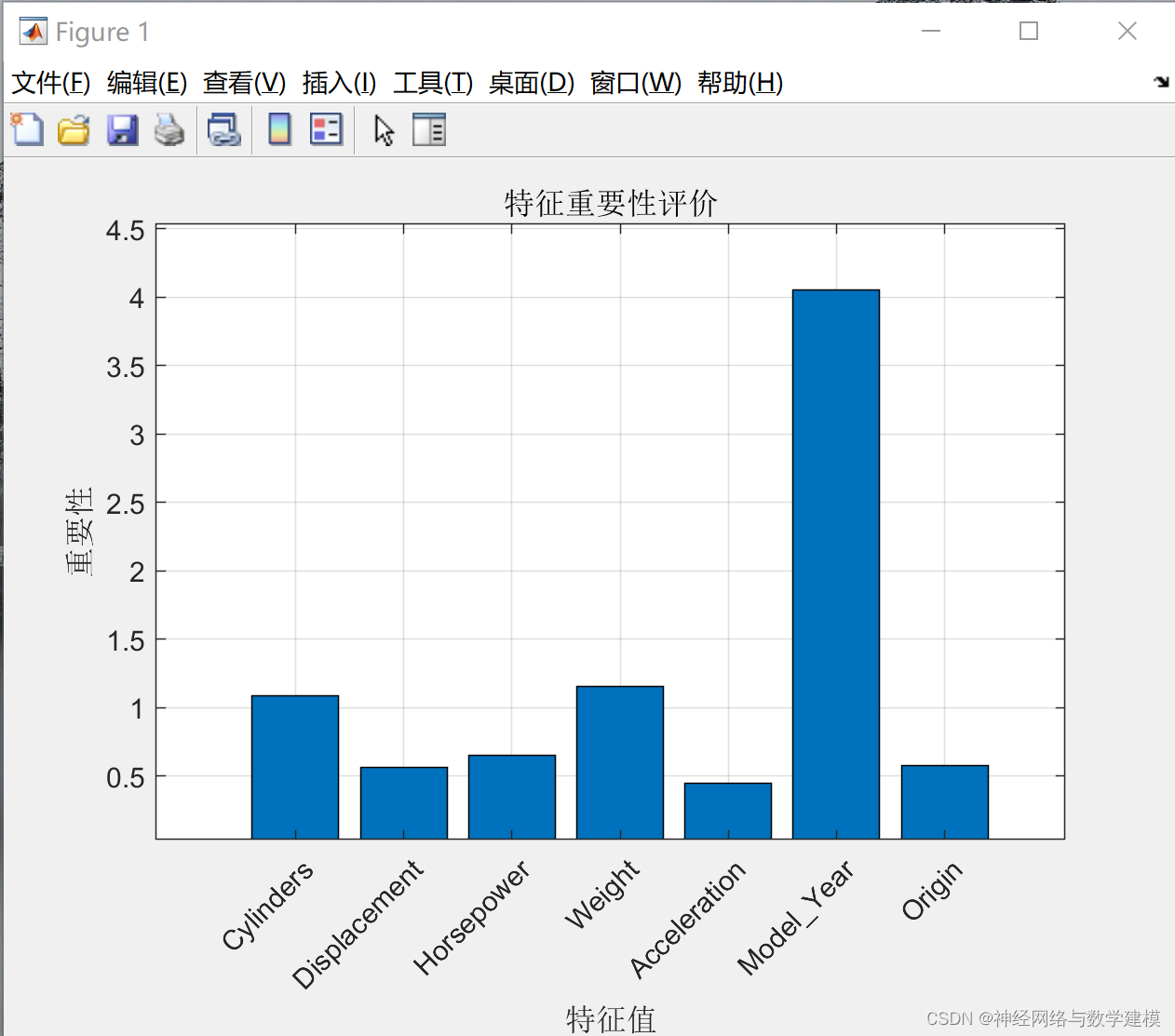
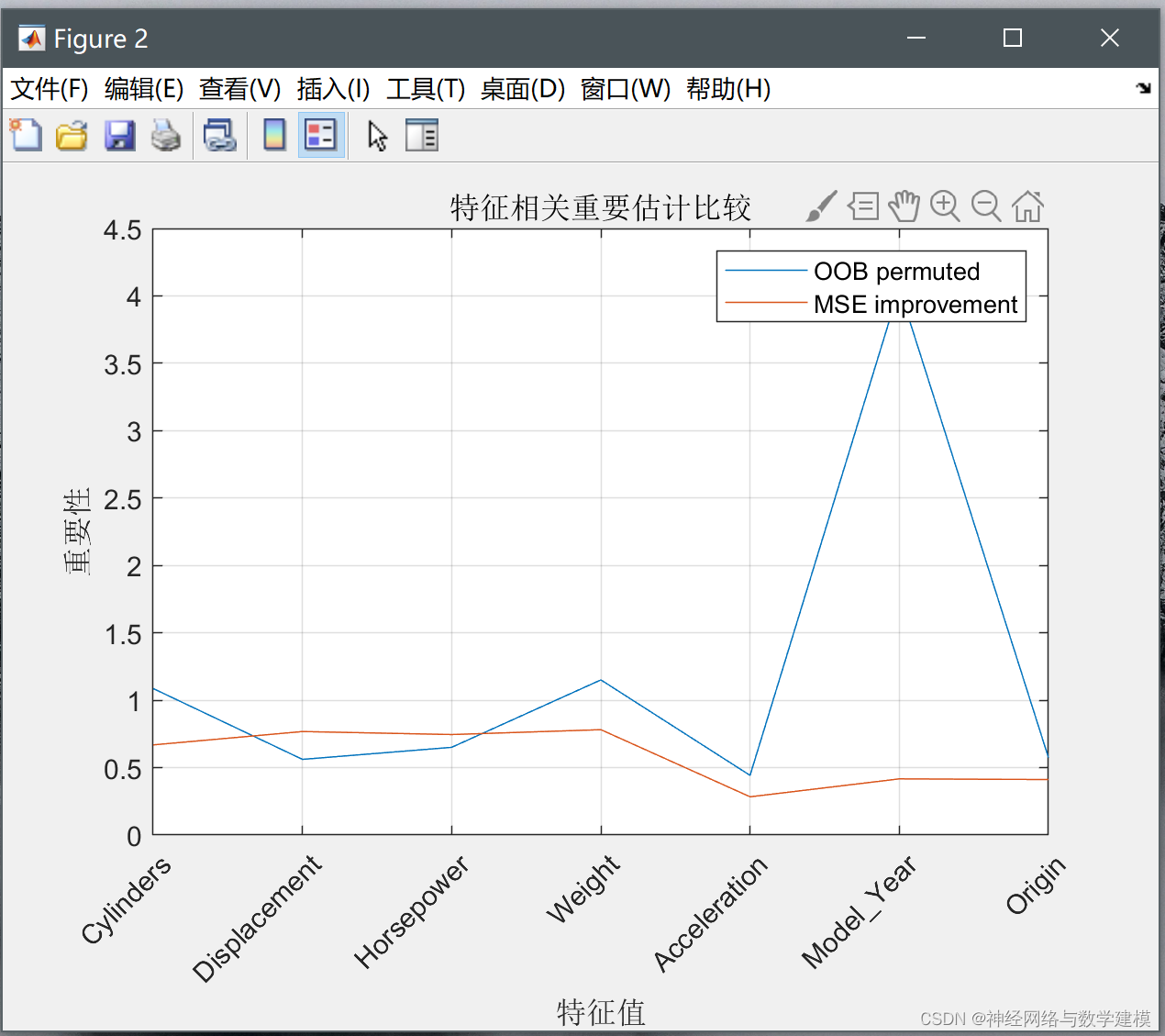
(4)评价各个特征之间的相关性
当随机森林评价完成特征的重要性后,还需要对各个特征变量之间的相关性进行评估,以更加明显的看出何种特征最能影响预测结果,使用皮尔逊系数作为各个特征变量之间的相关性评价指标,从下图可以看出,越接近黄色表示相关性越强。
