



 文章介绍了如何解决在使用tinny-cuda-nn时,由于cmake编译时CUDA版本与conda虚拟环境中torch版本不匹配的问题,包括注释.bashrc中的cuda路径,安装对应torch版本的cuda,确认环境变量以及最终的编译步骤。
文章介绍了如何解决在使用tinny-cuda-nn时,由于cmake编译时CUDA版本与conda虚拟环境中torch版本不匹配的问题,包括注释.bashrc中的cuda路径,安装对应torch版本的cuda,确认环境变量以及最终的编译步骤。
假如你想安装tinny-cuda-nn,经常在cmake编译的时候,报本机的cuda版本和conda虚拟环境下安装torch版本对应的cuda不匹配。
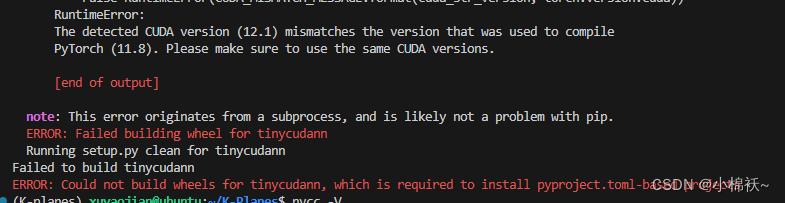
以下是解决办法:
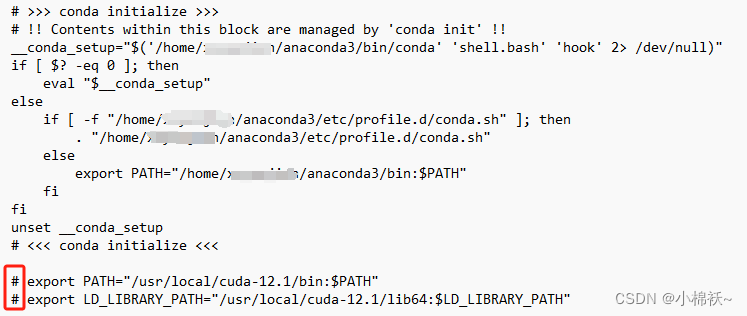
第一步:把 .bashrc 下的cuda指定路径给注释掉。
第二步:安装你torch版本对应的cuda版本,比如我虚拟环境安装的torch版本为:
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118再安装torch指定的cuda版本,比如cuda-11.8
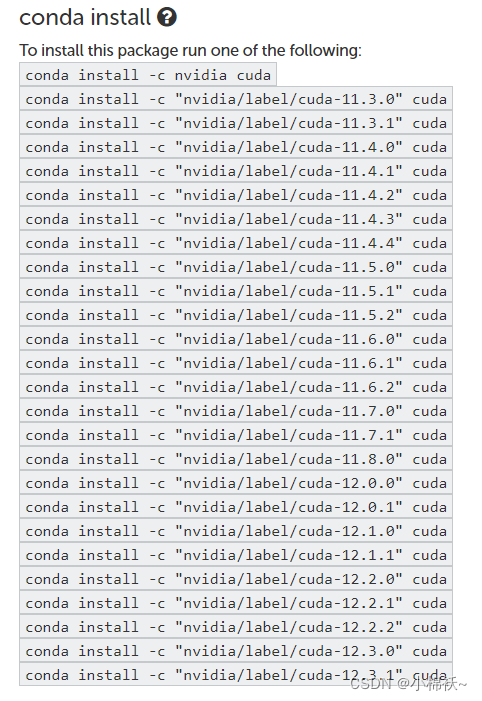
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit其他版本可以去这里查Cuda :: Anaconda.org
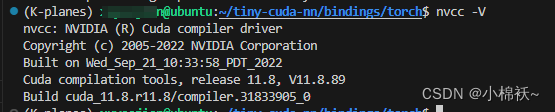
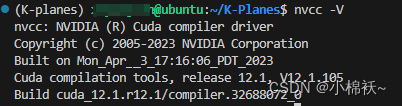
第三步:查看你所在的虚拟环境ncvv -V 的输出是否为 cuda11.8
第四步:去编译
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py install显示安装成功了!

第五步:把第一步的注释给去掉,恢复原来的cuda路径。


















 3673
3673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









