







 本文介绍了如何使用HadoopMapReduce框架进行数据清洗,包括删除NULL值过多、关键字段缺失和重复记录的步骤,并提供了Java代码实现。通过Mapper和Reducer处理hotel.csv文件,最后输出清理后的结果。
本文介绍了如何使用HadoopMapReduce框架进行数据清洗,包括删除NULL值过多、关键字段缺失和重复记录的步骤,并提供了Java代码实现。通过Mapper和Reducer处理hotel.csv文件,最后输出清理后的结果。
一、数据要求
1.数据清洗
不符合要求的数据为:
1)每条记录如果为NULL的字段数量大于等3;
2)“星级6、评论数11、评分10、房间数8”这4个字段有一个为NULL;
3)重复的记录,将重复的去掉;
请删除满足以上三个条件的记录,并打印每类不符合要求的记录的数量;
2.请根据数据清洗的输出数据集,编写Mapreduce程序
1)统计各省份的酒店数量和房间数量,
2)以省份房间数量降序排列并输出前10条统计结果
数据定义如下:
province city hotel_num room_num
贵州 贵阳 1234 123456.0
二、编写代码(本类完成以上1.数据清洗)
package com.mhys;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.Counters;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MyClean1 {
static class MyCleanMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if(key.get()==0) return; //首行干掉
String[] arr = value.toString().split(",");//分隔一行数据为数组
String start = arr[6];
String score = arr[10];
String comments = arr[11];
String rooms = arr[8];
Counter c1 = context.getCounter("NUMS","nulls");//记录一行超过3个为NULL的个数
Counter c2 = context.getCounter("NUMS","isNull");//记录4个关键数据任何一个为null的个数
//计算为NULL的个数
int nulls = 0;
for(String info:arr){
if(info.equals("NULL")){
nulls+=1;
}
}
if(nulls>=3){
c1.increment(1);
return;
}
else if(start.equals("NULL") || score.equals("NULL") || comments.equals("NULL") || rooms.equals("NULL")){
c2.increment(1);
return;
}
else{
//去重交给reduce处理
context.write(value,NullWritable.get());
}
}
}
static class MyCleanReduce extends Reducer<Text, NullWritable,Text,NullWritable>{
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
Counter c3 = context.getCounter("NUMS","repeat");//记录重复的行数
int sum = 0;
for(NullWritable n : values){
sum+=1;
}
c3.increment(sum-1);//将个数-1就是去重的个数
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();//创建一个执行mapreduce的默认配置
Job job = Job.getInstance(conf); //根据默认配置创建一个任务
job.setJarByClass(MyClean1.class);//指明当前类名.class是运行的主类
job.setMapperClass(MyCleanMapper.class);
job.setReducerClass(MyCleanReduce.class);
//告诉任务 map端输出的key-value的类型是什么
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//告诉任务 reduce端输出的key-value类型是什么
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//告诉任务输入单词计数文件在哪里
FileInputFormat.addInputPath(job,new Path("/hotel/hotel.csv"));
//告诉任务输出结果的文件目录在哪里
FileOutputFormat.setOutputPath(job,new Path("/out2"));
//运行程序
boolean flag = job.waitForCompletion(true); //提交运行
//取出计数器的值
long c1 = job.getCounters().findCounter("NUMS","nulls").getValue();
long c2 = job.getCounters().findCounter("NUMS","isNull").getValue();
long c3 = job.getCounters().findCounter("NUMS","repeat").getValue();
System.out.println("每行超过3个为NULL的数量是:"+c1);
System.out.println("4个关键字段任何一个为空的行数是:"+c2);
System.out.println("去除重复的行数是:"+c3);
System.exit(flag?1:0); //根据结果退出程序
}
}
三、执行
1.将要处理的大数据文件上传至 hadoop 的 hotel 目录:
hdfs dfs -put /mysofts/hotel.csv /hotel
2.执行处理:
[root@master hadoop]# hadoop jar /mysofts/mapreduce1-1.0-SNAPSHOT.jar com.mhys.MyClean1
3.查看结果:
[root@master hadoop]# hdfs dfs -cat /out2/part-r-00000
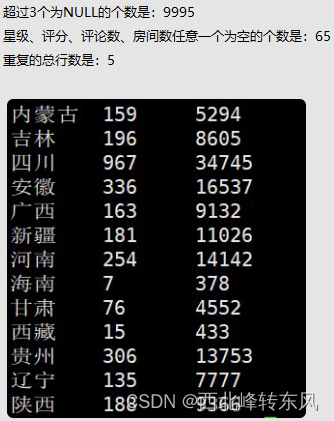

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