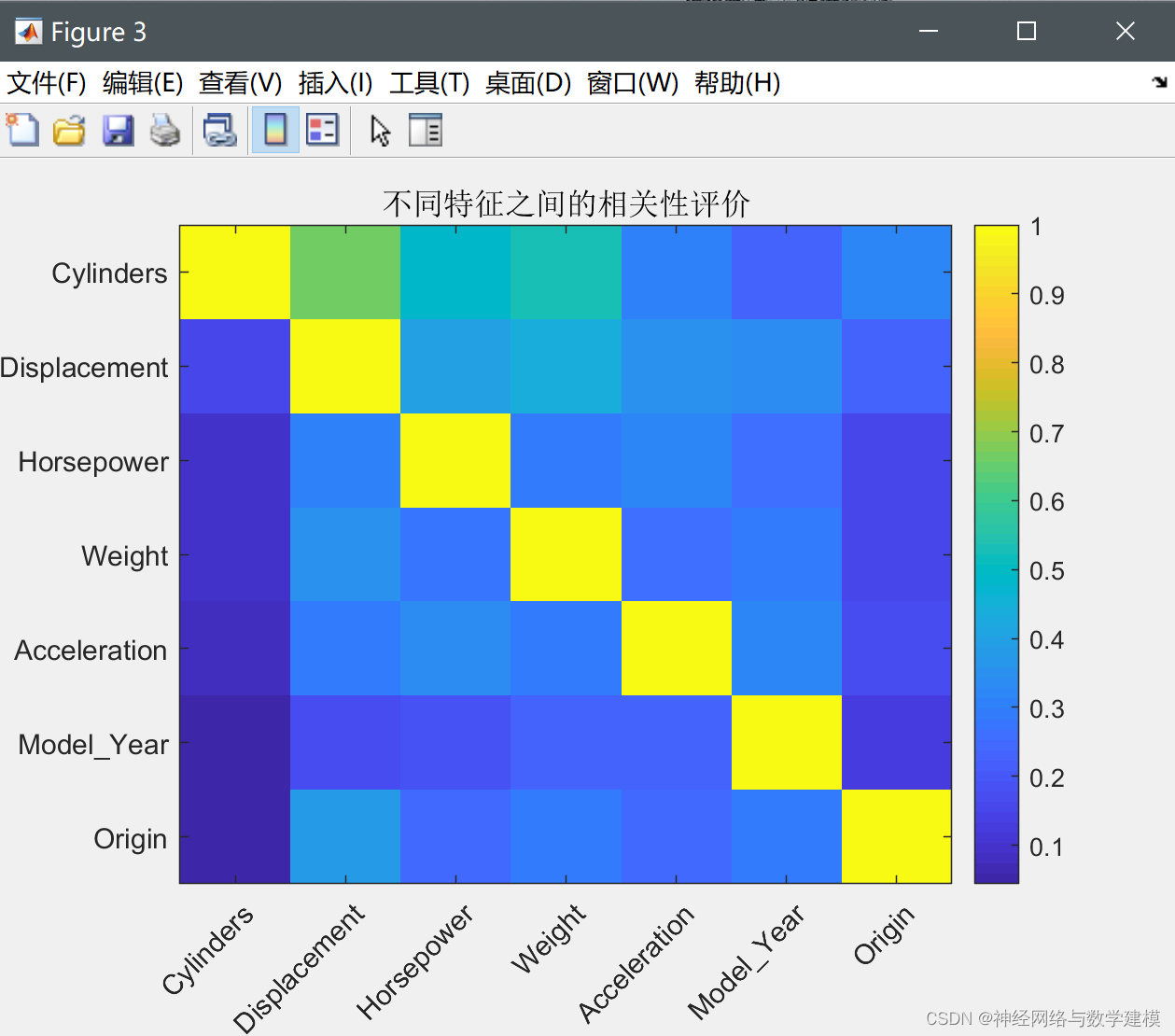
(5)使用筛选后的特征进行测试
综合之前所有特征的重要性与相关性的重要性评价情况,使用【重量,车辆年份】这两个特征进行回归预测,也就是从7个特征降维到2个特征。建立随机森林进行回归预测,其设置与之前的相同,同样使用100棵树。具体结果如下

可以看到,使用两个特征进行预测的准确度为85.2077,与使用所有特征进行预测的准确度相差不大,这表明随机森林特征选择方法有效的选择出了最重要的特征,实现了从大量特征到少数重要特征的特征降维筛选,极大的降低了特征的冗余性。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









